ENVIFormat开源样本库使用教程
前段时间分享了两个开源样本库:GID-ENVIFormat和Five-Billion-Pixels-ENVIFormat样本库。这两个样本库均包含大量影像底图和高质量的样本数据。GID-ENVIFormat样本库包含5类别和15类别样本数据,Five-Billion-Pixels-ENVIFormat包含24类别样本数据。有关样本库数据的获取可参考:
GID-ENVIFormat样本库获取链接:https://www.cnblogs.com/enviidl/p/18195824
Five-Billion-Pixels-ENVIFormat样本库获取链接:https://www.cnblogs.com/enviidl/p/18245365
有了样本数据,就可以使用ENVI深度学习工具方便地进行深度学习模型训练和图像分类了。本文以Five-Billion-Pixels-ENVIFormat样本库数据的使用为例,介绍使用ENVI深度学习工具进行图像信息提取的操作流程。
1. 选择数据
在进行深度学习操作之前,首先要确定使用的数据,样本库中包含了8位3波段RGB图像和16位4波段原始图像,根据待分类图像的类型选择使用的影像底图。如果待分类的图像是3波段字节型数据可选择8bit_RGB数据进行后续的模型训练。如果是原始4波段数据,可以使用16bit_BGRNir数据进行模型训练。

2. 生成标签图像
确定好底图数据之后,需要和分类图像一起生成标签图像,从而训练深度学习模型。Image_Class文件夹中的数据为分类图像。在ENVI工具箱中,使用由分类图像构建标签图像工具(Build Label From Classification)。
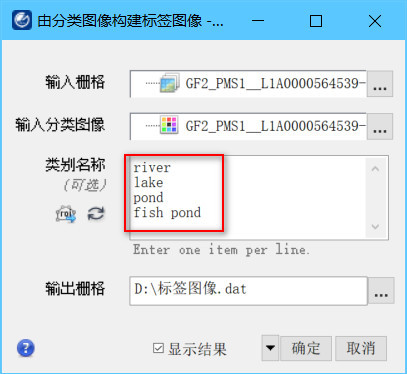
在工具中,输入栅格选择影像底图,输入分类图像选择已有分类图像。在类别名称选项中,选择性地输入分类图像中已有的类别名。如果不设置,默认提取所有类别从而生成标签图像。如果仅想提取单独的几个类别,可输入这几个类别的类别名,例如本例中仅想提取水面相关的类别,则可在类别名称选项中输入已有的几个水面相关的类别名,从而生成标签图像。Five-Billion-Pixels-ENVIFormat样本库中包含了如下类别:
表1 Five-Billion-Pixels-ENVIFormat样本库类别
|
序号 |
英文类别名 |
中文类别名 |
|
1 |
industrial area |
工业区 |
|
2 |
paddy field |
水田 |
|
3 |
irrigated field |
灌溉田 |
|
4 |
dry cropland |
旱地 |
|
5 |
garden land |
园地 |
|
6 |
arbor forest |
乔木林地 |
|
7 |
shrub forest |
灌木林地 |
|
8 |
park |
公园 |
|
9 |
natural meadow |
天然草地 |
|
10 |
artificial meadow |
人工草地 |
|
11 |
river |
河流 |
|
12 |
urban residential |
城市居民区 |
|
13 |
lake |
湖泊 |
|
14 |
pond |
池塘 |
|
15 |
fish pond |
鱼塘 |
|
16 |
snow |
雪 |
|
17 |
bareland |
裸地 |
|
18 |
rural residential |
农村居民区 |
|
19 |
stadium |
体育场 |
|
20 |
square |
广场 |
|
21 |
road |
道路 |
|
22 |
overpass |
立交桥 |
|
23 |
railway station |
火车站 |
|
24 |
airport |
机场 |
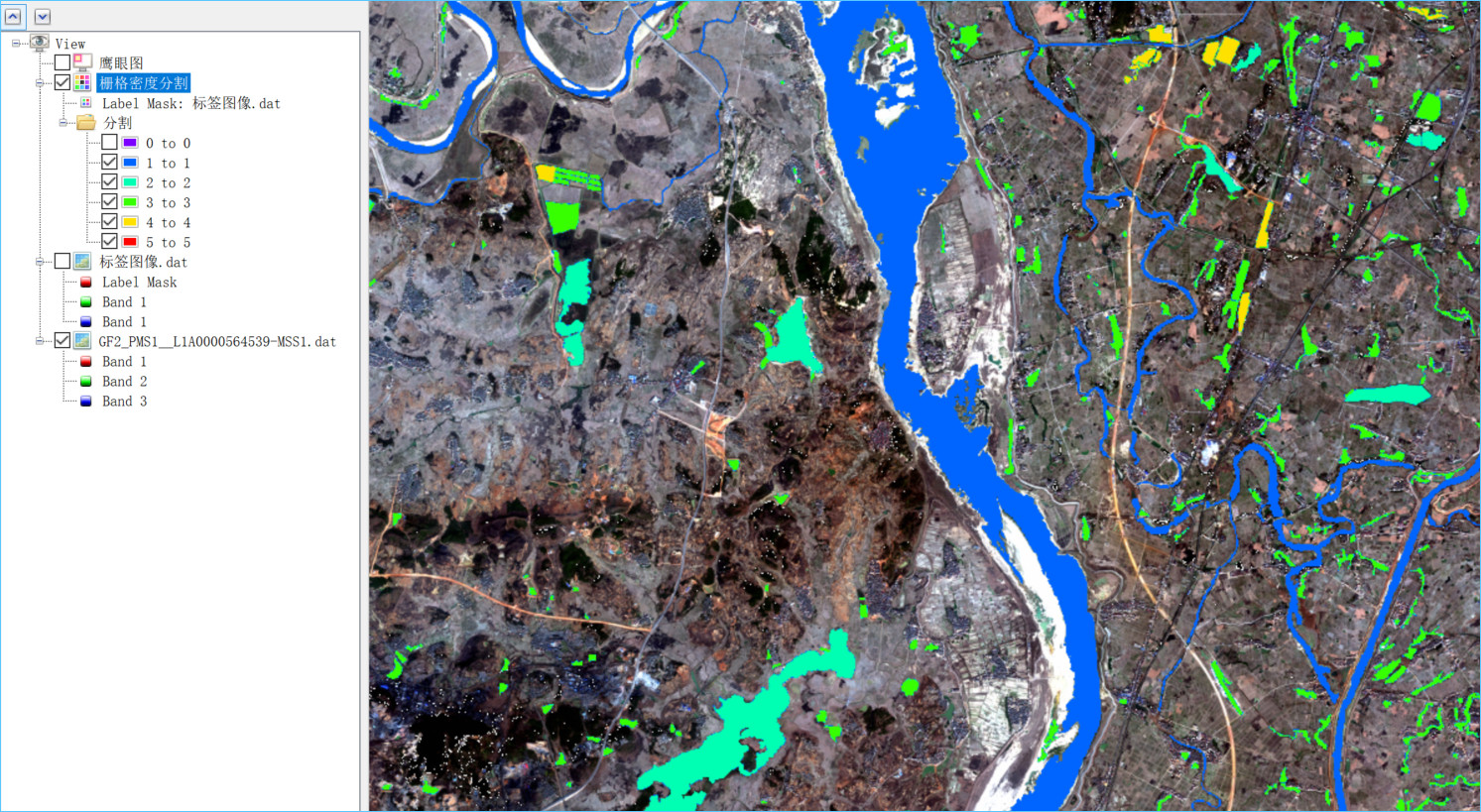
对生成的标签图像的最后一个Label Mask波段进行密度分割,可以看到里面包含的五个类别样本。
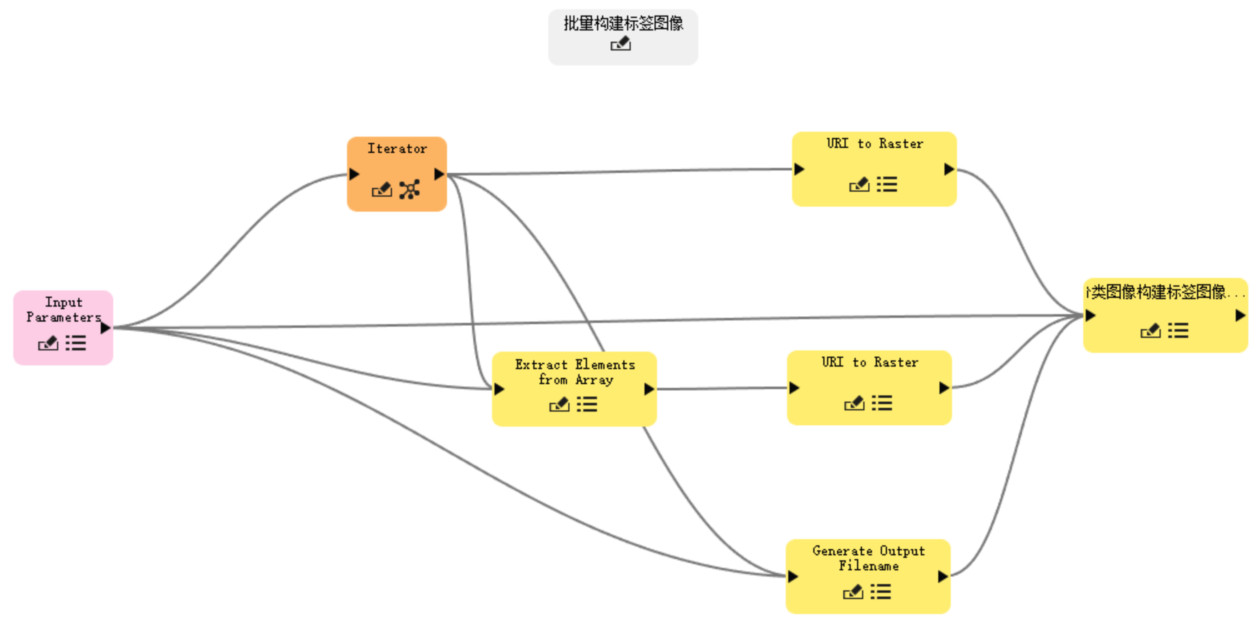
如果要批量生成标签图像,可在ENVI Modeler建模工具中构建批处理模型,如下图所示的批处理模型可在样本库获取链接中下载。
3. 训练深度学习模型
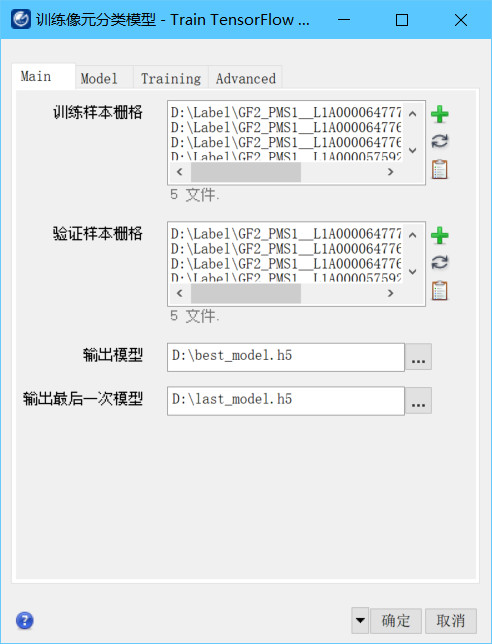
生成深度学习标签图像之后就可以进行深度学习模型训练了。ENVI深度学习需要英伟达独立显卡,推荐8G以上显存,会有一个更快的训练速度。在ENVI工具箱中,使用训练像元分类模型工具(Train TensorFlow Pixel Model)。
|
|
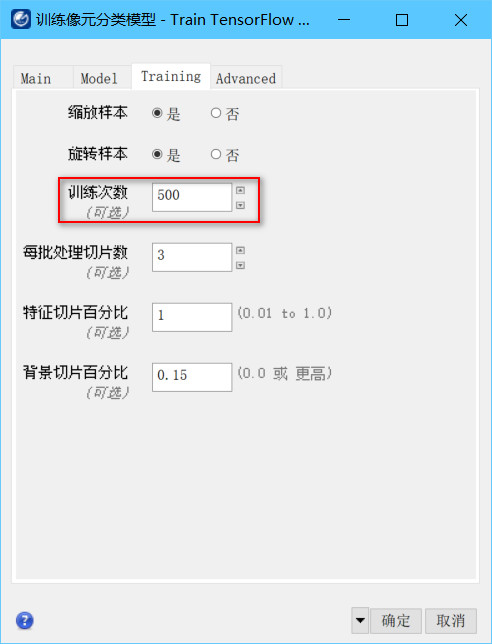
在训练像元分类模型工具Main选项卡中,训练样本栅格和验证样本栅格选择上一步生成的标签图像,设置指标最优模型和最后一次训练模型的输出路径和文件名。如果想要得到一个训练更为充分的模型,可在Training选项卡中,将训练次数设置为一个较高的次数,例如500次,这样模型会有更充分的训练。理论上训练次数越多,精度指标越趋向更高,但注意这会大大增加训练时间。
4. 图像分类
训练好模型之后就可以用训练好的模型进行其它相似图像的分类。在ENVI工具箱中,选择深度学习像元分类工具(TensorFlow Pixel Classification)进行图像分类。
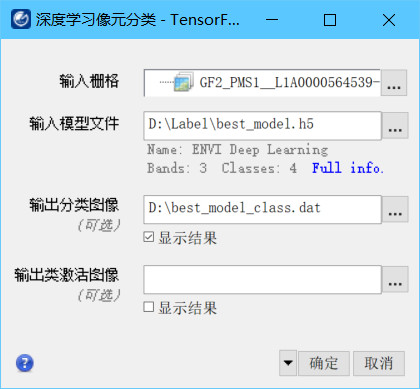
在深度学习像元分类工具中,输入栅格选择待分类图像,输入模型选择上一步中训练好的模型,设置分类图像输出路径和文件名即可对相似图像进行图像分类。如需批量化分类,也可在ENVI Modeler中构建批处理工作流。
注意:待分类图像的波段数和数据类型要尽量和训练时的影像底图一致,如果波段数量不一致,选择输入栅格的时候可以选择spectral subet波段裁剪,选择三波段或四波段数据。如果数据类型不一致,可使用相对辐射归一化等工具进行图像数据类型转换。
5. 总结
深度学习开源样本库的使用总体分为3步。第1步,使用样本数据生成标签图像(可在ENVI Modeler中进行批量标签图像生成);第2步,使用生成的标签图像训练深度学习模型;第3步,使用训练好的模型进行图像分类。通过以上3步即可利用已有的开源样本库方便地进行图像分类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号