【IDL代码库】大数据分块写入HDF5文件示例代码
IDL提供了专门针对HDF5科学数据格式的读写函数库。可以参考IDL帮助的Routines (alphabetical) > Routines: H > HDF5 Routines 这个章节查看函数列表。
如果只是简单的读写HDF5文件,可以利用下面三个函数即可:
-
H5_GETDATA
读取数据 -
H5_LIST
查看数据列表 -
H5_PUTDATA
写入数据
注:上面3个函数用法非常简单,这里不再举例。要求IDL最低版本为8.3。
下面介绍如何将一个大数据分块写入HDF5文件。在test_write_h5d.pro源码中,分成了如下几个步骤
(1)首先随机创建一个大数据,利用了hanning函数(生成汉宁窗,主要用于快速傅里叶变换),再计算两个维度的步长、步数。
(2)然后将第一个分块数据写入数据集,并进行第一个分块数据的可视化展示。
(3)最后是一个嵌套循环,将剩余分块数据动态写入,并叠加展示每一个分块数据。
下图为可视化结果,左侧图形为分块效果,右侧图形为整体数据效果。
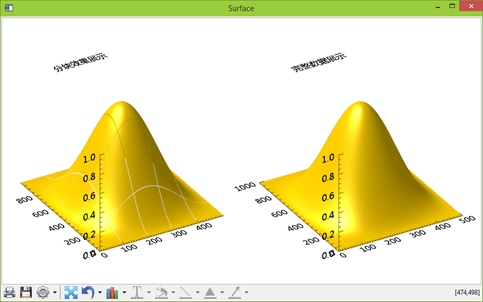
图:可视化效果
最后附上源码:
PRO test_write_h5d
COMPILE_OPT idl2
; 创建新的 HDF5文件,可修改
file = 'D:\temp\mytest_h5_file.h5'
fid = H5F_CREATE(file)
; 随机创建初始维度
random_number1 = SORT(RANDOMU(seed, 1000))
random_number2 = SORT(RANDOMU(seed, 2000))
dim1 = random_number1[0]>500
dim2 = random_number2[0]>1000
; 每一个维度的分块步长
step1 = 100
step2 = 200
; 每一个维度的分块数目
nstep1 = dim1/step1
nstep2 = dim2/step2
; 重新定义大数据维度,可以完美分块
dim1 = nstep1*step1
dim2 = nstep2*step2
; 创建一个大数据
data = hanning(dim1,dim2)
; 取出第一个分块数据
data_segment = data[0:(step1-1),0:(step2-1)]
; 展示第一个分块数据
s = surface(data_segment, title='分块效果展示', $
xrange=[0,dim1-1], yrange=[0,dim2-1], layout=[2,1,1],$
dimensions=[900,500], margin=[.2,.2,.2,.2])
; 根据数据创建一个datatype
datatype_id = H5T_IDL_CREATE(data)
; 创建一个dataspace,并且可以进行扩展
dataspace_id = H5S_CREATE_SIMPLE([step1,step2],$
max_dimensions=[-1,-1])
; 创建一个dataset
dataset_id = H5D_CREATE(fid,'Hanning', datatype_id,$
dataspace_id, chunk_dimensions=[step1,step2])
; 扩展dataset的维度,以适应第一个分块数据
H5D_EXTEND,dataset_id,SIZE(data_segment,/dimensions)
; 将第一个分块数据写入dataset
H5D_WRITE,dataset_id,data_segment
; 同上面操作相似,将剩下的数据分块写入到HDF5文件中
FOR ind1 = 0L, nstep1-1 DO BEGIN
FOR ind2 = 0L, nstep2-1 DO BEGIN
; 如果文件dataspace已存在,则关闭
IF (ISA(iter_data_space_id)) THEN BEGIN
H5S_CLOSE, iter_data_space_id
ENDIF
; 如果memory dataspace已存在,则关闭
IF (ISA(iter_data_space_id2)) THEN BEGIN
H5S_CLOSE, iter_data_space_id2
ENDIF
; 计算当前分块的起始行列号
start1 = ind1 * step1
start2 = ind2 * step2
; 获取当前分块数据
data_segment = data[start1:(start1+step1-1),start2:(start2+step2-1)]
; 展示当前分块数据
s = surface(data_segment, layout=[2,1,1], $
LINDGEN(step1)+start1, LINDGEN(step2)+start2, /overplot)
; 扩展dataset维度,输入维度应该是扩展后维度,而不是新增的维度
H5D_EXTEND, dataset_id, [start1+step1, start2+step2]
; 创建新的dataspace
iter_data_space_id = H5D_GET_SPACE(dataset_id)
; 选中包含当前分块数据的 slab
H5S_SELECT_HYPERSLAB, iter_data_space_id, [start1,start2], $
[step1,step2], /RESET
; 创建memory data space
iter_data_space_id2 = H5S_CREATE_SIMPLE([step1,step2])
; 使用文件dataspace和 Memory dataspace,将当前分块数据写入Dataset
H5D_WRITE, dataset_id, data_segment, $
FILE_SPACE_ID=iter_data_space_id,$
MEMORY_SPACE_ID=iter_data_space_id2
ENDFOR
ENDFOR
; 关闭前边打开的标识符
H5S_CLOSE, iter_data_space_id
H5S_CLOSE, iter_data_space_id2
H5S_CLOSE,dataspace_id
H5D_CLOSE,dataset_id
H5T_CLOSE,datatype_id
H5F_CLOSE,fid
HELP, data
; 读取新建的HDF5数据列表
h5_list, file
; 获取数据并进行可视化
in_dat = H5_GETDATA(file, '/Hanning')
s=surface(in_dat, layout=[2,1,2], /current, $
margin=[.2,.2,.2,.2], title='完整数据展示')
END

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界