这可能是Matplotlib和Seaborn最全的入门文档
matplotlib是python第一个数据可视化库,在数据分析,可视化领域的地位和贡献是无法磨灭的。但也正是因为有了这位老大哥的出现给后续基于matplotlib实现的绘图库实现了可能。
而对于绘图的基本操作来说,是没有什么创新性改变的,除非是提供matlab可视化的操作。所以seaborn之类的高级库所作的努力就在配色以及一些不方便的参数上。
相信很多人在jupyter notebook画图,是这样的过程,
画什么图? 散点? 柱状?function是什么?google查一下。
嗯,我还差个标题,标题加在哪里,stackoverflow 看看有没有。
对了,我还要调颜色,调坐标,我还想双轴展示,左右展示。
然后,google看了10几个链接,结果,要么花了半个小时,不停试错,终于画出了想要的图,要么还在一个个点google 搜索的link内容。
如果你有大量时间,当然是没什么问题,但是美赛当中,都需要熬通宵了,哪来的那么多时间。
所以,在这种情况下,我们就需要掌握必要且充分的seaborn的使用。画出绝大多数的理想之图。
当然seaborn并不能替代matplotlib。虽然seaborn可以满足大部分情况下的数据分析需求,但是针对一些特殊情况,还是需要用到matplotlib的。换句话说,matplotlib更加灵活,可定制化,而seaborn像是更高级的封装,使用方便快捷。
所以我们可以把matplotlib看作画笔,而seaborn作为最后的美化工具。
matplotlib
引入
#约定俗成
import matplotlib.pyplot as plt
使用
直接绘图
如果简单绘图,就直接plt.plot等就行。
- 基础绘图
plot(x,y),线图scatter(x,y),散点图bar(x,height),柱状图stem(x,y),火柴图step(x,y),阶梯图fill_between(x,y1,y2)stackplot(x,y)

- 数组区域绘图
imshow(Z),热图,应该配备colorbar().可以理解为三维的俯视图.pcolormesh(X,Y,Z)imshow的x和y必须是相同说两的contour(X,Y,Z),等值线图contourf(X,Y,Z),函数名中的‘f’=fill,填充之意barbs(X,Y,U,V)quiver(X,Y,U,V)streamplot(X,YU,V)quiver连成线
data Z(x, y) and fields U(x, y), V(x, y)

- 统计绘图
hist(x)boxplot(X)errorbar(x,y,yerr,xerr)violinplot(D)eventplot(D)hist(x,y)hexbin(x,y,C)pie(x)
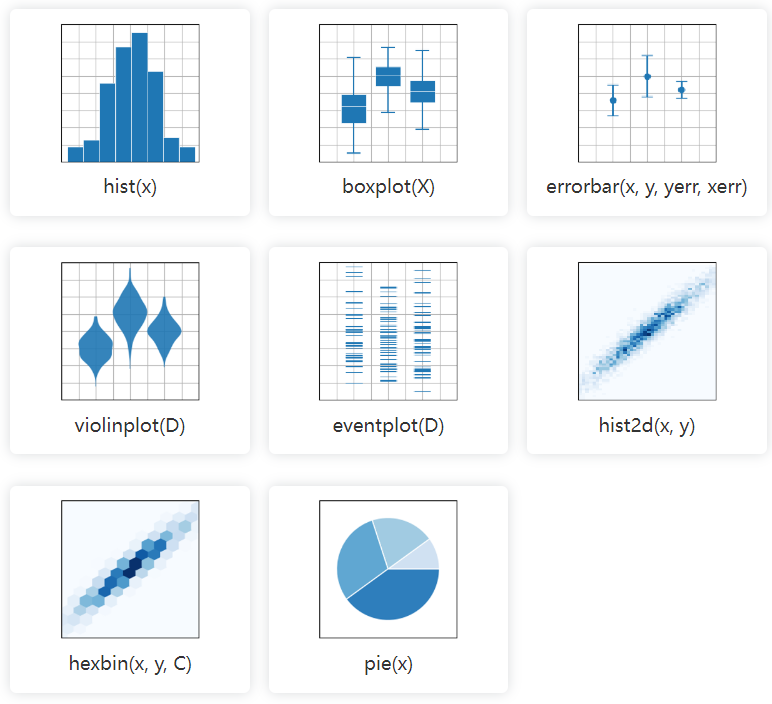
Figure和Subplot
所有的图像都位于Figure对象中。我们可以通过对figure的操作实现更多的操作。
plt.figure有一些选项,特别是figsize,它用于确保当图片保存到磁盘时具有一定的大小和纵横比。
但是不能通过空Figure绘图。必须用add_subplot创建一个或多个subplot才行。
提示:使用Jupyter notebook有一点不同,即每个小窗重新执行后,图形会被重置。因此,对于复杂的图形,,你必须将所有的绘图命令存在一个小窗里。
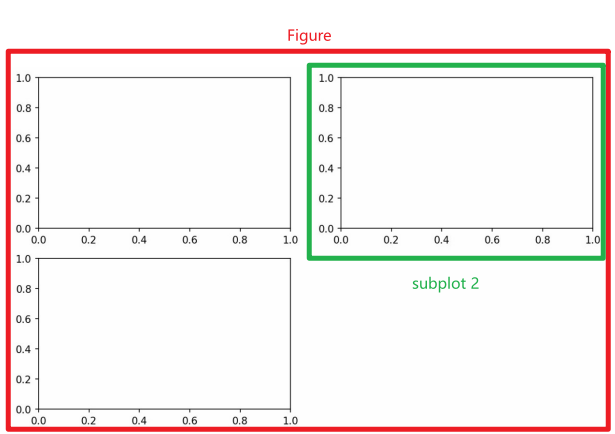
fig = plt.figure()
#表示生成最多四个自会实例化子绘图对象,并且选择第~个(编码从1开始)
ax1 = fig.add_subplot(2, 2, 1)
ax2 = fig.add_subplot(2, 2, 2)
ax3 = fig.add_subplot(2, 2, 3)
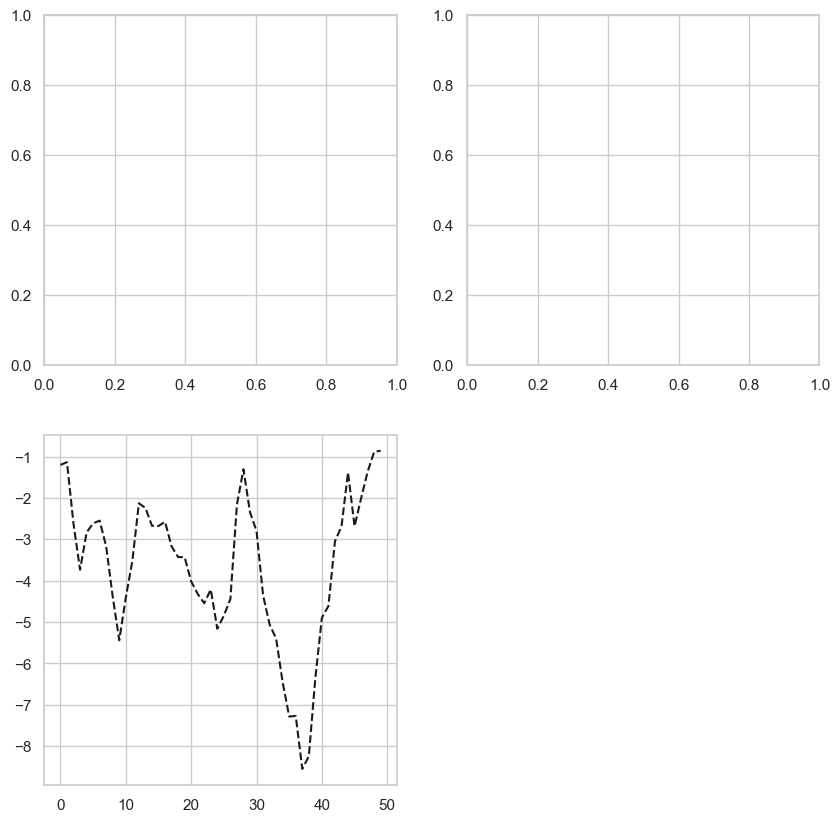
如果这时候直接plt.plot操作,会选择最近使用过的subplot(如果没有就创建一个)进行绘制,隐藏创建figure和subplot的过程,这也是上面直接作图的原理
plt.plot((np.random.randn(50).cumsum(), 'k--')
#其中k是一个线形选项,表示黑色虚线图。
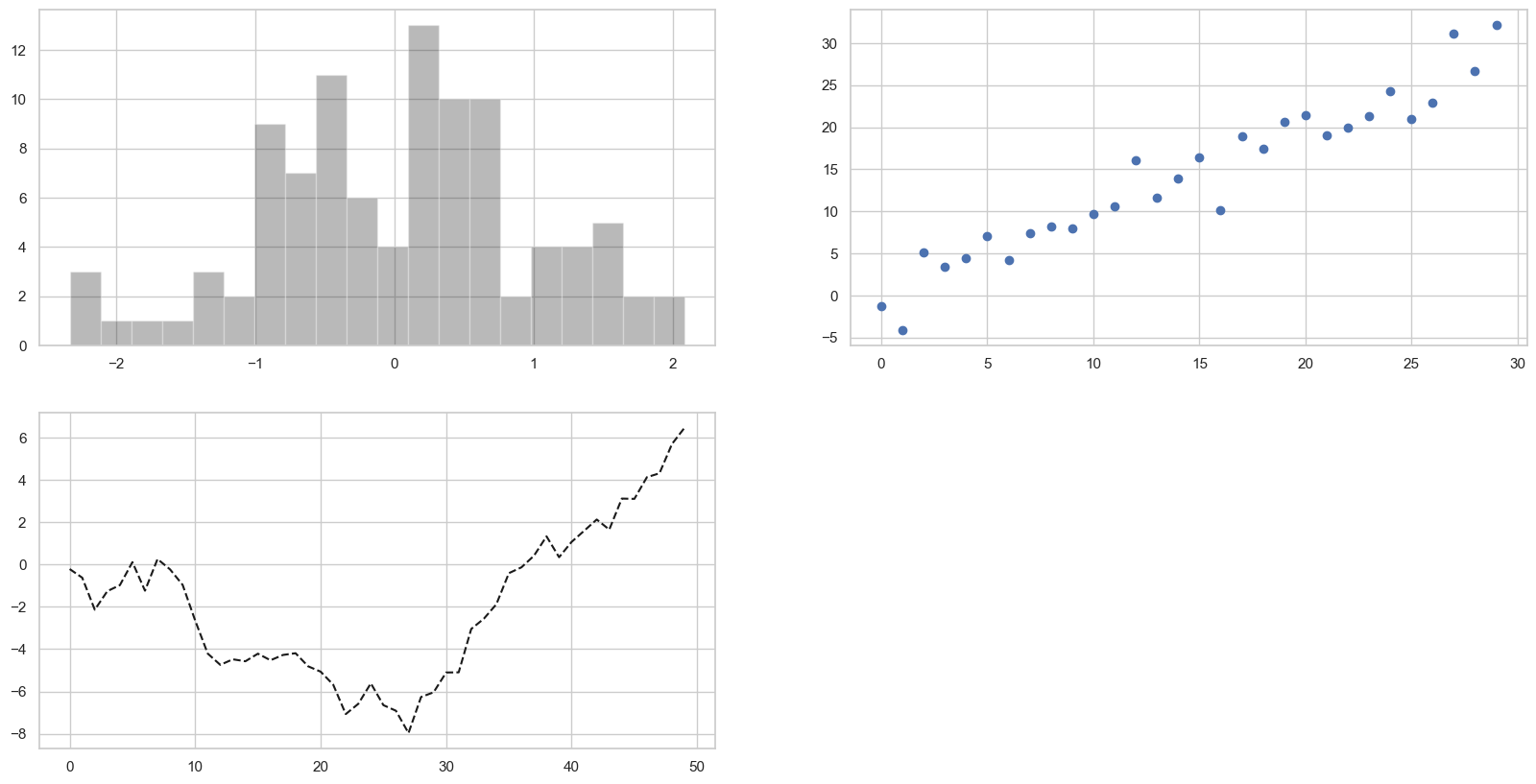
上面的那些从fig.add_subplot所返回的对象是AxesSubplot对象,直接调用他们的实例方法就可以在它们所对应的格子里面绘图
ax1.hist(np.random.randn(100), bins=20, color='k', alpha=0.3)
ax2.scatter(np.arange(30), np.arange(30) + 3 * np.random.randn(30))
更加简便的操作方法
由于在一个figure中创建多个图表是一个非常常见的任务,matplotlib提供了简化操作
#创建一个新的figure,并且返回一个含有已创建的subplot对象的Numpy对象
fig, axes = plt.subplots(2, 3)
axes
#这就意味着我们对fig中的通向可以像二维数组一样进行操作了。
array([[<matplotlib.axes._subplots.AxesSubplot object at 0x7fb626374048>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7fb62625db00>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7fb6262f6c88>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x7fb6261a36a0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7fb626181860>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7fb6260fd4e0>]], dtype
=object)

调整subplot周围的间距
subplots_adjust(left=None, bottom=None, right=None, top=None,
wspace=None, hspace=None)
wspace和hspace用于控制宽度和高度的百分比,可以用作subplot之间的间距。下面是一个简单的例子,我将间距收缩到了0
fig, axes = plt.subplots(2, 2, sharex= 'all', sharey='all')
for i in range(2):
for j in range(2):
axes[i, j].hist(np.random.randn(500), bins=50,color='k', alpha=0.5)
plt.subplots_adjust(wspace=0, hspace=0)
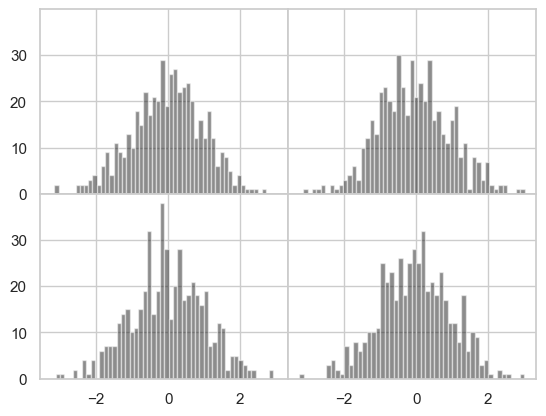
不难看出,其中的轴标签重叠了。matplotlib不会检查标签是否重叠,标签不同的情况我们会自己设定刻度位置和刻度标签。
颜色、标记和线型
比如前面使用的k--就起到了对绘图过程中线描述的作用。而这是由color=k和linestyle='--'组成的。
同时我们还可以通过marker='o'来表示画图中的数据点(。因为matplotlib可以创建连续线图,在点之间进行插值,因此有时可能不太容易看出真实数据点的位置。)
三者可以同时放在格式字符串中,但是标记和线形状要饭在颜色的后面
- 颜色可以使用常用颜色缩写,但是配色的时候直接复制16进制颜色码就可以了。
- 可以通过查看plot的文档字符串查看所有线型的合集(在IPython和Jupyter中使用plot?)
'-'实线'--'虚线'-.'细点划线':'点
- 线图可以使用标记强调数据点。
'.'point marker','pixel marker'o'circle marker'v'triangle_down marker'^'向上三角'<'~'>'~'1'向下奔驰标'2'~上'3'~左'4'~右'8'八边形's'正方形'p'五边形'P'粗体加号'*'五角星号'h'六边形1'H'六边形2'+'加号'x'x'X'粗体x'D'菱形'd'瘪一点的菱形
'|'vline marker
'_'hline marker
插值和拟合
无论是画什么图,matplotlib都只接受离散的点,而当我们画线图的时候就会自动插值,使之连成一条完整的线。
matplotlib默认使用线性方式插值。可以通过drawstyle选项来修改。
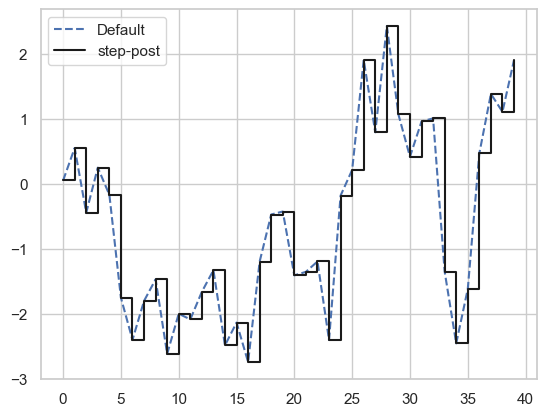
np.random.seed(4)
data = np.random.randn(40).cumsum()
plt.plot(data,'b--',label='Default')
plt.plot(data,'k-',label='step-post',drawstyle='steps-post')
plt.legend(loc='best')
#你必须调用plt.legend(或使用ax.legend,如果引用了轴的话)来创建图例,无论你绘图时是否传递label标签选项。下面我们会详细讲解图例的设置
刻度、标签和图例
对于大多数的图表装饰项,其主要实现方式有二:使用过程型的pyplot接口(例如,
matplotlib.pyplot)以及更为面向对象的原生matplotlib API。
pyplot接口的设计目的就是交互式使用,含有诸如xlim、xticks和xticklabels之类的方法。它们分别
控制图表的范围、刻度位置、刻度标签等。其使用方式有以下两种:
- 调用时不带参数,则返回当前的参数值(例如,
plt.xlim()返回当前的X轴绘图范围)。 - 调用时带参数,则设置参数值(例如,
plt.xlim([0,10])会将X轴的范围设置为0到10)。
所有这些方法都是对当前或最近创建的AxesSubplot起作用的。它们各自对应subplot对象上的两个方法,以xlim为例,就是ax.get_xlim和ax.set_xlim。
设置标题、轴标签、刻度以及刻度标签
有些时候,我们并不想坐标轴显示无意义的数字,而是更加直观的文字。这时候我们就可以自定义轴
#创建一段图像
fig = plt.figure(figsize=[20,10])
axe = fig.add_subplot(1,1,1)
axe.plot(np.random.randn(1000).cumsum(),'b-')
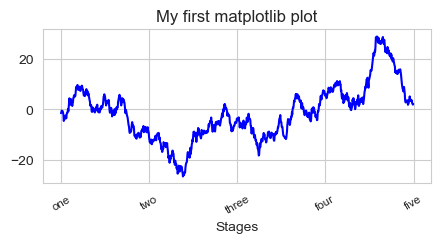
要改变x轴刻度,最简单的办法是使用set_xticks和set_xticklabels。前者告诉matplotlib要将刻度放
在数据范围中的哪些位置,默认情况下,这些位置也就是刻度标签。但我们可以通过
set_xticklabels将任何其他的值用作标签:
ticks = ax.set_xticks([0, 250, 500, 750, 1000])
#这里我们使用0, 250, 500, 750, 1000的实际意义'one', 'two', 'three', 'four', 'five'来代替它放在x轴上
#rotation选项设定x刻度标签倾斜30度
axe.set_xticklabels(['one', 'two', 'three', 'four', 'five'],rotation=30,fontsize='small')
axe.set_title('My first matplotlib plot')
axe.set_xlabel('Stages')
当然,这一种常用的操作也有简单操作
props = {
'title': 'My first matplotlib plot',
'xlabel': 'Stages'
}
ax.set(**props)
添加图例
图例(legend)是另一种用于标识图表元素的重要工具。添加图例的方式有多种。最简单的是在
添加subplot的时候传入label参数。但是要注意的是,必须在最后添加plt.legend(loc='best')或者axe.legend(loc='best')
loc告诉matplotlib要将图例放在哪。如果你不是吹毛求疵的话,"best"是不错的选择,因为它会选择最不碍事的位置。要从图例中去除一个或多个元素,不传入label或传入label='nolegend'即可。
注解以及在Subplot上绘图
除标准的绘图类型,你可能还希望绘制一些子集的注解,可能是文本、箭头或其他图形等。注解和文字可以通过text、arrow和annotate函数进行添加。
笔记:其实,所有的注解都画在
Patch单元上。
text可以将文本绘制在图表的指定坐标(x,y),还可以加上一些自定义格式:
ax.text(x, y, 'Hello world!',family='monospace', fontsize=10)
- 当然,注解中可以既含有文本也含有箭头,我们需要调用
annotate。
fig = plt.figure(figsize=[5,3])
axe2 = fig.add_subplot(1,1,1)
axe2.plot(a,'b-')
axe2.annotate('Peak', xy=(10, a[10]+0.1),xytext=(10, a[10]+3),
arrowprops=dict(facecolor='black', headwidth=6,
headlength=4,width=3),
horizontalalignment='left', verticalalignment='top')
axe2.set_ylim([0, 12])
annotate方法可以在指定的x和y轴绘制标签。这里我们使用set_xlim和set_ylim人工设置起始和结束边界,而不使用默认的方法。如果找不到你所添加的可能是在外面了。
- 图形:
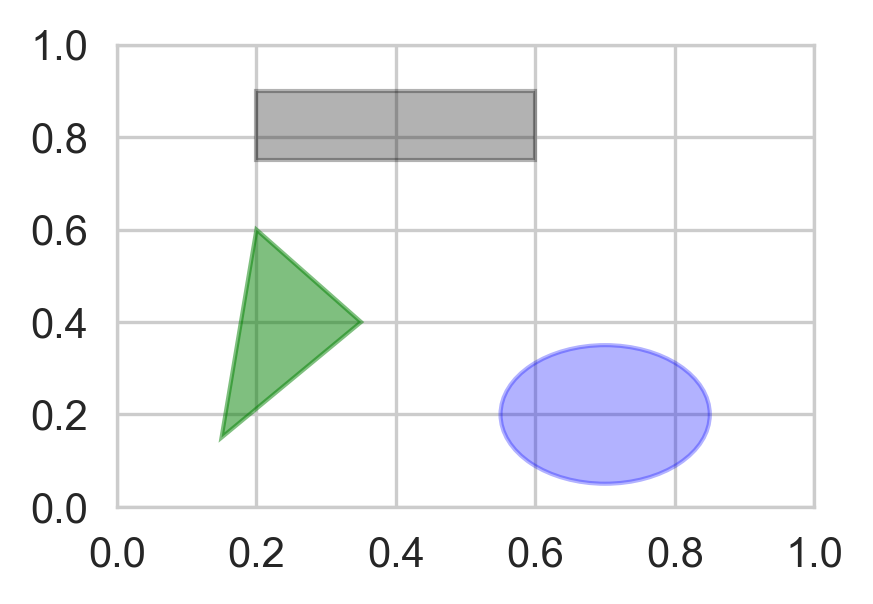
matplotlib有一些表示常见图形的对象。这些对象被称为块(patch)。其中有些(如Rectangle和Circle),可以在matplotlib.pyplot中找到,但完整集合位于matplotlib.patches。
要在图表中添加一个图形,你需要创建一个块对象shp,然后通过ax.add_patch(shp)将其添加到subplot中
fig = plt.figure(dpi=300,figsize=[3,2])
ax = fig.add_subplot(1,1,1)
rect = plt.Rectangle((0.2, 0.75), 0.4, 0.15, color='k', alpha=0.3)
circ = plt.Circle((0.7, 0.2), 0.15, color='b', alpha=0.3)
pgon = plt.Polygon([[0.15, 0.15], [0.35, 0.4], [0.2, 0.6]],
color='g', alpha=0.5)
ax.add_patch(rect)
ax.add_patch(circ)
ax.add_patch(pgon)
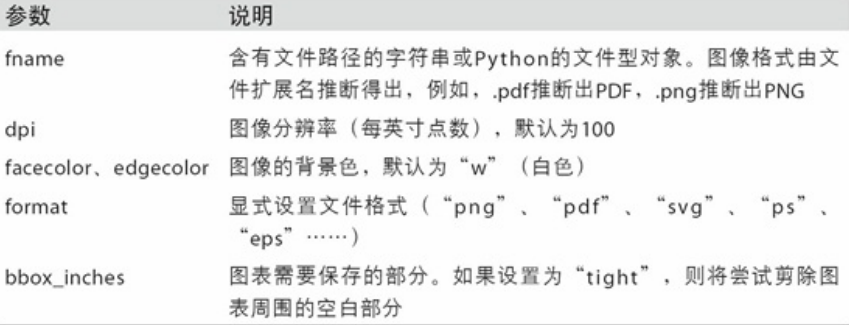
将图表保存到文件
利用plt.savefig可以将当前图表保存到文件。该方法相当于Figure对象的实例方法savefig。
文件类型是通过文件扩展名推断出来的。
需要保存的图表无疑是为发表而用的,所以有两个参数最重要:其他参数见下图
- dpi(控制“每英寸点数”分辨率)
- bbox_inches(可以剪除当前图表周围的空白部分)
比如我们需要输出最小白边300dpi的png图片:
plt.savefig('figpath.png', dpi=400, bbox_inches='tight')
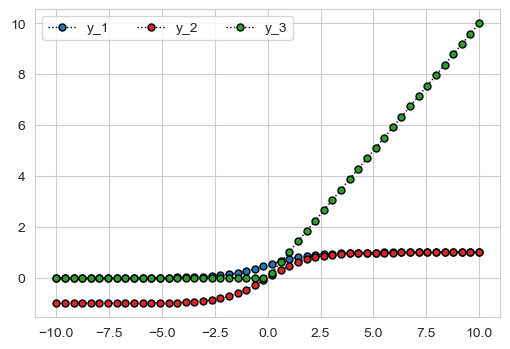
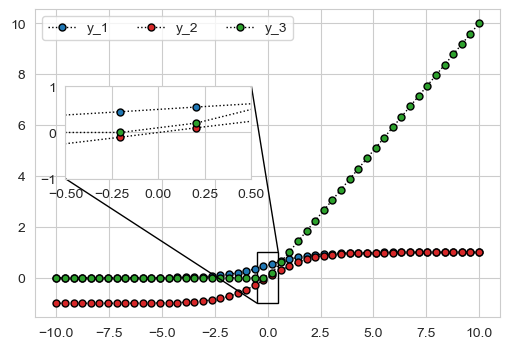
局部放大
准备数据
#浅浅画一下激活函数
from mpl_toolkits.axes_grid1.inset_locator import mark_inset
from mpl_toolkits.axes_grid1.inset_locator import inset_axes
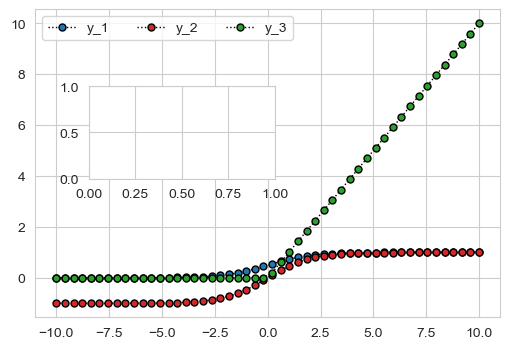
x = np.linspace(-10,10,50)
y_1 = 1/(1+np.exp(x)**(-1))
y_2 = (1 - np.exp(-x))/(1 + np.exp(-x))
y_3 = np.where(x<0,0,x)
fig, ax = plt.subplots(1, 1, figsize=(6, 4))
ax.plot(x, y_1, color='k', linestyle=':', linewidth=1,
marker='o', markersize=5,
markeredgecolor='black', markerfacecolor='C0')
ax.plot(x, y_2, color='k', linestyle=':', linewidth=1,
marker='o', markersize=5,
markeredgecolor='black', markerfacecolor='C3')
ax.plot(x, y_3, color='k', linestyle=':', linewidth=1,
marker='o', markersize=5,
markeredgecolor='black', markerfacecolor='C2')
ax.legend(labels=["y_1", "y_2","y_3"], ncol=3)
再需要导入两个依赖
from mpl_toolkits.axes_grid1.inset_locator import mark_inset
from mpl_toolkits.axes_grid1.inset_locator import inset_axes
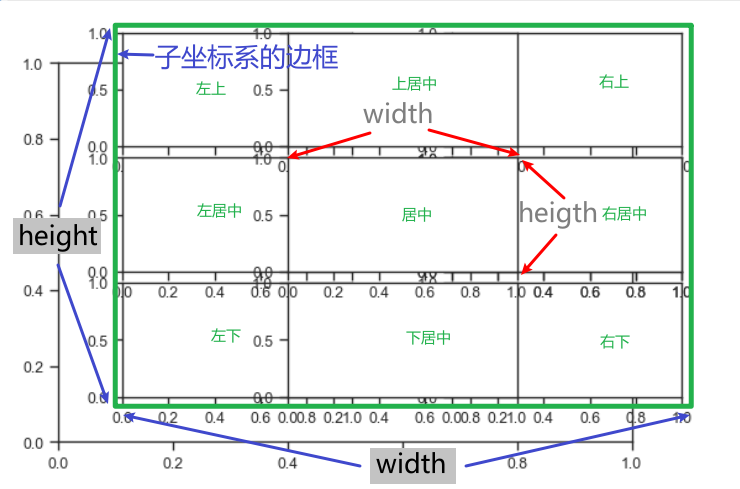
嵌入绘制局部放大图的坐标系
- inset_axes()方法
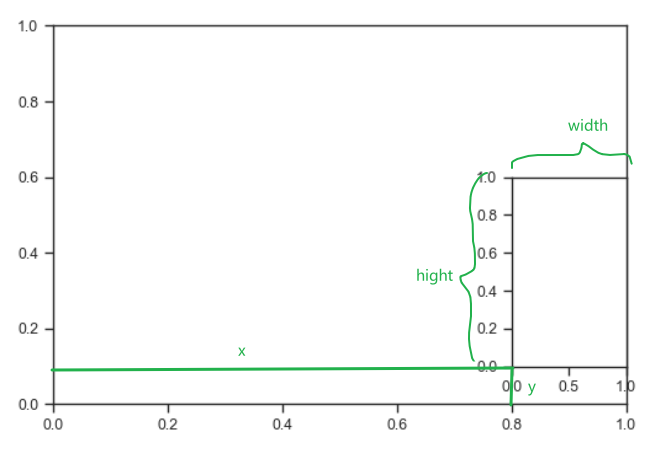
axins = inset_axes(ax, width="40%", height="30%", loc='lower left',
bbox_to_anchor=(0.1, 0.1, 1, 1),
bbox_transform=ax.transAxes)
ax:父坐标系
width, height:子坐标系的宽度和高度(百分比形式或者浮点数个数)
loc:子坐标系的位置
bbox_to_anchor:边界框,四元数组(x0, y0, width, height)
bbox_transform:从父坐标系到子坐标系的几何映射
axins:子坐标系实例化
loc:
'upper right', 'upper left', 'lower left', 'lower right', 'right', 'center left', 'center right', 'lower center', 'upper center', 'center'
- inset_axes()函数
axins = ax.inset_axes(
bounds=[0.8, 0.1, 0.2, 0.5]
)
bounds : [x0, y0, width, height]
#创建子坐标系
axins = inset_axes(ax, width="40%", height="30%", loc='center left',
bbox_to_anchor=(0.1, 0.1, 1, 1),
bbox_transform=ax.transAxes)
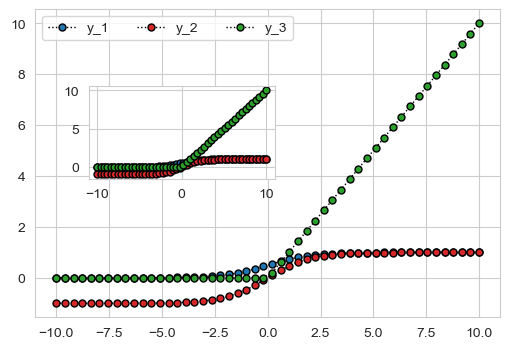
在子坐标系中绘制原始图形
axins.plot(x, y_1, color='k', linestyle=':', linewidth=1,
marker='o', markersize=5,
markeredgecolor='black', markerfacecolor='C0')
axins.plot(x, y_2, color='k', linestyle=':', linewidth=1,
marker='o', markersize=5,
markeredgecolor='black', markerfacecolor='C3')
axins.plot(x, y_3, color='k', linestyle=':', linewidth=1,
marker='o', markersize=5,
markeredgecolor='black', markerfacecolor='C2')
设置放大区间,调整子坐标系的显示范围
原理:子图的大小是不会变的,我们可以吧x的范围减小,这样就达到了,缩小的效果
# 调整子坐标系的显示范围
axins.set_xlim(-0.5,0.5)
axins.set_ylim(-1,1)
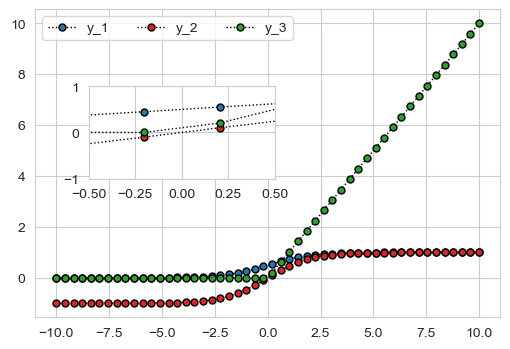
# loc1 loc2: 坐标系的四个角
# 1 (右上) 2 (左上) 3(左下) 4(右下)
mark_inset(ax, axins, loc1=3, loc2=1, fc="none", ec='k', lw=1)
fig
自定义
setp()
matplotlib有一个顶级的修改函数setp,还有一个顶级的查看属性的函数getp
setp(obj, *args, **kwargs)
下一级修改函数
matplotlib自带一些配色方案,以及为生成出版质量的图片而设定的默认配置信息。幸运的是,几乎所有默认行为都能通过一组全局参数进行自定义,它们可以管理图像大小、subplot边距、配色方案、字体大小、网格类型等。
一种Python编程方式配置系统的方法是使用rc方法。
#将全局的图像默认大小设置为10*10
plt.rc('figure', figsize=(10, 10))
rc的第一个参数是希望自定义的对象,如'figure'、'axes'、'xtick'、'ytick'、'grid'、'legend'等。其后可以跟上一系列的关键字参数。一个简单的办法是将这些选项写成一个字典:
font_options = {'family' : 'monospace',
'weight' : 'bold',
'size' : 'small'}
#**可以将迭代器展开
plt.rc('font', **font_options)
对于所有的自定义,我们应该有面对对象的思想,figure是最终的图像,而axe是其中的一个图表。
一般来说我们对figure的自定义不会很多。都是对axe对象的调整,对于常用的参数,我们只需要使用axe.set_...即可,其他比较繁琐的可以使用seaborn来操作,更加复杂的可能要再出一片文章详细讲解。
- 比较简单的可以直接
set:xlim,xlabel,title - 但是比较复杂的我们就需要先实例化,然后再具体操作
labels = ax.get_xticklabels() plt.setp(labels, rotation=45, horizontalalignment='right')
相信只要有了这一种面对对象的思想,对于想要调整的属性只需要简单查询即可。
seaborn包有若干内置的绘图主题或类型,它们使用了matplotlib的内部配置来美化。
matplotlib基础颜色定义
matplotlib并没有创造颜色的索引方式。定义一种颜色的方式很多,matplotlib中使用了RGB,RGBA,CMYK,灰色等方法。
RGB
使用红、绿、蓝三原色的亮度来定量表示颜色,这种模型也称为加色混色模型,是以RGB三色光互相叠加来实现混色的方法。
- 小数模式:
(r, g, b),对应R、G、B。每个元素取值[0,1] - 16进制字符串模式:以#开头后面6位16进数字,每2位一组,对应R、G、B,例如
#FFFFFF
RGBA
其中A = alpha,表示不透明度
- 小数模式
- 16进制字符串模式
16进制简写规则:每组数字如果2个数字相同可简写为1个,例如
#FFFFFF可简写为#FFF。
CMYK模型
C:Cyan = 青色,又称为天蓝色或是湛蓝,M:Magenta = 品红色,又称为洋红色;Y:Yellow = 黄色;K:blacK=黑色。
灰色模型
灰度模型使用黑色调表示物体,即用黑色为基准色,不同的饱和度的黑色来显示图像。 每个灰度对象都具有从 0%(白色)到100%(黑色)的亮度值。 使用黑白或灰度扫描仪生成的图像通常以灰度显示。
- 灰度小数字符串模式:小数字符串,表示灰度,小数取值范围为0到1,例如'0.5'。
默认色彩循环,Cn彩色定义
由字符串C和1个非负整数构成,数字为默认色彩循环rcParams["axes.prop_cycle"]的索引,
rcParams["axes.prop_cycle"]
(default:
cycler('color',
['#1f77b4', '#ff7f0e',
'#2ca02c', '#d62728',
'#9467bd', '#8c564b',
'#e377c2', '#7f7f7f',
'#bcbd22', '#17becf']))。
当数字超过9时,对应的颜色索引为数字个位数索引,例如C101和C1的取值相同。
注意C必须为大写。
matplotlib大部分绘图函数、方法的颜色属性指向默认色彩循环,这也是为什么默认图表的颜色经常为蓝色的原因。
其他表示方法
基础颜色字符:长度为1的字符串,取值范围为{'b', 'g', 'r', 'c', 'm', 'y', 'k', 'w'}对应RGB模型、CMYK模型的基础色和白色。X11/CSS4 ("html")模式的色彩名称:字符串,比如"blue"。
xkcd色彩名称:以xkcd:开头的字符串,对应xkcd社区定义的色彩映射,例如'xkcd:sky blue'。- Tableau色彩定义:以tab:开头的字符串,取值范围为:{'tab:blue', 'tab:orange', 'tab:green', 'tab:red', 'tab:purple', 'tab:brown', 'tab:pink', 'tab:gray', 'tab:olive', 'tab:cyan'},对应默认的色彩循环,例如'tab:blue'等于C0。色彩取自Tableau的tab10调色盘。
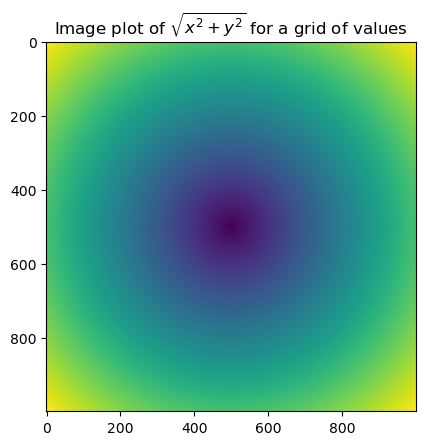
matplotlib的cmap
colormap的简称,用于指定渐变色,默认的值为viridis, 在matplotlib中,内置了一系列的渐变色,
第一种使用方法:
import matplotlib as plt
plt.imshow(zz, cmap=mpl.colormaps['viridis'])
plt.title("Image plot of $\sqrt{x^2 + y^2}$ for a grid of values")
第二种使用方法:
plt.imshow(zz, cmap=plt.cm.viridis); plt.colorbar()
plt.title("Image plot of $\sqrt{x^2 + y^2}$ for a grid of values")
递增递减

发散

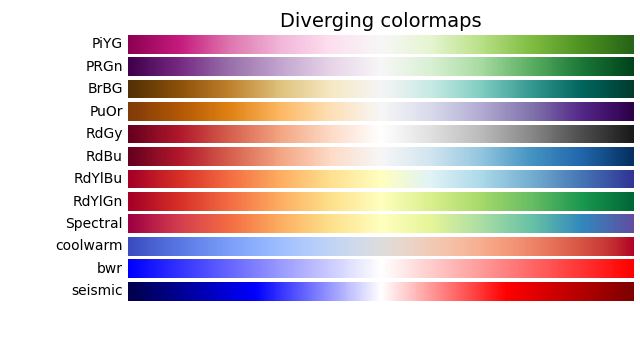
循环

颜色不代表可是效果,为了美观
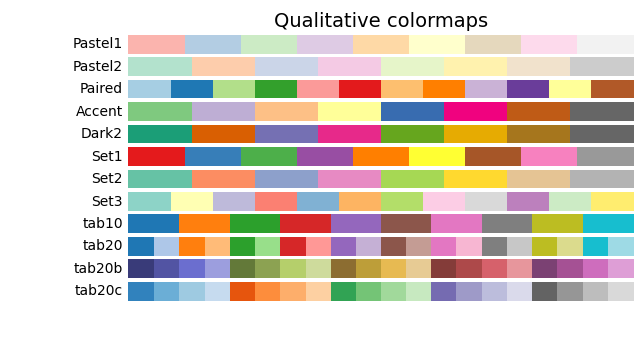
sns的palette
以下两个语句都能设置palette
sns.set_pelettesns.color_palette- 可以在
with sns.color_palette():中使用
- 可以在
分类画板
连续画板
- “rocket”


- “flare”


- “crest”


- “mako”


离散画板
- vlag

- icefire

自定义画板
通过改变sns.color_palette()的palette参数。
可以传入palette的参数包括:
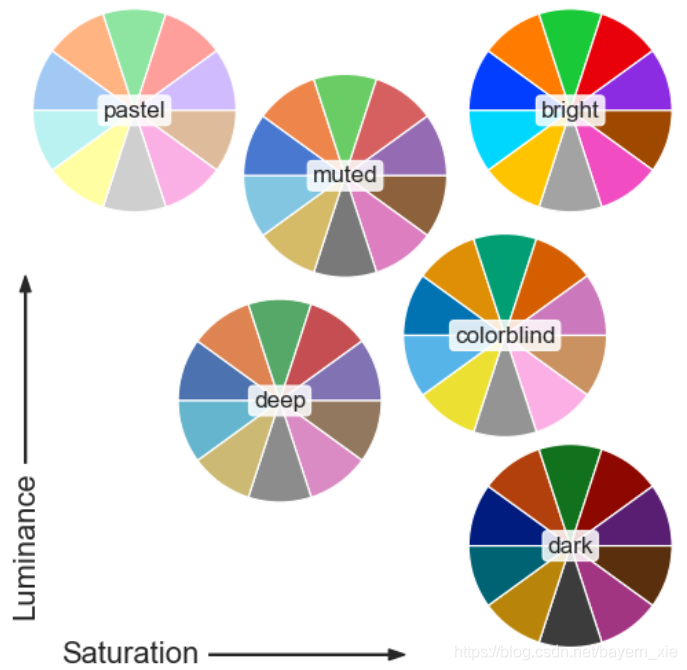
- Name of a seaborn palette (deep, muted, bright, pastel, dark, colorblind)
- Name of matplotlib colormap
- 'husl' or 'hls'
- 'ch:
' - 'light:
', 'dark: ', 'blend: , ', - A sequence of colors in any format matplotlib accepts
使用pandas和seaborn绘图
在pandas中,我们有多列数据,还有行和列标签。pandas自身就有内置的方法,用于简化从DataFrame和Series绘制图形。Seaborn简化了许多常见可视类型的创建。
引入seaborn会修改matplotlib默认的颜色方案和绘图类型,以提高可读性和美观度。即使你不使用seaborn API,你可能也会引入seaborn,作为提高美观度和绘制常见matplotlib图形的简化方法。
热力图
hexbin图
常见属性说明
#数据集
x=None,
y=None,
data=None,
#分类,str
hue=None,
#分类成多个图表,str。比如一个male,female
col=None,
row=None,
#调色板,这是美化的重点会放在后面详细的奖
palette=None,
#如果有多个图表,输出的时候,每行的个数。
col_wrap=None,
#线宽
linewidth=1
aspect=1,
#图上点的形状
markers='o',
markersize=5,
markeredgecolor='black'
markerfacecolor='C3'
#如果多个图的话,座标轴刻度是否要统一
sharex=None,
sharey=None,
#朝向,'vertical','historical'
orient=None
#标签
legend=True,
legend_out=None,
#网格线是否打开
grid=bool
线图
s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10))
s.plot()
该Series对象的索引会被传给matplotlib,并用以绘制X轴。可以通过use_index=False禁用该功能。X轴的刻度和界限可以通过xticks和xlim选项进行调节,Y轴就用yticks和ylim。

- ax:
pandas的大部分绘图方法都有一个可选的ax参数,它可以是一个matplotlib的subplot对象。这使你
能够在网格布局中更为灵活地处理subplot的位置。
而DataFrame的plot方法会在一个subplot中为各列绘制一条线,并自动创建图例
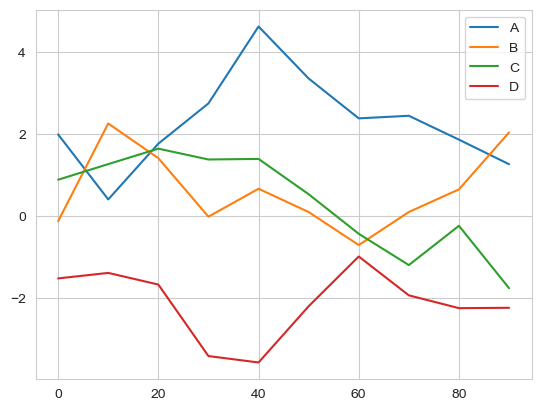
df = pd.DataFrame(np.random.randn(10, 4).cumsum(0),
columns=['A', 'B', 'C', 'D'],
index=np.arange(0, 100, 10))
df.plot()

柱状图
plot属性包含一批不同绘图类型的方法。例如,df.plot()等价于df.plot.line()。所以还可以化很多图。
plot.bar()和plot.barh()分别绘制水平和垂直的柱状图。这时,Series和DataFrame的索引将会被用
作X(bar)或Y(barh)刻度
对于DataFrame,柱状图会将每一行的值分为一组,并排显示。
df = pd.DataFrame(np.random.rand(6, 4),
index=['one', 'two', 'three', 'four', 'five', 'six'],
columns=pd.Index(['A', 'B', 'C', 'D'], name='Genus'))
#复习一下面对对象,实例化思想
labels_1 = df.plot.bar().get_xticklabels()
plt.setp(labels_1, rotation=45, horizontalalignment='right')
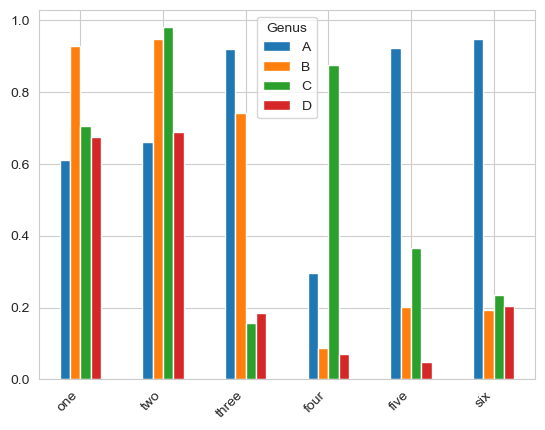
注意,DataFrame各列的名称"Genus"被用作了图例的标题。
#设置stacked=True即可为DataFrame生成堆积柱状图,这样每行的值就会被堆积在一起
df.plot.barh(stacked=True, alpha=0.5)
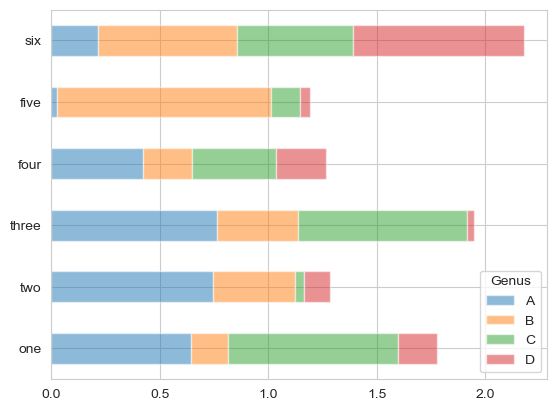
笔记:柱状图有一个非常不错的用法:利用value_counts图形化显示Series中各值的出现频
率,比如s.value_counts().plot.bar()。当然如果会高级统计图的话
下面让我们看看实现上面的笨办法和seaborn的强大之处。
#来导入seaborn最经典的tips数据集
tips = sns.load_dataset('tips')
#假设我们想要做一张堆积柱状图以展示每天各种聚会规模的数据点的百分比
#1.首先数据不对,所以我们要进行提取,使用交叉表crosstab:于计算分组频率的特殊透视表
party_counts = pd.crosstab(index=tips['day'], columns=tips['size'])
#2.数据归一化,每个size都除以每个size的sum,这里需要注意两个axis是不一样的:
#sum是求列的总和,所以axis=1
#div是每一行都除以sum
party_pct = party_counts.div(party_counts.sum(axis=1), axis=0)
labels__1 = party_pct.plot.bar().get_xticklabels()
plt.setp(labels__1, rotation=45,horizontalalignment='right')
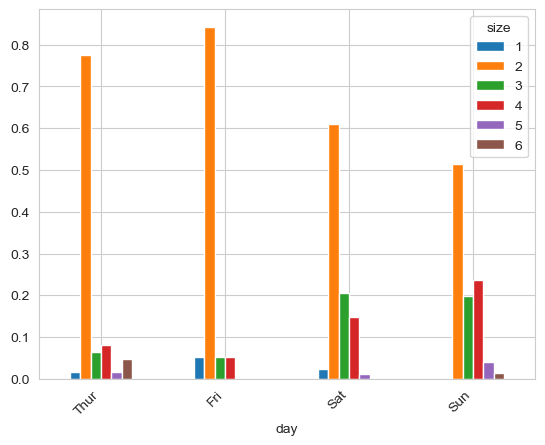
使用seaborn可以使得我们对数据的处理变得少。
import seaborn as sns
#用seaborn来看每天的小费比例
tips['tip_pct'] = tips['tip'] / (tips['total_bill'] - tips['tip'])
sns.barplot(x='tip_pct', y='day', data=tips, orient='h')

柱状图的值是tip_pct的平均值。绘制在柱状图上的黑线代表95%置信区间(可以通过可选参数ci配置)。
直方图和密度图
- 直方图(histogram)是一种可以对值频率进行离散化显示的柱状图。数据点被拆分到离散的、间隔均匀的面元中,绘制的是各面元中数据点的数量。
直方图也是用柱子进行标注的,而柱形图和直方图犹如孪生兄弟般让很多人都傻傻分不清。
直方图是用来表示某种属性再群体中的分布,两个条形之间的差距是按照数据来的。
柱状图是主要是用来查询的。
分布情况就意味着我们只需要知道大致的趋势,再找到极值就可以对样本做出大致的印象。
- bins 将数据分成几组。
- 如果是int,则表示要将所有数据平均分成n组进行绘图
- 如果是list,则是指定每一组的临界值
- range 样本中拿来绘制的范围,类比xlim
- 元组
- density 可以将y轴转化成密度刻度(建议直接看后面密度图)
- 布尔值
- weight 权重
- cumulative cumsum
fig,axes = plt.subplots(2, 2, figsize=(6,5), dpi=400,sharex='all', sharey='all')
tips['tip_pct'].plot.hist(bins=50, linewidth=0, ax=axes[0,0])
tips['tip_pct'].plot.hist(bins=60, linewidth=0, ax=axes[0,1])
tips['tip_pct'].plot.hist(bins=80, linewidth=0, ax=axes[1,0])
tips['tip_pct'].plot.hist(bins=100, linewidth=0, ax=axes[1,1])
fig
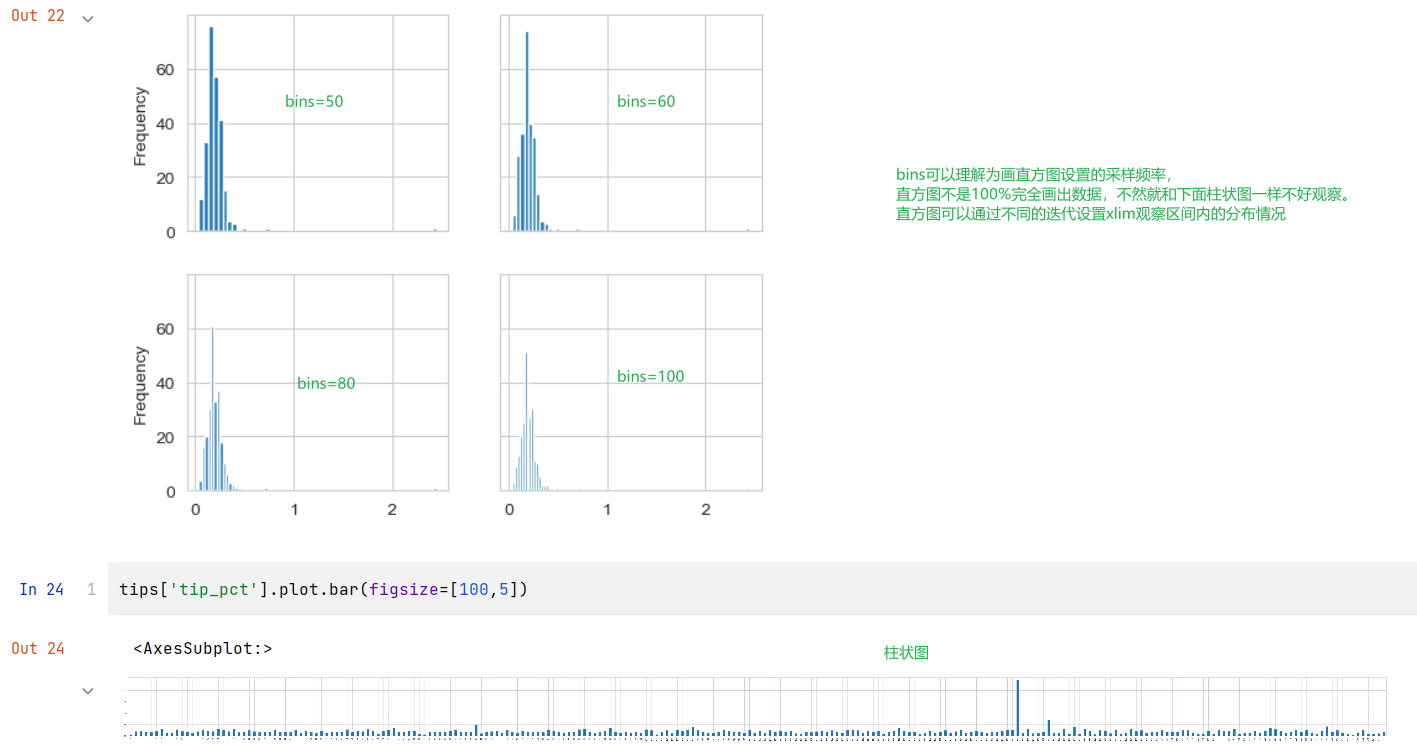
标准直方图的‘柱子’之间是没有间隔的,datespell的这个配色中每个柱子有外边框而且是白色的设置linewidth参数来设置
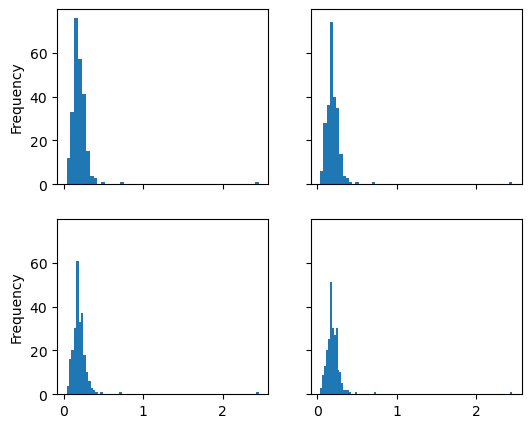
- 密度图的效果也和此类似,计算可能会产生观测数据的连续概率分布的估计.
tips['tip_pct'].plot.density()
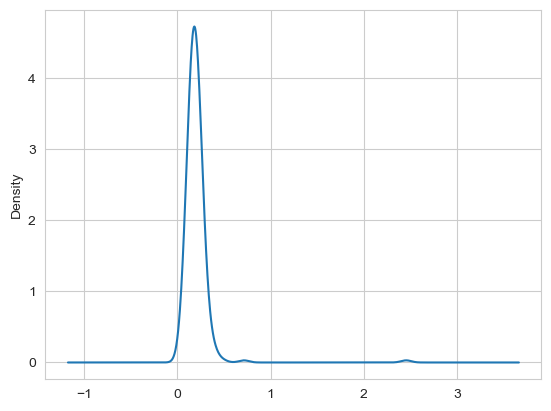
seaborn的distplot方法绘制直方图和密度图更加简单,还可以同时画出直方图和连续密度估计图。
代码运行会提示,以后会移除。但不知道为什么要移除。
散点图
点图或散布图是观察两个一维数据序列之间的关系的有效手段。
Hexbin图
如果散点很集中,会不太好看,可以使用Hexbin来代替散点图。
小提琴图
- 中位数(小提琴图上的一个白点)
- 四分位数范围(小提琴中心的黑色条)。
- 较低/较高的相邻值(黑色条形图)--分别定义为第一四分位数-1.5 IQR和第三四分位数+1.5 IQR。这些值可用于简单的离群值检测技术,即位于这些 "栅栏"之外的值可被视为离群值。

正态分布情况下三种图的展示效果
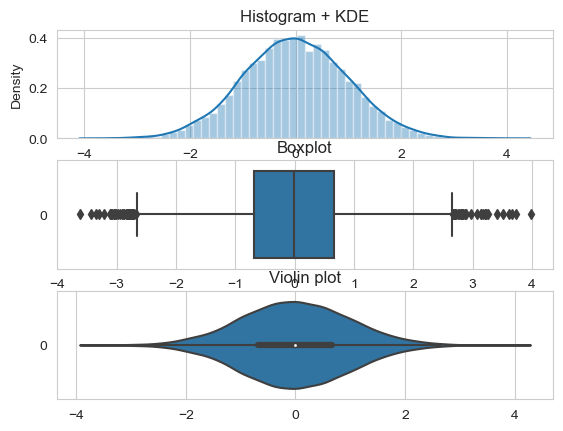
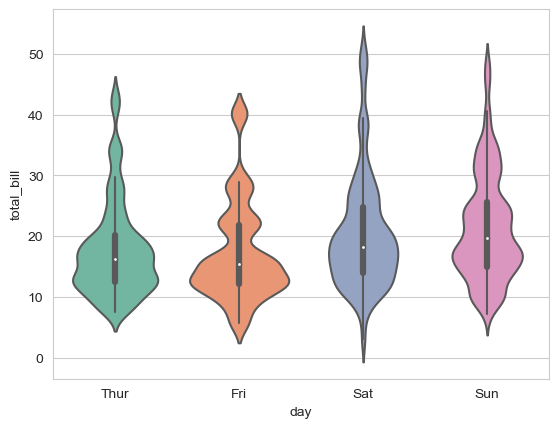
其实我们可以发现,小提琴图只需要一般就可以了,所以我们可以借此来完成对比,只需要split一下就行;
sns.violinplot(x='day', y='total_bill', hue='sex', split=True, data=tips, palette="Set2")
对比效果还是很明显的
小提琴的是核密度图和箱图的杂交,而核密度图的采样频率对最后的成图影响很大。
我们可以通过设置bw参数来设置
sns.violinplot(x='day', y='total_bill', bw=0.2, data=tips, palette="Set2")
jointplot
从名字来理解就是可以一次画两种图,属于jointgrid的特例,如果想要更加定制化操作,请上官网查询。
主图表示的是两个变量之间的关系。
join进来的图表示的是每个变量的分布情况
sns.jointplot(data=tips, x='tip', y='total_bill', kind='scatter', hue='sex', hue_order=['Male','Female'])
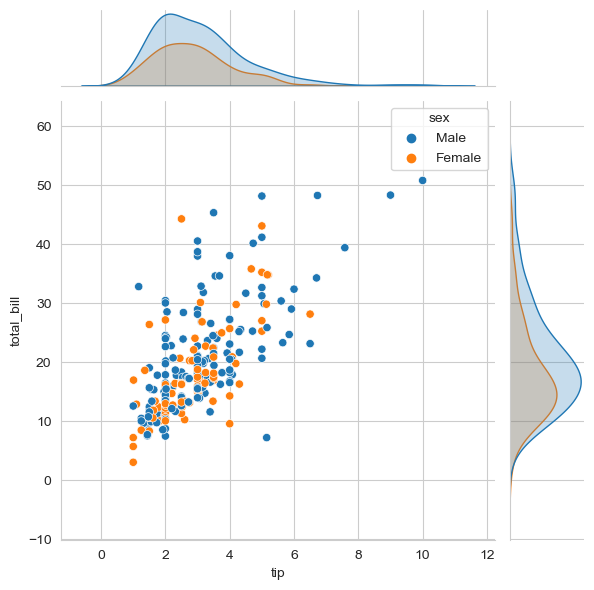
kind : { "scatter" | "kde" | "hist" | "hex" | "reg" | "resid" }
pairplot
会自动配对dataframe中可以配对的变量画出图像。注意这里和lmplot()的区别,lmplot()绘制的行(或列)是将一个变量的多个水平(分类、取值)展开,而在这里,PairGrid则是绘制了不同变量之间的线性关系。
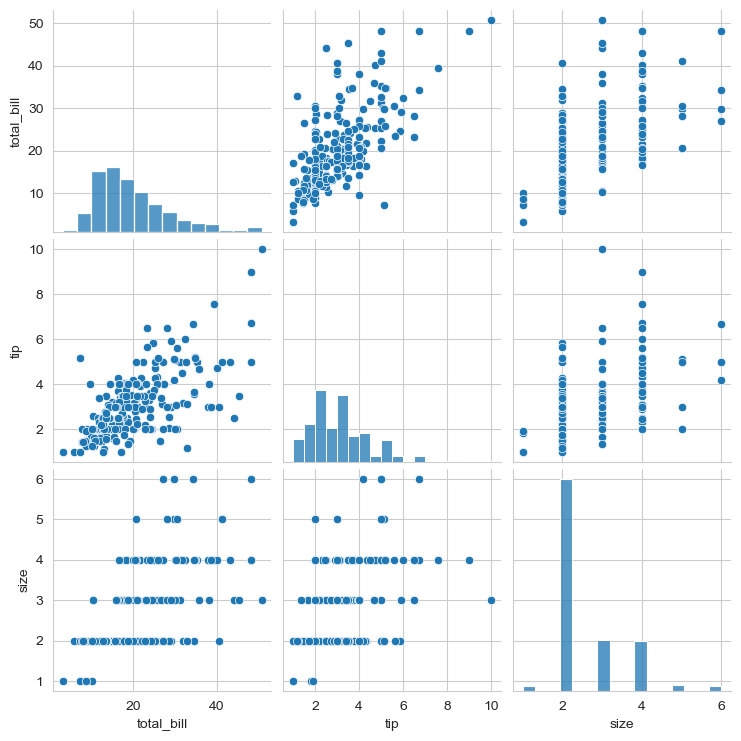
kind : 'scatter', 'kde', 'hist', 'reg'
对角线上图的类型:'auto', 'hist', 'kde', None
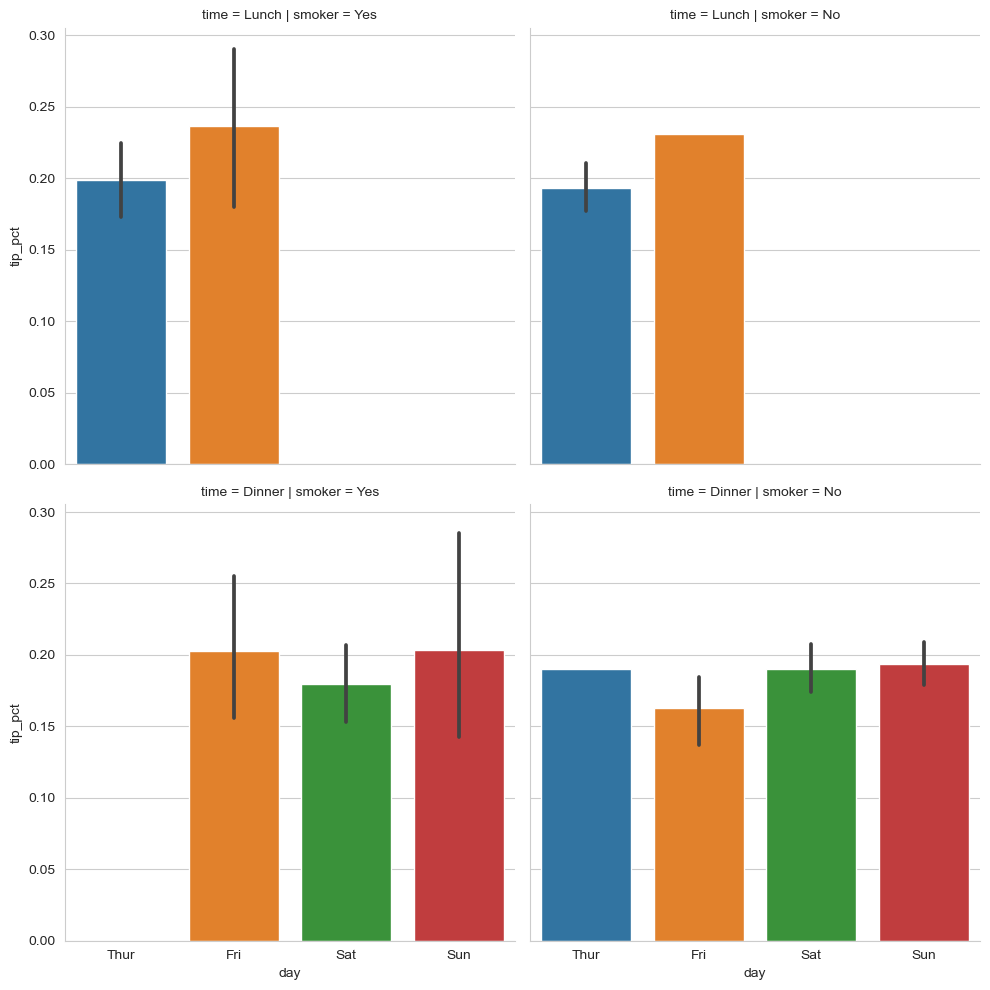
分面网格(facet grid)和类型数据
数据集可能有较多的分组维度,我们可能希望分开来看,我们可以使用seaborn中的内置函数catplot,简化制作分面图(分面图的基础做法就是一个fig,多个subplot)(有一些图的分面网格,可以直接如此设置:sns.plot(row='',col='',col_wrap=2)既可分开)
#把time和smoke分开
sns.catplot(x='day', y='tip_pct', row='time', col='smoker', kind='bar',data=tips[tips.tip_pct < 1])
#kind可选许多图 "strip", "swarm", "box", "violin",
"boxen", "point", "bar", or "count"
风格设定
这里也应用的是面对对象的思想。我们可以选定一个axe来操作,也可以直接操作。但是为了清晰起见,我们选择前者
当我们使用plt.plot的时候也可以转换为seaborn默认绘图,用sns.set()来激活
输入sns.axes_style()会返回所有seaborn可供选择的选项
{
#背景色,可以通过0(黑色)到1(白色)控制,但注意还是要str格式的
'axes.facecolor': 'white',
#轴的颜色,调整方法同上
'axes.edgecolor': '.8',
#坐标系是否有网格
'axes.grid': True,
#这涉及到了图表中元素的显示顺序,会改变轴上的突起和网格线的显示顺序.
[zorder demo](https://matplotlib.org/stable/gallery/misc/zorder_demo.html)
如果设置为False,轴和网格线会在图像的上方
'axes.axisbelow': True,
'axes.labelcolor': '.15',
#figure的颜色
'figure.facecolor': 'white',
#grid的设置
'grid.color': '.8',
'grid.linestyle': '-',
'text.color': '.15',
'xtick.color': '.15',
'ytick.color': '.15',
'xtick.direction': 'out',
'ytick.direction': 'out',
'lines.solid_capstyle': <CapStyle.round: 'round'>,
'patch.edgecolor': 'w',
'patch.force_edgecolor': True,
'image.cmap': 'rocket',
'font.family': ['sans-serif'],
'font.sans-serif': ['Arial',
'DejaVu Sans',
'Liberation Sans',
'Bitstream Vera Sans',
'sans-serif'],
'xtick.bottom': False,
'xtick.top': False,
'ytick.left': False,
'ytick.right': False,
'axes.spines.left': True,
'axes.spines.bottom': True,
'axes.spines.right': True,
'axes.spines.top': True}
如果你想定制化seaborn风格,你可以将参数传递给set_style()的参数rc。而且你只能通过这个方法来覆盖风格定义中的部分参数:
axe.set_style("darkgrid",{'axes.facecolor':"0.9"})
我们可以在全局当中定义最常用的,基本不会改变的参数,然后在每次画图的时候设置合适的自定义参数。
甚至可以写到matplotlib的配置文件matplotlibrc中,永久改变默认设置。
如果只想临时改变我们可以使用with语句:
with sns.axes_style("darkgrid"):
...
Seaborn的五种绘图风格
Seaborn有五种风格:darkgrid, whitegrid, dark, white, ticks。它们各自适合不同的应用和个人喜好。默认的主题是darkgrid。选择好自己喜欢的主题就可以在全局设置风格。
axe.set_style('whitegrid')
Seaborn绘图元素比例
有四个预置的环境:按大小排列:paper, notebook, talk, poster。notebook是默认的。
plotting_context()返回可以修改的参数, set_context()修改参数
#字体大小
'font.size': 24.0,
#标签大小
'axes.labelsize': 24.0,
#标题大小
'axes.titlesize': 24.0,
#轴上的突起
'xtick.labelsize': 22.0,
'ytick.labelsize': 22.0,
'legend.fontsize': 22.0,
'axes.linewidth': 2.5,
'grid.linewidth': 2.0,
'lines.linewidth': 3.0,
'lines.markersize': 12.0,
'patch.linewidth': 2.0,
'xtick.major.width': 2.5,
'ytick.major.width': 2.5,
'xtick.minor.width': 2.0,
'ytick.minor.width': 2.0,
'xtick.major.size': 12.0,
'ytick.major.size': 12.0,
'xtick.minor.size': 8.0,
'ytick.minor.size': 8.0,
'legend.title_fontsize': 24.0
轴脊柱
注:
white和ticks两种风格都可以移除顶部和右侧不必要的轴脊柱
使用matplotlib是无法实现这一需求的,但是使用seaborn的despine()方法可以实现。如果画图主体是matplotlib的话,可以sns.set()使用seaborn的风格渲染图片。
回归分析
美赛不需要代码,不如绘图回归一起做,哈哈哈。
lmplot()函数
1.使用模型参数来调节需要拟合的模型:order、logistic、lowess、robust、logx。默认为order。
2.针对过拟合(对样本数据过拟合,但是样本数据中本来就存在偏差,所以过拟合的结果就是,对于所用的数据表现很好,但是预测结果往往差强人意。)我们可以使用局部加权回归散点平滑法
只需要设置参数lowess=True即可。
原理是一般来说异方差的点都是有误的,而偏差小的点准确度比较高。所以给待预测点附近的每个点都赋予一定的权重,然后基于最小均方误差进行普通的线性回归。
3.对数线性回归模型
通过设置参数logx 完成线性回归转换对数线性回归,其实质上是完成了输入空间x到输出空间y的非线性映射。
注意x必须是正的。
4.稳健线性回归
在有异常值的情况下,它可以使用不同的损失函数来减小相对较大的残差,拟合一个健壮的回归模型,传入robust=True。
稳健回归是将稳健估计方法用于回归模型,以拟合大部分数据存在的结构,同时可识别出潜在可能的离群点、强影响点或与模型假设相偏离的结构。
原理是利用了对异常值十分敏感的最小二乘回归中的目标函数进行修改。
不同的目标函数定义了不同的稳健回归方法。常见的稳健回归方法有:最小中位平方法、M估计法等。
和上面针对过拟合相比,稳健性回归消除了异常值的权重。并且由于使用引导程序计算回归线周围的置信区间
- 通过ci来调整置信区间(通过bootstrap估算的)的大小.c in int[0,100]
sns.lmplot(x='',y='',data=...,hue=...,ci = 60)
- n_boot:int:用于估计的重采样次数。默认值试图平衡时间和稳定性。
5.多项式回归
在存在高阶关系的情况下,可以拟合多项式回归模型来拟合数据集中的简单类型的非线性趋势。通过传入参数order大于1,此时使用numpy.Polyfit估计多项式回归的方法。
写paper的注意事项:虽然多项式回归是拟合数据的非线性模型,但作为统计估计问题,它是线性的。在某种意义上,回归函数 在从数据估计到的未知参数中是线性的。因此,多项式回归被认为是多元线性回归的特例。
6.逻辑回归
logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释,多类可以使用softmax方法进行处理。
- {x,y}_jitter floats, 在x或y变量中加入这个大小的均匀随机噪声。对回归拟合后的数据副本添加噪声,只影响散点图的外观。这在绘制取离散值的变量时很有用。
# 制作具有性别色彩的自定义调色板
pal = dict(Up= "#6495ED", Down= "#F08080")
# 买卖随开盘价与涨跌变化
g = sns.lmplot(x= "open", y= "Buy_Sell", col= "Up_Down", hue= "Up_Down", data=dataset, palette=pal, y_jitter= .02,logistic= True)# 逻辑回归模型
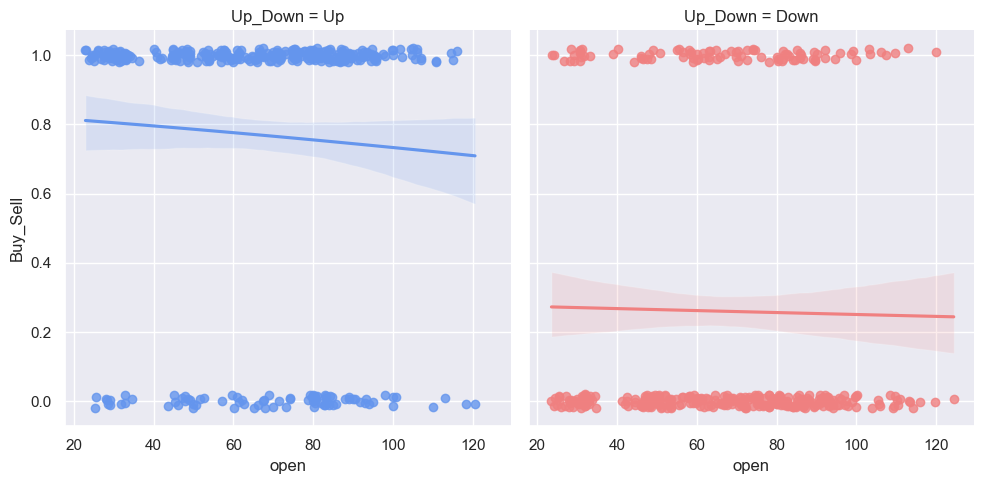
那么根据这张图我们就可以看出Down的时候回归为卖出(0),Up的时候回归为买入(1)
线性回归图-replot()
Lmplot()与regplot()与两个函数之间的主要区别是regplot()接受变量的类型可以是numpy数组、pandas序列(Series)。或者直接对data传入pandas DataFrame对象数据。而lmplot()的data参数是必须的,且变量必须为字符串。
1.线性回归
- fit_reg bool,如果为True,则估计并绘制与x 和y变量相关的回归模型。
- ci int in [ 0,100 ]或None。回归估计的置信区间的大小。这将使用回归线周围的半透明带绘制。置信区间是使用自举估算的;对于大型数据集,建议将此参数设置为"None",以避免该计算。
- scatter bool,可选。如果为True,则绘制一个散点图,其中包含基础观察值(或x_estimator值)
同样可以进行,多项式回归,逻辑回归,对数线性回归,稳健线性回归。
除了可以接受连续型数据,也可接受离散型数据。
我们可以将多个点打包在一起,然后通过x_estimator(default=np.mean)选出一个点作为代表,参与回归.
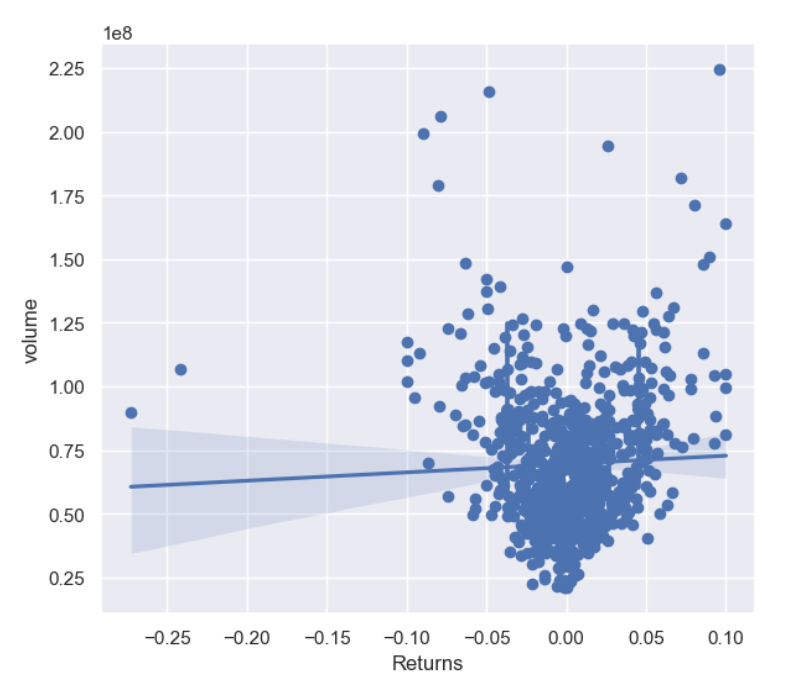
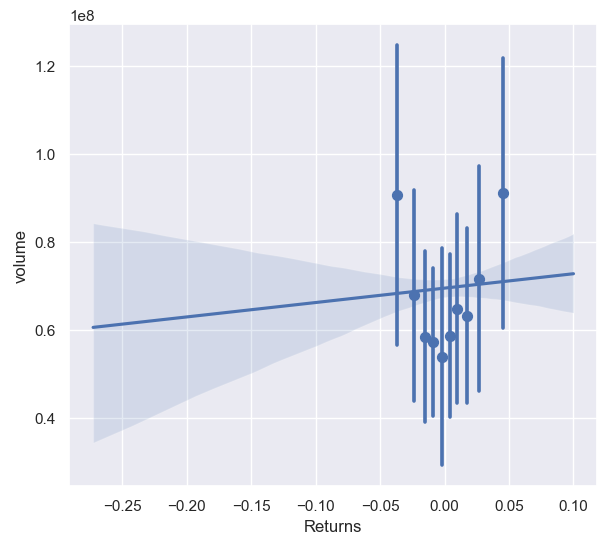
- x_estimator callable 映射向量(一系列数字)->标量(一个数字),将此函数应用于的每个唯一值,x并绘制得出的估计值。当x是离散变量时,这很有用。如果x_ci给出,该估计将被处理,并得出一个置信区间。
- x_bins int或vector,将x变量分为离散的bin,然后估计中心趋势和置信区间。这种装箱仅影响散点图的绘制方式;回归仍然适合原始数据。该参数可以解释为均匀大小(不必要间隔)的垃圾箱数或垃圾箱中心的位置。使用此参数时,表示默认x_estimator为numpy.mean。
- x_ci : “ ci”,“ sd”,[ 0,100 ]中的int或None。绘制离散值的集中趋势时使用的置信区间的大小。如果为"ci",则遵循ci参数的值 。如果为"sd",则跳过bootstrap,并在每个箱中显示观测值的标准偏差。
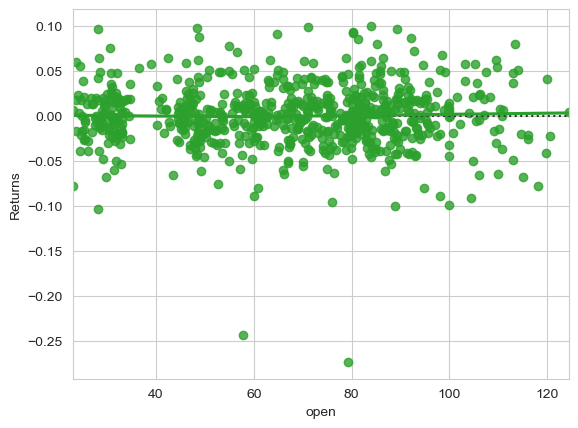
线性回归残差图residplot
residplot()用于检查简单的回归模型是否拟合数据集。它拟合并移除一个简单的线性回归,然后绘制每个观察值的残差值。通过观察数据的残差分布是否具有结构性,若有则这意味着我们当前选择的模型不是很适合。
1、线性回归的残差
此函数将对x进行y回归(可能作为稳健或多项式回归),然后绘制残差的散点图。可以选择将最低平滑度拟合到残差图,这可以帮助确定残差是否存在结构
- lowess,在残留散点图上安装最低平滑度的平滑器。
x=dataset.open
y=dataset.Returns
sns.residplot(x=x, y=y, lowess=True, color="C2")
plt.show()
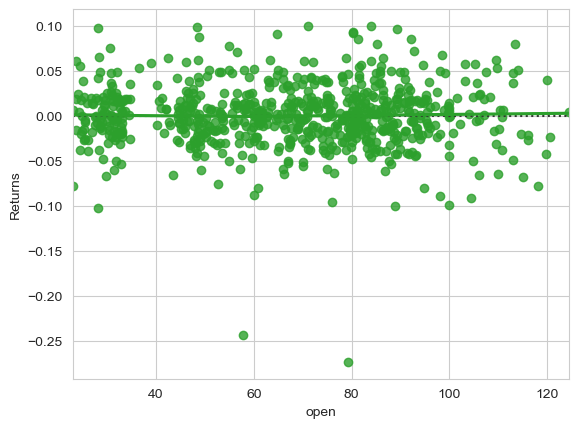
2、稳健回归残差图
robust 设置为True即可。
3、多项式回归残差图
通过设置order来确定次数
其他背景中添加回归
1、jointplot
jointplot()函数在其他更大、更复杂的图形背景中使用regplot()。jointplot()可以通过kind="reg"来调用regplot()绘制线性关系。
2、pairplot
给pairplot()传入kind="reg"参数则会融合regplot()与PairGrid来展示变量间的线性关系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号