学习手册 | MySQL篇 · 其一
InnoDB关键特性
插入缓冲(Insert Buffer)
问题:
在InnoDB插入的时候,由于记录通常都是按照插入顺序,也就是主键的顺序进行插入的,因此,插入聚集索引是顺序的,不需要随机IO。但是对于非聚集的索引,则由于B+树的特性需要随机IO。
解决:
插入缓冲就是为了解决这个问题。对于非聚集且非唯一的索引,他们的插入先不进行实际的插入,而是先缓存下来,再在某些情况下或定期的真正插入。
如目标页不在内存中,且当前将其读到内存中,就可以先将 buffer 里面的数据应用,再进行操作
该非聚集索引不能是唯一的,这是因为要确保唯一性,就要实际的去随机IO来保证没有重复,这样的话随机IO就已经发生了,无法通过插入缓存来避免。
缺陷:
在写密集的情况下,插入缓冲会占用过多的innodb_buffer_poll,默认最多能占用一半的内存。
Change Buffer
对于DML操作都能进行缓存
该特性适用于读少写多的场景,因为写后读会立刻 merge
两次写(Double Write)
问题:
数据库在宕机时,某个正在写的页会丢失,即使要用 redo log 恢复,也需要先用页的副本来恢复。
解决:
在对数据库的脏页进行刷新时,会先写到内存中的double write buffer,之后会通过double write buffer分两次顺序写入到共享表(在物理磁盘)中。最后再将共享表中的页写入到各个表文件中。
脏页
在内存已经被修改的 Page,还没有刷新到磁盘,但是它会达到最终一致
脏数据
一个事务读到的另一个事务未提交的数据
此时,如果再宕机,InnoDB可以在共享表中找到页的副本,将其复制到对应的表空间。
不过,在从服务器上,可以关闭这个功能来提升性能。
自适应哈希索引(Adaptive Hash Index)
问题:
B+树的查找次数取决于其高度,生产中会在3~4层。
解决:
InnoDB能监控索引的查询,根据监控的结果,来自动为某些热点项建立哈希索引,以提升查询效率。
异步I/O(Asynchronous IO)
问题:
同步IO,即每一次IO操作都需要等待IO结束才能继续。
解决:
异步IO可以一次将所有IO请求发送完,等待所有结果返回。同时还可以合并要访问的页,来避免同时多次访问一页。
刷新邻接页(Flush Neighbor Page)
在刷新一个脏页时,InnoDB可以顺便将其同区的脏页一起刷入,来合并IO操作。
在 MySQL 8.0 被设置为0,这是因为在 SSD 中作用不大
文件
参数文件
通过 mysql --help | grep my.cnf 来找到文件位置
show variables 找到参数
日志文件
-
错误日志(error log)
位置:
show variables like 'log_error' -
二进制日志(binlog)
对数据库的所有更改操作的记录
数据恢复、数据复制
-
慢查询日志(slow query log)
阈值为
long_query_time的值(ms)开关为
log_slow_querieslog_queries_not_using_indexes:无索引同样记录log_throttle_queries_not_using_indexes:每分钟允许记录的无索引查询 -
查询日志
-
中续日志
-
事务日志
socket 文件
使用Unix套接字后再本地连接的文件
pid 文件
MySQL示例运行后的pid写入
MySQL表结构文件
.frm 结尾的文件,用来存储表的结构
存储引擎文件
redo log
至少有一个 redo log 组,每个组下至少有2个 redo log file,可以设置多个镜像日志组在不同硬盘上
但 redo log buffer 只有一个
与 bin log 的区别是,bin log 会记录与MYSQL有关的记录,而 redo log 只会记录与存储引擎本身的事务,同时,它记录的是每个页的更改的物理情况。
同时 bin log 只在事务提交前进行提交,而 redo log 是任何情况下都写入。
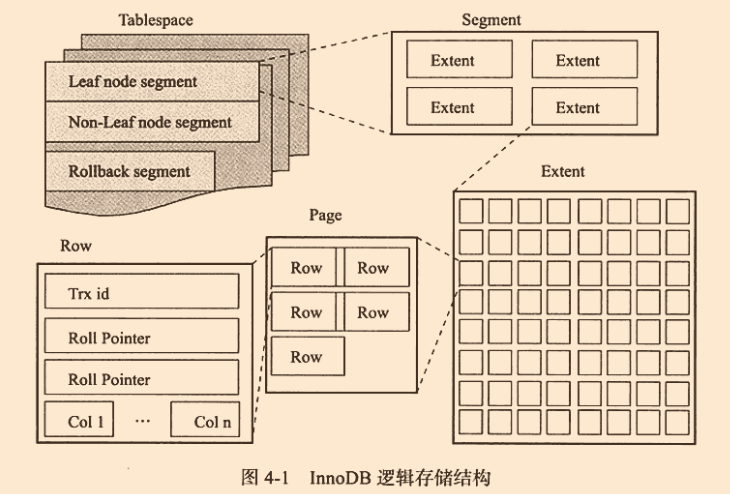
表空间是最高层,所有的数据都放在表空间中
表空间由各个段组成,常见有数据段、索引段、回滚段等。InnoDB是索引结构的,数据段为B+树的叶子节点,索引段则为它的非索引节点
区是由连续的页所组成的空间。任何情况下,区都为1MB。InnoDB一次申请4-5个区。默认情况一个页为16kb
页是InnoDB磁盘管理的最小单位,可以设置为4K、8K、16K。
常见的页类型
-
数据页(B-tree Node)
-
undo页(undo Log Page)
-
系统页(System Page)
-
事务数据页(Transcaction system Page)
-
插入缓冲位图页(Insert Buffer Bitmap)
-
插入缓冲空闲列表页(Insert Buffer Free List)
-
未压缩的二进制大对象页(Uncompressed BLOB Page)
-
压缩的二进制大对象(compressed BLOB Page)
InnoDB是面向列的,就是说是按行来存放的。
Compact 行记录格式
变长字段长度列表-NULL标志位-记录头信息-列1数据-列2数据-....
- 小于255,用1字节表示
- 大于255,用2字节表示
不会超过2个字节,因为varchar的最大长度为65535
varchar最多长度为65535,实际上的长度会低于这个长度,并且这个长度是一行的长度。
InnoDB的页为16k,并不能容下65532字节,所以发生行溢出的时候,数据会存放在 Uncompress BLOB页中。此时在原地址中会保存他的前768字节的前缀数据,然后是指向溢出页的地址。
对于char,由于多字节的字符编码,CHAR不是固定长度的字符串,所以也会将它视为变长,没有占满的会填充0x20
Barracuda拥有两种新的行记录格式:Compressed和Dynamic
这两种会对Blob进行完全的溢出,就是说只存指针,同时会用zlib进行压缩
InnoDB页结构
-
File Header(文件头)
-
Page Header(页头)
-
Infimun 和 Supremum Records
两个虚拟行记录,用来确定记录的边界。
-
User Records(用户记录,就是行记录)
-
Free Space(空闲空间)
一条记录被删除后,会被放到空闲空间
-
Page Directory(页目录)
-
File Trailer(文件结尾信息)
确认页完整写入磁盘
分区
垂直拆分
将字段进行拆分,将主要热门的数据拆分为单表,其余设计为次要表
产生问题:会引起本来不必要 JOIN 操作、事务处理复杂
水平拆分
利用函数分片,如hash,ID范围\时间,映射表
产生问题:分布式事务、关联的表不在同一库(跨节点 JOIN)、ID要保证唯一性
Mysql 原生只支持水平分区,不支持垂直分区
支持的分区类型
-
range
连续区间、通常用于按时间列的分区,因为这样可以触发分区修剪
用时间分区会导致写入操作集中在一个分区,热点倾斜问题。
-
list
离散的区间
-
hash
用户自定义的表达式,也可以直接提供列名
-
key
使用提供的哈希函数,与hash的区别在于,这是使用的MySQL内部的函数
散列能解决热点倾斜,但会失去区间查询特性
分区列需要是唯一索引的一部分,没有主键或唯一索引则可以加入任意的列进行分区
子分区:在分区的基础上再分区,可在在RANGE和LIST的分区上进行Hash或KEY的子分区
NULL值在range上视为最小值,LIST下要显示指定,hash和key会直接视为0
- 对于引擎层,会生成多个表;对于 Server 层,只有一个表
- 所有分区会共用一个 MDL 锁
二级索引
-
基于文档
每个分区维护自己的数据的索引
-
基于词条
全局索引,并且索引拆分
对于OLAP,分区可以很好的提升性能,这是因为要频繁的查询
索引
类型
B+树索引、全文索引、hash索引、R-Tree索引
B+树索引不能直接找到具体行,只能查到其所在页,然后将其页读到内存再进行二分查找,才能找到对应行
数据库中的B+索引可以分为聚集索引和辅助索引,索引页指向的是数据页的偏移量
优点
- 大大减少了服务器需要扫描的数据量
- 帮助服务器避免排序和临时表
- 将随机IO变为顺序IO
缺点
- 索引需要占用额外的内存
- 降低表的DML的操作的速度
- 在巨大数据量下工作不是很好,这种情况下需要分区
注意
- 索引的列必须是独立的列
- 我们可以通过计算 选择性 建立前缀索引,缺点是分布可能不均和无法使用order by和group by,同时无法作用索引覆盖
选择性
不重复的索引值和记录总数的比值
- 将选择性最高的列放在最前面
- 范围查询停止匹配
基数(Cardinality)
查询优化器会根据索引中的 Cardinality 来判断是否使用这个索引,但这个值不是实时更新的,所以可以使用analyze table命令来重新分析。
更新策略:
- 1/16 的数据已经发生了变化
- stat_modified_counter(变化的次数) > 2 000 000 000
计算过程:
- 取得叶子节点数量,为A
- 随机取索引的8个叶子节点,统计每个页不同记录的个数,记为 \(P1\) 、\(P2\) \(...\) \(P8\)
- $Cardinality=(P1+P2+...+P8) * A/8 $
FIC:快速创建辅助索引,创建时会加上S锁
SHARE:将在索引创建中的执行数据加入到日志里,在创建后使用其进行重做
数据更新频繁可能导致基数不准,可以通过 analyze table t 来重新统计索引信息
HASH索引
特性:
- 只存储指针,不能索引覆盖
- 不是顺序存储,不能帮助排序,不能范围查询
- 不存在最左匹配原则
联合索引
本质也是B+树,只是其键值的数量大于等于2,且从左到右建立索引
InnoDB对同时有联合索引和单个索引的选择
直接查询:会选择单个索引,这是因为它的叶子节点包含单个键值。所以一个页可以存放更多的记录。
查询选定目标的最近记录:会选择联合索引,因为第二个字段在联合索引中已经排序好了
前缀索引
?字符串索引的一种方法,可以通过统计每增加一位带来的区分度,来选择前缀长度。同时可以使用倒叙存储和 Hash 字段来优化。
?缺点在于,不能索引覆盖和范围查询
索引覆盖
直接从辅助索引中得到查询的数据,不需要回表查询,在辅助索引上具有主键和辅助索引上的值。
索引覆盖被使用后会出现 using index
索引合并
用多个单列索引来定位引用的值,即将多个不同的索引查询拆分并使用union
前缀压缩
MyISAM可以对具有相同前缀的字符串只存储一次
不走索引的情况
- 索引列参与了计算或函数
- 空值
- 复合索引(a-b-c),只用到了a和c。此时可以通过枚举b值的技巧走索引
force index 可以强制选择索引
MRR(Multi-Range Read)
减少磁盘的随机访问。原理是在获取所有的辅助索引的键值后,通过主键进行排序。
ICP(Index Condition Pushdown)
在取出索引时判断where,这个需要判断的条件能够被索引覆盖的时候才生效
自适应哈希索引
发现二级索引频繁的访问后会被生成到Hash索引里面去
全文索引
倒排索引,在辅助表中存储了单词与单词在一个或多个文档中位置之间的映射
inverted file index
形式为 {单词, 所在文档的ID}
full inverted index
形式为 {单词,(单词所在文档ID,在文档的具体位置)}
碎片
- 行碎片
数据行被存储在多个地方的多个片段
- 行间碎片
在逻辑上顺序的页或行,在磁盘上不是顺序存储的
- 剩余空间碎片
数据页中有大量的空余空间
通过 optimize table 重新整理数据
SQL 优化思路
字段优化
-
数据范围尽量小且简单
-
字段设计不设置null
原因:
- 负向查询不能命中索引
- 预料之外的结果集
- 额外维护null造成的其他工作量
InnoDB对null用额外标志位进行了处理,可用于存储稀疏数据
-
char 和 varchar 在多字节字符集下的实际存储没有区别
-
避免使用bit
-
防止过多的列
语句优化
-
防止大量关联
-
不使用
select * -
多个简单查询 > 一个复杂查询
- 删除大量数据时,一次语句会锁很多行,占据日志,要进行拆分
- 分解关联查询
- 提高缓存命中率
- 减少锁的竞争
- 应用层关联,更易进行拆分
JOIN 优化
- 应该让小表去做驱动表
- 被驱动表上应该走索引
- 如果 join 较慢,可以调大 join_buffer_size
海量数据量下的优化
-
分页
在MySQL使用limit分页时,会先获取所有的数据,再根据limit来丢弃,这样在大数据量下会出现效率低下问题。
- 延迟关联
select uid from user inner join (
select id,uid from user
where x.set = '男'
order by name
limit 1000000,10
) as x using(id,uid)
通过索引覆盖先获取id,再通过id获取详细信息,这样可以减少扫描时需要丢掉的行。
- 子查询分页
select * from user where id >= (
select id from user
order by id
limit 1000000,1
) limit 10
原理和延迟关联接近,先通过只查id来减少需要丢掉的行,再通过获得的id来获得需要的下十列。
- 使用前一次查询的id
select * from user
where id > 999990
order by id
limit 10
?通过上一次获得的id,来直接作用于下一页,这样减少了重复的查询。
一次查询的过程
- 查询缓存(MySQL 8.0 移除)
通过Hash查找有没有匹配的语句,有则直接返回
- 解析器
语法分析,词法分析,生成解析树
- 预处理器
检查解析树是否合法(表名列名是否存在等),鉴权
- 查询优化
静态优化
对where的条件装换为另一种形式等
动态优化
对于where的取值和索引中的行数等
估算查询计划的成本
通过成本选择查询计划,可以通过 show status like 'Last_query_cost' 查看优化器估计需要访问多少的页
- 查询执行引擎
通过存储引擎提供的接口来执行查询计划,将结果返回并加入缓存
锁
latch
轻量级的锁,锁定时间短,InnoDB中分为mutex(互斥量),rwlock(读写锁),无死锁机制。
lock
对象是事务,用来锁对象,在commit或rollback后释放,有死锁机制。
行级锁
共享锁(S Lock),排他锁(X Lock)
意向锁
当一个锁打算获取表锁的时候,需要逐一检查每一行是否有其他锁,但如果有了意向锁,在表上就能知道有其他锁阻塞(快速失败)。
一致性非锁定读
通过多版本并发控制(MVCC)实现的功能,当要读取的数据处于DELETE或UPDATE状态时,可以直接读取其历史快照。
在读提交(READ COMMITED)和可重复读(REPEATABLE READ)中的锁定是不一样的,在前者中,会读取被锁定的最新数据,而后者会读取事务开始时的行数据
一致性锁定读
FOR UPDATE 施加 \(\text X\) 锁,LOCK IN SHARE MODE 施加 \(\text S\) 锁,这个模式只有在选择的情况下生效。
插入类型
- insert-like,所有的插入语句
- simple inserts,在插入前能确定插入行数的语句
- bulk inserts,插入前不能确定得到插入行数的语句
- mixed-mode inserts,一部分是自增长,一部分未知
自增长的方法
- 通过表级别AUTO-INC的锁(如果rollback就会浪费)
- 对于simple inserts使用互斥量(mutex)批量获取ID,获取到足够的ID就会释放锁(间隙更多了),对于bluk inserts还是使用表锁。mutex需要等待表锁。
- 所有语句对同一值进行CAS
InnoDB 计数器在8.0前存在内存中,8.0后保存到 redo log 中
MyISAM 的自增值保存在内存中
外键
mysql会自动给外键加索引
锁算法
-
Record Lock:单个行上的锁
总是去锁索引,没有索引则会用隐式的主键去锁定
-
Gap Lock:间隙锁,锁范围不锁本身
-
Next-Key Lock:上面两锁的集合,锁范围和本身
对于行的查询,都是使用该算法
具有唯一性时,会降级为Record Lock
例:对于1,3,6,进行3的查询,锁的范围会是(1,3),[3,6)
如果不这样做,会导致幻读问题
同一事务下,连续读取两次某个范围的记录,读取的结果不一样
例:
select * from t where id > 2
此时记录有1,2,5,查询的结果应该是5
现在 insert into t values(6)
由于存在next-key lock,会锁住(2,+inf),所以无法插入
事务
-
扁平事务
-
带有保存点的扁平事务
-
链事务
和上一次同的是,会释放当前事务的锁,且只能回滚到最近一个事务
-
嵌套事务
-
分布式事务
ACID 的 D 由 redo log 和 undo log 实现(事务日志)
redo log
由 redo log buffer 和redo log file 组成
保证事务的持久性,基本是顺序写,默认是在事务提交前先写入到磁盘(日志先行),事务提交后才会缓慢刷新回磁盘。也可以通过设定来定时写入和手动写入,在大数据量插入下,这样效果更好,但是会丧失ACID的D。
InnoDB中,重做日志是以512字节存储的
写入磁盘的时机:
- 后台线程每秒都将 buffer write 并 fsync
- 占用空间到达 buffer_size 一半的时候,只 write 不 fsync
- 并行的事务提交时,顺带将 buffer 持久化
组提交
每个日志具有逻辑序列号,在并行事务提交的时候其他事务一起刷入磁盘,而 fsync 调用的次数越少,节约次数越好
binlog
用于 PIT 恢复和主从复制,和重做日志的区别在于,这个是MySQL的上层生成的,记录的是各种SQL语句。
其 Cache 由每个线程维护。
只有在事务提交的时候,才会将其刷新回磁盘。可以通过 sync_binlog 来控制 write 和 fsync 的时机
0:只 write,不 fsync
1:提交事务时都 fsync
N:每次都 write,N 次后才 fsync
每次事务都带有两次刷盘:
? redo log prepare(write) -> binglog(write) -> redo log prepare(fsync) -> binlog(fsynnc) -> red log commit(write)
undo log
记录数据被修改前的日志,帮助事务回滚和MVCC需要用的历史快照的功能
MVCC
通过对数据做多版本管理,来实现了提交读和可重复性读,并且部分解决了幻读
快照读
基于undo log历史版本的读取,不需加锁,配合MVCC能解决幻读
当前读
总是读数据库最新的数据,任何操作都需要加锁(读锁或写锁),需要配合 Next-key Locks 才能解决幻读
InnoDB在select时会使用快照读(for update 除外),update、insert、delete会使用当前读
使用
- 获取事务编号
- 把修改前的数据存储到undo log
- 修改数据
- 将修改后的事务版本号改成当前事务版本号,将undo log地址放入
Read View
这在SQL语句执行前会获得,结构为
- trx_ids:未提交事务的版本号集合
- low_limit_id:当前最大版本号+1
- up_limit_id:未提交事务的最小版本号
- creator_trx_id:当前事务版本号
结果集 在每一行匹配前判断,若
- 该行 事务版本 < up_limit_id,说明是在Read View创建前修改的,故直接显示
- 该行 事务版本 >= low_limit_id,说明最后修改为Read View之后,故不显示
- 该行 up_limit_id < 事务版本 < low_limit_id,说明该记录在Read View创建之时,被另一个事务修改,则若
- 事务版本 不在trx_ids中,说明修改它的事务已经提交,可以显示
- 事务版本 在trx_ids中,且为creator_trx_id,说明修改它的事务是它自己,可以显示
- 事务版本 在trx_ids中,但不为creator_trx_id,说明修改它的事务仍未提交,不能显示
以上判断中,若判定为不显示,则会到undo日志,对每一条记录重复以上判断,直到满足条件,或日志到达尾部。
MVCC可以在读提交和可重复读中运行
读提交中(read commit)中,每一次查询都会获取一个新的read view,这会出现不可重复读
可重复读(read repeated)中,一次事务只会获取一个read view
故从这可以看出在InnoDB中,可重复读的效率比读提交的效率要高
垃圾回收
用户删除的数据只是将其进行了标记,过期的undo log等需要等待后台的Purge线程回收
分布式事务
2PC
两阶段提交
- 协调者向所有节点发送准备请求
- 协调者向所有节点发送提交请求
XA事务
RM(资源管理器):提供访问事务资源的方法
TM(事务管理器):协调各个事务
AP(应用程序):定义事务的边界,全局事务中的操作
备份与恢复
热备份:数据库运行时直接备份
ibbackup
冷备份:数据库停止下复制相关物理文件
温备份:会对数据库运行有影响的备份
逻辑备份:备份出可读的文件,一般是SQL语句
mysqldump、select ... into outfile
裸文件备份:复制数据库的物理文件
完全备份:完整的备份
增量备份:对于上次备份的基础进行备份
日志备份:对二进制日志的备份
复制
主从复制
过程:
- 指定一个节点为主节点,写请求时会发送到这个节点
- 其余节点为从节点,从主节点获取日志,然后写入
- 读请求可以打到主节点或从节点
同步复制:主节点等待从节点确认更改才返回成功
异步复制:主节点自己成功后直接返回
半同步:部分同步,部分异步,同步节点挂时,对异步选举
从节点失效:追赶式恢复
主节点失效:确认失效、选举新节点、配置新节点
产生问题:
- 读自己的写:从节点还未获取修改就读(写后读一致性)
- 单调读:不同从节点数据不同问题(单调读一致性)
- 前缀一致性:写入顺序混乱(分区造成的问题)
多主节点复制
写冲突:对同一块位置进行写
- 避免冲突:分位置选择数据中心
- 收敛于一致状态:应用层处理冲突
无主节点复制
节点失效重启后的数据恢复
-
读修复
读取多副本时,检测不同并回写
-
反熵过程
后台不断查找差异并副本复制
MySQL为基于行的逻辑日志复制
(1) 主服务器将数据更改记录到binlog
(2) 将binlog复制到自己的relay log
(3) 重放relay log,达到数据一致性
参考资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号