计算机网络 | 从 ChannelOption 到 Netty 底层
概述
ChannelOption 是 Netty 中在构建引导类时可以填写的构建 Channel 的选项
其可以分为两部分,一部分为控制 Netty 自身底层运行的选项;另一部分则是操作系统创建 socket 时的选项 (如果熟悉 UNIX 网络编程的话应该知道这玩意)
本文上半部主要解释作用于 Netty 的常用选项,需要有 Netty 的基础知识;后半部主要解释作用于 socket 的选项,需要有 TCP/IP 的基础知识。
Netty 部分
ALLOCATOR
设置需要使用的 ByteBufAllocator (ByteBuf 的分配器)
ByteBuf 的分配器主要是 PooledByteBufAllocator 和 UnpooledByteBufAllocator ,区别就如同其类名称介绍的一样,前者的池化的,后者为非池化的。
ByteBuf 是 Netty 中数据存储的容器,它可以从三个维度来分类
-
Pooled 和 Unpooled
池化的意思是使用对象池去管理一些对象,需要的时候从池子中取出,用完后放回去,在 Netty 中池化有两类好处
一是分装为局部对象池,通过 ThreadLocal 机制来消除多线程竞争所带来的消耗
二是通过对象池来复用对象,可以显而易见的减少创建对象所带来的对象创建的消耗
-
Unsafe 和 非 Unsafe
Unsafe 和 非 Unsafe 指的是底层获取数据的方式
Unsafe 的方式是指通过 Unsafe 包下的 api 来获取底层的数据
非 Unsafe 则是直接通过 ByteBuffer 或 byte[] 对应的 api 获取
-
Heap 和 Direct
这个分类是指 ByteBuf 所存储的数据所在的位置。
Heap 是直接在 Java 的堆中存放对象;由于是在堆中,所以可能会受到 GC 时对象的地址的移动的影响(取决于使用的垃圾回收器对应的 GC 算法)。
Direct 是指直接 Java 中的直接内存(也叫堆外内存),这部分的内存不会被 GC 影响,操作的效率高于 Heap,但同时创建成本高于 Heap (因为需要涉及到系统调用,而 heap 中的内存是在启动的时候就已经申请好的)。
由于以上两个 ByteBuf 的区别,Channel 在将 Heap ByteBuf 写出到网卡的发送缓冲区前,会先将其数据拷贝到一块 Direct ByteBuf 中。所以在 Netty 中,如果我们打算发送大量的数据到对端,最好是直接申请一块 Direct ByteBuf ,这样可以免去从 Netty 的将其拷贝的消耗。
在 Netty 4.1 中,默认的 ALLOCATOR 使用的是 PooledByteBufAllocator ,大多数情况不需要更改
WRITE_BUFFER_WATER_MARK
控制 Netty 中 Write Buffer 的水位线
要理解水位线 (wrter mark) 的概念,还要从 Netty 的 channel.write(...) 讲起。
首先先来根据下面这张图来观察 write 的大致流程

首先,我们对一个 Channel 写入的时候,会先将需要 write 的对象封装为任务放入 Queue
然后,同时 IO 线程会定时将任务从 Queue 取出,然后再经过 Pipeline 中各个处理器处理(图中未画出),再将处理结果写入到 Netty Buffer,然后到达操作系统的底层的 TCP 的发送缓冲区。
最后,TCP 发送缓冲区中的数据会分包发送给对端,就是在这里的对面的 Client 的 TCP 接收缓冲区。
需要注意的是,如果只是调用 channel.write(..) 方法,该数据只会暂时存储到 Netty Buffer。在 channel.flush() 被调用后,则会发送 flush 包(即上图中标记为 "F" 的包),在 Netty Buffer 收到了 flush 控制包,才会将 Buffer 冲刷到 TCP Buffer。
其中,TCP 连接的数据发送一方中的 TCP Buffer (发送缓冲区) 的大小由 SO_SNDBUF 控制,而 Netty Buffer 是"无界"的,且它的位置在堆外内存(Direct Buffer)。
我们在一开始提到的水位线,则是标记当前 Netty Buffer 所使用的大小的一个值。当 Netty Buffer 的大小到达这个值后,调用 chanel.isWriteable 则会返回 false,且会通过调用业务 handler 的 writabilityChanged 方法来通知上层应用。
同时水位线还分为高水位线和低水位线,到达高水位线后调用 chanel.isWriteable 则会返回 false ,直到下降到低水位线,调用时才会返回为 true 。
不过,水位线只是一个警示,并不是实际上限,到达水位线后 Netty Buffer 仍然可以被写入,写入后会在由 Netty 维护的内部缓冲区进行排队。
顺带一提,在之前的 netty 版本中,高水位线通过
WRITE_BUFFER_HIGH_WATER_MARK设置,低水位线通过WRITE_BUFFER_LOW_WATER_MARK,但现在已经被标记为 Deprecated,取而代之则是上文介绍的WRITE_BUFFER_WATER_MARK,通过下列样式进行配置.option(ChannelOption.WRITE_BUFFER_WATER_MARK, new WriteBufferWaterMark(10000, 20000))
上面提到的 Netty Buffer 的在 Netty 中的类名为 ChannelOutboundBuffer;TCP Buffer 也叫 socket 发送缓冲区
AUTO_READ
启用自动读取
准确来讲,应该说是启用自动向 Selector 注册 OP_READ 事件的功能;启用后,在有可读的数据时,会自动的从 channel 读取数据,并交给业务上层的 handler。
但是如果 handler 对于这些数据的处理过于慢又没有相对的措施的话,那么很可能就会使 CPU 的负载过高或将 JVM 的 heap 占满。
这取决于业务 handler 对于数据的处理方式,如果是放入到线程池的话将很快的将线程池中的线程消耗殆尽,若使用的等待队列是无界队列,那么最终会导致 JVM 的 OOM。
否则的话会根据拒绝策略来处理 (这应该算是相对较好的情况)
当然以上是速率不匹配且没有做处理时的最坏情况,实际上我们可以通过背压 (Back Pressure) 来做流量控制。
而关闭 AUTO_READ 选项,就是一种策略,在 netty 不再自动从 socket 接收缓冲区读取数据时,TCP 自带的流量控制就开始工作。
TCP 的流量控制的做法简单来讲,就是可以在接收端进行 ack 时,可以顺便带上剩余缓冲区的大小,发送端会根据这个大小来控制发送速率。
一旦我们不再从 socket 接收缓冲区读取数据了,接收缓冲区的可用大小就只能减少,发送方就会调整发送的速率。所以在实际使用中,我们可以通过 channel.config().setAutoRead(..) 来设置是否自动读取以做流量控制。
AUTO_CLOSE
启用自动关闭
在一个 Channel 写入失败的时候立刻自动 close 这个 Channel,不需要手动去关闭
WRITE_SPIN_COUNT
控制一次 write 操作的最多次数
Netty 对于一个大文件的写入,并不会直接调用底层的 socket.write() 来将整个文件写入,因为这会导致该 socket 在一段时间,其他尝试写入的文件必须等待这个大文件写入完成。
所以 Netty 为了减少这种多个其他文件的写入被单个大文件阻塞的情况,会对这个大文件进行拆分,且分多次写入,这个选项控制的就是最多允许拆分的写入次数
SINGLE_EVENTEXECUTOR_PER_GROUP
开启单线程执行 ChannelPipeline 中的 handler
在关闭时会为每一个 handler 都分配可能不同的 EventLoop ,在开启这个选项后,会让所有 handler 在同一个 EventLoop 来执行,这样可以减少线程上下文切换的开销。
UNIX socket 部分
SNDBUF 和 SO_RCVBUF
发送缓冲区大小 与 接收缓冲区大小
在 socket 中,发送缓冲区和接受缓冲区决定了流量控制中的发送窗口与接收窗口的大小,上文也不止一次提到了 socket 缓冲区
REUSEADDR 和 REUSEPORT
允许地址复用 和 允许端口复用
大多数情况下启用该选项都是为了允许快速的重新启动一个服务器应用
假如当旧的服务器应用崩溃了,我们需要立刻启动,但是由于旧的 socket 还没有完全关闭,所以立刻进行 bind 时可能会提示端口已经被占用了。
出现这种情况的原因是,旧的服务器在还没有调用 close() 来关闭所有的 tcp 连接就直接关闭了,这会导致在该端口上还有一些 socket 处于 TIME_WAIT 状态,所以会提示已经被占用,这样的话就需要等待直到 TIME_WAIT 时间结束才能重新启动这个服务器应用。
如果启用了这个选项,可以立即重用这个端口(但是如果处于非 TIME_WAIT 状态时仍然会报错)
在大多数的服务器应用都会启用该选项
当然这两个选项还有其他的功能,详细介绍见:
SO_BACKLOG
backlog 也是个老生常谈的话题了(在面试中),其出现的背景是:
TCP 三次握手中,当处于 LISTEN 状态的服务器收到来自客户端的 SYN 包时,会将这个 SYN 包放起来,直到收到客户端对于自己发送另一个的 SYN 包的 ACK 为止,而放入的位置则叫 backlog
在 Linux 中,backlog 分为了两个队列,分别是 SYN 队列和 accept 队列
-
SYN 队列
这个队列就是上面说的用来存放需要等待 ACK 的 socket 的队列。
这个队列的长度由系统控制,即如果修改,只能修改整个系统的 SYN 队列的大小
同时,SYN 队列队满后,会直接把新来的 ACK 包进行抛弃,客户端发现超时未收到 ACK 时会重发。
-
accept 队列
同时,当在 SYN 队列中的 SYN 包收到对应的 ACK 包后,会放入 accept 队列,等待应用程序
accept(),通常这个过程会很快但如果应用程序没有及时的通过
accept()函数将 socket 取出,当这个队列满的时候,将不会把该 SYN 的 ACK 包交给到上层,而是会直接丢掉这个包,当作没收到。而另一方处于
ESTABLISHED的连接虽然已经开始发包,但由于 TCP 的慢启动,所以发送端很快就会发现并进行重发,故并不会有太大的影响。同时当 accept 队列满的时候,还会对 SYN 队列的接收速率加以控制
TCP_FASTOPEN | TCP_FASTOPEN_CONNECT
开启 TCP Fast Open 机制
TCP Fast Open (简称 TFO) 是一个由 Google 工程师设计的算法,用于减少在 TCP 三次握手中建立连接所带来的延时与消耗。
具体来讲,这个算法分为两个部分:
上半部为交换 cookie 的过程
- Client 发送一个 SYN 包请求生成 cookie
- Server 收到后使用对称加密算法对 Client ip 进行加密,然后将加密结果和 ACK 包一起发回给 Client
下半部为使用 cookie 来快速建立 TCP 连接的过程
- Client 想要建立 TCP 时,发送 SYN + cookie + 想要立刻发送的数据,到 Server
- Server 收到后,若校验 cookie 成功,会将收到的自定义数据交给上层应用,并发送对 Client SYN 包的 ACK 与另一个 SYN
- 然后,Server 可以不需要等待收到刚发送的 SYN 包的 ACK,就能立即开始对 Client 发送数据
图片流程示例如下:
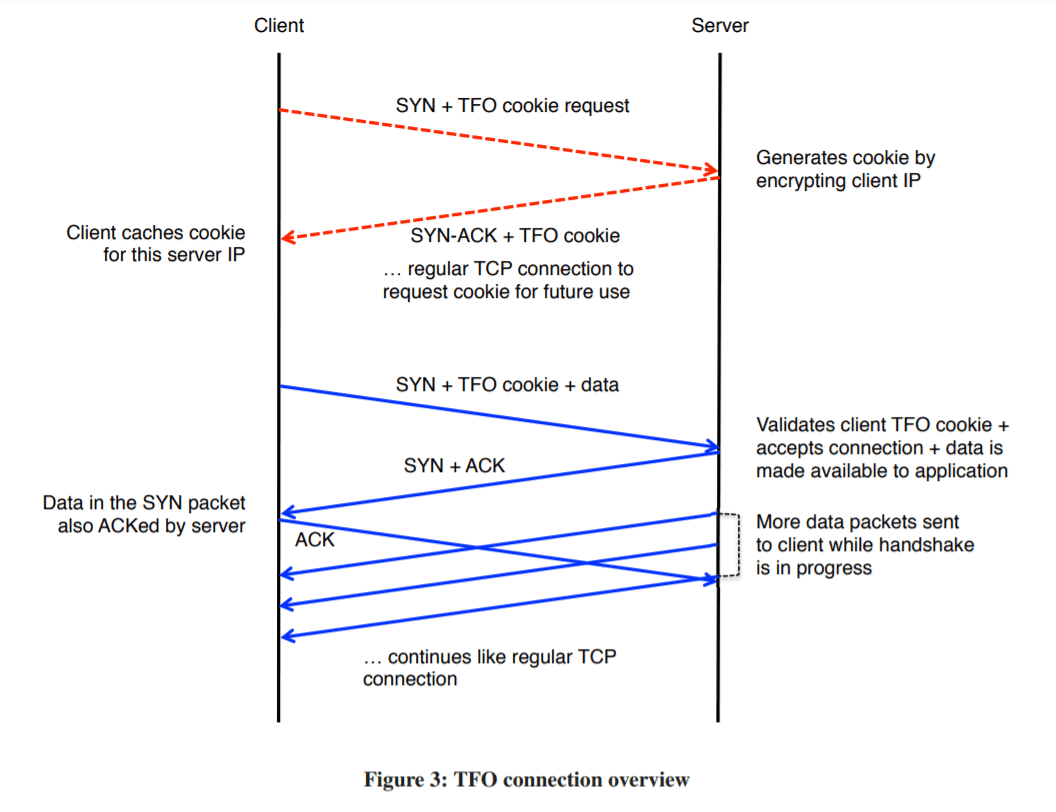
可以看出,由于不需要等待 TCP 连接建立好后就能发送数据,所以节省了不少时间。
但根据上述流程,我们不难发现几个问题:
-
如果两段中有一端不支持 TFO 怎么办?
我们从 TFO 的握手阶段来看:
假定 Client 不支持,那么 Server 只需要进行检查是否具有 cookie 即可,如果没有,则进入普通的 TCP 握手流程
假定 Server 不支持,那么在申请 cookie 时不返回 cookie 即可,这样 Client 即可得知 Server 不支持 TFO,接下来进行普通的 TCP 握手
-
为什么要加上 cookie 生成的过程,直接走下半部分不是更简单更节约吗?
如果网络中不存在攻击的话,这是行得通的,但是在网络中存在一类叫 源地址欺骗攻击(source-address spoofing attack) 的攻击,简单来讲,就是伪造 IP 包首部中的源 IP 字段
如果我们不经过验证就直接的接受来自源 IP 的所有数据包,且在 ACK 前就进行工作与数据的发送;那如果有这么一台机器,不断的发送具有不同的 ip 的伪造的 ip 数据包,那么只需要一台机器就能很快的让服务器的 CPU 资源和网络资源消耗殆尽。
那为什么普通的 TCP 可以避免这种攻击呢?
因为 TCP 需要三次握手才能建立连接,如果对面的 ip 是伪造的,那么 Server 的 ACK 包只会发往被伪造的 ip,用来伪造的机器无法收到这个 ACK 包,所以就无法建立握手,就不能欺骗 Server 处理请求与发送大量数据包
这样的话,第一步生成 cookie 的意图就很好理解了,就是为了目标 ip 不是被伪造的 ip
-
使用了 cookie 后,这个协议就安全了吗?
RFC 7413 的回答是:并不
例如常见的泛洪攻击 (SYN flood),其尝试用大量的 SYN 来请求 Server 建立连接,但不进行响应,从而耗尽服务器的资源。
而这个攻击对于 TFO 造成的影响可能更大,还记得上半部吗?我们在那里使用了对称加密算法进行加密,通常上,我们会使用 AES128,且加密速度只需要几百纳秒,在正常使用中并不会造成影响,但如果受到了泛洪攻击,则造成的影响是可能会耗尽服务器的 CPU 资源的。
而 TFO 的做法是:创建的 cookie 到达一定上限后,退化为普通的 TCP 进行三次握手
除此之外,还有 cookie 窃取等攻击,TFO 同样也做了不少对策
但只用 TFO 是并不会完全安全的,实际上使用时还会配合 SSL/TLS 进行使用
最后,在 Netty 中的这两个选项,一个对应客户端,一个对应服务器,两端都需要打开才有效
Server:
ServerBootstrap sb = ...;
sb.option(ChannelOption.TCP_FASTOPEN, maxPendingFastOpen);
Client:
Bootstrap cb = new Bootstrap();
cb.option(ChannelOption.TCP_FASTOPEN_CONNECT, true);
// ...set handler, etc...
Channel channel = cb.register().sync().channel(); // Get unconnected channel.
ByteBuf fastOpenData = ...;
ByteBuf normalData = ...;
channel.write(fastOpenData); // Write TFO data.
channel.connect(remoteAddress).sync(); // Establish connection (flushes TFO data).
channel.write(normalData); // TCP connection works like normal now.
SO_LINGER
若有数据发送则延迟关闭。
这个设置有两个用处:
第一个是设置为正数,这样在调用 close() 时,会在发送 FIN 包后,等待设置的时间,然后才进行清理并返回;如果没有设置这个时间则会直接进行清理并返回。
当然,我们并不能在这段时间内发送数据,这一段等待时间只是为了接收到,之前发送的数据包的 ACK 和最后的 FIN 包的 ACK;如果不设置这个选项,我们甚至不能确定对方是否收到了数据。
第二个作用则是设置为 0 ,这样在 close() 时,就不会进入到 FIN_WAIT_1 状态,而是直接删除 socket 并清理掉发送缓冲区,然后发送一个 RST 包过去,我们都知道一旦一方收到 RST 包就会直接关闭 socket 。
所以使用这种方法可以直接关闭 TCP 连接而不经过 TIME_WAIT 状态,所以通常被用来结束大量的 TIME_WAIT 状态。
但这并不是一个好的做法,因为 TIME_WAIT 在设计上就是为了让旧的 tcp 包在网络中超时,来避免新的 TCP 连接获取到错误的控制信息
SO_KEEPALIVE
周期测试连接是否存活。
给一个 TCP 的 socket 设置这个选项后,如果 2 小时内维持 socket 的两端都没有互相发送过包(包括发送 FIN 包和 RST 包),设置了该选项的一方的 socket 将会发送一个包。然后对端可能发生以下几种情况:
-
回以对应的 ACK 包
该 socket 仍然存活
-
回以 RST 响应
对方已经的 socket 已经被关闭
-
对方没有任何响应或响应错误
发生这种情况经常是对方的主机已经崩溃或发生了网络故障,此时对面的路由器将会返回常见的 "主机不可达" 响应
当然 2 小时这个时间可以被缩短,但是只能只能调整内核,也就是说不能调整单独的一个 socket。
所以在使用 Netty 时,我们经常选择关闭这个选项,且使用 Netty 自带的心跳控制器。IdleStateHandler 就是我们经常使用的控制器,这个 handler 可以设置 未读超时时间、未写超时时间、未读未写超时时间,当发生以上超时情况的时候,就会发送对应的事件,我们可以通过继承这个类来捕获这些事件,来做出对应的处理 (比如发送一个心跳包保持连接啥的)。
TCP_NODELAY
禁用 Nagle 算法
Nagle 算法主要用于在 TCP 减少分组的数量,当我们发送一个包的时候,如果大小较小(Nagle 算法觉得只要小于 MSS 就算小),且发现还有一些自己发送的包还没被对面 ACK,就会稍微等待一下,到满后,和其他的小的包一起发送。
MSS
最大报文端长度,TCP 连接建立时,双方会确定一个最大缓冲区长度,各自发送的包都不会超过这个大小
ALLOW_HALF_CLOSURE
允许半关闭的 socket(默认不允许)
TCP 是双向通道,所以 TCP 允许只关闭自己发往对端的数据通道,但对端仍然可以向自己发送数据,同时可以从接收的数据通道中读取。
CONNECT_TIMEOUT_MILLIS
TCP 连接建立的超时时间
如果在指定的时间内还没有建立起连接,将会抛出异常 ConnectTimeoutException
SO_TIMEOUT
同上,但是这个是 socket 的选项,即不仅包括 connect 的超时时间,还包括 accept 的等待时间
对于 accept,一般如果不进行指定,会被 accept 阻塞直到客户端的连接建立的请求到来;设置这个时间后,如果在指定的时间内还没有客户端的连接到来,将会抛出异常
SO_BROADCAST
用来开启或关闭广播数据报发送的能力。
开启这个选项后,UDP 才能发送广播数据报;但是对于我们经常使用的 TCP 是无效的
参考资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号