Python基础学习
1.数组类型转换
| 函数名 | 作用 | 注意事项 | 举例 |
|---|---|---|---|
| str() | 将其他类型数据转换为字符串 | 也可以用引号转换 | str(123) 或者'123' |
| int | 将其他类型数据转换为整数 | 1.文字类和小数类字符串,无法转换为整数 2.浮点数转换为整数,抹零取整 | int('123') int(9.8) |
| float(0) | 将其他类型数据转换为浮点数 | 1.文字类无法转换为整数 2.整数转换为浮点数,末尾为0 | float('9.9') float(9) |
2.for-in循环
-
for-in循环
-
in 表达从(字符串、序列等)中依次取值,又称为遍历
-
for-in遍历的对象必须是可迭代对象
-
-
for-in的语法结构
- for 自定义的变量 in 可迭代对象:循环体

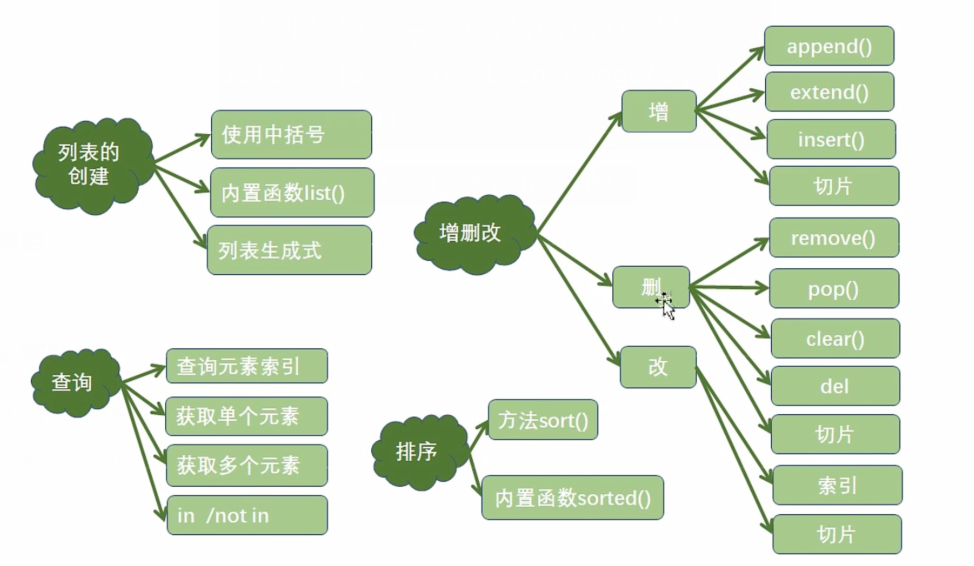
3.四种数据结构
1.列表
(1)列表的内存表示
- 列表对象中存储的并不是变量对象,而是指向变量对象的引用
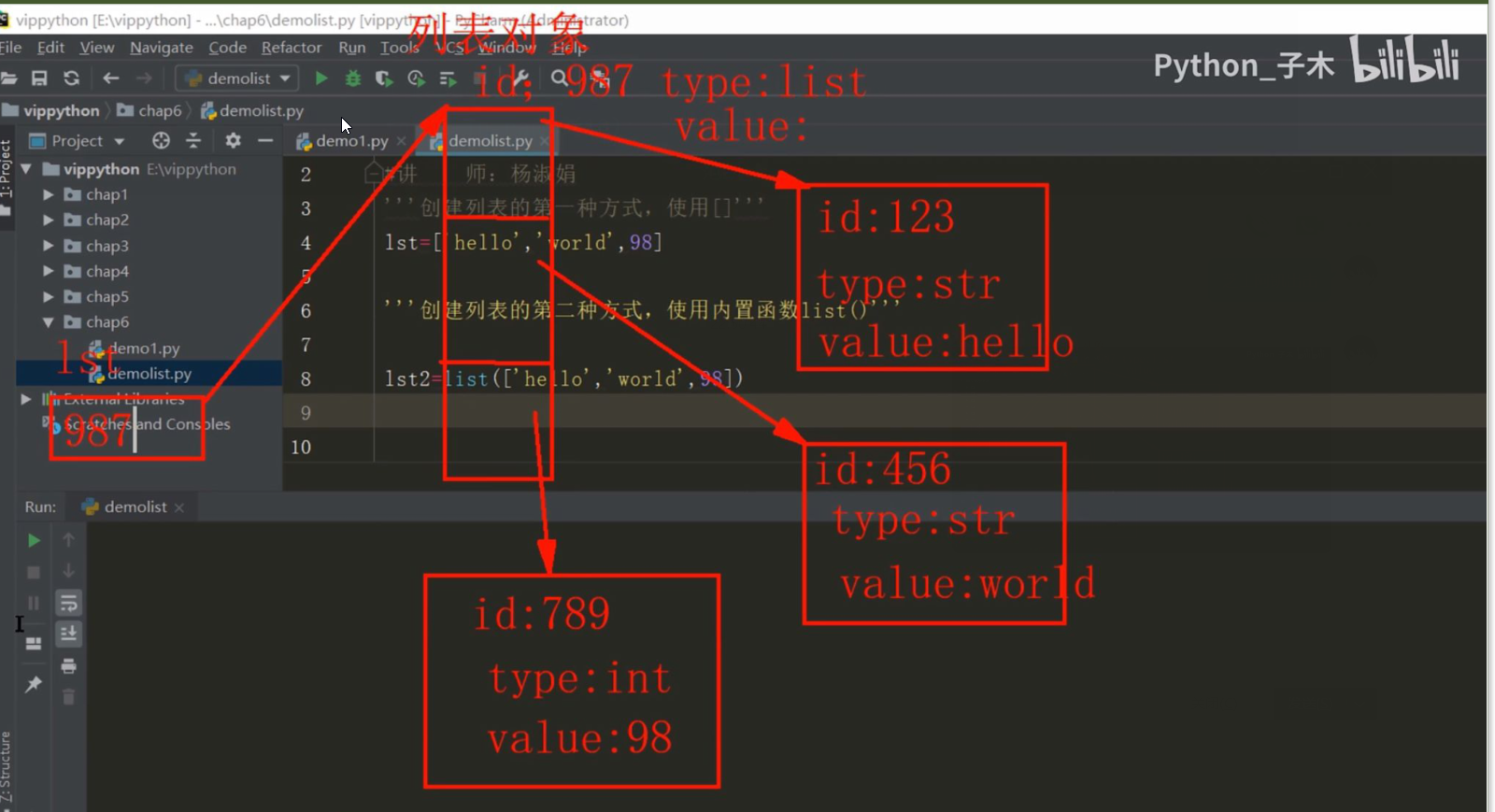
(2)列表的使用方法
- 方法一:使用[]来创建列表
- 方法二:使用内置函数list()来创建列表

(3)列表的特点
-
列表元素按顺序有序排列
-
索引映射唯一一个数据
-
列表可以存储重复的数据
-
任意数据类型混存
-
根据需要动态分配和回收内存
(4)列表的查询操作
-
获取列表中指定元素的索引:index()
-
如查列表中存在N个相同元素,只返回相同元素中的第一个元素的索引
-
如果查询的元素不存在,则会抛出ValueError
-
还可以在指定的start和stop之间进行查找
-
-
获取列表中的单个元素
- 正向索引从0到N-1,举例lst[0]
- 逆向索引从-N到-1,举例lst[-N]
- 指定索引不存在,抛出indexError
-
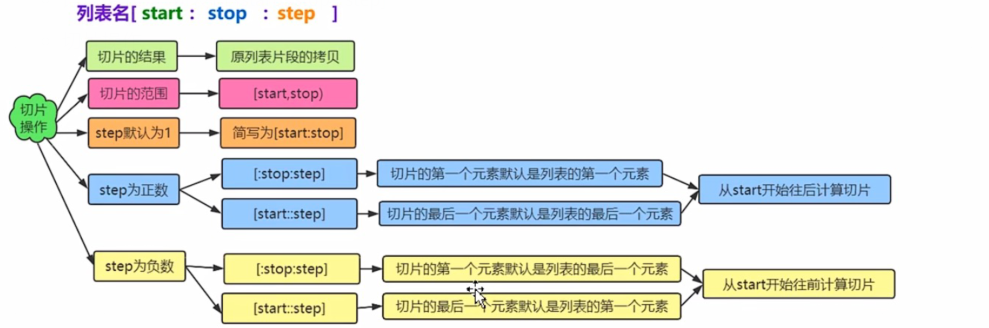
获取列表中的多个元素
-
语法格式:列表名 {start : stop : step]
-
切片操作
-
-
判断指定元素在列表中是否存在
元素 in 列表名 元素 not in 列表名
-
列表元素的遍历
for 迭代变量 in 列表名:操作
(5)列表元素的增加操作
| 方法 | 操作描述 |
|---|---|
| append() | 在列表的末尾添加一个元素 |
| extend() | 在列表的末尾添加至少一个元素 |
| insert() | 在列表的任意位置添加一个元素 |
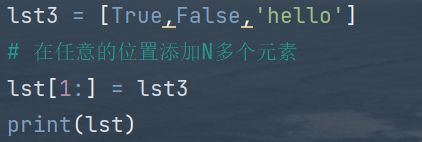
| 切片 | 在列表的任意位置添加至少一个元素 |
tips:关于切片
将列表lst3的内容赋值到了列表lst下标1的位置及之后,变量的旧值被赋值后的新值所替换掉

(6)列表元素的删除操作
| 方法 | 操作描述 |
|---|---|
| 一次删除一个元素 | |
| remove() | 重复元素只删除第一个 |
| 元素不存在抛出ValueError | |
| 删除一个指定索引位置上的元素 | |
| Pop() | 指定索引不存在抛出IndexError |
| 不指定索引,删除列表中最后一个元素 | |
| 切片 | 一次至少删除一个元素 |
| clear() | 清空列表 |
| del | 删除列表 |
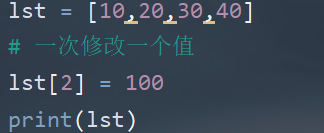
(7)列表元素的修改操作
-
为指定索引的元素赋予一个新值

-
为指定的切片赋予一个新值


(8)列表元素的排序操作
- 常见的两种方式
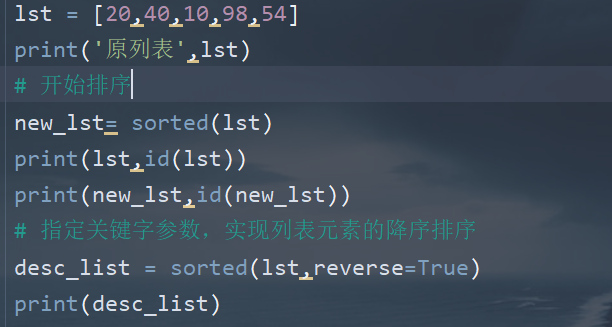
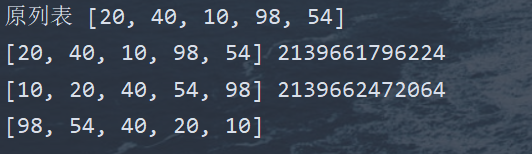
- 调用sort()方法,列表中的所有元素默认按照从小到大的顺序进行排序,可以指定reverse = True,进行降序排序
- 调用内置函数sorted(),可以指定reverse = True,进行降序排序,原列表不发生改变,将产生一个新的列表对象
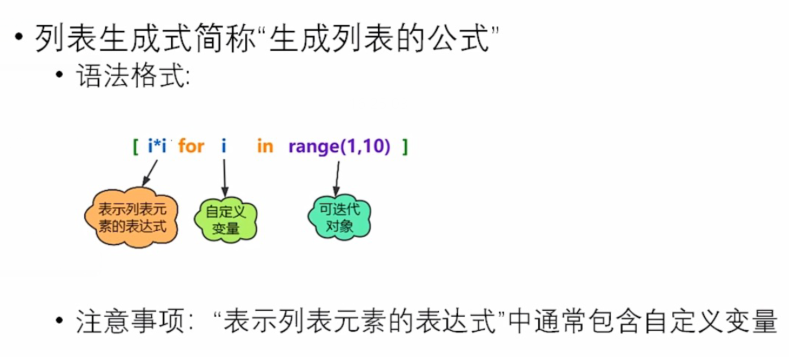
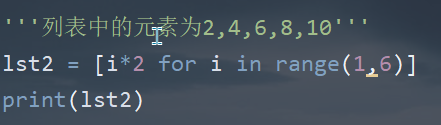
(9)列表生成式

总结
2.字典
(1) 字典的定义
- 字典与列表一样是一个 可变序列
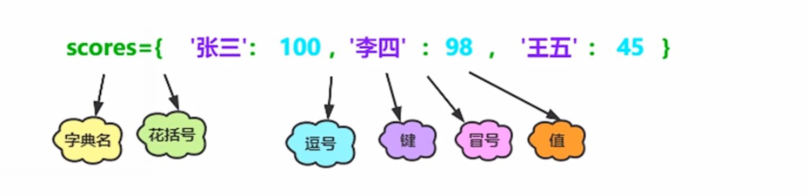
- 字典以键值对的方式存储数据
- 字典是一个无序的序列
- 字典中的所有元素都是一个Key-value对,key不允许重复,value可以重复
(2)字典的创建
-
最常用的方式:使用花括号{}

-
使用内置函数dict()

(3)字典中元素的获取
-
[] 方法:
scores['张三'] -
get()方法:
scores.get('张三') -
[]取值与使用get()取值的区别:
- []如果字典中不存在指定的Key,抛出KeyError异常
- get()方法取值,如果字典中不存在指定的Key,并不会抛出KeyError而是返回None,可以通过参数设置默认的value,以便指定的Key不存在时返回
(4)获取字典视图的三个方法
| 方法 | 操作描述 | |
|---|---|---|
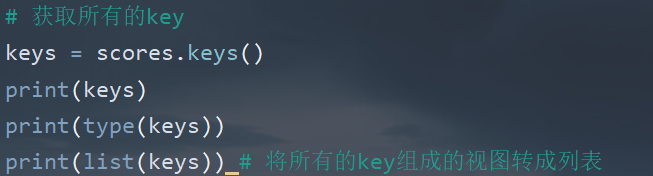
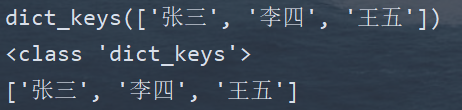
| keys() | 获取字典中所有key | |
| 获取字典视图 | values() | 获取字典中所有value |
| items | 获取字典中所有key,value对 |
- keys()方法
- values()方法
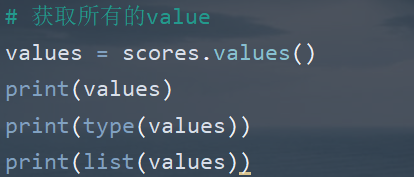
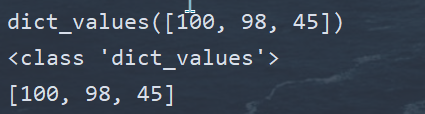
(5)字典元素的遍历
for item in scores:
print(item)

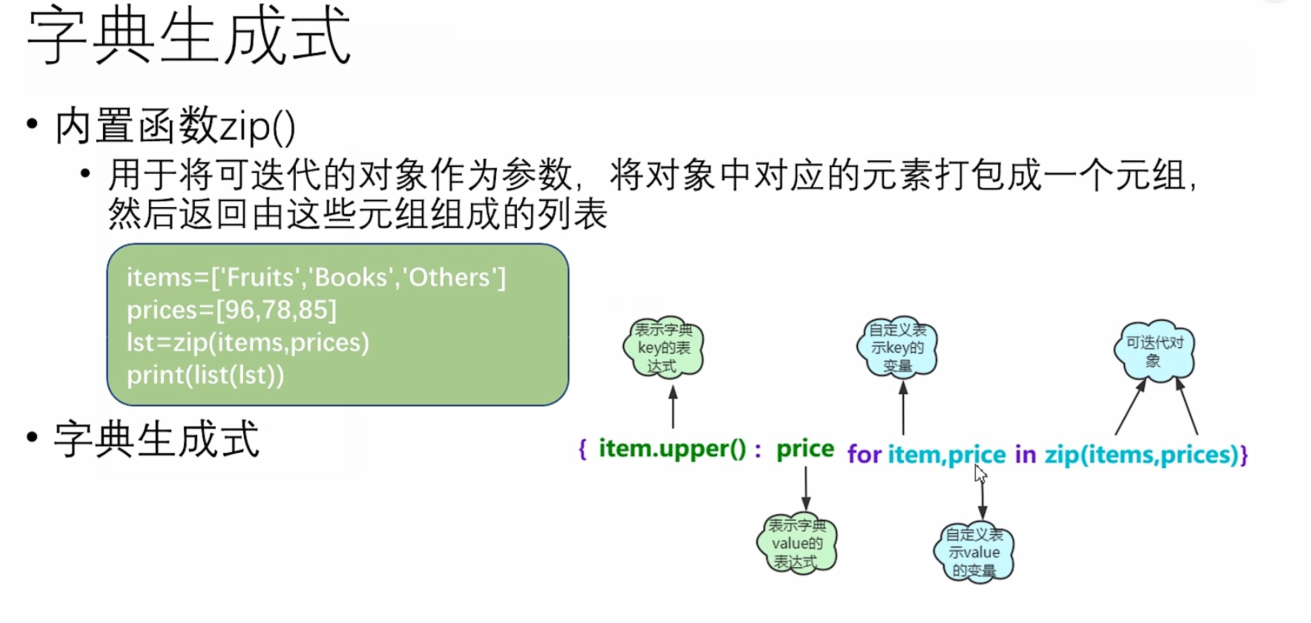
(6)字典生成式
3.元组
(1)定义
- 元组是一个不可变序列
- 注意事项:元组中存储的是对象的引用
- 如果元组中对象是不可变对象,则不能再引用其他对象
- 如果元组中对象时可变对象,则可变对象的引用不允许改变,但数据可以改变
(2)创建方式
-
直接小括号
t = ('Python','hello',90) -
使用内置函数tuple()
t = tuple(('Python','hello',90)) -
只包含一个元组的元素需要使用逗号和小括号
t = (10,)
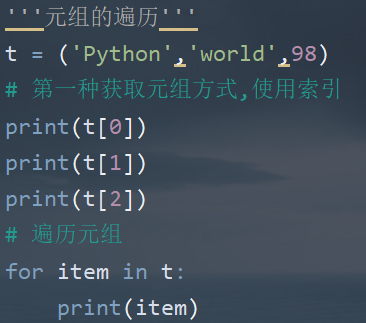
(3)遍历方式
4.集合
(1)定义
- 与列表、字典一样都属于可变类型的序列
- 集合是没有value的字典
- 集合是无序的
(2)创建方式
-
直接使用{}
s = {'Python','hello',90} -
使用内置函数set()
(3)相关操作
-
集合元素的判断操作
- in或者Not in
-
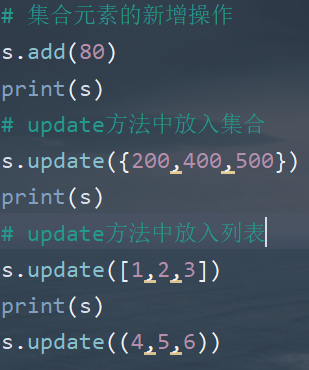
集合元素的新增操作
- 调用add()方法,一次添中一个元素
-
调用update()方法至少添中一个元素
- update的参数可以是集合、列表和元组
-
集合元素的删除操作
- 调用remove()方法,一次删除一个指定元素,如果指定的元素不存在抛出KeyError
- 调用discard()方法,一次删除一个指定元素,如果指定的元素不存在不抛出异常
- 调用Pop()方法,一次只删除一个任意元素
- 调用clear()方法,清空集合
(4)集合之间的关系
-
两个集合是否相等
- 可以使用运算符==或!=进行判断
-
一个集合是否是另一个集合的子集
-
可以调用方法issubset进行判断
-
一个集合是否是另一个集合的超集
-
可以调用方法issuperset 进行判断
-
两个集合是否没有交集
- 可以调用方法isdisjoint 进行判断
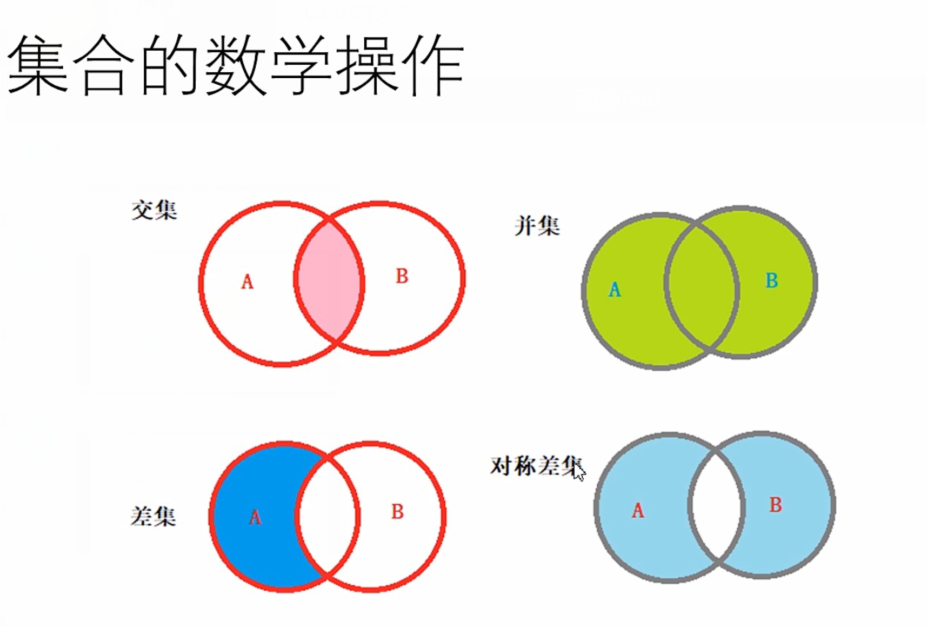
(5)集合的数学操作
(6)集合生成式
-
用于生成集合的公式
{i*i for i in range(1,10)} -
将{}改为[]就是列表生成式
-
没有与元组生成式
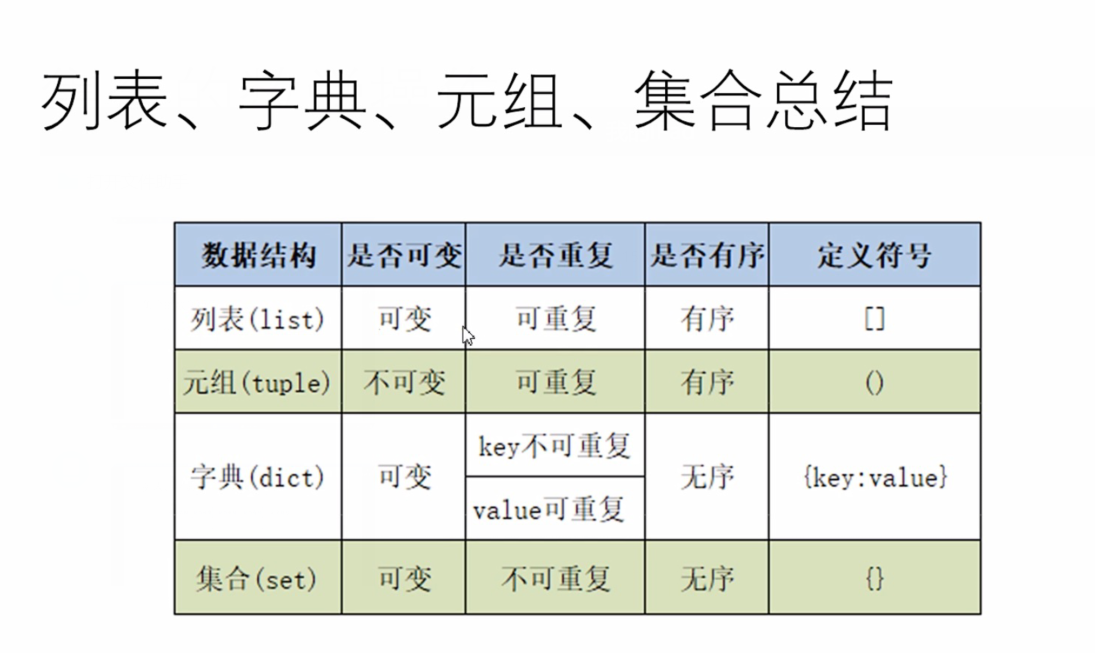
5.四种数据结构的总结
4.字符串
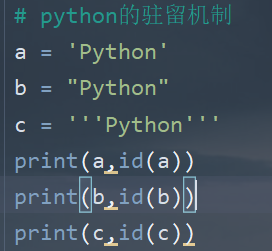
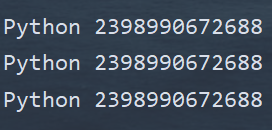
(1)字符串的驻留机制
- 仅保存一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,Python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同字符串时,不会开辟新空间,而是把字符串的地址赋给新创建的变量
(2)字符串的查询操作
- 索引从0开始
| 功能 | 方法名称 | 作用 |
|---|---|---|
| index() | 查找子串substr第一次出现的位置,如果查找的子串不存在时,则抛出ValueError | |
| 查询方法 | rindex() | 查找子串substr最后一次出现的位置,如果查找的子串不存在时,则抛出ValueError |
| find() | 查找子串substr第一次出现的位置,如果查找的子串不存在时,则返回-1 | |
| rfind() | 查找子串substr最后一次出现的位置,如果查找的子串不存在时,则返回-1 |
(3)字符串的大小写转换操作的方法
| 方法名称 | 作用 |
|---|---|
| upper() | 把字符串中所有字符都转成大写字母 |
| lower() | 把字符串中所有字符都转成小写字母 |
| swapcase() | 把字符串中所有大写字母都转成小写字母,把所有小写字母都转成大写字母 |
| capitalize() | 把第一个字符转换成大写,把其余字符转换为小写 |
| title() | 把每个单词的第一个字符转换为大写,把每个单词的剩余字符转换为小写 |
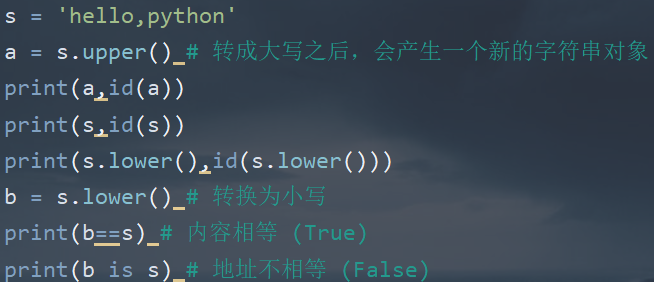
tips: 字符串大小写转换后会产生一个新的字符串对象
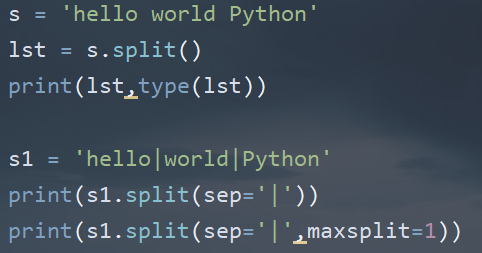
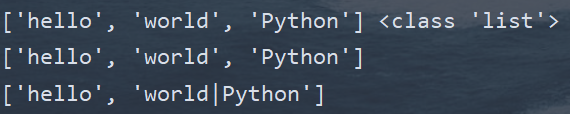
(4)字符串劈分操作的方法
| 方法名称 | 作用 |
|---|---|
| 从字符串的左边开始劈分,默认的劈分字符是空格字符串,返回的值是一个列表 | |
| split() | 以通过参数seq指定劈分字符串的劈分符 |
| 通过参数maxsplit指定劈分字符串的最大劈分次数,在经过最大劈分之后,剩余的子串会单独做为一部分 | |
| 从字符串的右边开始劈分,默认的劈分字符是空格字符串,返回的值都是一个列表 | |
| rsplit() | 以通过参数seq指定劈分字符串的劈分符 |
| 通过参数maxsplit指定劈分字符串时的最大劈分次数,在经过最大劈分之后,剩余的子串会单独做为一部分 |
(5)判断字符串操作的方法
| 方法名称 | 作用 |
|---|---|
| isidentifier() | 判断指定过的字符串是不是合法的标识符 |
| isspace() | 判断指定的字符串是否全部由空白字符组成(回车、换行、水平制表符) |
| isalpha() | 判断指定的字符串是否全部由字母组成 |
| isdecimal() | 判断指定字符串是否全部由十进制的数字组成 |
| isnumeric | 判断指定的字符串是否全部由数字组成 |
| isalnum() | 判断指定字符串是否全部由字母和数字组成 |
(6)字符串操作的其他方法
| 功能 | 方法名称 | 作用 |
|---|---|---|
| 字符串替换 | replace() | 第一个参数指定被替换的子串,第2个参数指定替换子串的字符串,该方法返回替换后得到的字符串,替换前的字符串不发生变化,调用该方法时可以通过第3个参数指定最大替换次数 |
| 字符串的合并 | join() | 将列表或元组中的字符串合并成一个字符串 |
(7)格式化字符串
- 格式化字符串的两种方式
%作占位符
'我的名字叫:%s,今年%d岁了 ' % (name,age)
{}作占位符
'我的名字叫:{0},今年{1}岁了'.format(name,age)
f-string
f'我叫{name},今年{age}岁'
(8)字符串编码转换
- 编码:将字符串转换为二进制数据(bytes)
- 解码:将bytes类型数据转换成字符串类型
5.函数
1.函数的创建和调用
# 函数的创建
def 函数名([输入参数]):
函数体
[return xxx]
# 函数的调用
函数名([实际参数])
2.函数的参数传递
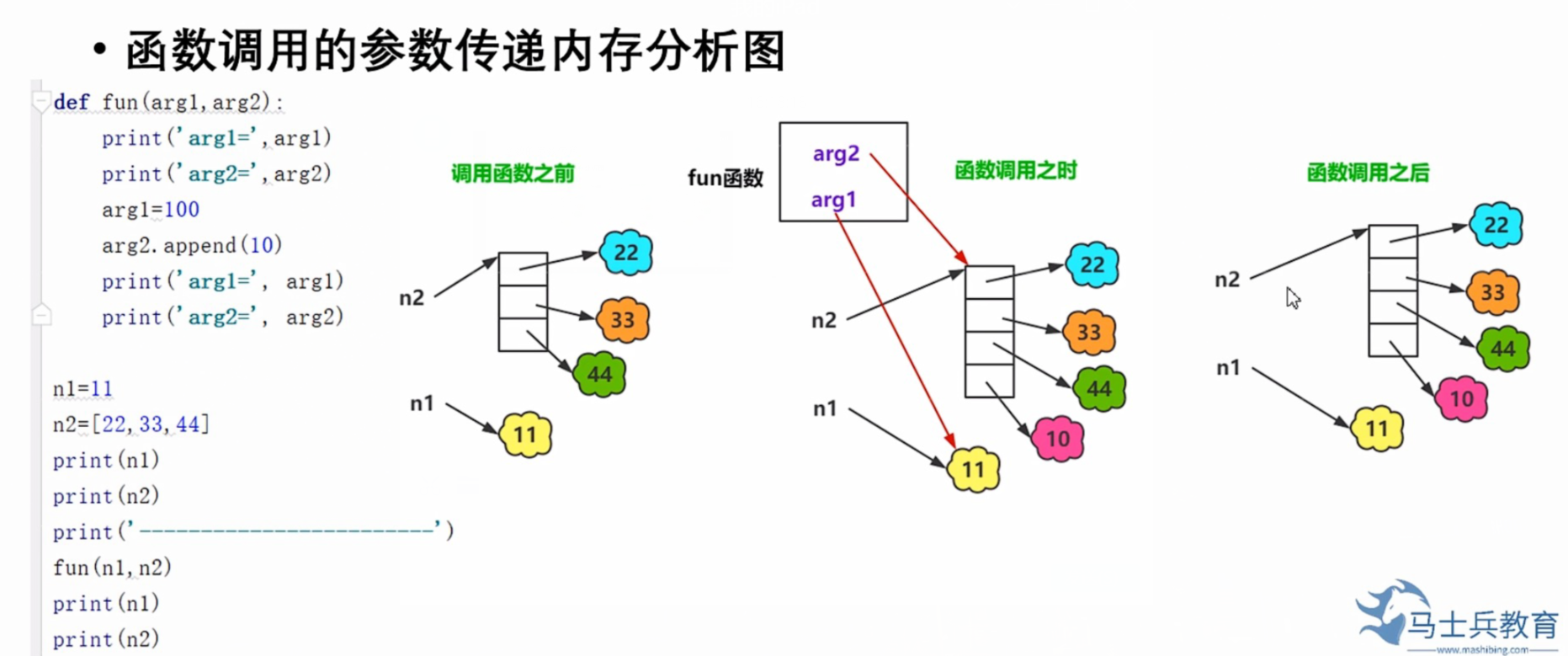
- 如果是不可变对象,在函数体的修改不会影响实参的值
- 如果是可变对象,在函数体的修改会影响到实参的值
3.函数的返回值
- 函数返回多个值时,结果为元组
4.函数的参数定义
- 函数定义默认值参数
- 参数定义时,给形参设置默认值,只有与默认值不符的时候才需要传递实参

-
个数可变的位置参数
- 定义函数时,可能无法事先确定传递的位置实参的个数时,使用可变的位置参数
- 使用*定义个数可变的位置参数
- 结果为一个元组
- 在函数的定义时,可变的位置参数只能是1个
-
个数可变的关键字形参
- 定义参数时,无法事先确定传递的关键字实参的个数时,使用可变的关键字形参
- 使用**定义个数可变的关键字形参
- 结果为一个字典
- 在函数的定义时,可变的关键字参数只能是一个
在一个参数的定义过程中,既有个数可变的关键字形参,也有个数可变的位置形参,要求个数可变的位置形参放在个数可变的关键字形参之前

5.函数的参数总结
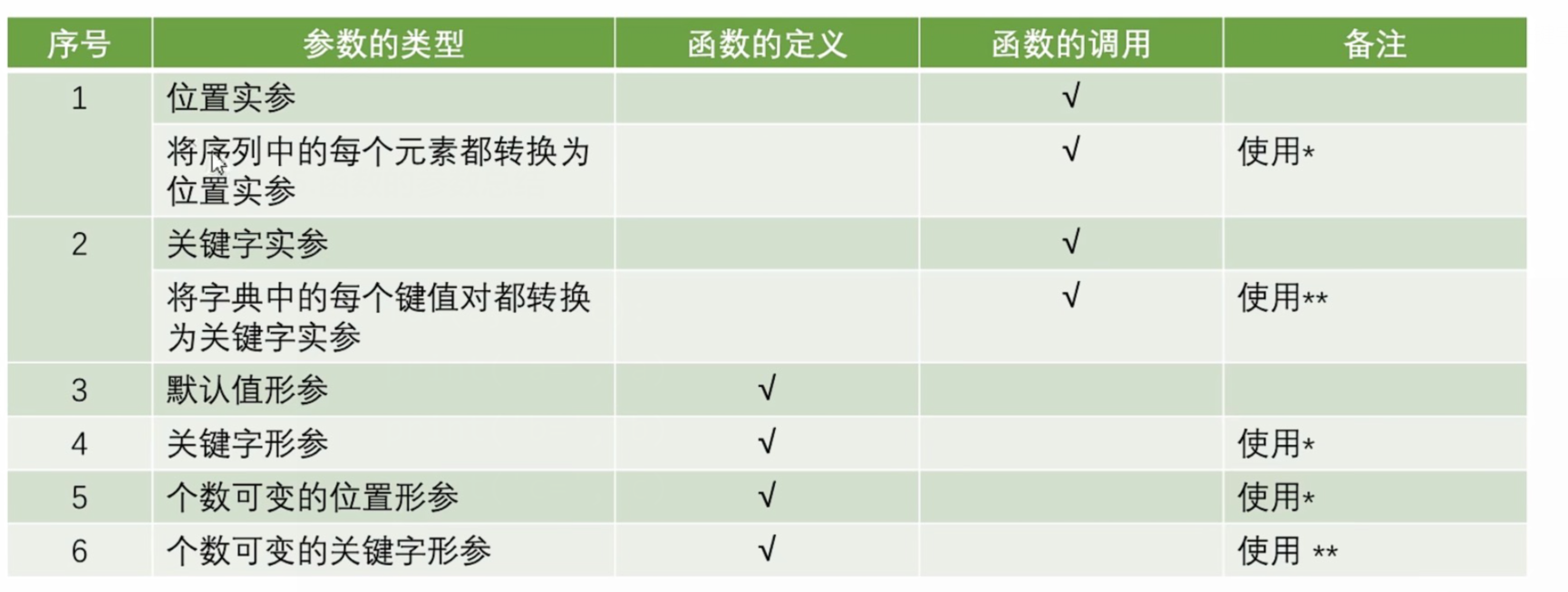
- 在传参时使用*,可以将序列中的每个元素都转换为位置实参
- 在传参时使用**,可以将字典中的每个键值对都转换为关键字实参

- 在函数形参中*之后的参数,在函数调用时,只能采用关键字参数传递

5.关于参数赋值的错误经验

6.Python异常
1.Python的异常处理机制
-
try..except...else结构
- 如果try块中没有抛出异常,则执行else块,如果try块中抛出异常,则执行excpt块
-
try...except...else..finally结构
- finally块无论是否发生异常都会被执行,能常用来释放try块中申请的资源
2.Python常见的异常类型
| 序号 | 异常类型 | 描述 |
|---|---|---|
| 1 | ZeroDivisionError | 除(或取模)零(所有数据类型) |
| 2 | IndexError | 序列中没有此索引(index) |
| 3 | KeyError | 映射中没有这个键 |
| 4 | NameError | 未声明/初始化对象(没有属性) |
| 5 | SyntaxError | Python语法错误 |
| 6 | ValueError | 传入无效的参数 |
7.类与对象
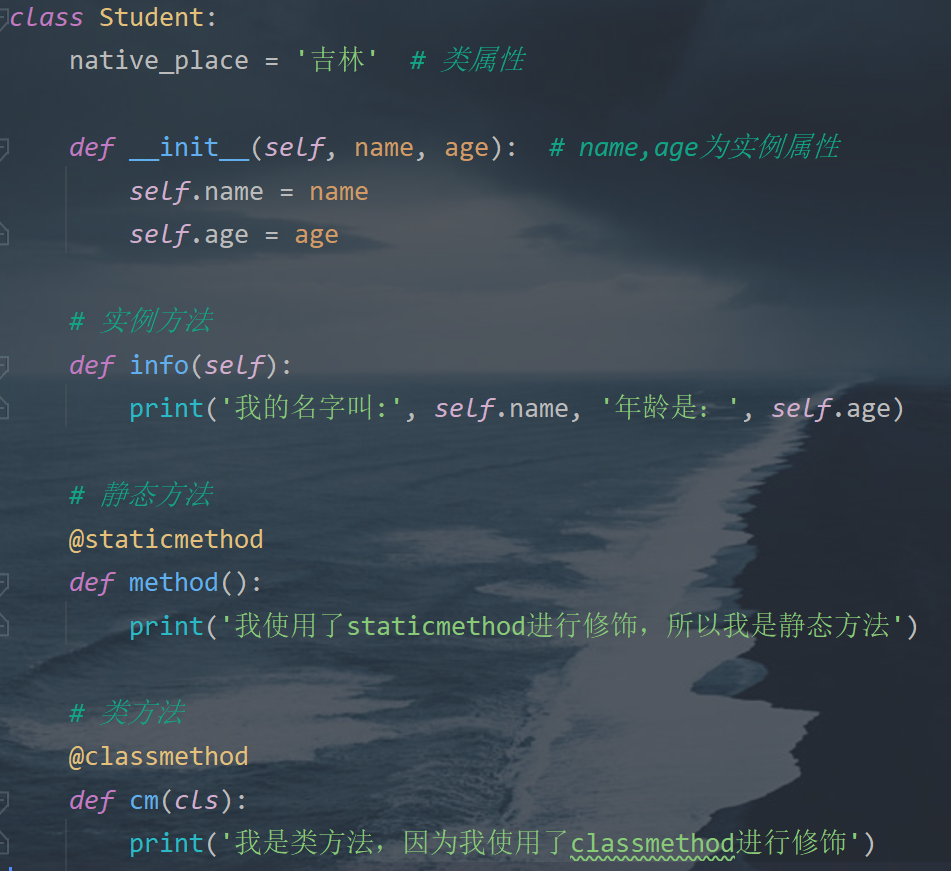
1.类的创建
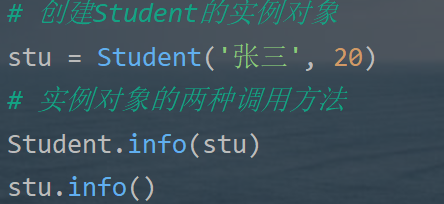
2.对象的创建与实例方法的调用
- 对象的创建又称为类的实例化
- 语法:实例名 = 类名 ()
3.类属性、类方法、静态方法
- 类属性:类中方法外的变量称为类属性,被该类的所有对象共享
- 类方法:使用@classmethod修饰的方法,使用类名直接访问的方法
- 静态方法:使用@staticmethod修饰的主法,使用类名直接访问的方法

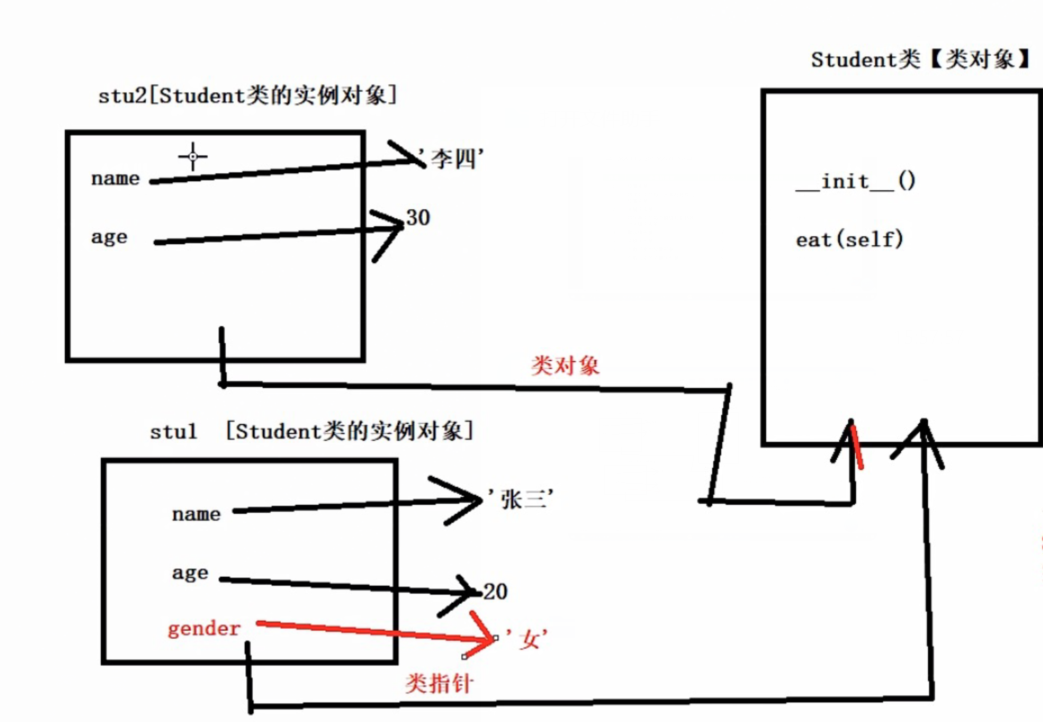
4.动态绑定属性
- Python 是动态语言,在创建对象后,可以动态地绑定属性和方法
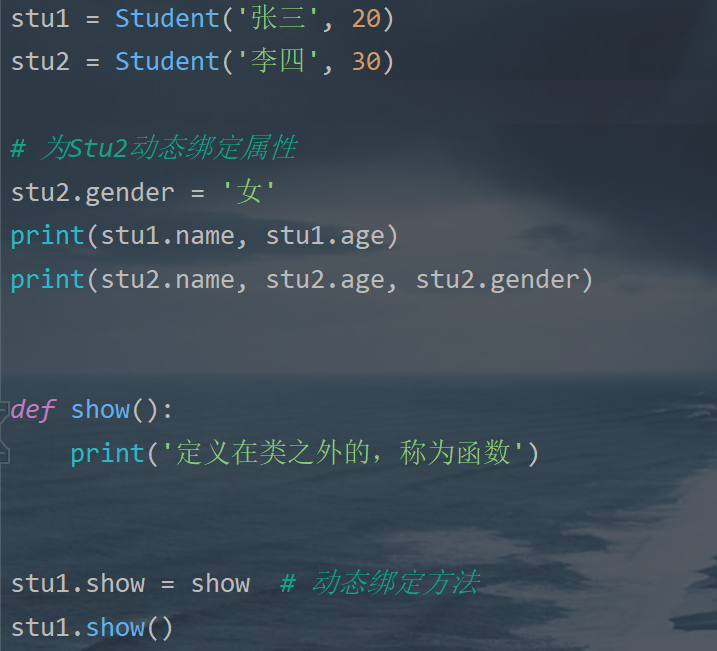
- 一个Student类可以创建N多个Student类的实例对象,每个实例对象的属性值不同
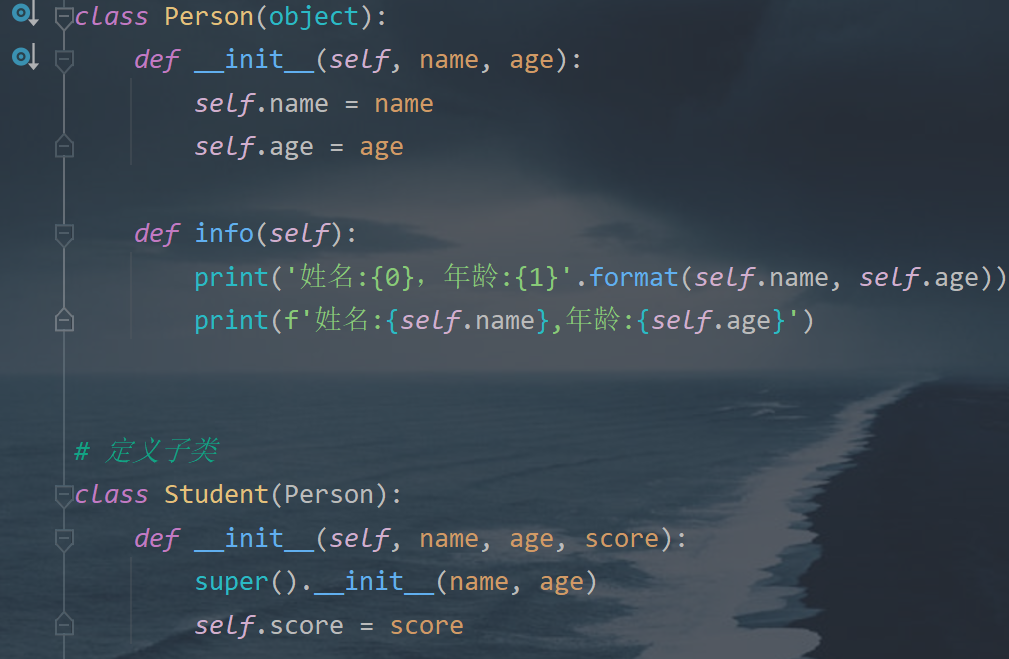
5.类的继承及其实现方式
- 语法格式
class 子类类名(父类1 父类2):
pass
- 如果一个类没有继承任何类,则默认继承object
- Python支持多继承
- 定义子类时,必须在其构造函数中调用父类的构造函数
6.方法重写
- 如果子类对继承自父类的某个属性或方法不满意,可以在子类中对其进行重新编写
- 子类重写的方法可通过super().xxx()调用父类中被重写的方法
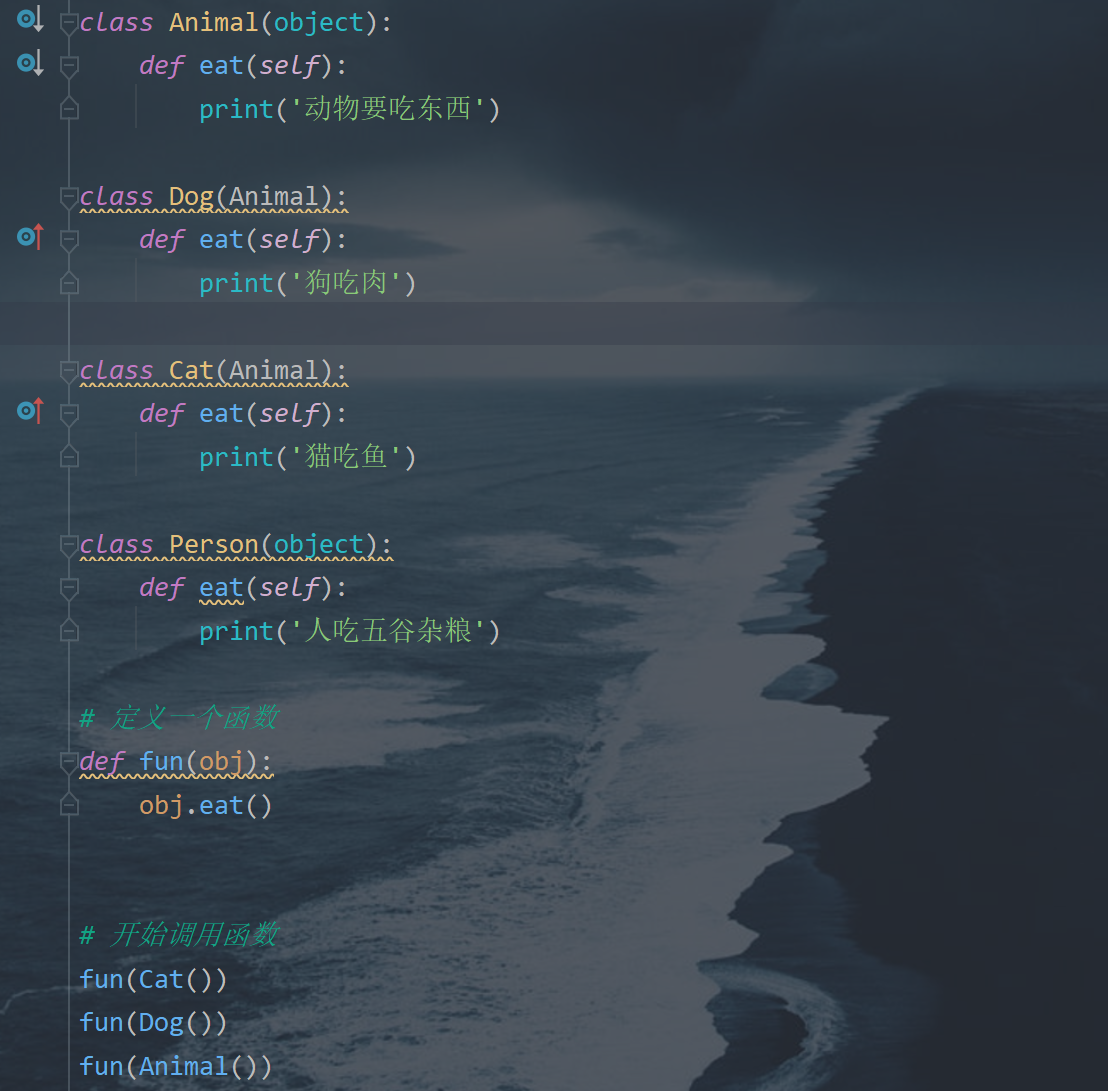
7.多态
- 即便不知道一个变量所引用的对象到底是什么类型,仍然可以通过这个变量调用方法,在运行过程中根据变量所引用对象的类型,动态决定调用哪个对象中的方法
8.特殊方法和特殊属性
| 名称 | 描述 | |
|---|---|---|
| 特殊属性 | __ __dict __ __ | 获得类对象或者实例对象所绑定的所有属性和方法的字典 |
| __ len __ | 通过重写__ len __()方法,让内置函数len()的参数可以是自定义类型 | |
| 特殊方法 | __ add __ | 通过重写__ add __()方法,可使自定义对象具有‘+'功能 |
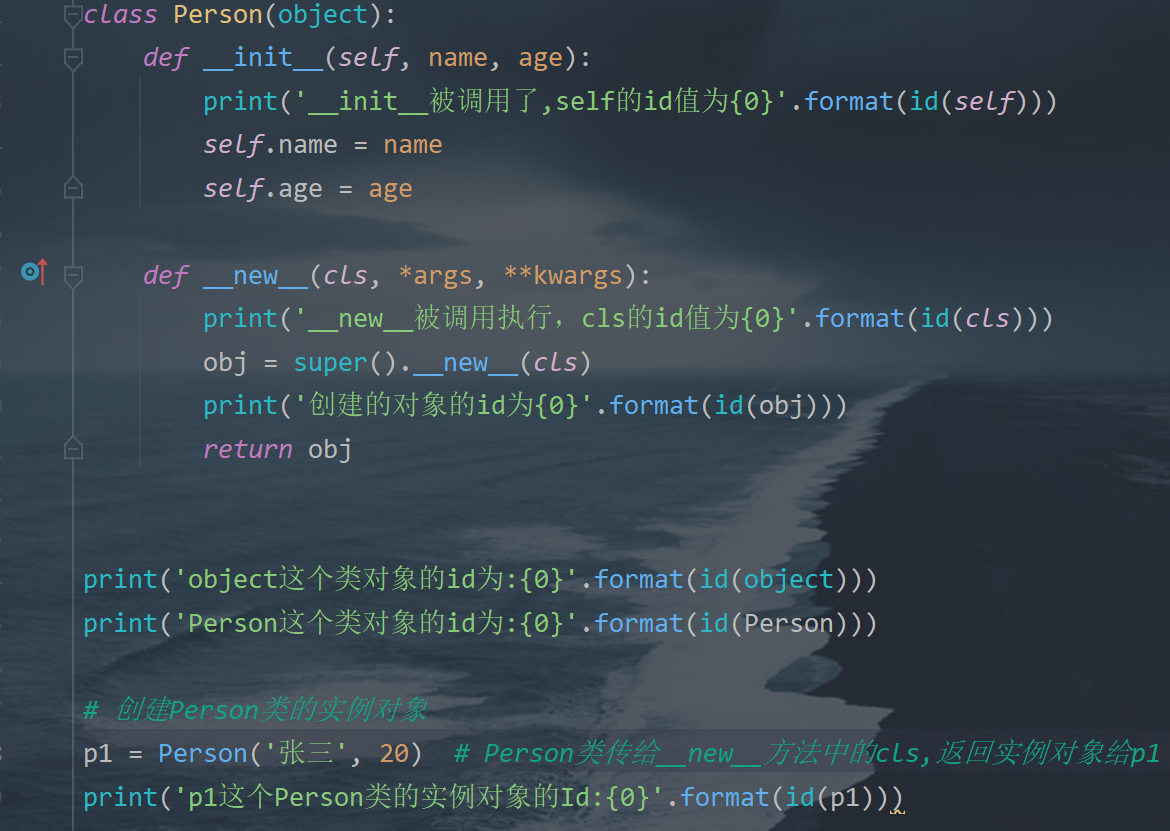
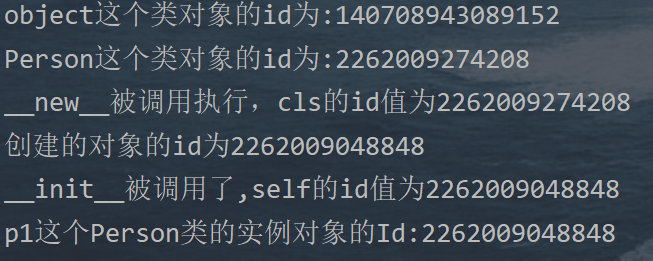
| __ new __ | 用于创建对象 | |
| __ init __ | 对创建的对象进行初始化 |
- 特殊属性
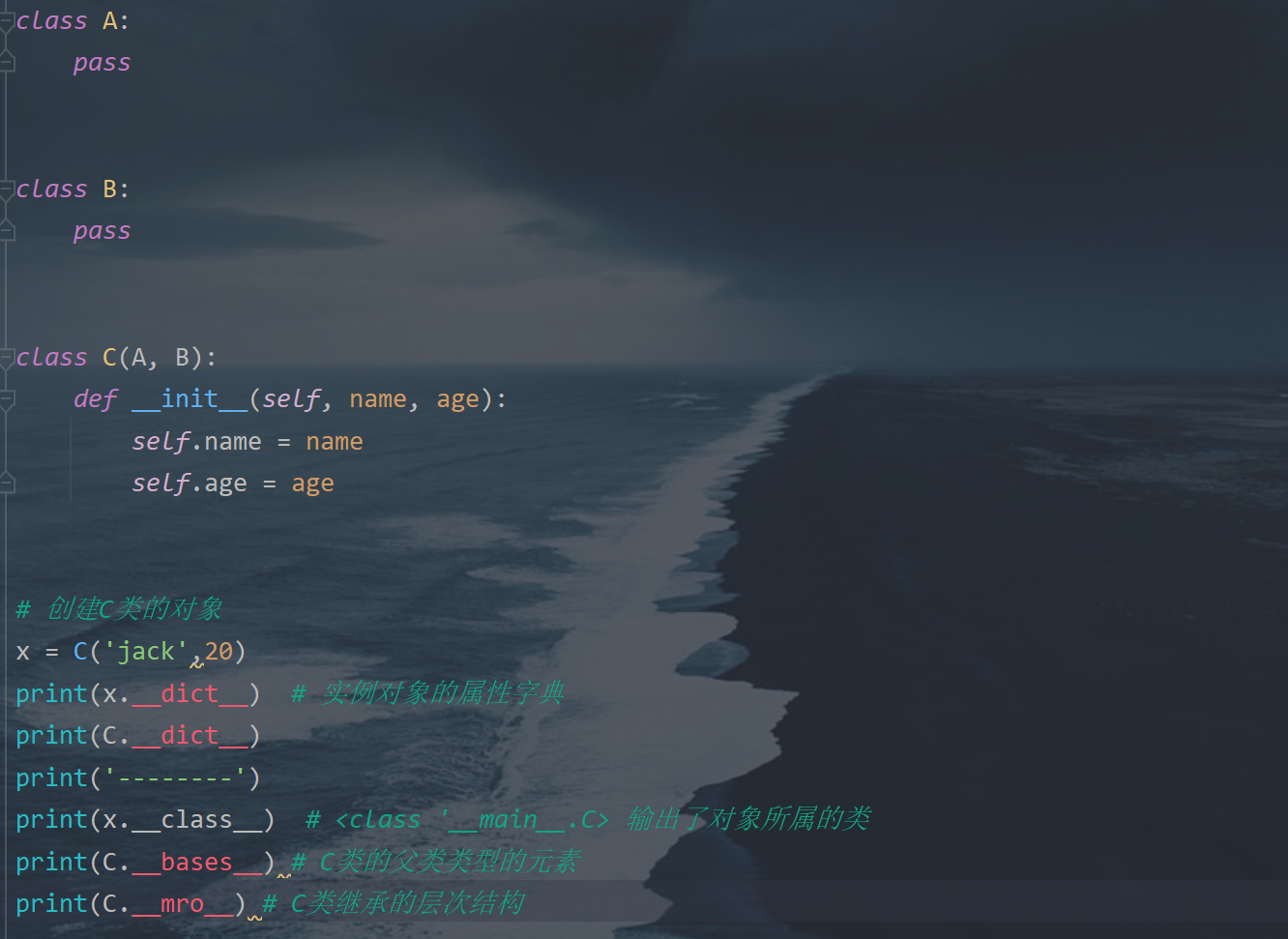

-
特殊方法
- __ add __ 方法和 __ len __方法

- __ init __ 方法和 __ new __方法
9.类的浅拷贝与深拷贝
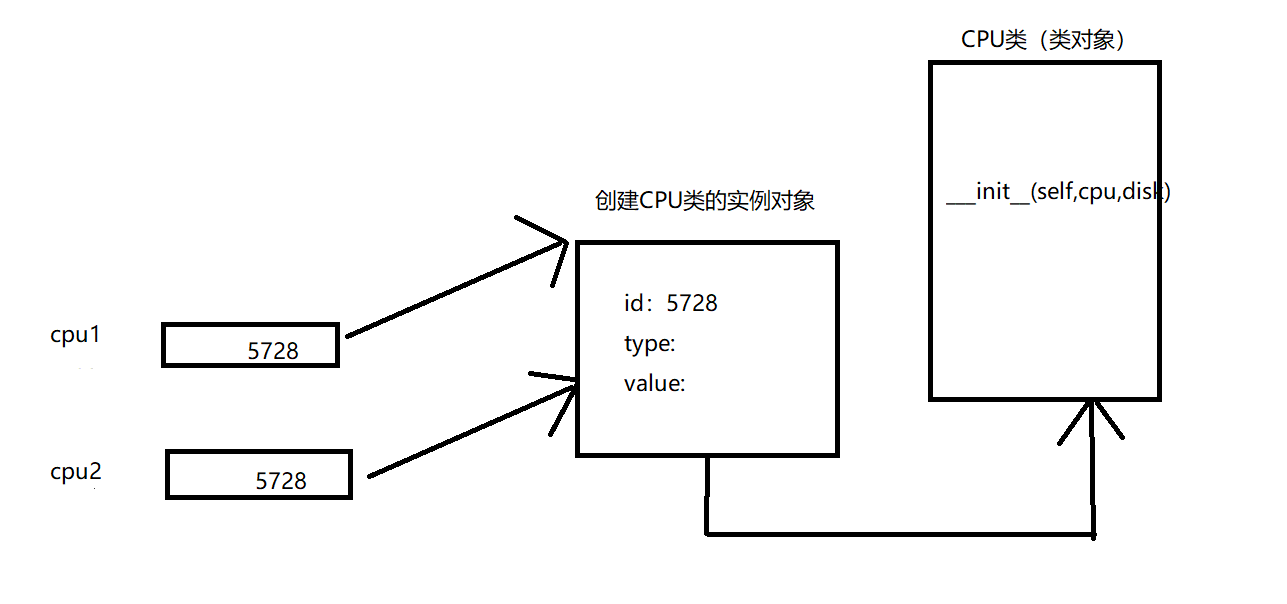
- 变量的赋值操作
- 只是形成两个变量,实际上还是指向同一个对象,如下所示
-
浅拷贝
- Python拷贝一般都是浅拷贝,拷贝时,对象包含的子对象内容不拷贝,因此,源对象与拷贝对象会引用同一个子对象
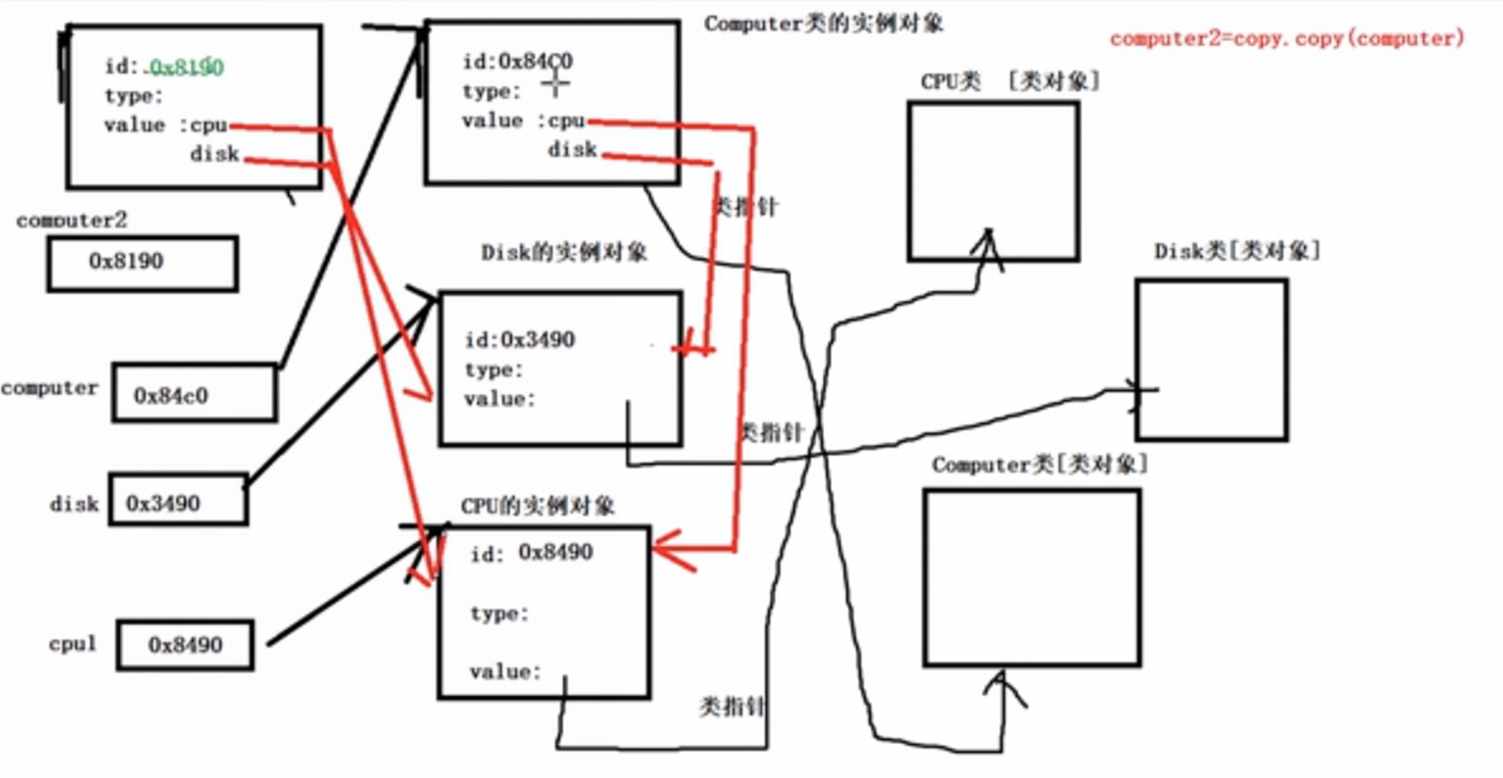
-
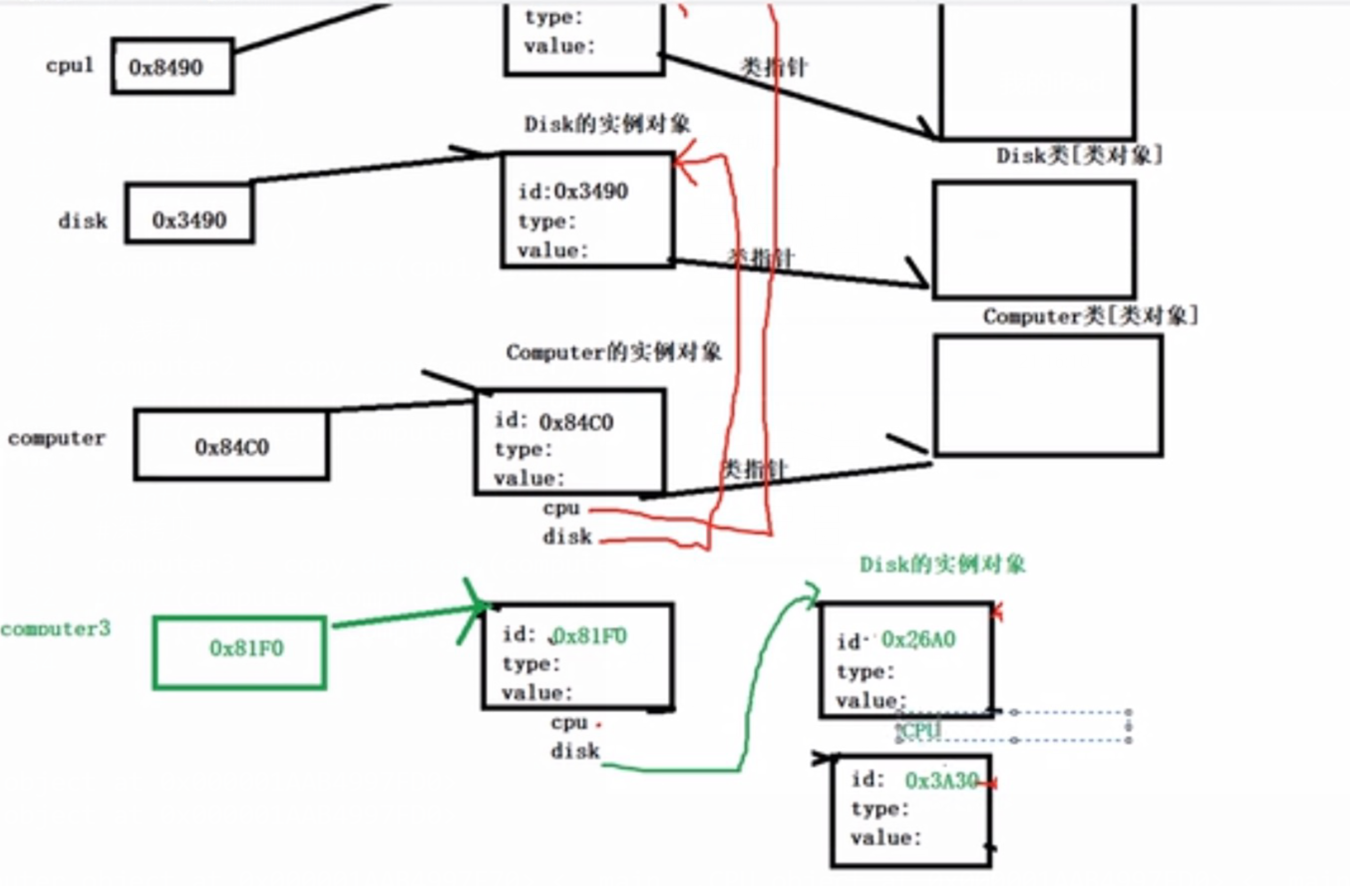
深拷贝
- 使用copy模块的deepcopy函数,递归拷贝对象中包含的子对象,源对象和拷贝对象所有的子对象也不相同
8.Python的模块
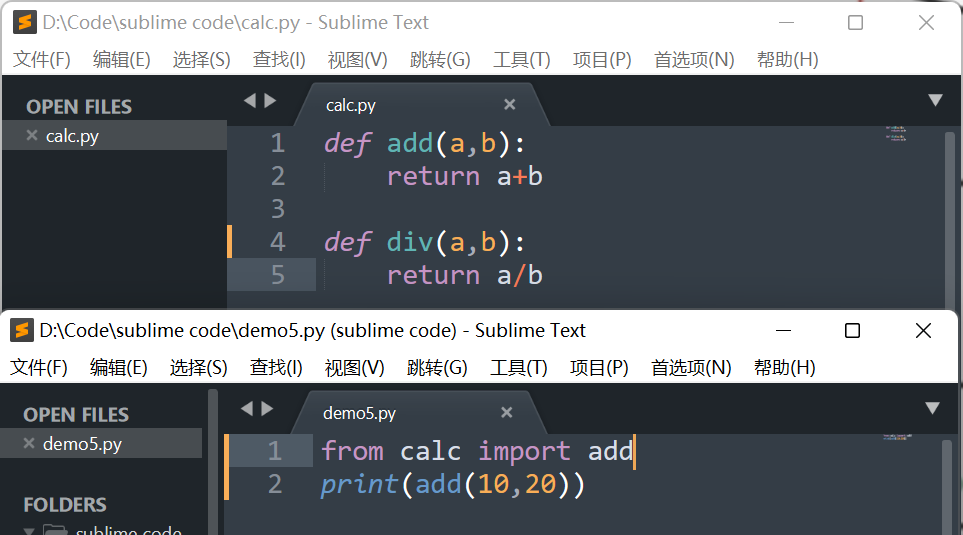
1.模块的导入
- 导入模块的方法
import 模块名称 [as 别名]
from 模块名称 import 函数/变量/类
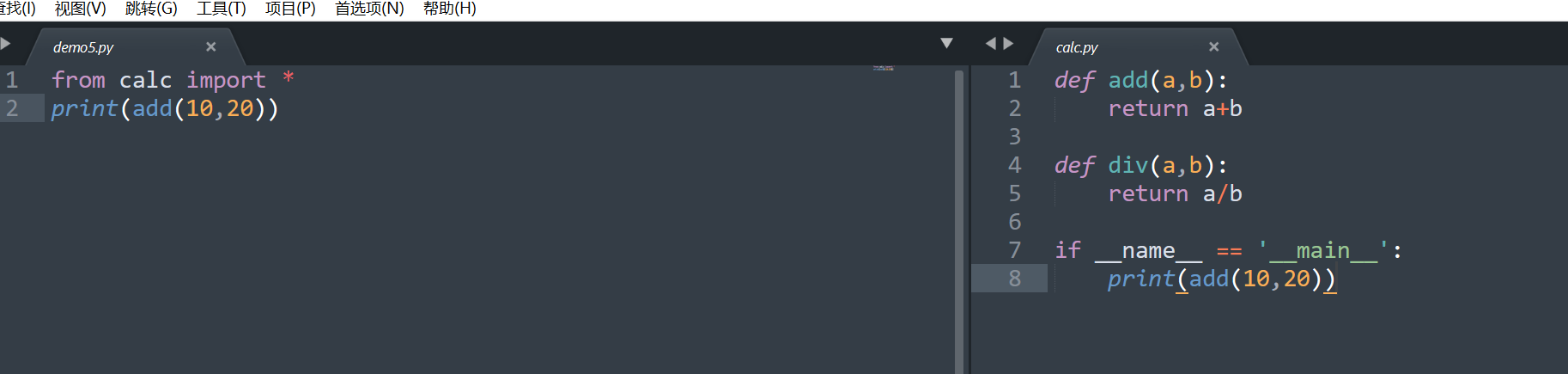
- 导入模块的注意事项
Python导入模块时,实际上会把被导入的模块执行一遍
如何才能只是单纯调用而不执行被调用模块的代码呢?方法就是:在被调用的模块中,可执行代码前加上if name == 'main':这么一句判断,被调用的模块的代码就不会被执行。
2.Python的工作机制

解释器的具体工作:
1、完成模块的加载和链接;
2、将源代码编译为PyCodeObject对象(即字节码),写入内存中,供CPU读取;
3、从内存中读取并执行,结束后将PyCodeObject写回硬盘当中,也就是复制到.pyc或.pyo文件中,以保存当前目录下所有脚本的字节码文件。
之后若再次执行该脚本,它先检查【本地是否有上述字节码文件】和【该字节码文件的修改时间是否在其源文件之后】,是就直接执行,否则重复上述步骤。
第一次执行代码的时候,Python解释器已经把编译的字节码放在__pycache__文件夹中,这样以后再次运行的话,如果被调用的模块未发生改变,那就直接跳过编译这一步,直接去__pycache__文件夹中去运行相关的*.pyc文件,大大缩短了项目运行前的准备时间。
3.Python中常用的模块
| 模块名 | 描述 |
|---|---|
| sys | 与Python解释器及其环境操作相关的标准库 |
| time | 提供与时间相关的各种函数的标准库 |
| os | 提供了访问操作系统服务功能的标准库 |
| calendar | 提供了与日期相关的各种函数的标准库 |
| urllib | 用于读取来自网上(服务器)的数据标准库 |
| json | 用于使用JSON序列化和反序列化对象 |
| math | 提供标准算术运算函数的标准库 |
| decimal | 用于进行精确控制运算精度、有效数位和四舍五入操作的十进制运算 |
| logging | 提供了灵活的记录事件、错误、警告和调试信息等日志信息的功能 |
| re | 用于在字符串中执行正则表达式匹配和替换 |
4.常用的文件打开模式
- 文件的类型
- 按文件中数据的组织方式,文件分为以下两大类
- 文本文件:存储的是普通'字符'文本,默认为unicode字符集,可以使用记事本程序打开
- 二进制文件:把数据内容用'字节'进行存储,无法用记事本打开,必须用专用的软件
- 按文件中数据的组织方式,文件分为以下两大类
5.文件对象的常用方法
| 方法名 | 说明 |
|---|---|
| read([size]) | 从文件中读取size个字节或字符的内容返回,若省略[size],则读取到文件末尾 |
| readline() | 从文本文件中读取一行内容 |
| readlines() | 把文本文件中每一行都作为独立的字符串对象,并将这些对象放入列表返回 |
| write(str) | 将字符串str内容写入文件 |
| writelines(s_list) | 将字符串列表s_list写入文本文件,不添加换行符 |
| tell | 返回文件指针的当前位置 |
| fflush() | 把缓冲区的内容写入文件,但不关闭文件 |
| close() | 把缓冲区的内容写入文件,同时关闭文件,释放文件对象相关资源 |
6.with语句(上下文管理器)
- with语句可以自动管理上下文资源,不论什么原因跳出with块,都能确保文件正确的关闭,以此来达到释放资源的目的
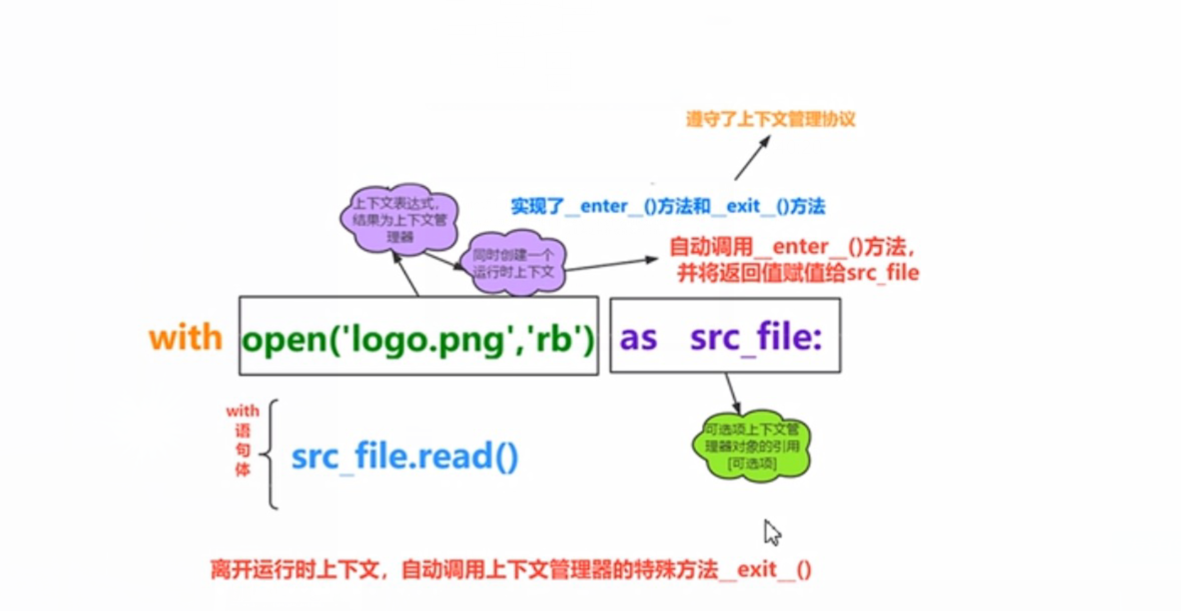
7.OS模块操作目录相关函数
| 函数 | 说明 |
|---|---|
| getcwd() | 返回当前的工作目录 |
| listdir(path) | 返回指定路径下的文件和目录信息 |
| mkdir(path[,mode]) | 创建目录 |
| makedirs(path1/path2...[,mode]) | 创建多级目录 |
| removedirs(path1/path2.....) | 删除多级目录 |
| chdir(path) | 将path设置为当前工作目录 |
8.os.path模块操作目录相关函数
| 函数 | 说明 |
|---|---|
| abspath(path) | 用于获取文件或者目录的绝对路径 |
| exists(path) | 用于判断文件或目录是否存在,如果存在返回True,否则返回False |
| join(path,name) | 将目录与目录或者文件名拼接起来 |
| splitext() | 分离文件名和扩展名 |
| basename(path) | 从一个目录中提取文件名 |
| dirname(path) | 从一个路径中提取文件路径,不包括文件名 |
| isdir(path) | 用于判断是否为路径 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号