PyTorch环境安装与基础学习
 Pytorch安装与基础讲解
Pytorch安装与基础讲解
一.环境安装
1.关于环境的一些思维导图
来源-B站小土堆
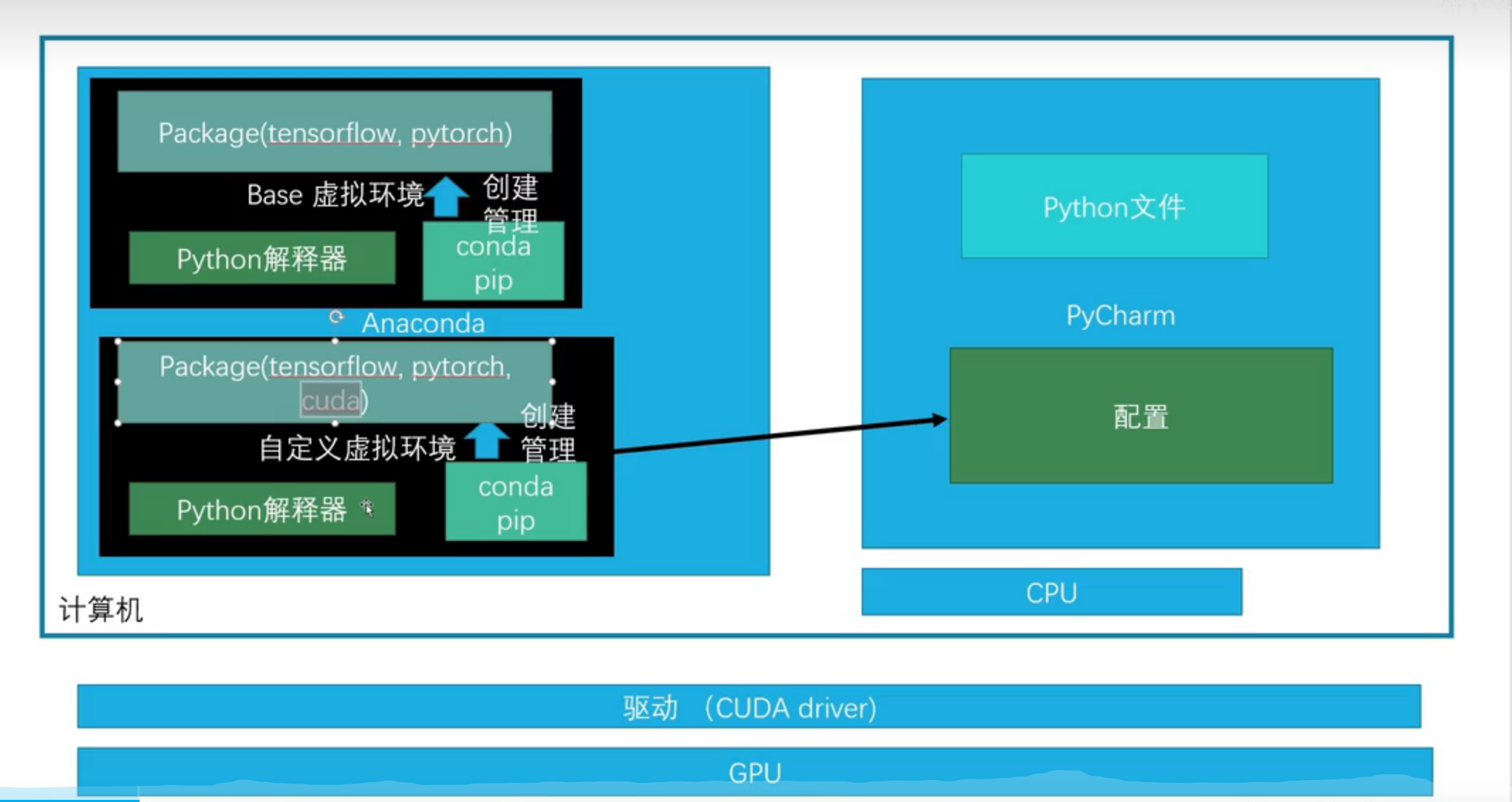
2.关于环境的搭建
Anaconda
(1) anaconda安装
安装网站(清华镜像): https://repo.anaconda.com/archive/
下载完成后打开图像化界面 Anaconda Navigator,可以看到环境中有个base
(2)创建虚拟环境
我们在做一些项目时,可能要用到不同版本的PyTorch,所以创建不同的虚拟环境是非常有必要的

step1:使用清华镜像创建虚拟环境,名称为:
mypytorch1 镜像地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
指令:
conda create -n mypytorch1 python=3.8 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/step2:下载成功,如下所示,使用
conda env list指令查看环境列表

(3) conda的通道与镜像地址
镜像地址原理:
在anaconda下载后,在配置文件中的channel参数中有个默认的下载地址,是国外的服务器
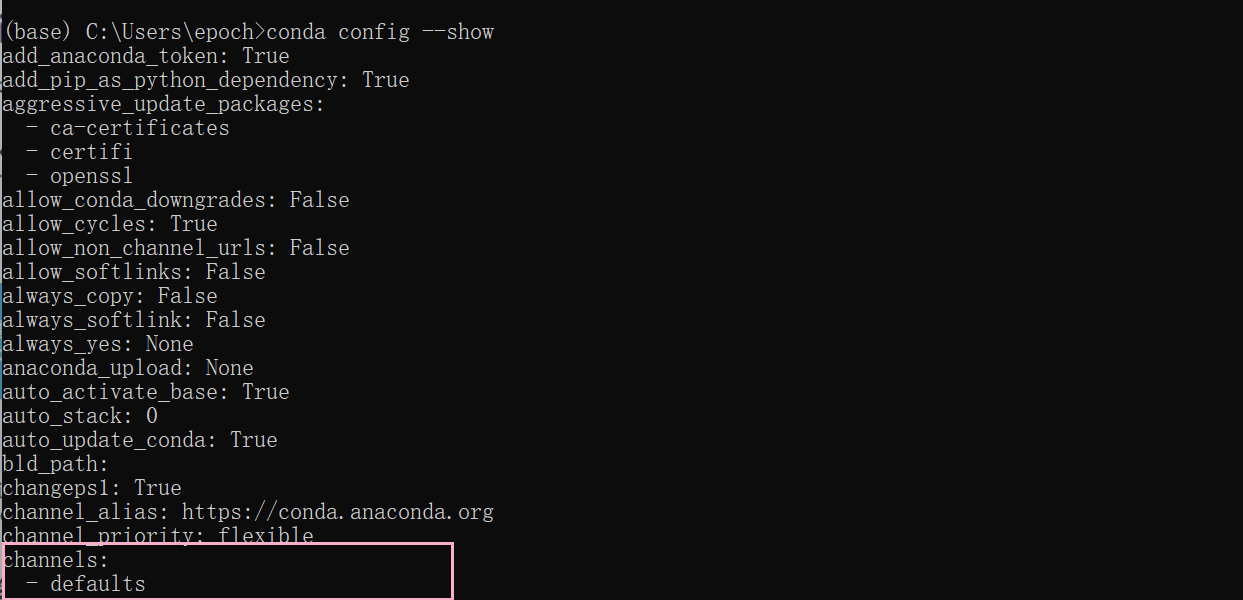
而我们可以通过添加镜像地址(通道地址)来实现镜像下载

CUDA
1.准备工作
1)概念梳理

2)关于显卡算力
查看网址(需外网):CUDA - Wikipedia
| Compute capability (version) | GPUs | GeForce | Quadro, NVS |
|---|---|---|---|
| 8.6 | GA102, GA103, GA104, GA106, GA107 | GeForce RTX 3090 Ti, RTX 3090, RTX 3080 Ti, RTX 3080 12GB, RTX 3080, RTX 3070 Ti, RTX 3070, RTX 3060 Ti, RTX 3060, RTX 3050, RTX 3050 Ti(mobile), RTX 3050(mobile), RTX 2050(mobile), MX570 |
RTX A6000, RTX A5500, RTX A5000, RTX A4500, RTX A4000, RTX A2000 RTX A5000(mobile), RTX A4000(mobile), RTX A3000(mobile), RTX A2000(mobile) |
3)cuda版本与支持的算力
- CUDA SDK 11.1 – 11.4 support for compute capability
3.5 – 8.6(Kepler (in part), Maxwell, Pascal, Volta, Turing, Ampere (in part)).[38] - CUDA SDK 11.5 – 11.7.1 support for compute capability
3.5 – 8.7(Kepler (in part), Maxwell, Pascal, Volta, Turing, Ampere).[39]
4)查看自己的驱动 CUDA Driver Version-11.6
命令:nvidia-smi
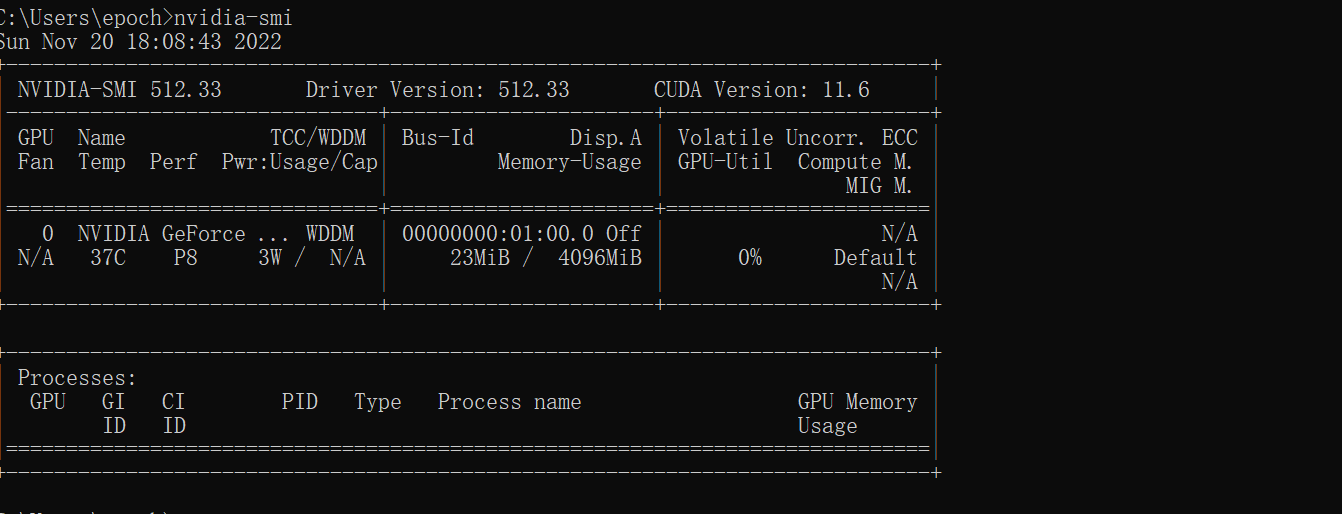
5)最终适用CUDA 11.1-11.6之间均可以
2.NVIDIA驱动程序安装
最好到官网 https://www.nvidia.com/Download/index.aspx?lang=cn 去安装最新版本的驱动
PyTorch安装
首先要conda activate mypytorch1进入自己的虚拟环境
下载地址:[PyTorch](https://pytorch.org/)
指令:pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116

安装完成后可以通过pip list来查看packages中是否有torch包
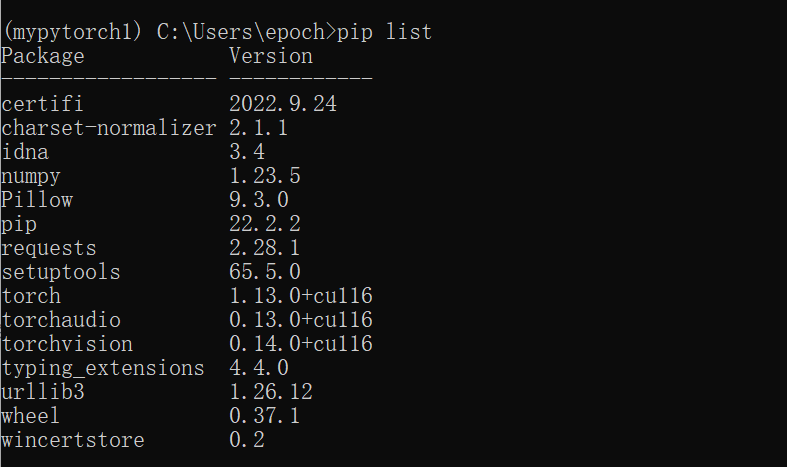
验证是否安装成功
1.输入python
2.输入import torch
3.输入torch.cuda.is_available()
4.如果显示True, 就说明我们安装成功

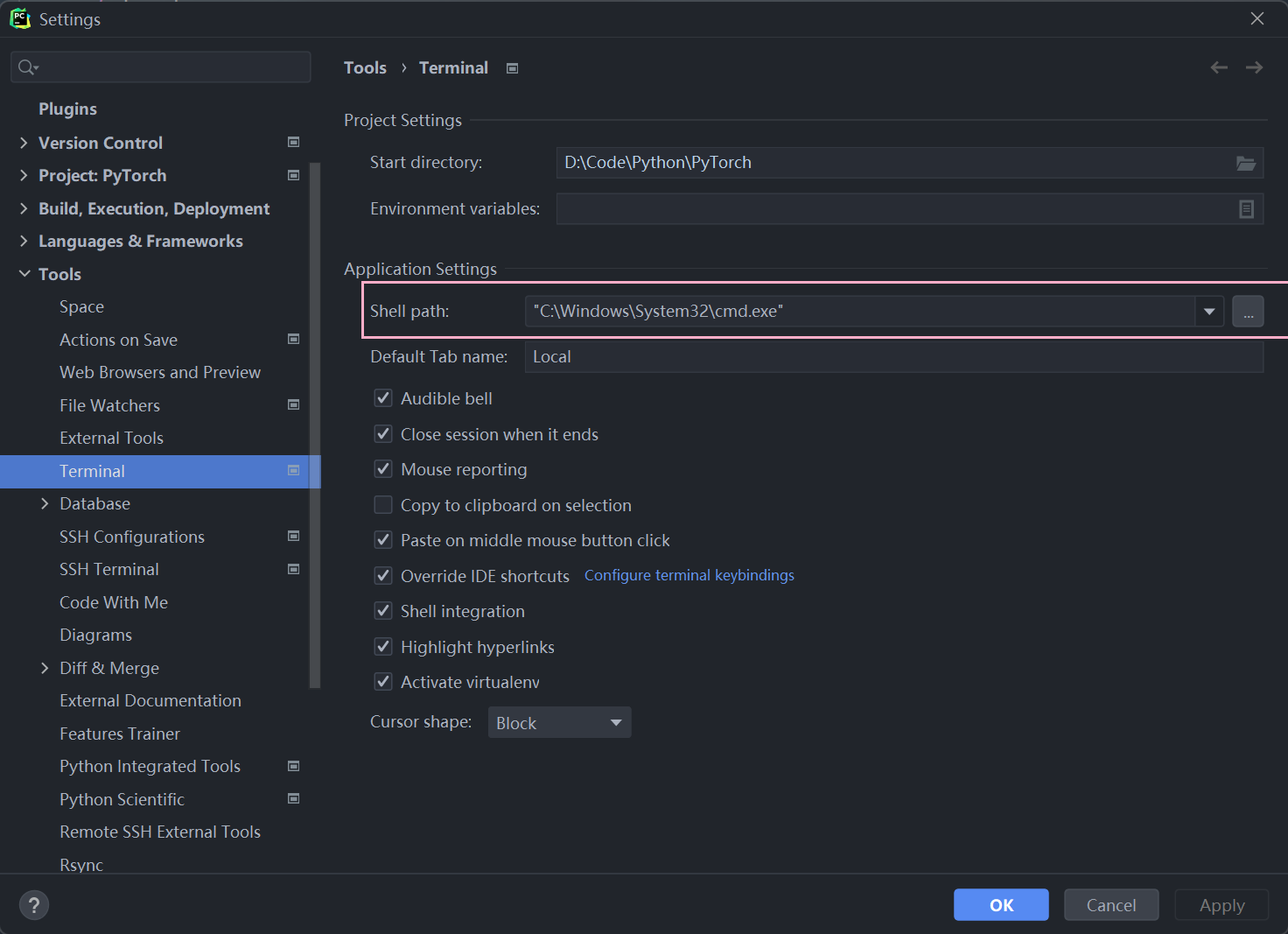
Pycharm中使用
在pycharm中可以将我们的terminal定位到我们安装torch的虚拟环境mypytorch中
在jupyter notebook中添加虚拟环境
1.首先要激活(进入)虚拟环境
conda activate 虚拟环境名称
2.pip install ipykernel ipython
3.ipython kernel install --user --name mypytorch1
4.如果以后想要删除虚拟环境jupyter kernelspec remove 虚拟环境名称
二.Pytorch的数据载体张量
1.张量的基本概念
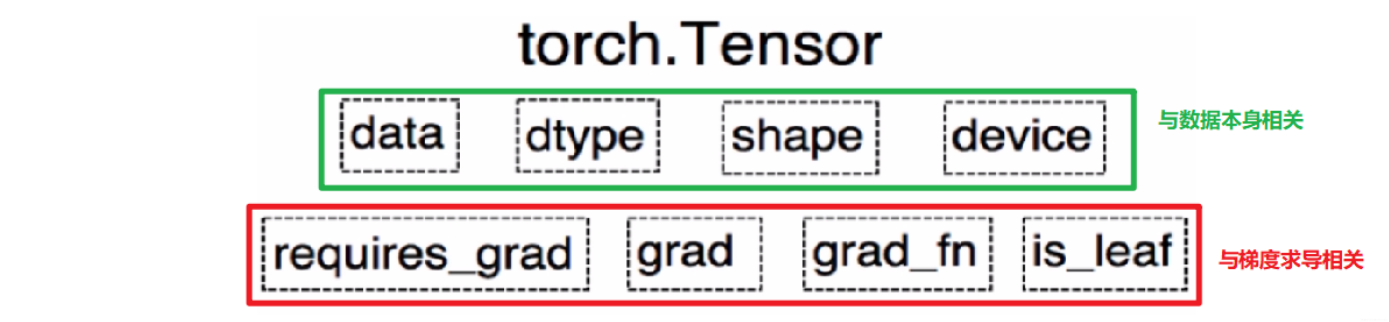
张量其实是一个多维数组,它是标量,向量和矩阵的高维拓展

目前版本的Tensor(张量)共有8个属性,上面4个与数据本身相关,下面4个与梯度求导相关
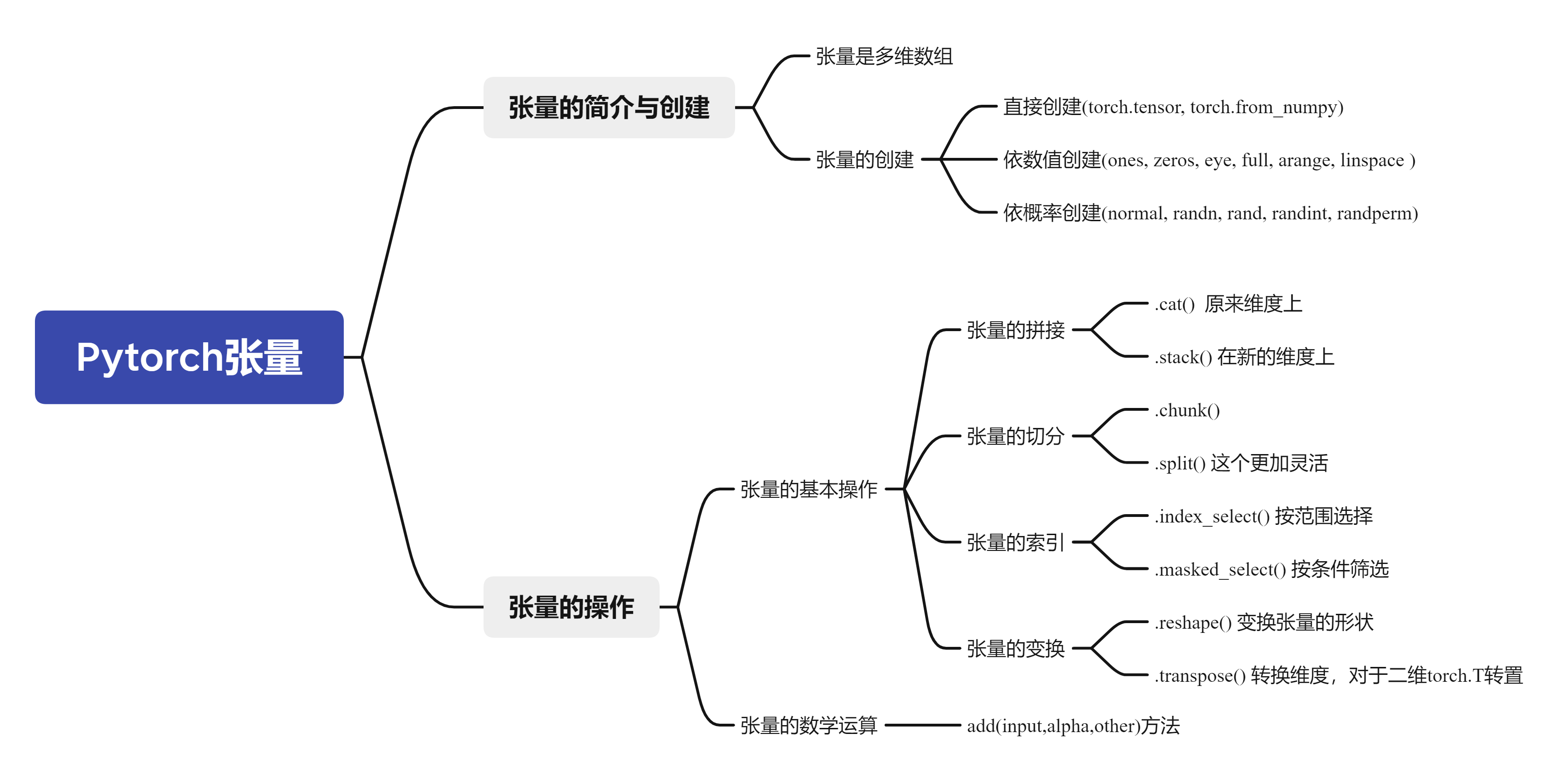
2.张量的一些基本操作
关于的操作有很多,不用刻意记忆,使用的时候边查边用
Pytorch学习博客:张量的基本操作
3.总结与思维导图
三.Pytorch的动态图与自动求导
1.计算图
计算图是用来描述运算的有向无环图。主要有两个因素:节点和边。其中节点表示数据,如向量,矩阵,张量;而边表示运算,如加减乘除,卷积等。
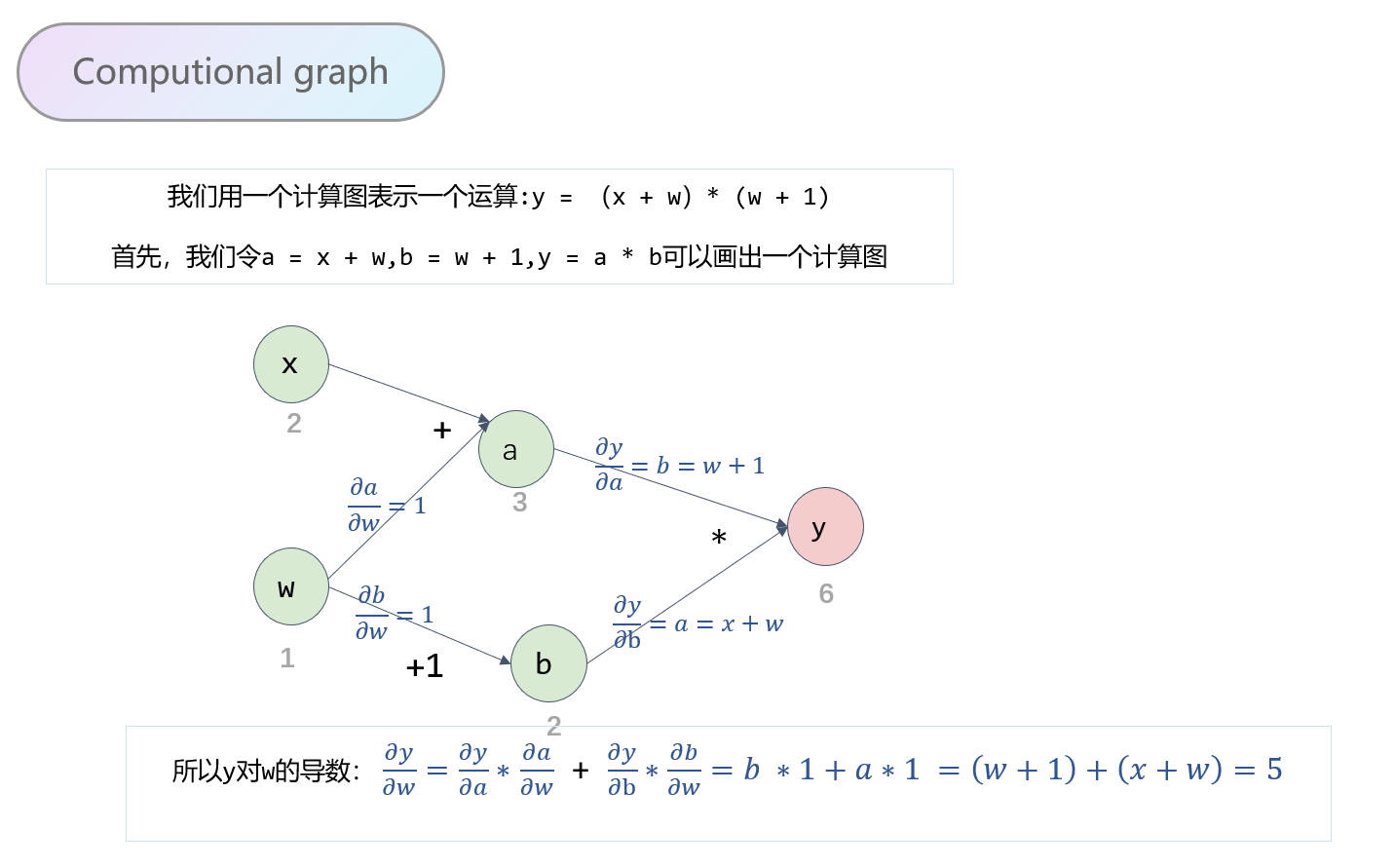
import torch
w = torch.tensor([1.],requires_grad=True)
x = torch.tensor([2.],requires_grad=True)
a = torch.add(w,x)
b = torch.add(w,1)
y = torch.mul(a,b)
y.backward()
print(w.grad) #tensor([5.])
基于计算图来说明几个张量里面重要的属性:
1. 叶子节点这个属性
叶子节点:用户创建的节点,比如上面的\(x和w\)。叶子节点是非常关键的,在正向传播和反向传播中,其实都是依赖我们叶子节点进行计算的。
is_leaf:指示张量是否是叶子节点
叶子节点的设置意义:主要是为了节省内存,因为我们在反向传播后,非叶子节点的梯度是被默认释放掉的。我们来看下面的例子:
# 查看叶子节点
print('is_leaf:\n', w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf, y.is_leaf)
# 查看梯度,默认只保留叶子节点的梯度
print('gradient\n', w.grad, x.grad, a.grad, b.grad, y.grad)
## 结果
is_leaf:
True True False False False
gradient
tensor([5.]) tensor([2.]) None None None
但是如果我们想要使用这里面非叶节点的某个梯度呢?比如我们想保留\(a\)的梯度,那么我们可以使用retain_grad()方法。就是在执行反向传播前,执行一行代码a.retain_grad()即可。
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
a.retain_grad()
b = torch.add(w, 1)
y = torch.mul(a, b)
# 反向传播
y.backward()
# 查看叶子节点
print('is_leaf:\n', w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf, y.is_leaf)
# 查看梯度,默认只保留叶子节点的梯度
print('gradient\n', w.grad, x.grad, a.grad, b.grad, y.grad)
## 结果: a的梯度被保留
gradient
tensor([5.]) tensor([2.]) tensor([2.]) None None
2 .grad_fn:记录创建张量时所用的方法(函数),记录这个方法主要用于梯度的求导
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
a.retain_grad()
b = torch.add(w, 1)
y = torch.mul(a, b)
# 反向传播
y.backward()
# 查看grad_fn 这个表示怎么得到的
print("grad_fn:\n", w.grad_fn, x.grad_fn, a.grad_fn, b.grad_fn, y.grad_fn)
# 结果:
grad_fn:
None None <AddBackward0 object at 0x000001F1260B1A90> <AddBackward0 object at 0x000001F1261FF550> <MulBackward0 object at 0x000001F125F18700>
2.Pytorch的动态图机制
- 动态图:运算与搭建同时进行,灵活,容易调节
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
print(y) #tensor([6.], grad_fn=<MulBackward0>)
这里会发现直接就算出了y的结果,这说明上面的每一步都进行了计算。
3.Pytorch的自动求导机制
Pytorch自动求导机制使用的是\(torch.autograd.backward\)方法, 功能就是自动求取梯度。

- tensors表示用于求导的张量,如loss。
- retain_graph表示保存计算图, 由于Pytorch采用了动态图机制,在每一次反向传播结束之后,计算图都会被释放掉。如果我们不想被释放,就要设置这个参数为True
- create_graph表示创建导数计算图,用于高阶求导。
- grad_tensors表示多梯度权重。如果有多个loss需要计算梯度的时候,就要设置这些loss的权重比例。
这里我们可能会有疑问:我们当时不是直接y.backward()吗? 哪有什么torch.autograd.backward()啊? 其实,当我们执行y.backward()的时候,背后其实是在调用后面的这个函数,下面我们进行调试

我们在这一行打断点,然后进行调试。 我们进入这个函数之后,会发现
def backward(self, gradient=None, retain_graph=None, create_graph=False):
torch.autograd.backward(self, gradient, retain_graph, create_graph)
这样就清楚了,这个backward函数就是在调用这个自动求导的函数
注意几个参数:
backward()里面有个参数叫做retain_graph, 这个是控制是否需要保留计算图的, 默认是不保留,即一次反向传播之后,计算图就会被释放掉,这时候,如果再次调用y.backward, 就会报错:
RuntimeErroe:Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed) #计算图已经被释放掉
这里如果我们想保留计算图,我们需要将第一次反向传播的参数retain_graph设置为True
y.backward(retain_graph=True)
另外这里面还有一个比较重要的参数grad_tensors,这个含义时当有多个梯度时,控制梯度的权重,举例如下:
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y0 = torch.mul(a, b) # y0 = (x+w)*(w+1) dy0 / dw = 5
y1 = torch.add(a, b) # y1 = (x+w)+(w+1) dy1 / dw = 2
loss = torch.cat([y0, y1], dim=0)
# 这时如果loss对w求导会有两个梯度,如果直接loss.backward会报错,因为程序不知道用哪个梯度作为w的梯度
loss.backward(retain_graph=True)
# 报错
RuntimeError: grad can be implicitly created only for scalar output # 没有指明使用哪一个梯度
上面这个过程会报错,这时候我们就需要用到gradient这个参数了, 给两个梯度设置权重,最后得到的w的梯度就是带权重的这两个梯度之和。
grad_tensors = torch.tensor([1., 1.])
loss.backward(gradient=grad_tensors)
print(w.grad) # 这时候会是tensor([7.]) 5+2
grad_tensors = torch.tensor([1., 2.])
loss.backward(gradient=grad_tensors)
print(w.grad) # 这时候会是tensor([9.]) 5+2*2
关于Pytorch的自动求导系统要注意:
- 梯度不自动清零:每一次反向传播,梯度都会自动叠加上去,这个需要特别注意
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
for i in range(4):
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
print(w.grad)
## 结果:
tensor([5.])
tensor([10.])
tensor([15.])
tensor([20.])
会发现,每次w的梯度都会累加, 执行了四次,最后是20了。这样就会发生错误了,尤其是训练神经网络的时候特别注意。毕竟我们肯定不是训练一次,所以每一次反向传播之后,我们要手动的清除梯度
# 梯度清零
w.grad.zero_()
- 依赖于叶子节点的节点,requires_grad默认为True
拿上面的计算图过来解释一下,依赖于叶子节点的节点,在上面图中w,x是叶子节点,而依赖于叶子节点的节点,其实这里说的就是a,b, 也就是a,b默认就是需要计算梯度的。 这个也好理解,因为计算w,x的梯度的时候是需要先对a, b进行求导的,要用到a, b的梯度,所以这里直接默认a, b是需要计算梯度的。 在代码中,也就是这个意思
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b) # y0=(x+w) * (w+1) dy0 / dw = 5
print(w.requires_grad, a.requires_grad, b.requires_grad) # 这里会都是True, w的我们设置了True, 而后面这里是依赖于叶子,所以默认是True
但注意,虽然依赖于叶子节点的节点是默认计算梯度的,但是非叶子节点的梯度默认是不保存的,也就是会被清空,也就是会被清空掉,所以如果想要保留下来,依然是需要再建立计算图之前使用a.retain_grad
- 叶子节点不可执行in-place(这个in-place就是原位操作)
in_place 操作是进行运算后地址不变, a= a+1 开辟新内存, 不是原位操作,a+=1 是原位操作; 由于计算图前向传播用到了叶子节点的地址,如果进行原位操作,数据就会被改变,而反向传播会用到叶子节点的数据,会根据叶子节点的地址来取出叶子节点的值,如果值改变反向传播就会计算错误
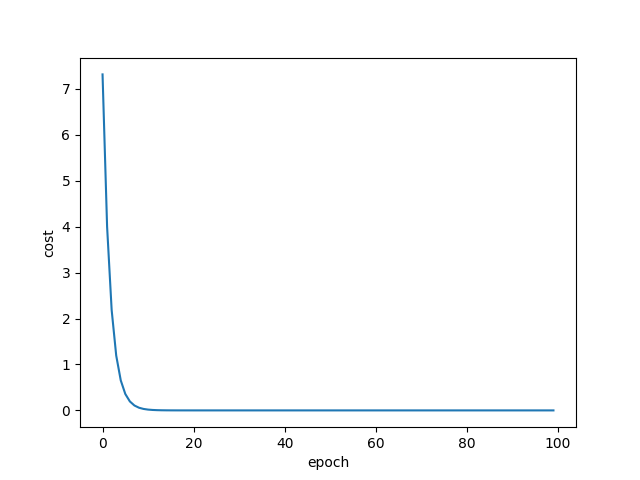
4.实战:线性回归模型
import torch
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.tensor(data=[1.0], requires_grad=True) # w的初值为1.0
# 前向传播
def forward(x):
return x * w # w是一个tensor张量
# 损失函数
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
print("predict (before training)", 4, forward(4).item())
# 记录每一次迭代的loss值
mse_list = []
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y) # l是一个张量,tensor主要是在建立计算图forward,compute the loss
l.backward() # backward,compute the grad for tensor whose requires_grad set to true
print('\tgrad', x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data # 权重更新时,注意grad也是一个张量,所以要用grad.data(这样不会建立计算图)
# 将w中记录的张量清零
w.grad.data.zero_()
mse_list.append(l.item())
print("progress:", epoch, l.item())
print("predict (after training)", 4, forward(4).item())
plt.plot(range(100), mse_list)
plt.xlabel('epoch')
plt.ylabel('cost')
plt.show()
5.思维导图
四.Pytorch数据读取机制(DataLoader)与图像处理模块(transforms)
1.Pytorch的数据读取机制
机器模型学习的五大模块:数据、模型、损失函数、优化器、迭代训练

而这里的数据读取机制,很显然是位于数据读取模块中的一个小分支
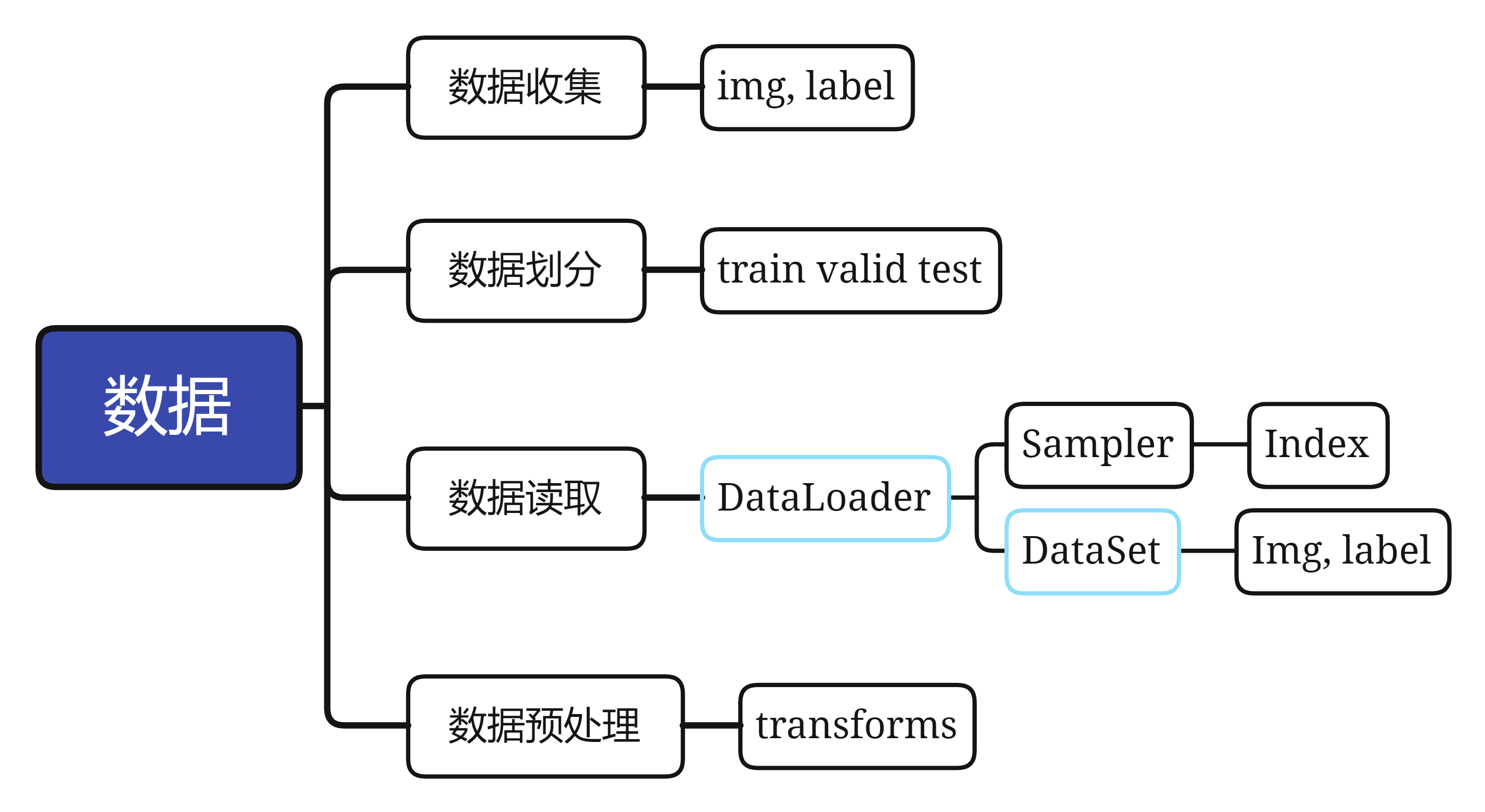
1.1 DataLoader
torch.utils.data.DataLoader(): 构建可迭代的数据装载器,我们在训练时,每一个for循环,每一次iteration,就是从DataLoader中获取一个batch_size大小的数据

DataLoader最常用的参数主要有5个:
- dataset: Dataset类, 决定数据从哪读取以及如何读取
- batch_size: 批大小
- num_works: 是否多进程读取机制
- shuffle: 每个epoch是否乱序
- drop_last: 当样本数不能被batch_size整除时, 是否舍弃最后一批数据
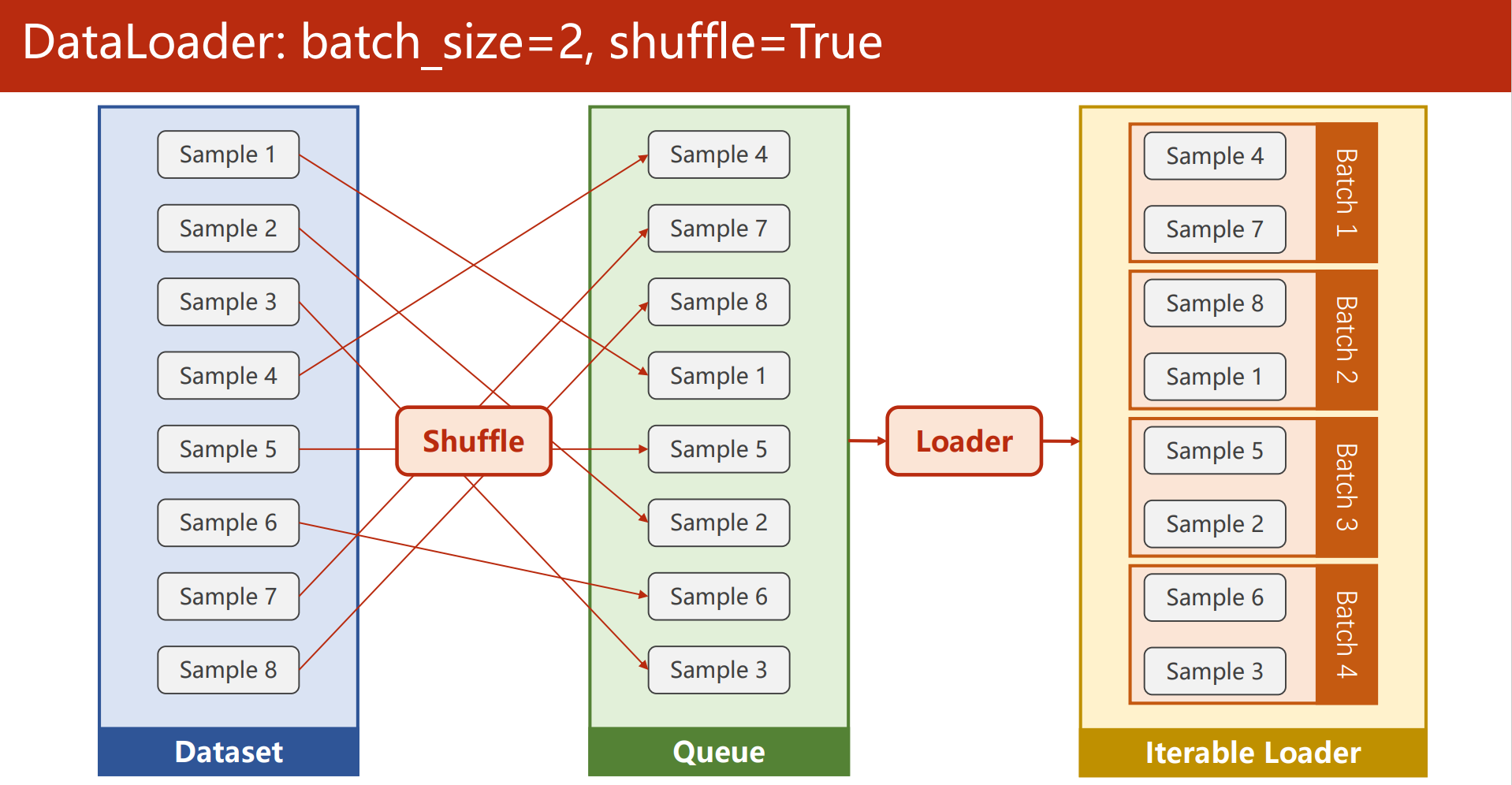
要理解这个drop_last, 首先,得先理解Epoch, Iteration和Batchsize的概念:
- Epoch: 所有训练样本都已输入到模型中,称为一个Epoch
- Iteration: 一批样本输入到模型中,称为一个Iteration
- Batchsize: 一批样本的大小, 决定一个Epoch有多少个Iteration
举例:
-
假设样本总数80, Batchsize是8, 那么1Epoch=10 Iteration。
-
假设样本总数是87, Batchsize是8, 如果drop_last=True, 那么1Epoch=10Iteration, 如果等于False, 那么1Epoch=11Iteration, 最后1个Iteration有7个样本。
1.2 Dataset
torch.utils.data.Dataset: Dataset抽象类,所有自定义的Dataset都要继承它,并且必须复写——__getitem__()这个方法
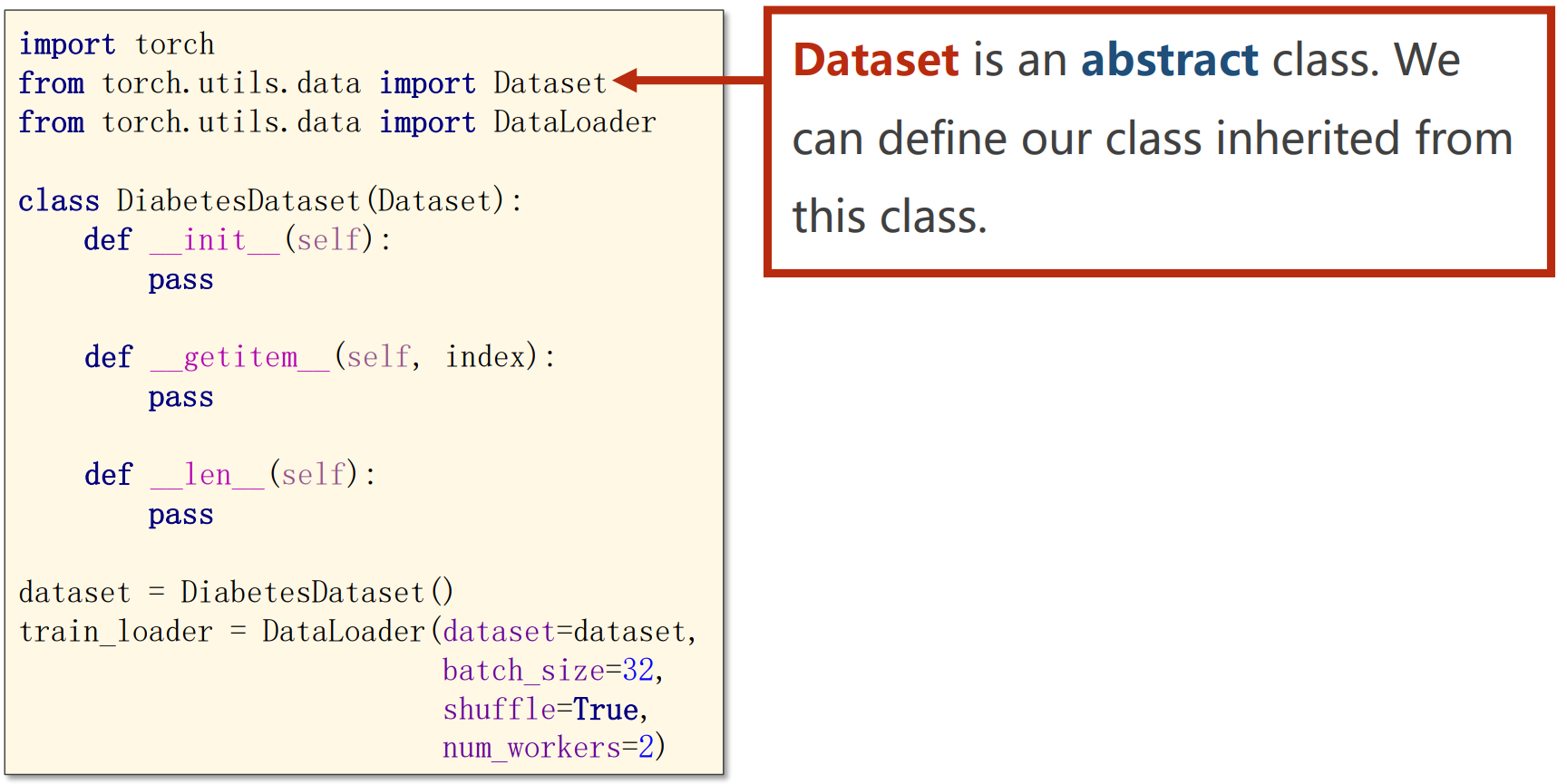
class MyData(Dataset):
"""
根据路径读取并返回图像数据和标签
"""
def __init__(self, root_dir, label_dir, transform):
self.root_dir = root_dir
self.label_dir = label_dir
self.transform = transform
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path) # 获取该路径文件夹下每一个文件的名字
def __getitem__(self, idx):
# 根据索引取到对应图片的名字
img_name = self.img_path[idx]
# 拼成图片的相对路径
img_item_path = os.path.join(self.path, img_name)
# 获得PIL Image
img = Image.open(img_item_path).convert('RGB') # 把所有图片的通道数都变为3(包括灰度图),保证图片的Channel相同
# 进行图像预处理
if self.transform is not None:
img = self.transform(img)
# 获得Image Label
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
root_dir = "../dataset/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
# 图像预处理(通过Resize保证图片的H和W)
transform = transforms.Compose([transforms.Resize((256, 256)), transforms.ToTensor(), ])
ants_dataset = MyData(root_dir, ants_label_dir, transform)
bees_dataset = MyData(root_dir, bees_label_dir, transform)
train_dataset = ants_dataset + bees_dataset
1.3 数据读取机制的工作流程
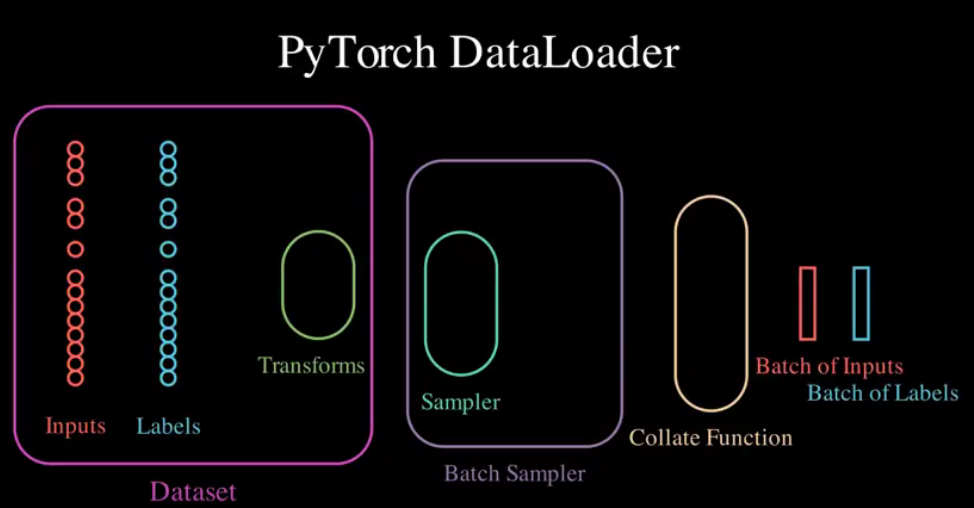
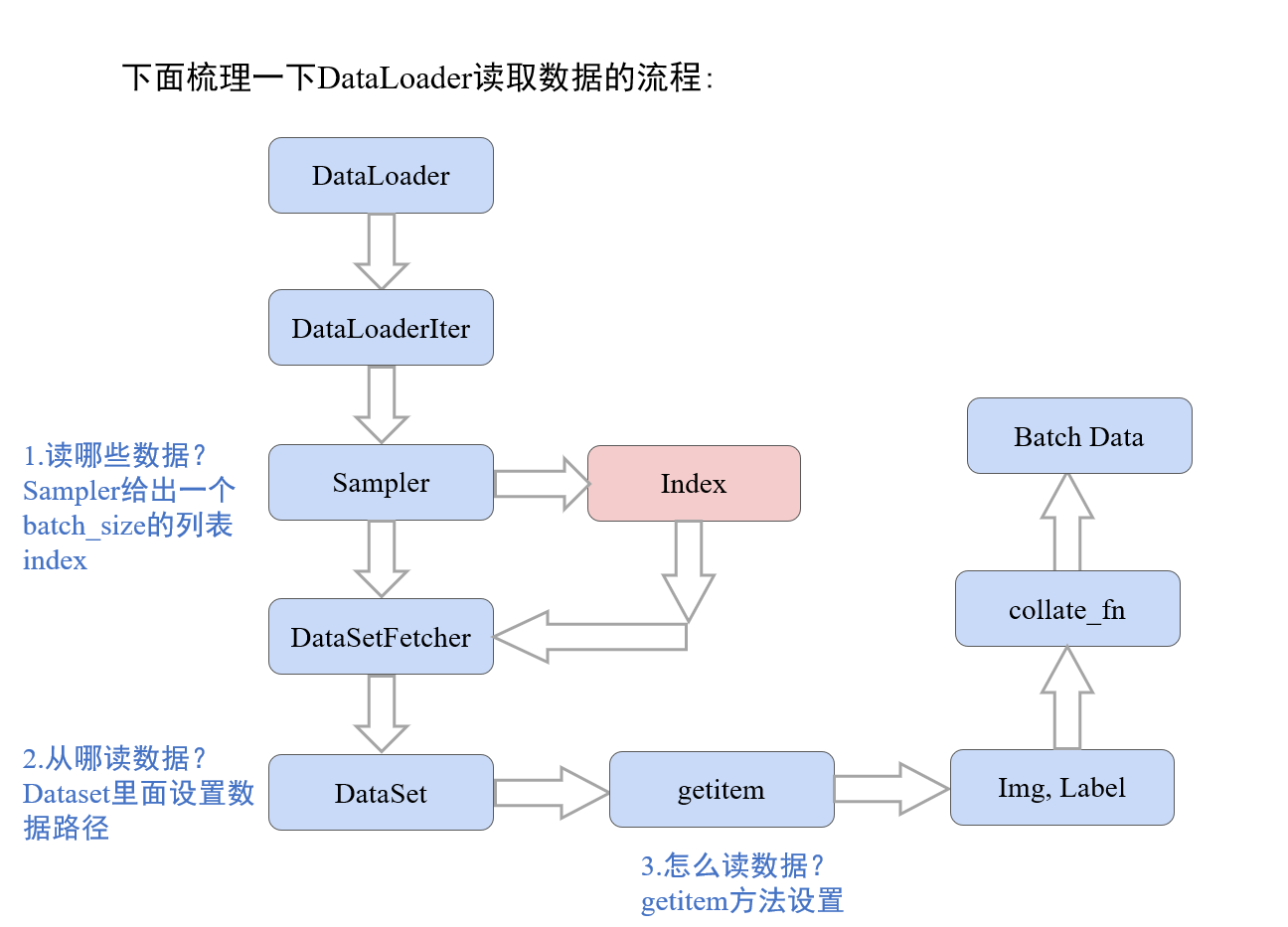
DataLoader的作用就是构建一个数据装载器,根据我们提供的batch_size的大小,将数据样本分成一个个的batch去训练模型,而这个分的过程中需要把数据取到,这个就是借助Dataset的getitem方法。
当然这里还有个细节,就是还要覆盖里面的__len__方法,这个是告诉机器一共有多少个样本数据。 要不然机器没法去根据batch_size的个数去确定有多少批数据。这个写起来也很简单,返回总的样本的个数即可。
2.Pytorch的图像预处理transforms
transforms是常用的图像预处理方法, 这个在torchvision计算机视觉工具包中,我们在安装Pytorch的时候顺便安装了这个torchvision(可以看看上面的搭建环境)。 在torchvision中,有三个主要的模块:
torchvision.transforms: 常用的图像预处理方法, 比如标准化,中心化,旋转,翻转等操作torchvision.datasets: 常用的数据集的dataset实现, MNIST, CIFAR-10, ImageNet等torchvision.models: 常用的模型预训练, AlexNet, VGG, ResNet, GoogLeNet等。
我们这次看图像预处理模块transforms, 主要包括下面的方法:
数据中心化,数据标准化,缩放,裁剪,旋转,翻转,填充,噪声添加,灰度变换,线性变换,仿射变换,亮度、饱和度及对比度变换。
2.1 常见的图像预处理方法

transforms.Compose方法是将一系列的transforms方法进行有序的组合包装,具体实现的时候,依次的用包装的方法对图像进行操作。transforms.Resize方法改变图像大小transforms.RandomCrop方法对图像进行裁剪(这个在训练集里面用,验证集就用不到了)transforms.ToTensor方法是将图像转换成张量,同时会进行归一化的一个操作,将张量的值从0-255转到0-1。下面我们看一下transforms.py文件中ToTensor类的注释:
Converts a PIL Image or numpy.ndarray (H x W x C) in the range
[0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0]
transforms.Normalize方法是将数据进行z-score标准化,标准化的公式如下所示,这种方法是将原始数据变换到均值为 0,方差为 1 的范围内。Normalize的处理作用就是有利于加快模型的收敛速度。
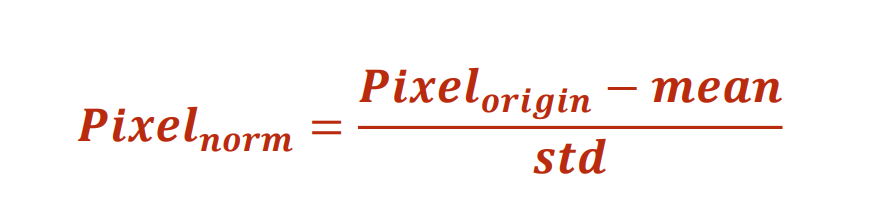
2.2 transforms的其他图像增强方法
1. 数据增强
数据增强又称为数据增广, 数据扩增,是对训练集进行变换,使训练集更丰富,从而让模型更具泛化能力

2.图像数据增强方法
- 图像裁剪
- 图像的翻转和旋转
- 图像变换
具体的方法看这一篇博客:Pytorch数据读取机制(DataLoader)与图像预处理模块(transforms)
3.数据增强策略原则: 让训练集与测试集更接近。
- 空间位置上: 可以选择平移
- 色彩上: 灰度图,色彩抖动
- 形状: 仿射变换
- 上下文场景: 遮挡,填充

 浙公网安备 33010602011771号
浙公网安备 33010602011771号