ENVI下支持向量机(SVM)使用说明
支持向量机分类(Support Vector Machine 或 SVM)是一种建立在统计学习理论(Statistical 或 SLT)基础上的机器学习方法。与传统统计学相比,统计学习理论(SLT)是一种专门研究小样本情况下及其学习规律的理论。
ENVI中有两个地方可使用SVM方法:监督分类工具和基于样本的面向对象分类工具,两个工具中的参数设置基本一样,下面以监督分类工具中的SVM为例介绍这种方法。
在ENVI中进行支持向量机(SVM)和其他监督分类一样:打开待分类的图像->选择感兴趣区(样本)->设置参数->分类。
(1)
(2)
(3)
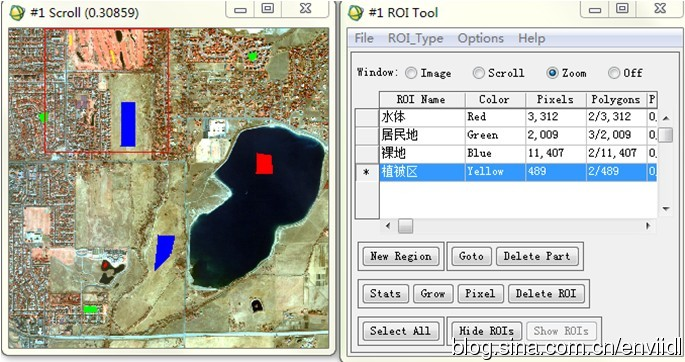
图:选择的分类样本
(4)
注:这里不能设置掩膜,对于不规则图像就会把背景分类。
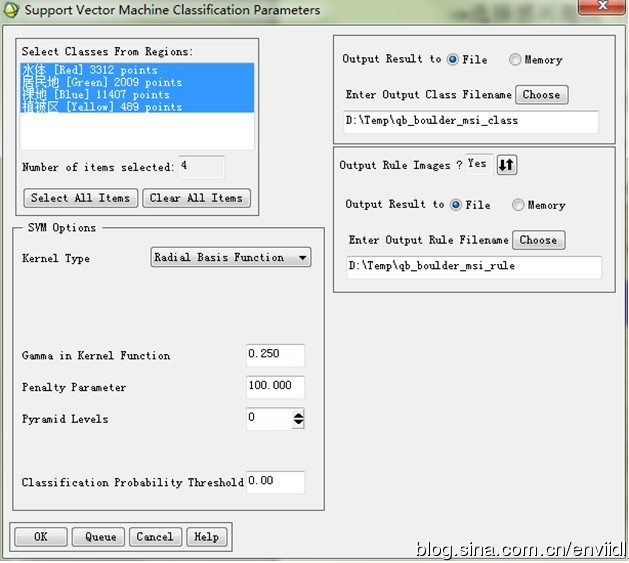
(5)
a)
- 如果选择Polynomial,设置一个核心多项式(Degree of Kernel Polynomial)的次数用于SVM,最小值是1,最大值是6。
- 如果选择Polynomial or Sigmoid,使用向量机规则需要为Kernel指定 the Bias ,默认值是1。
- 如果选择是 Polynomial、Radial Basis Function、Sigmoid,需要设置Gamma in Kernel Function参数。这个值是一个大于零的浮点型数据。默认值是输入图像波段数的倒数。
b)
c)
d)
e)
(6)
(7)
(8)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号