
对抗训练
参考博客
有pytorch的实现,开箱即食:https://zhuanlan.zhihu.com/p/91269728
原理的说明更容易理解,而且覆盖的对抗训练方法更多更广更新:https://zhuanlan.zhihu.com/p/103593948
本博客主要是基于自己的理解过程,结合一下上面的两篇大佬的博客。
关于对抗
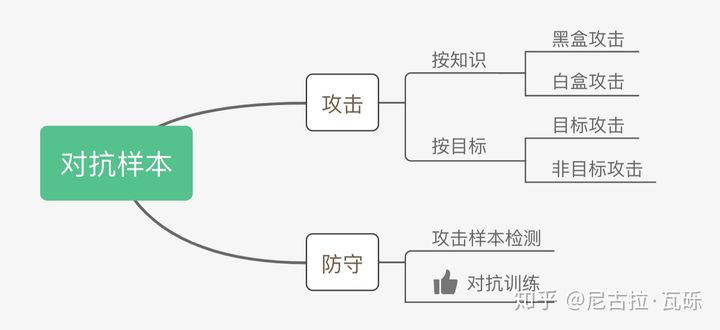
对抗样本可以用来攻击和防御,对抗训练属于对抗样本用于防御的一种方式。
对抗样本一般具有两个特点:
- 相对于原始输入,所添加的扰动是微小的。(人工仍可识别)
- 能使模型犯错
对抗训练
对抗训练的作用:
- 几行代码就可以提升模型泛化能力。对抗训练通过引入噪声以对参数进行正则化,提高泛化能力。
- 提高模型应对对抗样本时的鲁棒性
对抗训练的基本原理:通过添加扰动构造一些对抗样本,给模型训练,以提高模型在遇到对抗样本时的鲁棒性,同时一定程度提高模型的表现和泛化能力。
对抗训练假设:给输入加上扰动之后,输出分布和原分布一致。
有监督的数据下使用交叉熵作为损失:
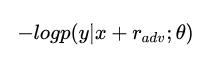
加上扰动后,用其进行训练,问题相当于
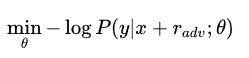
扰动的设置需要对抗的思想,往增大损失的方向增加扰动,得到的对抗样本就能得到更大的损失以提高模型的错误率:
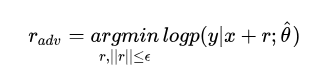
半监督下使用KL散度也是一样的。
用一句话形容对抗训练的思路,就是在输入上进行梯度上升(增大loss),在参数上进行梯度下降(减小loss)。由于输入会进行embedding lookup,所以实际的做法是在embedding table上进行梯度上升。
也相当于Min-Max公式,

该公式等于内部损失函数的最大化(输入上),外部经验风险的最小化(参数上)。
- 内部max是为了找到最差情况,worst-case,也就是攻击
- 外部min是基于最差情况找到最鲁棒的模型参数,也就是防御
FGM(Fast Gradient Method)
假设输入的文本序列的embedding vectors 为
,embedding的扰动为:
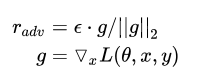
g表示的是梯度(gradient), 用梯度的二范式做了一个scale
伪代码如下:

大佬实现的pytorch版本如下:
import torch class FGM(): def __init__(self, model): self.model = model self.backup = {} def attack(self, epsilon=1., emb_name='emb.'): # emb_name这个参数要换成你模型中embedding的参数名 for name, param in self.model.named_parameters(): if param.requires_grad and emb_name in name: self.backup[name] = param.data.clone() norm = torch.norm(param.grad) if norm != 0 and not torch.isnan(norm): r_at = epsilon * param.grad / norm param.data.add_(r_at) def restore(self, emb_name='emb.'): # emb_name这个参数要换成你模型中embedding的参数名 for name, param in self.model.named_parameters(): if param.requires_grad and emb_name in name: assert name in self.backup param.data = self.backup[name] self.backup = {}
需要使用对抗训练时,只需要添加五行代码:
# 初始化 fgm = FGM(model) for batch_input, batch_label in data: # 正常训练 loss = model(batch_input, batch_label) loss.backward() # 反向传播,得到正常的grad # 对抗训练 fgm.attack() # 在embedding上添加对抗扰动 loss_adv = model(batch_input, batch_label) loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度 fgm.restore() # 恢复embedding参数 # 梯度下降,更新参数 optimizer.step() model.zero_grad()
PGD(Projected Gradient Descent)
FGM直接通过epsilon参数一下子算出了对抗扰动,这样得到的可能不是最优的。因此PGD进行了改进,多迭代几次,慢慢找到最优的扰动。简单的说,就是“小步走,多走几步”,如果走出了扰动半径为 的空间,就映射回“球面”上,以保证扰动不要过大:
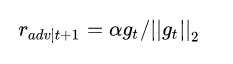
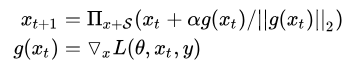
g还是梯度,α为小步的步长
伪代码如下:

可以看到,在循环中r是逐渐累加的,要注意的是最后更新参数只使用最后一个x+r算出来的梯度。
大佬实现的pytorch版本如下:
import torch class PGD(): def __init__(self, model): self.model = model self.emb_backup = {} self.grad_backup = {} def attack(self, epsilon=1., alpha=0.3, emb_name='emb.', is_first_attack=False): # emb_name这个参数要换成你模型中embedding的参数名 for name, param in self.model.named_parameters(): if param.requires_grad and emb_name in name: if is_first_attack: self.emb_backup[name] = param.data.clone() norm = torch.norm(param.grad) if norm != 0 and not torch.isnan(norm): r_at = alpha * param.grad / norm param.data.add_(r_at) param.data = self.project(name, param.data, epsilon) def restore(self, emb_name='emb.'): # emb_name这个参数要换成你模型中embedding的参数名 for name, param in self.model.named_parameters(): if param.requires_grad and emb_name in name: assert name in self.emb_backup param.data = self.emb_backup[name] self.emb_backup = {} def project(self, param_name, param_data, epsilon): r = param_data - self.emb_backup[param_name] if torch.norm(r) > epsilon: r = epsilon * r / torch.norm(r) return self.emb_backup[param_name] + r def backup_grad(self): for name, param in self.model.named_parameters(): if param.requires_grad: self.grad_backup[name] = param.grad.clone() def restore_grad(self): for name, param in self.model.named_parameters(): if param.requires_grad: param.grad = self.grad_backup[name]
使用的时候,代码增加如下:
pgd = PGD(model) K = 3 for batch_input, batch_label in data: # 正常训练 loss = model(batch_input, batch_label) loss.backward() # 反向传播,得到正常的grad pgd.backup_grad() # 对抗训练 for t in range(K): pgd.attack(is_first_attack=(t==0)) # 在embedding上添加对抗扰动, first attack时备份param.data if t != K-1: model.zero_grad() else: pgd.restore_grad() loss_adv = model(batch_input, batch_label) loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度 pgd.restore() # 恢复embedding参数 # 梯度下降,更新参数 optimizer.step() model.zero_grad()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号