

NLP常用损失函数
参考博客
https://blog.csdn.net/WinterShiver/article/details/103021569
https://zhuanlan.zhihu.com/p/58883095
https://blog.csdn.net/jclian91/article/details/115876393
常用的损失函数总结
loss一般是正的,训练过程中越来越小。
0-1 loss
- 应用场景:回归问题
- 只要预测值和标签值不相等或者差距大于阈值,loss+=1
- 直接对应分类判断错误的个数,属于非凸函数

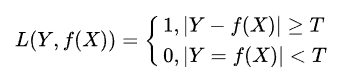
abs loss(绝对值损失)
- 计算预测值与目标值的差的绝对值。
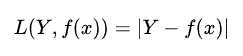
Mean Absolute Error(MAE)
- 也就是L1范数
- 应用场景:一般用于回归问题
- 在绝对值损失的基础上算平均值。
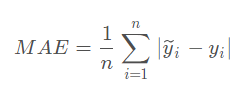
- pytorch实现代码如下:

square loss(平方损失)
- 应用场景:分类问题和回归问题都可以,经常应用于回归问题
- 预测和标签对应,然后求差的平方,累加起来就是平方损失
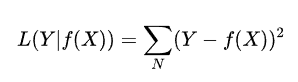
Mean Squared Error(MSE,均方差损失)
- 也叫做L2范数
- 应用场景:一般用于回归问题
- 预测和标签一一对应。在平方损失的基础上算了个平均值。
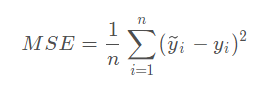
- Pytorch实现代码如下:
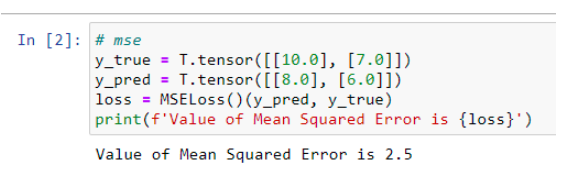
hinge loss(合页损失函数)
- 应用场景:N分类问题
- loss输入:模型输入一个N维向量为分类结果,针对这个向量计算loss.(这个N维向量一般是一个全连接层(线性层)的输出,是模型对于每个类别的打分。)不仅要分类正确,而且确信度要足够高。
-
向量的每个分量和正确分类的分量比较,如果差的不多甚至超过(说明有混淆),则在loss中反映出来。在下面的公式中, i 是正确的类别, t是阈值(一般为1,或是某个计算出来的平均值)。

或者
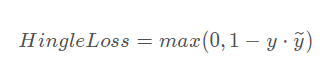
- pytorch的实现:

softmax loss
- 应用场景:N分类问题
- 模型输出一个N维向量,为模型预测的分类概率。
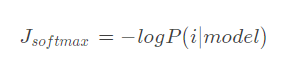
关于softmax可以参考:https://www.zhihu.com/question/23765351
cross entropy loss(交叉熵损失函数)
- 应用场景:NLP中很常用
多分类中如下,(应该在前面再求个平均)
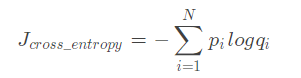
二分类中也可以表示为:
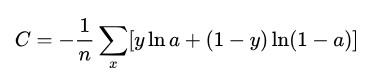
y为实际的标签,a为预测的,求和的两项只会有一项存在。
相关问题
交叉熵与最大似然函数的联系和区别
- 区别:交叉熵函数使用来描述模型预测值和真实值的差距大小,越大代表越不相近;似然函数的本质就是衡量在某个参数下,整体的估计和真实的情况一样的概率,越大代表越相近。
- 联系:交叉熵函数可以由最大似然函数在伯努利分布的条件下推导出来,或者说最小化交叉熵函数的本质就是对数似然函数的最大化。
使用sigmoid作为激活函数的时候,应该用交叉熵损失函数,而不能用均方误差损失函数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号