ENVI新机器学习:异常探测分类工具操作手册
异常探测是一种用于定位数据集中异常点的数据处理技术。异常值是指与数据集中的已知特征相比被认为不正常的值。例如,如果水是已知的特征,那么除水之外的任何东西都将被视为异常值。
ENVI机器学习异常探测在训练过程中接受单一背景特征。该特征表示被认为是整个数据集正常的像素。任何在分类过程中被认为不正常的像素都被认为是异常的。在训练之前的标记过程中,需要为给定的数据集标记一个背景特征。
标记数据对于生成一个好的异常探测器是至关重要的,对于大多数类型的分类器来说都是如此,特别是对于异常探测而言。例如,如果属于异常目标的标记像素与背景特征相关联,这可能会产生一个质量不高的模型。
ENVI机器学习提供两种类型的异常探测器,孤立森林和局部异常因子。
- 孤立森林(Isolation Forest)是一种匹配算法,该方法认为数据中的异常信息是很少的,将其从正常像素中分离出来。
- 局部异常因子(Local Outlier Factor)是一种算法,用于测量给定像元相对于邻近像元的局部偏差。局部异常值是基于其周围像素的邻域,通过评估像素值的差异来确定的。
ENVI机器学习异常探测工具处理步骤如下:
第一步:标记背景特征。绘制ROI进行背景特征的标记;
第二步:模型训练。使用标记数据进行训练,生成模型;
第三步:模型分类。使用训练好的模型进行分类,生成分类结果文件。
第四步:分类后处理(该步可选)。
本教程中以港口中的九艘船作为异常对象,使用异常探测工具进行船只监测。
数据链接:https://pan.baidu.com/s/19vuMgp1XEZqCGXUymviqSg?pwd=envi
提取码:envi
使用软件为ENVI5.6.3+ENVI Deep Learning2.0,硬件为Intel® Core(TM) i7-7700HQ CPU@2.80GHz (用机器学习工具推荐使用Intel CPU)。
ENVI5.6.3试用请访问:https://www.cnblogs.com/enviidl/p/16275745.html。
1 标记背景像元
开始标记过程,至少需要一个输入图像,从中收集图像的主要特征的样本。与选择感兴趣的对象或像素的传统标记不同,异常探测需要相反的方法。例如,在本教程中,图像中的主要特征是水,标记为背景。选择的图像是训练栅格。图像可以是不同的大小,但需要具有一致的光谱和空间特性。使用ENVI ROI标记训练栅格简单的方法是使用机器学习标记工具。使用标记工具创建项目将有助于组织与标记过程相关的所有文件,包括训练栅格和相关的ROI。
第一步:建立一个项目文件
(1)选择一个文件目录,在里面创建一个名为ProjectFiles的空文件夹。
(2)在ENVI Toolbox中,打开/Machine Learning/Machine Learning Labeling Tool工具。
(3)在打开的labeling Tools工具界面选择File->New Project,在Project Type列表中选择Anomaly Detection。
(4)Project Name字段输入背景像元类别,此处输入Water。
(5)单击Project Folder后面的 按钮,并选择第一步创建的Project files文件夹,单击“选择文件夹”。
按钮,并选择第一步创建的Project files文件夹,单击“选择文件夹”。
(6)单击OK。
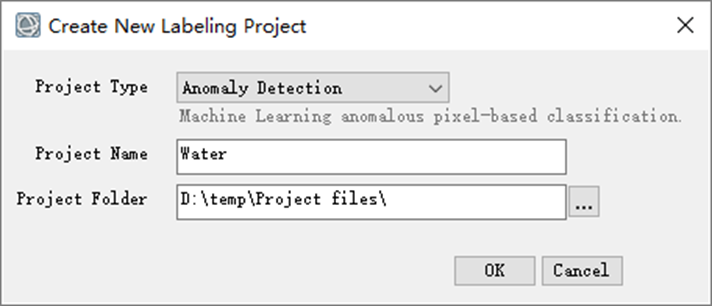
图:创建工程文件
当创建一个新的异常探测项目时,会自动创建Background类。这里无法添加其他标签,而背景标签将用于识别水。使用标注工具,将为输入的每个训练数据创建子文件夹。每个子文件夹将包含在标记过程中创建的ROI和训练栅格。
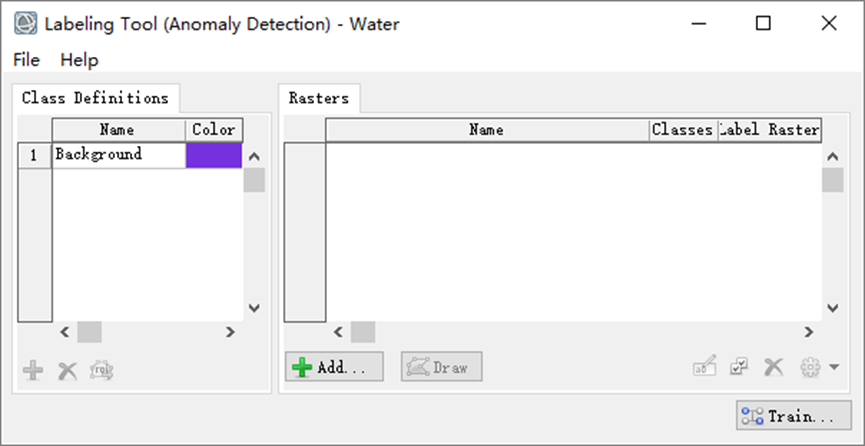
图:标记工具
第二步:添加训练数据
在Labeling Tool界面,单击Rasters下面的 按钮。选择数据文件naip_laharbor_sub .dat,单击OK。
按钮。选择数据文件naip_laharbor_sub .dat,单击OK。
训练数据被添加到机器学习标记工具的Raster列表中。列表有两列:Classes和Label Raster,每个Classes列显示一个红色的分数:0/1。“0”表示还没有绘制任何类标签。“1”表示定义的类别总数。Label Raster列用红色显示“No”,表示尚未创建标签栅格。
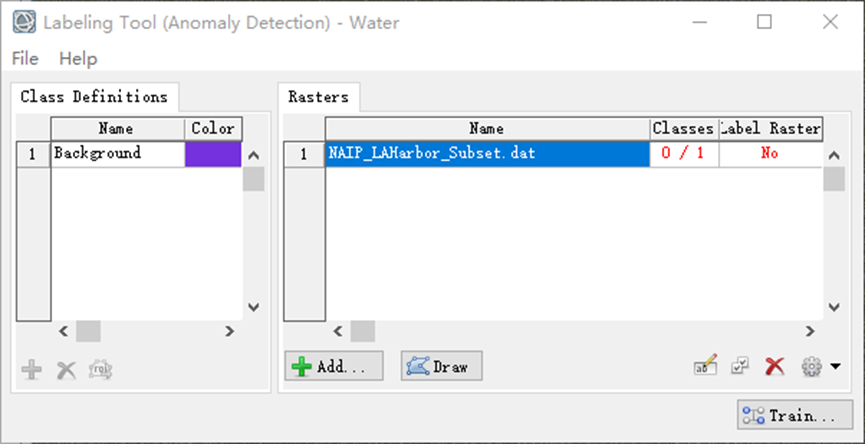
图:标记工具界面添加训练数据
第三步:标记背景像元
在为异常探测器标记样本时,有一个重要原则是:质量比数量更重要。标记像元过少可能无法提供足够的信息来找到所有异常目标;标记像元太多会使分类运行时间过长;标记异常目标的像元,将导致混乱和信息丢失。
(1)在Labeling Tool工具中点击naip_laharbor_sub .dat,让其高亮显示;
(2)单击![]() 按钮,在ENVI视窗中自动显示该图层,并自动打开了ROI工具;
按钮,在ENVI视窗中自动显示该图层,并自动打开了ROI工具;
(3)将Labeling Tool界面最小化,在Layer Manager中点击naip_laharbor_sub .dat图层,使其成为活动层;
(4)在ENVI工具栏中的拉伸类型列表选择Equalization均衡化拉伸,这种拉伸方法对图像进行均衡拉伸,使彩色信息可以突出显示,以便在标记时更容易选择;
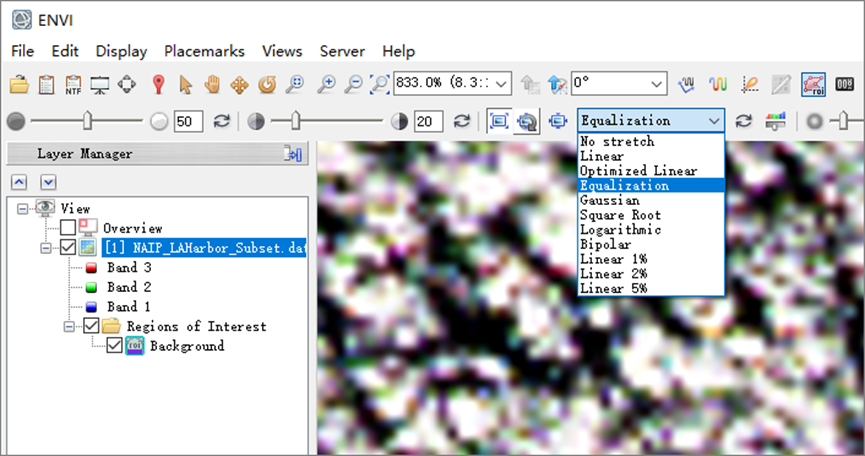
图:图像拉伸显示
(5)在ROI工具面板,选择![]() 类型,在ROI面板点击下面的Area按钮,可以查看所选择的像元个数;
类型,在ROI面板点击下面的Area按钮,可以查看所选择的像元个数;
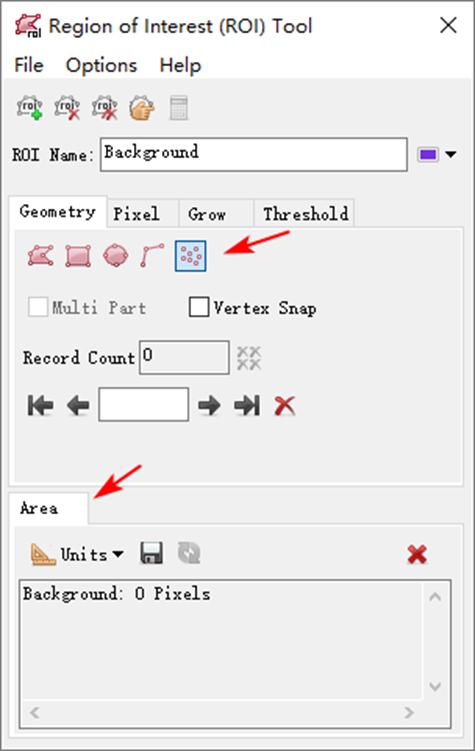
图:ROI工具
(6)在ENVI工具栏的Go To字段中,输入像素坐标:5480p,9276p(像素坐标),之后按回车键,定位到该像元位置,中心区域的水是较深的绿色。
(7)在ENVI工具栏的Zoom一栏输入1200,按回车键。显示屏放大1200%(12:1),在这个缩放级别下,所有地物都缩放到像元级,便于选择不同颜色的像元。

图:选择水体像元
(8)回到ROI工具界面,设置好选择像素之后,在图像上的水体像元上单击鼠标左键,点击一个或若干个像元后,右键选择Accept points确定。
注:避免标记绿色和白色像素,因为图像中一些船只像元有这两种颜色。标记25个不同颜色的像素,除了白色和绿色,选择尽可能多的其他不同颜色像素。
8、同样的方法,定位到以下三个像元坐标位置:7334p, 10161p ;9934p, 9389p;7920p, 11849p,用上一步的方法在每个区域标记25个像元,这样,一共标记了100个像元。异常探测选择背景像元的原则是:尽量减少标记像元的数量,同时提供足够的信息来识别与水异常的船只。
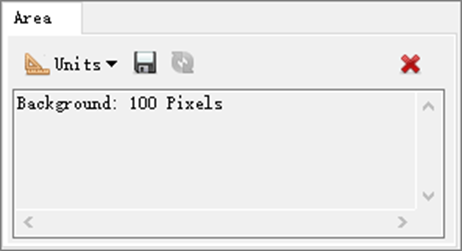
图:标记像元个数
注:在训练过程中尽量减少标记像元的数量使分类步骤较快运行。
像元标注现在已经完成,下面开始训练过程。
2 训练一个异常探测模型
本教程使用Local Outlier Factor algorithm算法,该算法测量给定像元相对于相邻像元的局部偏差。局部离群值基于它周围像素的邻域,通过评估像元值的差异来确定。
(1)回到Labeling Tool界面,点击底部的![]() 按钮,打开Train Machine LearningModel对话框。
按钮,打开Train Machine LearningModel对话框。
(2)在Train Model面板,设置参数如下:
- Method:Train Local Outlier Factor
- Model Name:输入模型名称,此处默认为Local Outlier Factor Anomaly Detector
- Decription:输入模型描述,如Ship Detection
- Leaf Size:该参数与模型训练速度和查询速度有关,以及运算所需的内存。此处按照默认30
- Output Model:点击
 ,设置输出模型的存放路径,文件名可命名为json
,设置输出模型的存放路径,文件名可命名为json
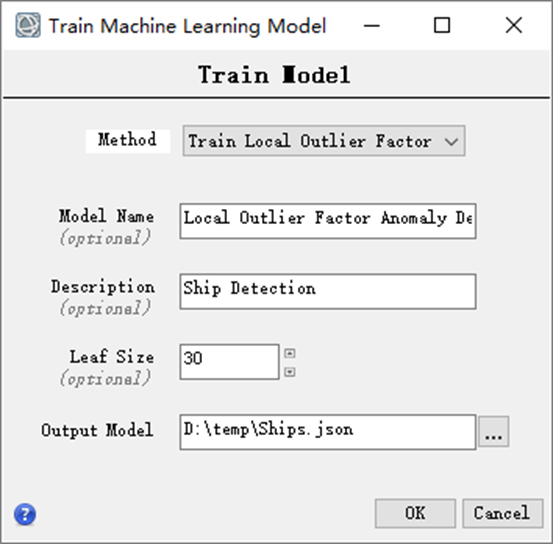
图:模型训练
(3)在Train Machine Learning Model面板点击OK。出现模型训练的进度条,在Labeling Tool界面可以看到所有数据的Label Raster列都显示为OK,表明ENVI已经自动创建了用于训练的栅格。生成的训练栅格包含从所有ROI标记点收集的光谱。
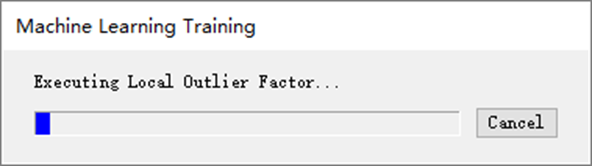
图:运行模型训练
本例训练花几秒钟完成,下面用该模型进行分类。
3 执行分类
上一步生成了一个区分水像元的异常探测模型,可以在同一类型的栅格数据上使用该模型来识别非水体像元。在本教程中,生成的模型不是通用的,可能在其他数据上运行效果不理想,可以使用上面的步骤,用多个栅格进行模型训练。
(1)关闭ROI和Labeling Tool工具(标签栅格同时也会自动关闭)。
(2)在ENVI Tools中,打开/Machine Learning/Machine Learning Classification工具;
(3)在Machine Learning Classification面板:
- Input Raster:输入待分类数据,此处选择dat文件
- Input Model:输入上一步训练好的分类模型json,下方出现该模型的描述信息,点击Full info,可以查看模型元数据信息;
- Normalize:通过指定对应于0%和100%反射率的Min和Max数据值,可以对待分类的数据进行归一化处理,本例中此处默认不输入;
- Output Raster:点击
 ,设置分类结果的输出路径为开始建立的Project files文件名为dat
,设置分类结果的输出路径为开始建立的Project files文件名为dat
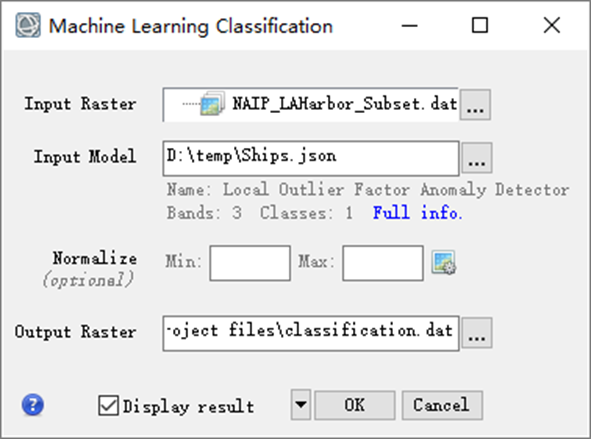
图:机器学习分类
(4)在Machine Learning Classification面板上单击OK,进行机器学习分类,几十秒后,分类完成,查看分类结果文件。
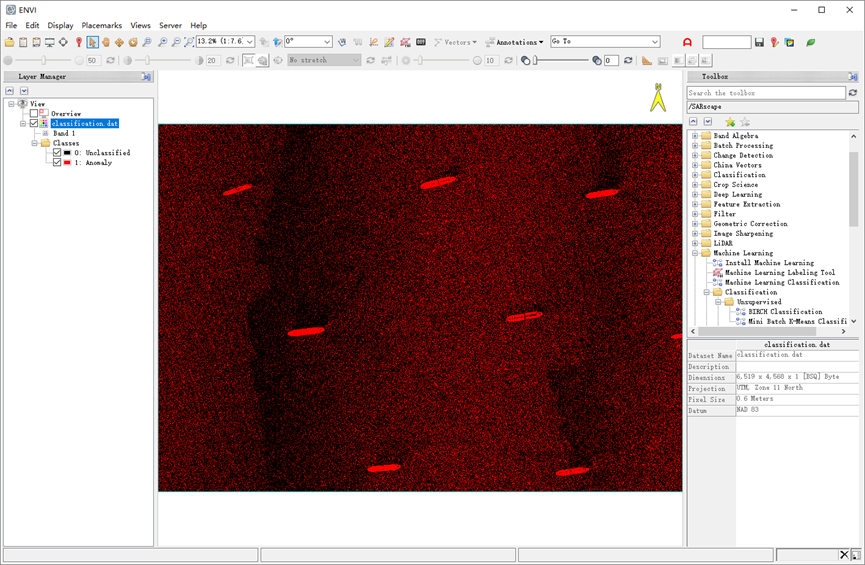
图:异常探测分类结果
异常探测的结果,除了提取出船只之外,还有很多噪声点,这是因为我们只使用了100个像元作为背景标记,使用更多的标记像元作为训练输入可以产生更清晰的结果,但分类时间会相应增加。这些噪声点,可以使用分类后处理工具来进行去除。
分类处理完成,下面进行分类后处理。
4 分类后处理(可选)
本例中,我们需要提取的异常信息是船只信息,后处理的目的是去除所有水的像元,只留下船只信息,可以使用ENVI分类后处理的聚类工具。
(1)噪声去除
ENVI Toolbox中选择/Classification/Post Classification/Classification Aggregation工具,在弹出的参数对话框中Input Raster选择分类后结果,设置聚合最小尺度Minimum Size为500,其他保持默认,输出结果。
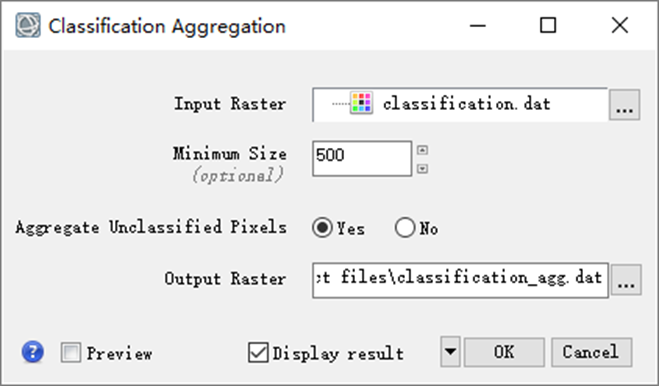
图:分类结果聚类处理
查看聚类的结果,水体噪声信息被去除,保留了我们需要的船只信息,但是船只内部的一些像元有所丢失,这是因为类似的像元被标记为水体的结果。
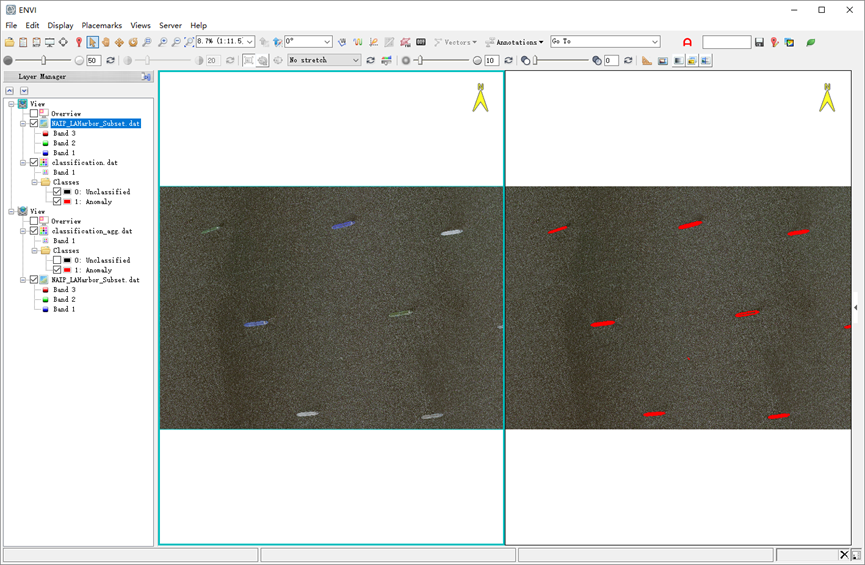

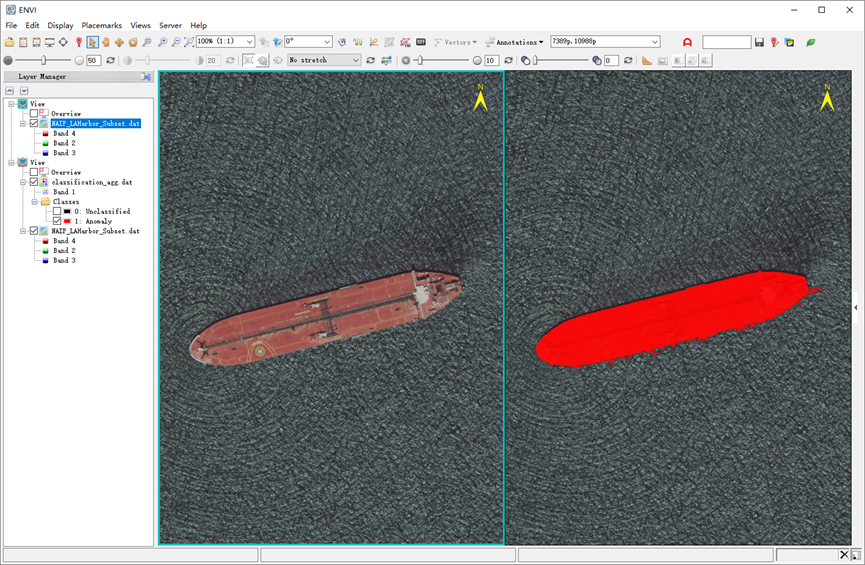
图:异常探测结果
除了监测到八艘大船,还有一条小船也被检测出来了,船桨留下的水迹也被归类为异常。如果想改善该结果,可以进行以下尝试:调整背景(水)标记像元,之后在分类结果小斑块聚类的时候减小Minimum Size参数。
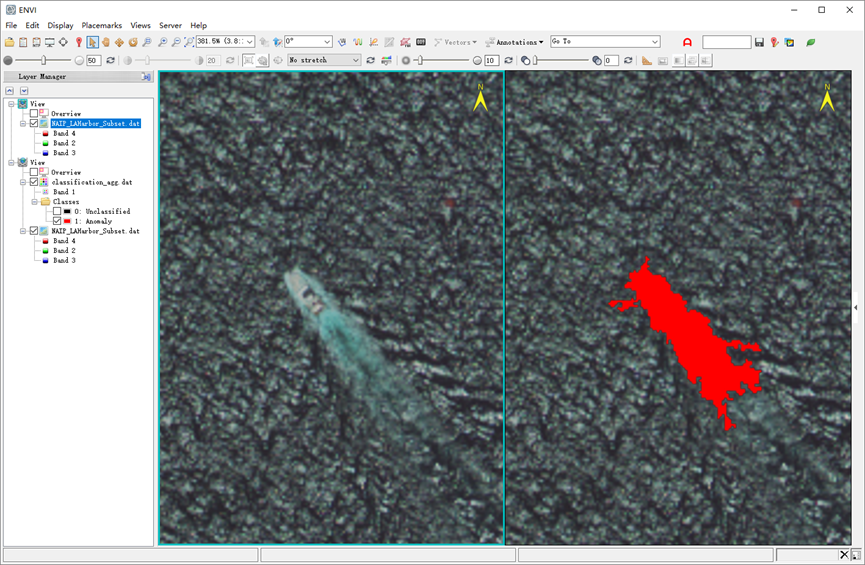
图:监测到的小船
(2)分类结果转矢量
可以将分类结果转矢量,再生成矩形框,得到船只轮廓矢量结果。
分类结果转矢量操作如下:
在ENVI工具箱中打开/Classification/Post Classification/Classification to Vector工具,选择上一步输出的聚类结果,Export Classes选择Anomaly类别,其他参数按照默认,设置输出路径点击OK,得到矢量结果。
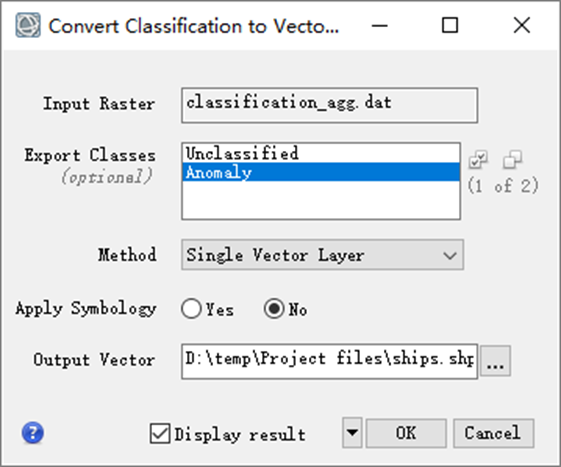
图:分类结果转矢量工具
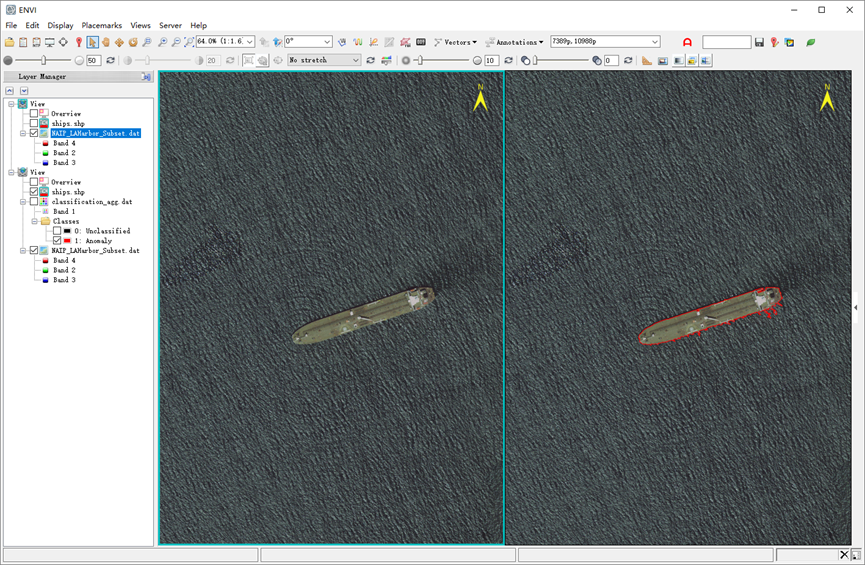
图:分类结果转矢量
(3)生成最小外接矩形
对上一步输出的矢量结果生成最小外接矩形,操作如下:
在Toolbox中,选择Vector/Vector to Bounding Box,在弹出的对话框中选择上一步输出的矢量,Oriented Bounding Box选择Yes,根据图斑边界生成最小外接矩形,设置文件输出路径点击OK,得到最终结果。
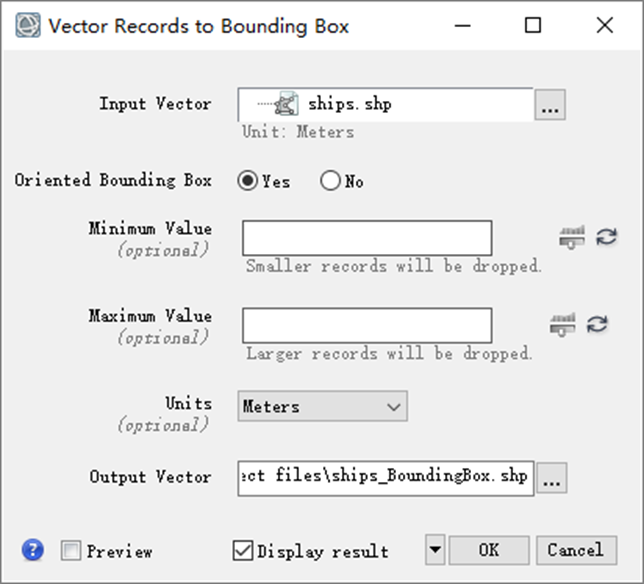
图:生成最小外接矩形
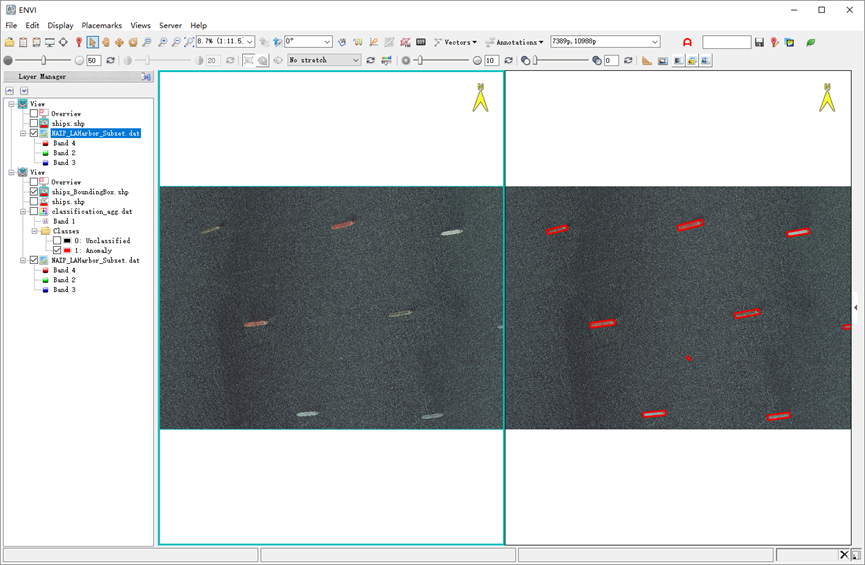


图:船只外接矩形结果
5 总结
使用ENVI的机器学习标记工具标记像素级的特征信息,标记的像元越少,模型训练和分类的速度越快。异常探测选择背景像元的原则是:尽量减少标记像元的数量,同时提供足够的信息来识别与背景信息相异的信息。使用多个数据制作背景样本标记,可以为类似的图像生成可复用的通用模型。
机器学习技术为学习数据中的复杂光谱模式提供了一个健壮的解决方案,可以从复杂的背景中提取特征,不考虑其形状、颜色、大小和其他属性。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?