ENVI新机器学习:随机森林遥感分类工具操作手册
1. 随机森林简介
随机森林是一种有监督的机器学习算法。监督学习是机器学习的一个子类。这种类型的学习依赖于分类标签,以生成一个函数(模型)来识别图像中的不同类别。有两种类型的分类问题,二元分类和多类分类。随机森林由于其准确性,简单性和灵活性,现已成为最广泛使用的分类算法之一。
随机森林是基于Bagging的决策树方法,其核心是bagging算法,原理如下:
给定一个大小为n的训练集D,Bagging算法从中均匀地、有放回地(使用自助抽样法)选出m个大小为n‘的子集Di作为新的训练集。在这m个训练集上使用分类、回归等算法,则可得到m个模型,再通过取平均值、取多数票等方法,即可得到Bagging结果。也即:
给定训练集X = x1, ..., xn和目标Y = y1, ..., yn,bagging方法重复(B次)从训练集中有放回地采样,然后在这些样本上训练树模型。在训练结束之后,对未知样本x的预测可以通过对x上所有单个回归树的预测求平均来实现:
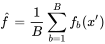
或在分类任务中选择多数投票的类别。
这种bagging方法在不增加偏置的情况下降低了方差,从而带来了更好的性能。但简单地在同一个数据集上训练多个树模型会产生强相关的树模型(甚至是完全相同的树模型)。Bagging使用Bootstrap自助抽样法,通过产生不同训练集从而降低树模型之间关联性。
此外,x'上所有单个回归树的预测的标准差可以作为预测的不确定性的估计:
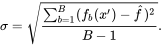
样本或者树的数量B是一个自由参数。通常使用几百到几千棵树,这取决于训练集的大小和性质。使用交叉验证,或者通过观察out-of-bag误差(那些不包含xᵢ的抽样集合在样本xᵢ的平均预测误差),可以找到最优的B值。当一些树训练到一定程度之后,训练集和测试集的误差开始趋于平稳。
随机森林就是bagging的决策树方法,有一点改进就是随机森林在学习过程中的每次候选分裂,选择特征的随机子集。这个过程也被称为“特征bagging”。
2. 运行环境
随机森林分类工具包含在新机器学习工具包内,新机器学习工具可以运行在没有高性能GPU配置的设备上。具体运行环境如下:
|
支撑软件 |
ENVI5.6.3+ENVI Deep Learning2.0 |
|
操作系统 |
◾Windows 10 and 11 (Intel/AMD 64-bit) ◾Linux (Intel/AMD 64-bit, 3.10.0及更高版本, glibc 2.17 及更高版本) |
|
硬件 |
具有AVX的CPU。 注:一般情况下,2011年之后的CPU都包含该指令集。推荐使用Intel CPU,但不是必需的,它们拥有优化的英特尔机器学习库,可为某些机器学习算法提供性能提升。 |
ENVI5.6.3试用:https://envi.geoscene.cn/envi_license,之前安装过562版本可直接覆盖安装,许可通用。
3. 操作流程
对于单张栅格图像的随机森林分类可以通过ROI工具绘制样本并使用随机森林分类工具进行图像分类。
3.1. 数据
启动ENVI,打开ENVI自带的示例数据,如下图所示。数据位于:C:\Program Files\Harris\ENVI56\data\qb_boulder_msi。ROI样本数据可下载获取(qb_boulder_msi_ROI_points.xml)。
链接:https://pan.baidu.com/s/1-28oUZ62h6abj1chzuMAkg?pwd=envi
提取码:envi
3.2. 随机森林分类流程

3.3. 样本绘制
随机森林分类属于机器学习工具,其分类算法主要利用了影像的光谱信息,其样本的绘制遵循“质量胜于数量”的原则,即绘制的样本要保证较高的光谱精度。同时随机森林算法会利用到所有的ROI像元,绘制的ROI覆盖的像元比较多的情况下会消耗较多的计算时间。因此建议绘制点状ROI样本,这样既可以保证绘制的样本精度较高,又可以节约大量的计算时间。
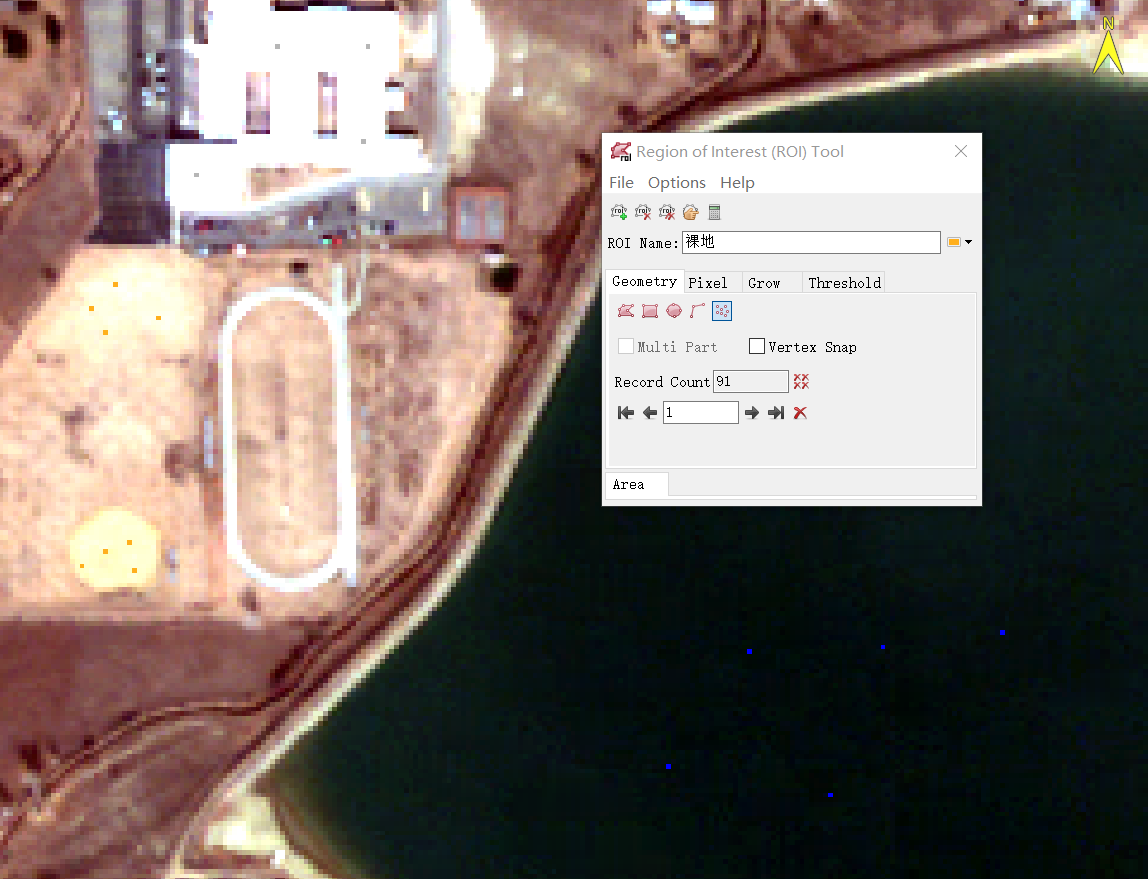
样本绘制可通过ROI工具绘制,单击ENVI工具栏中的ROI工具图标![]() ,打开Region of Interest (ROI) Tool面板,点击
,打开Region of Interest (ROI) Tool面板,点击![]() 按钮,添加一个ROI类别,修改ROI Name为“水体”。在Geometry选项卡点击
按钮,添加一个ROI类别,修改ROI Name为“水体”。在Geometry选项卡点击![]() 点状按钮,在图上找到水体区域并均匀地绘制点状ROI。之后再绘制剩余地物类型:裸地、草地、林地、建筑。绘制示例如下图所示:
点状按钮,在图上找到水体区域并均匀地绘制点状ROI。之后再绘制剩余地物类型:裸地、草地、林地、建筑。绘制示例如下图所示:
3.4. 随机森林分类
绘制好样本之后即可使用随机森林分类工具执行分类。在Toolbox工具箱,选择Machine Learning>Classification>Supercised>Random Foreast Classification随机森林分类工具。此工具对单个栅格影像执行随机森林监督分类。
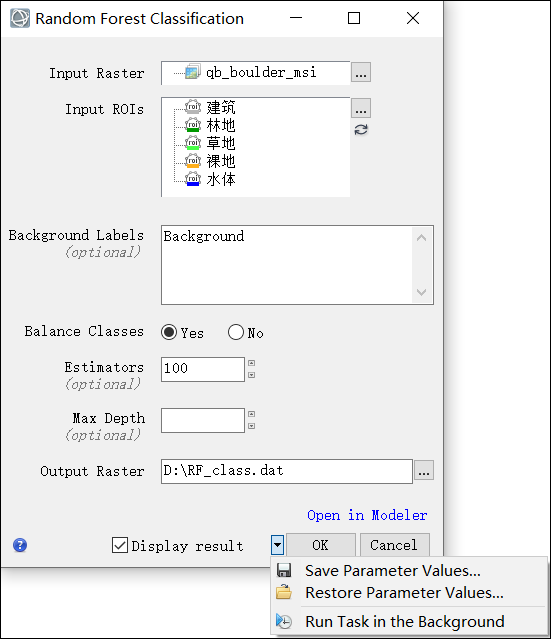
在随机森林分类对话框中:
- Input Raster:选择一个输入栅格执行随机森林分类。这里选择qb_boulder_msi影像。
- Input ROIs:选择ROI 文件 ( .xml ),包含想要分类的类别。注意ROI 必须要落在输入栅格的边界内。
- Background Labels:在“背景标签”字段中,指定要用作背景的 ROI 类。例如如果只想提取水体一类,就将其余的类别名输入在这里,表示这些类别为不感兴趣的背景类。注意,新的机器学习工具是全像素分类,因此样本类别至少为两类,一类为目标类别,一类为背景类别。此处可以按照默认Background,但不能为空。
- Balance Classes:选择是否平衡类别。默认为Yes,平衡类别表示指定在训练期间应将所有类视为平衡的。选择Yes有助于增加样本少的类别的提取范围。这里按照默认选Yes。
- Estimators:输入要使用的决策树的数量。估计器是算法的预测器。默认值为100。此处按照默认。
- Max Depth:指定树的最大深度。如果未指定,则扩展节点直到所有叶子都是纯的。
- Output Raster:选择分类结果的输出路径和文件名。
- 启用Display result复选框以在处理完成时在视图中显示输出结果。
- 要在以后再次使用这些参数设置,可以将参数保存到一个文件中。单击向下箭头并选择“Save Parameter Values...”,指定要保存到的位置和文件名。注意某些参数类型(例如栅格、矢量和ROI等文件)的设置不会保存在参数文件内。要应用已保存的参数设置,同样单击向下箭头并选择“Restore Parameter Values...”,然后选择之前保存的参数文件。
- 要在本地或远程 ENVI 服务器上运行该任务,请单击向下箭头并选择“Run Task in the Background”。ENVI Server Job Console 将显示作业的进度,并在处理完成时提供一个链接来显示结果。有关详细信息,请参阅 ENVI 帮助中的ENVI服务器主题。
- 要查看此工具的基于模型的版本(显示该工具是如何从各个子任务构建的),请单击“Open in Modeler” 。
单击OK执行随机森林分类,得到分类结果,如下图所示:
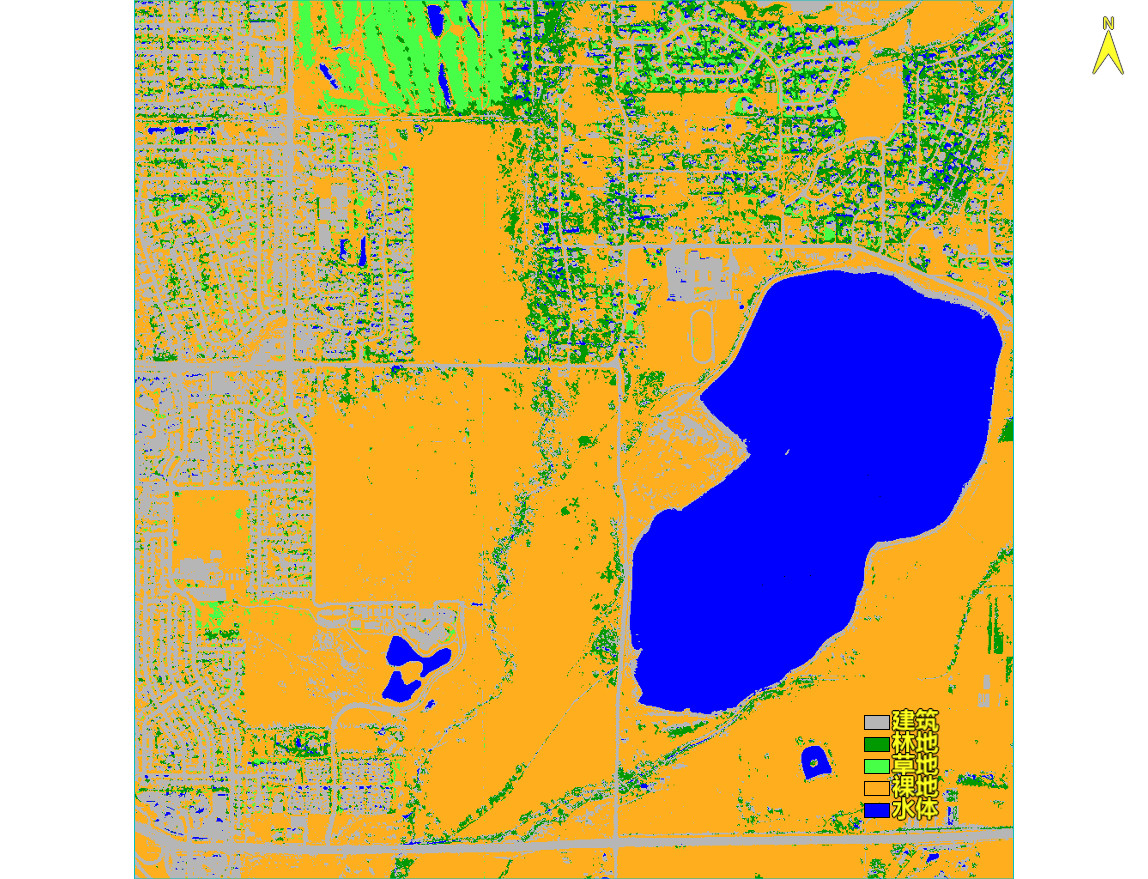
对于分类图像中的小图斑可使用分类后处理工具进行处理,参考:https://www.cnblogs.com/enviidl/p/16276676.html
4. 自定义工作流
随机森林分类工具可以对单幅影像快速执行随机森林分类,如果想要通过多幅影像和对应ROI训练随机森林模型并用于其它相似影像的分类,可以使用ENVI Modeler构建自定义可重复使用的工作流。接下来将介绍通过ENVI Modeler 构建自定义工作流,用于数据预处理和使用多个栅格进行机器学习模型训练。
4.1. 数据
本教程中使用的图像:classification下的两张用于分类的图像,以及 training 下的两张用于训练的图像。每个训练图像都是分类图像的小区域子集。图像是四波段(红/绿/蓝/近红外),空间分辨率为1米的航拍影像。ENVI 机器学习对于图像格式没有限制,对于本教程您将使用TIFF和ENVI两种格式。
注意:如果有多张影像,那么影像类型应该保持一致,如果其中一张为地表反射率,那么其余影像应该也为地表反射率数据。
|
文件 |
描述 |
|
NAIP_DallasTX_Oct11_2020_Subset.tif |
用于训练的图像(4,046 x 3,973 像素) |
|
NAIP_DallasTX_Oct11_2020_Subset.xml |
用于训练的 ROI 标签(人造地物、树木、地面、水面) |
|
NAIP_SanAntonioSE_2020_Subset.dat |
用于训练的图像(5,023 x 4,803 像素) |
|
NAIP_SanAntonioSE_2020_Subset.xml |
用于训练的 ROI 标签(人造地物、树木、地面、水面) |
|
NAIP_DallasTX_Oct11_2020.tif |
用于分类的图像(10,590 x 12,400 像素) |
|
NAIP_SanAntonioSE_2020.dat |
用于分类的图像(10,000 x 12,300 像素) |
4.2. 机器学习流程
机器学习的主要流程为训练栅格生成(影像和已有样本)、训练机器学习模型和模型分类。栅格归一化将输入的多张图像进行最大最小值归一化到0~1之间。

4.3. 使用 ENVI Modeler 创建模型
ENVI Modeler 是一个强大的可视化工具,用于使用 ENVI Task创建自定义工作流。ENVI Modeler 使用可视化方式构建流程块,类似于编写任务 API 代码。
4.3.1. 创建文件节点
- 启动 ENVI。
- 使用以下选项之一打开 ENVI Modeler:
- 按键盘上的Ctrl + M。
- 单击ENVI 菜单栏中的Display按钮,然后单击ENVI Modeler。
- 从Basic Nodes列表中双击(或点击并拖动)File到 ENVI Modeler 的 Untitled 区域。出现“Select Type”选择类型对话框。
- 在选择类型对话框中,单击Raster。选择文件 – [Raster] 对话框出现。
- 导航到您保存教程数据的位置\training,点击tif,然后点击Open。文件节点出现在无标题绘图区域中。

- 单击Basic Nodes基本节点中的另一个File文件节点并将其拖动到 ENVI Modeler 的无标题区域中。出现文件选择对话框。
- 在“Select Type”选择类型对话框中,单击“Regions of Interest”感兴趣区域。选择文件 – [ROI] 对话框打开。导航到包含教程数据的位置\training,单击xml,然后单击Open。
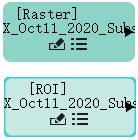
这两个文件节点由栅格图像和 ROI 标签组成。之后它们会生成一个训练栅格用于训练机器学习模型。为了保持井然有序,可以根据需要单击画布中的节点并将其拖动到合适的位置。
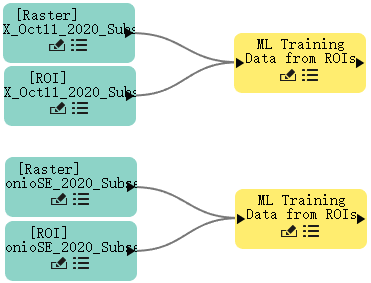
- 使用栅格文件dat和ROI文件NAIP_SanAntonioSE_2020_Subset.xml重复前两个步骤。这两个文件都位于教程数据文件夹\training中。完成后,您将拥有两个光栅文件节点和两个 ROI 节点。
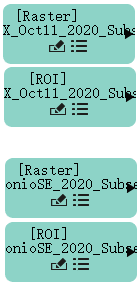
4.3.2. 准备数据
要为监督分类器创建训练数据,必须使用栅格和关联的 ROI 提取标记像素。使用 ENVI Machine Learning ML Training Data from ROIs 任务来创建训练数据。此任务将从栅格中提取所有标记像素,这些像素由.xml文件中指定的 ROI 标识。生成的训练数据是包含单行光谱的新栅格。训练栅格的维度是(行=1,列=提取的标记像素个数,波段=输入栅格波段+1)。附加波段将为每个像素提供一个数值,该数值表示每个像素的类标签值。
对于本教程,我们有类标签 Manmade、Trees、Ground、Water。这些标签解析为类值 (1, 2, 3,4)。Ground类的像素将在附加波段中分配一个值3,对于每个标记的像素依此类推。
- 在 ENVI Modeler 的“Search…”任务搜索字段中,键入ML Training。将出现两个任务。
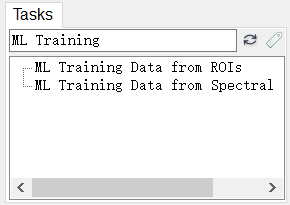
- 使用ML Training Data from ROIs来生成训练数据。ML Training Data from Spectral Library 是另一个机器学习数据准备任务,它使用光谱库收集像素数据进行训练。
- 双击ML Training Data from ROIs两次,两个名为“ML Training Data from ROIs”的黄色节点出现在画布中。

- 排列这些节点,放置在Raster和ROI文件节点的右侧。
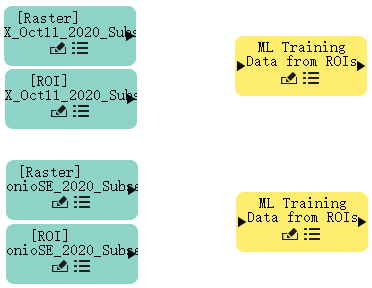
- 单击Raster节点的连接器并将其拖动到ML Training Data from ROIs。
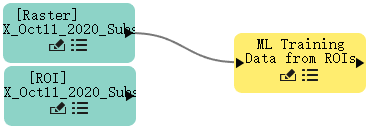
- 单击ROI节点连接器并将其拖动到ML Training Data from ROIs。
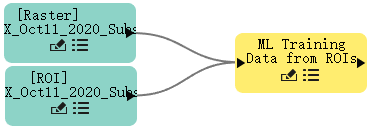
从 ROI 节点连接到ML Training Data from ROIs节点时,请务必正确配对Raster和ROI节点:
|
输入栅格 |
NAIP_DallasTX_Oct11_2020_Subset.tif |
|
输入ROI |
NAIP_DallasTX_Oct11_2020_Subset.xml |
|
输入栅格 |
NAIP_SanAntonioSE_2020_Subset.dat |
|
输入ROI |
NAIP_SanAntonioSE_2020_Subset.xml |
- 对其余两个Raster和ROI节点重复前两个步骤。如下图所示。
- 在“Search...”任务搜索中,键入Normalization Statistics标准化统计。双击Normalization Statistics。
- 一个Normalization Statistics节点出现在画布上。

- 从Basic Nodes列表中,双击Aggregator。一个 Aggregator聚合器节点出现在节点画布上。
- 单击并将两个Raster节点连接器拖动到Aggregator聚合器节点上。
- 单击Aggregator节点连接器并将其拖动到Normalization Statistics节点上。
- 单击Normalization Statistics节点连接器并将其分别拖动到两个ML Training Data from ROIs节点上。
完成这些步骤后,你的节点画布应类似于下图:
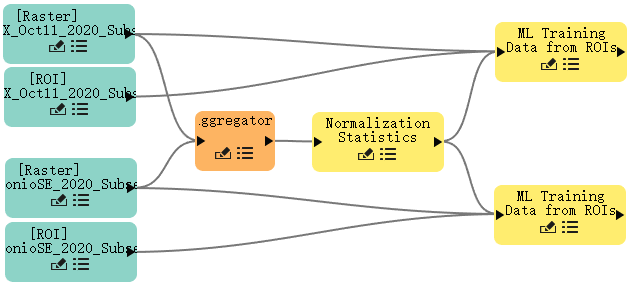
Normalization Statistics归一化统计节点从聚合器节点的输出栅格中收集最小和最大数据值。这在训练期间很重要,因为数据将使用最小值和最大值在 0 和 1 之间缩放。
4.3.3. 连接到训练节点
要使用ML Training Data from ROIs节点生成的输出数据进行训练,首先需要使用聚合器节点聚合两个训练数据,之后将其连接到训练任务节点。对于本教程,我们将使用Train Raster Forest训练随机森林节点,但也可以选择任何其它的监督分类任务。
- 在Tasks Search字段中,输入Train Random Forest。训练随机森林任务出现。
- 双击Train Random Forest训练随机森林节点。节点Train Random Forest出现在画布上。
- 从Basic Nodes列表中,双击Aggregator。一个新的 Aggregator 节点出现在节点画布上。
- 将两个ML Training Data from ROIs节点末端连接到Aggregator聚合器节点上。
- 将Aggregator节点的末端连接到Train Random Forest节点上。
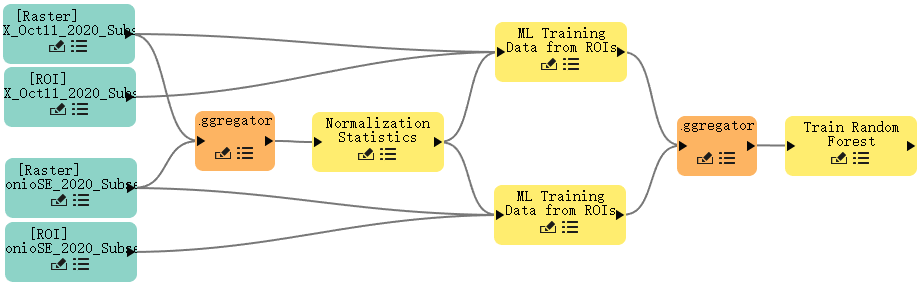
您的画布应该类似于下图。
4.3.4. 添加输入参数
Input Parameters输入参数节点是一个基本节点,可以被许多节点重用。输入参数节点将连接到画布上的多个节点。通过连接输入参数节点,可以构建一组在运行任务时能够进行参数输入的工作流。
- 从Basic Nodes基本节点列表中,双击Input Parameters输入参数。输入参数节点出现在节点画布上。

- 将Input Parameters输入参数节点连接到其中一个ML Training Data from ROIs节点的开头(左侧) 。出现“Connect Parameters”连接参数对话框。
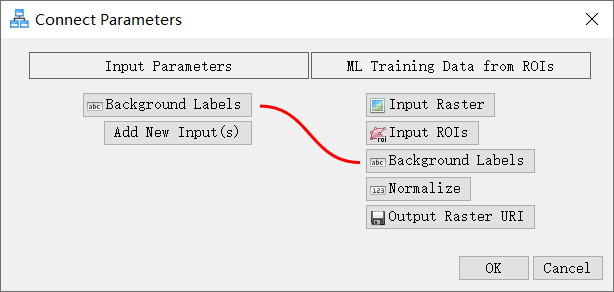
- 在Connect Parameters对话框中,单击ML Training Data from ROIs下的Background Labels按钮。一条红线将Input Parameters [Add New Inputs]连接到ML Training Data from ROIs[Background Labels]。单击OK。
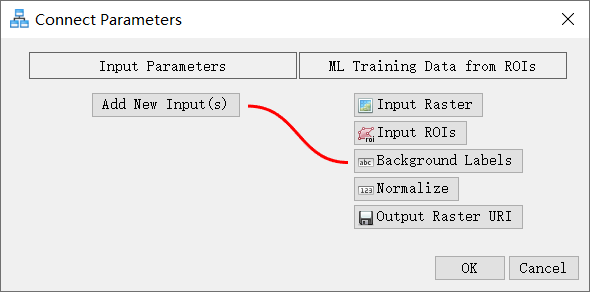
对第二个ML Training Data from ROIs节点重复此步骤。现在应该在Input Parameters下有一个[Background Labels] 选项,单击 Input Parameters [Background Labels],然后单击OK。
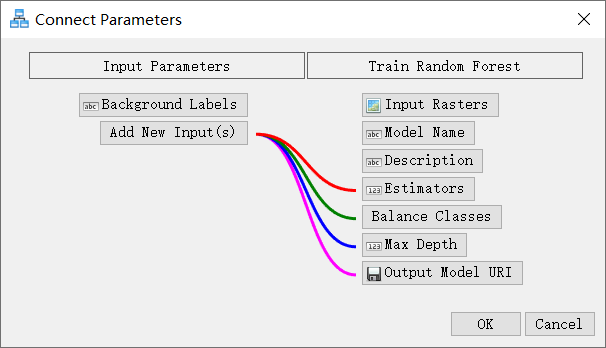
- 将Input Parameters输入参数节点连接到Train Random Forest训练随机森林节点。出现“Connect Parameters”对话框。
- 在“Connect Parameters”对话框中的“Train Random Forest”下,单击“Estimators” 估计器、“Balance Classes” 平衡类、“Max Depth” 最大深度和“Output Model URI”输出模型路径。
所有四个参数都通过彩色线连接到添加新的输入。这些参数都是用于训练模型时的输入参数。
- 单击OK。
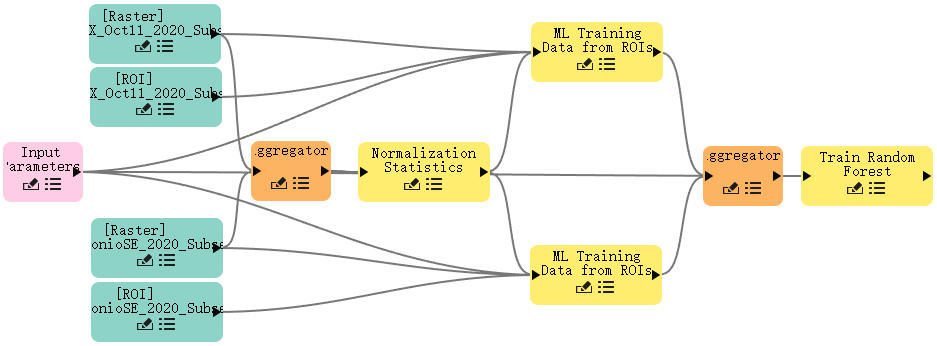
您的模型现在应该类似于下图,所有连接都已完成。注意输入参数节点和训练随机森林节点的连接在下图中被其它连线遮挡。
4.3.5. 运行模型
完成 ENVI 模型后,保存您的工作流程并运行它。
- 从ENVI Modeler菜单栏中,选择File>Save as…。出现“选择输出模型文件”对话框。指定保存文件的位置并将其命名为model并单击Save。
- 在 ENVI Modeler 工具栏中,单击Run运行按钮
 。出现带有五个参数的任务执行对话框。
。出现带有五个参数的任务执行对话框。 - 单击对话框左下角的“帮助”按钮
 。出现tutorial Task对话框。任务参数描述提供了每个参数功能的信息。
。出现tutorial Task对话框。任务参数描述提供了每个参数功能的信息。
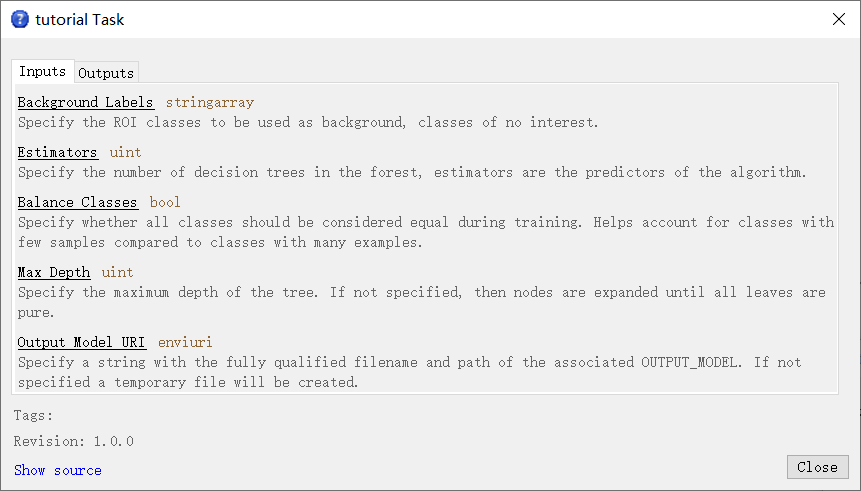
- 单击Close按钮关闭帮助对话框。
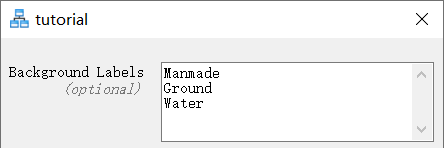
在Background Labels字段中,选择作为背景的类别。可以输入在标记过程中创建的任意几个类别(人造地物、树木、地面、水面)。例如,如果您只想识别树木,您可以添加标签(人造地物、地面、水面)。这将产生一个带有标签 Background 和 Trees的二元分类器。
- 保留参数Estimators、Balance Classes和Max Depth的默认值。
- 单击Output Model URI旁边的Browse按钮。出现选择输出模型URI对话框。
- 选择文件路径并将模型命名为json,然后单击“打开” 。
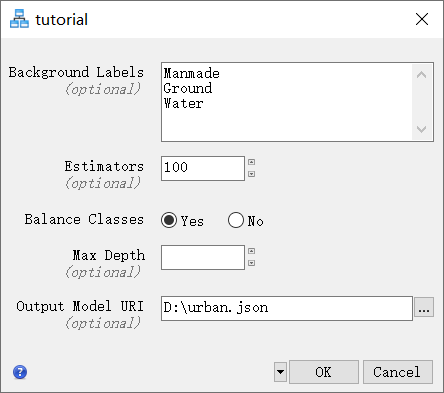
- 按指定设置所有参数后,单击OK按钮。ENVI Modeler节点颜色为绿色,表示工作流程中此步骤已完成。机器学习训练进度对话框会在训练步骤中出现。
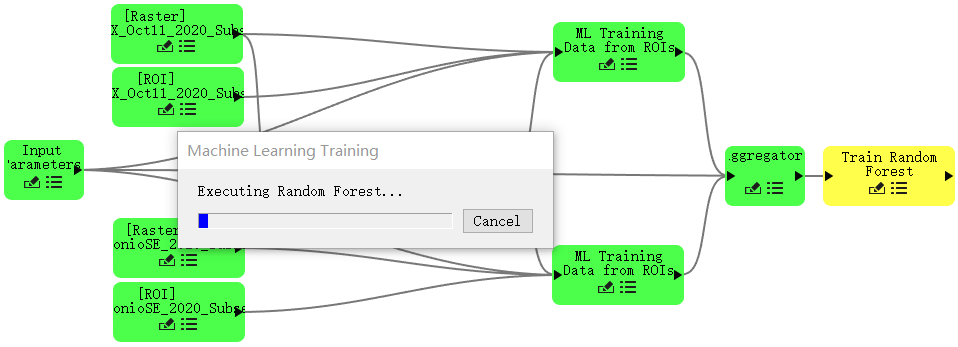
训练完成,节点恢复到默认颜色,训练进度对话框关闭。
4.4. 执行分类
生成训练好的监督分类模型后,您可以运行分类过程。最小化或关闭 ENVI Modeler;对于本节,您将使用 ENVI Toolbox工具箱中的Machine Learning Classification机器学习分类工具。
- 在 ENVI 工具箱中,展开Machine Learning文件夹并双击Machine Learning Classification。出现机器学习分类对话框。
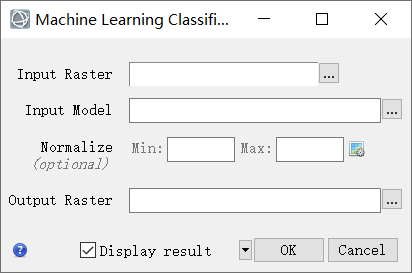
- 单击Input Raster旁边的浏览按钮。出现数据选择对话框。
- 单击数据选择对话框左下角的打开文件按钮
 。
。 - 转到您保存教程数据的位置并选择\classification/NAIP_DallasTX_Oct11_2020.tif,然后单击Open。
- 单击Input Model输入模型旁边的浏览按钮。出现选择文件对话框。转到保存模型json的位置。选择它并单击打开。
- 将Normalize字段留空,将使用模型文件中的最小值和最大值。
- 将Output Raster输出栅格字段留空,将创建一个临时文件并在分类完成后显示。

启用Display result显示结果。点击OK分类开始,机器学习分类进度对话框出现。分类在 30 - 60 秒后完成,具体时间取决于系统配置。
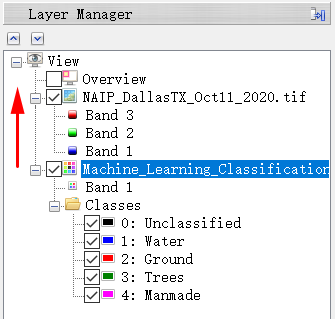
- 分类栅格显示在 ENVI 视图中。图层管理器显示未分类、水面、地面、树木和人造地物。在标注样本过程中未使用 Unclassified 类,此类表示未分类的像素(如果存在)。
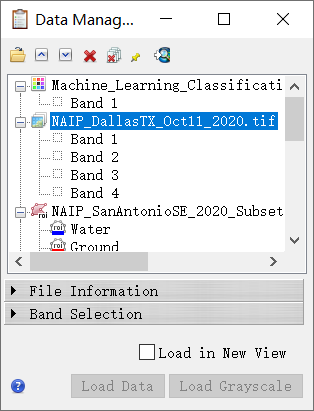
- 在 ENVI 工具栏中,单击Data Manager数据管理器按钮
 。出现数据管理器对话框。
。出现数据管理器对话框。 - 右键单击tif并单击Load Default加载默认值。原始图像显示在 ENVI 视图中。
在图层管理器中,单击Machine_Learning_Classification_output*raster并将其拖动到栅格NAIP_DallasTX_Oct11_2020.tif上方。分类栅格显示在原始图像上。
在 ENVI 工具栏中,前后移动 Transparency 透明度滑块以探索与原始图像相比的分类结果。注意到该模型在识别正确的类方面做得很好,但它并不完美。整个图像的阴影被归类为人造材料。尝试消除这种情况的一种方法是创建阴影类,或绘制阴影类并将其归为背景类。
另一个缺陷是足球场部分被分类为水体。这可以通过添加更多的足球场处样本并重新训练模型来缓解。
在Go To字段中输入像素坐标 ( 7784p,7148p ),然后按Enter键跳转到体育场。

- 或者再次运行分类工作流程以查看您的模型对其他分类场景的处理情况。例如另一幅图像:\classification\NAIP_SanAntonioSE_2020.dat。
在本教程中,您学习了如何构建自定义机器学习工作流,以使用标记数据训练随机森林分类器。了解到可以使用多个栅格和多个标签来训练模型并生成良好的结果。
总之,机器学习技术为学习数据中的复杂光谱模式提供了一个强大的解决方案,这意味着它可以从复杂的背景中提取特征,而不管它们的形状、颜色、大小和其他属性。
5. 总结
本教程介绍了两种方法进行随机森林分类。一种方法通过绘制样本ROI之后使用随机森林工具(Random Foreast Classification)直接得到分类结果。另一种方法通过ENVI Modeler自定义可重用的随机森林模型训练工作流,之后使用通用的机器学习分类工具(Machine Learning Classification)得到分类结果。第一种方法简便快捷,方便直接获得分类结果;第二种方法可以获得可重用的机器学习模型。其它监督分类方法整体操作流程与本教程方法一致,区别是选择的分类器有所不同。另外使用Machine Learning Labeling Tool机器学习标注工具也可以完成从样本选择到模型训练的整个过程。并且支持实时保存绘制的样本,提供项目管理等功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号