

LSTM原理理解
参考博客
https://zybuluo.com/hanbingtao/note/581764,LSTM的超详细解释
https://blog.csdn.net/qq_36696494/article/details/89028956,RNN、LSTM一起的详解,例子很详细。
长短时记忆网络(LSTM)
长短时记忆网络(Long Short Term Memory Network, LSTM),是RNN的一种,结构比较复杂,但是可以解决RNN的许多缺陷。
长短时记忆网络的思路比较简单。原始RNN的隐藏层只有一个状态,即h,它对于短期的输入非常敏感。那么,假如我们再增加一个状态,即c,让它来保存长期的状态,那么问题不就解决了么?如下图所示:
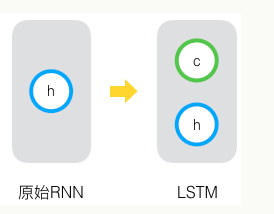
新增加的状态c,称为单元状态(cell state)。把上面的图按照时间维度展开:
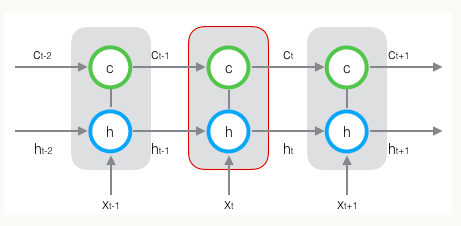
在每个时刻t,LSTM的输入有三个:当前的输入值xt,前一时刻LSTM的输出值ht-1,前一时刻的单元状态ct-1。LSTM的输出有两个,当前时刻LSTM的输出值ht,当前时刻的单元状态ct。
LSTM的关键,就是怎样控制长期状态c。在这里,LSTM的思路是使用三个控制开关。第一个开关,负责控制继续保存长期状态c;第二个开关,负责控制把即时状态输入到长期状态c;第三个开关,负责控制是否把长期状态c作为当前的LSTM的输出。三个开关的作用如下图所示:
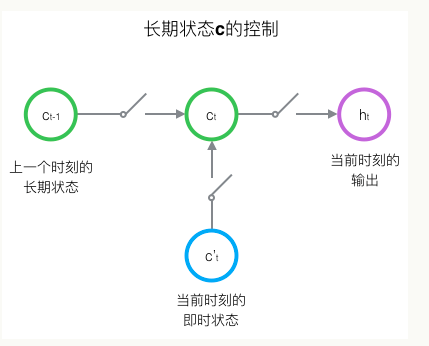
LSTM的前向计算
开关在算法中用门来实现。
门实际上就是一层全连接层,它的输入是一个向量,输出是一个0到1之间的实数向量。假设W是门的权重向量,b是偏置项,那么门可以表示为:
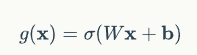
门的使用,就是用门的输出向量按元素乘以我们需要控制的那个向量。因为门的输出是0到1之间的实数向量,那么,当门输出为0时,任何向量与之相乘都会得到0向量,这就相当于啥都不能通过;输出为1时,任何向量与之相乘都不会有任何改变,这就相当于啥都可以通过。因为σ(也就是sigmoid函数)的值域是(0,1),所以门的状态都是半开半闭的。
LSTM一共有三个门,LSTM用两个门来控制单元状态c的内容,一个是遗忘门(forget gate),它决定了上一时刻的单元状态ct-1有多少保留到当前时刻ct;另一个是输入门(input gate),它决定了当前时刻网络的输入xt有多少保存到单元状态ct。LSTM用输出门(output gate)来控制单元状态ct有多少输出到LSTM的当前输出值ht。
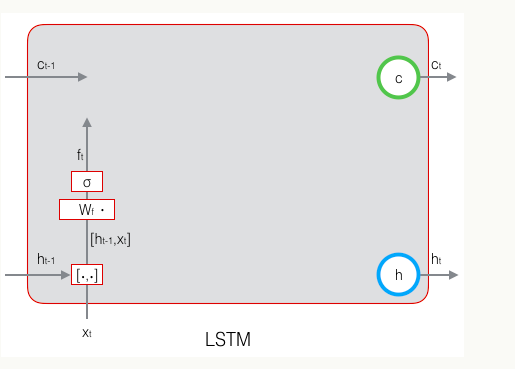
遗忘门:控制上一时刻的单元状态

遗忘门是由前一个时刻的输出h和这个时刻的输入x决定的,遗忘门的计算传播如下图:
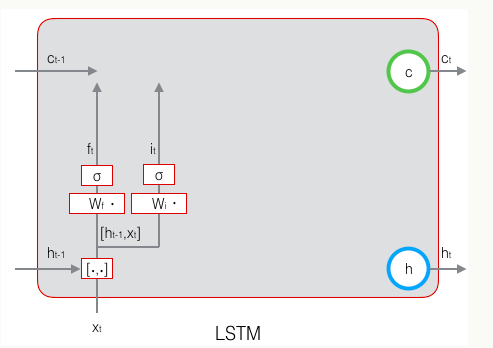
输入门:控制当前时刻的输入

输入门也是由上一时刻的输出h和这个时刻的输入t决定的,计算传播如下图:
除了遗忘门、输入门,还有当前时刻的单元状态c(这只是一个临时值,描述当前输入,由输入门控制)也是由前一时刻的输出h和这个时刻的输入x决定的,计算公式如下:
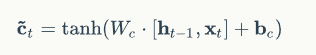
计算传播如下:

最终的要传到下一层的当前时刻的单元状态c,由遗忘门、输入门、描述输入的单元状态临时值、前一个时刻的最终单元状态共同决定。
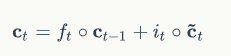
圆圈表示按元素乘,计算规则如下图:

作用于一个向量和一个矩阵时广播。
前一个时刻的最终单元状态由遗忘门决定,当前单元状态的临时值由输入门决定,通过遗忘门和输入门将当前的记忆和长期的记忆组合在一起,形成最终的当前时刻的单元状态。
由于遗忘门的控制,它可以保存很久很久之前的信息,由于输入门的控制,它又可以避免当前无关紧要的内容进入记忆。
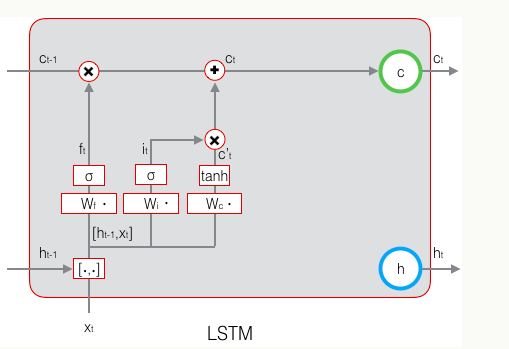
输出门:控制当前时刻的单元状态
当前时刻LSTM的输出由输出门控制,输出门控制了长期记忆对当前输出的影响,与当前时刻的输入x和前一时刻的输出h有关,计算公式如下:
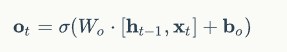
输出门的计算传播如下:
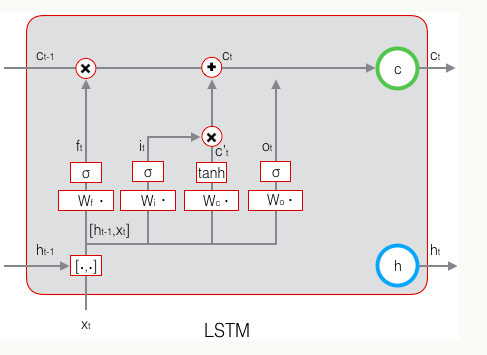
最终输出的计算由当前时刻的最终单元状态c和输出门共同决定,最终单元状态不仅包括此时的记忆,还包括之前的记忆。计算公式如下:

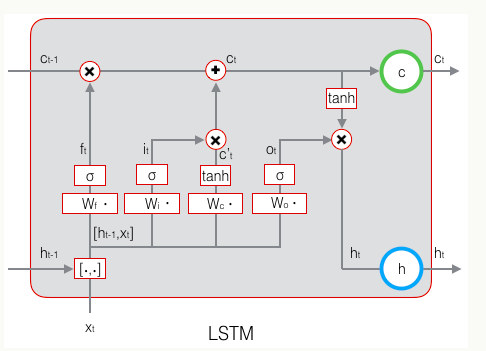
LSTM的最终计算如下图:
LSTM的训练
训练算法仍然是反向传播BP算法
主要有下面三个步骤:
- 前向计算每个神经元的输出值,对于LSTM来说,即、、、、五个向量(分别是遗忘门、输入门、单元状态、输出门、输出)的值。
- 反向计算每个神经元的误差项值。与循环神经网络一样,LSTM误差项的反向传播也是包括两个方向:一个是沿时间的反向传播,即从当前t时刻开始,计算每个时刻的误差项;一个是将误差项向上一层(输入层或其他)传播。
- 根据相应的误差项,计算每个权重的梯度。
推导过程如下:
LSTM需要学习的参数共有8组,分别是:遗忘门的权重矩阵和偏置项、输入门的权重矩阵和偏置项、输出门的权重矩阵和偏置项,以及计算单元状态的权重矩阵和偏置项。因为权重矩阵的两部分在反向传播中使用不同的公式,因此在后续的推导中,权重矩阵、、、都将被写为分开的两个矩阵:、、、、、、、。
分别的推导过程见:https://zybuluo.com/hanbingtao/note/581764
LSTM的python实现也见:https://zybuluo.com/hanbingtao/note/581764
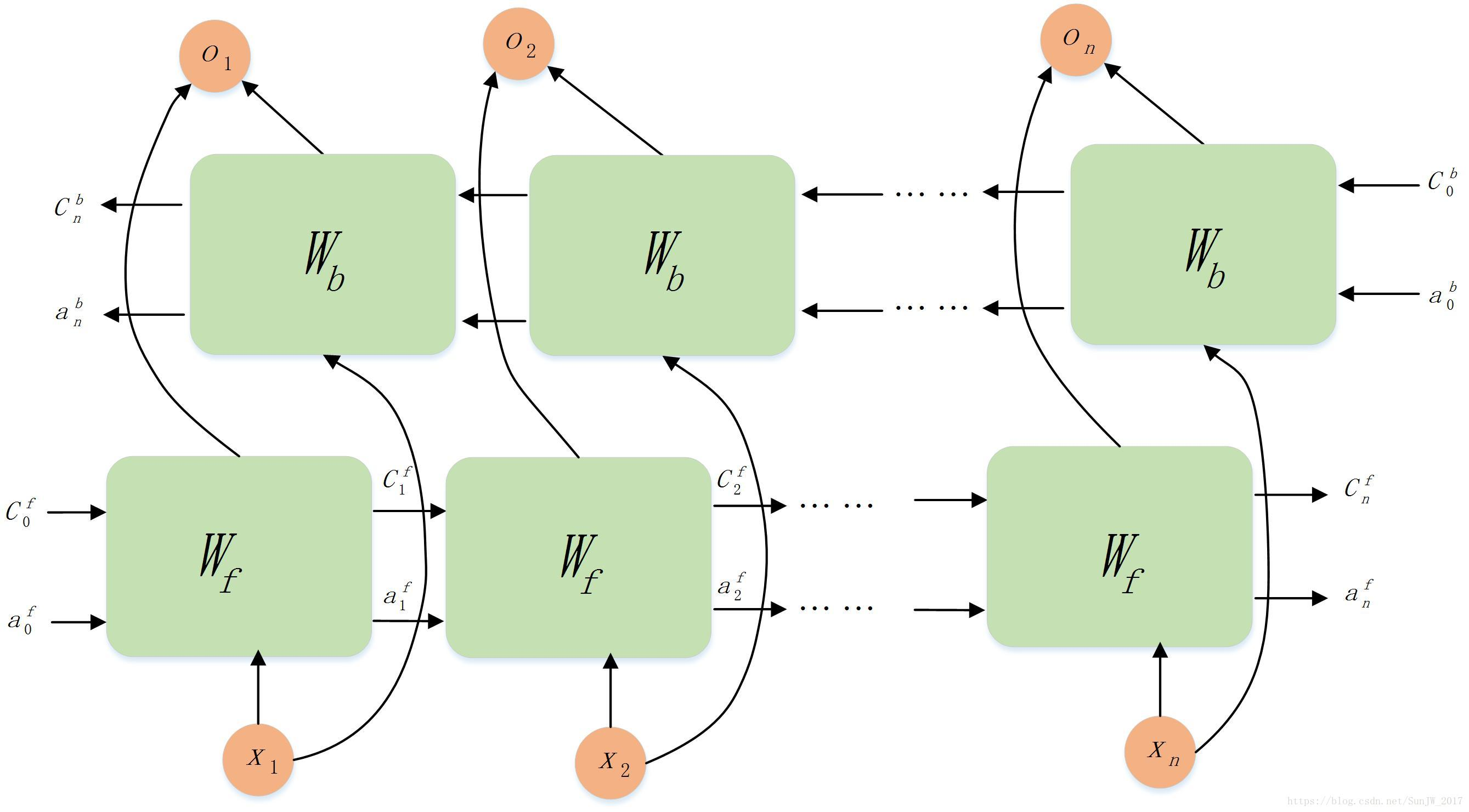
双向LSTM
类似于双向RNN,结构图如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号