
读书报告
Numpy: 基础的数学计算模块,以矩阵为主,纯数学。
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
NumPy 是一个运行速度非常快的数学库,主要用于数组计算,包含:
- 一个强大的N维数组对象 ndarray。
- 广播功能函数。
- 整合 C/C++/Fortran 代码的工具。
- 线性代数、傅里叶变换、随机数生成等功能。
SciPy: 基于Numpy,提供方法(函数库)直接计算结果,封装了一些高阶抽象和物理模型。比方说做个傅立叶变换,这是纯数学的,用Numpy;做个滤波器,这属于信号处理模型了,在Scipy里找。
Pandas: 提供了一套名为DataFrame的数据结构,适合统计分析中的表结构,在上层做数据分析。
Numpy:
来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多,本身是由C语言开发。这个是很基础的扩展,其余的扩展都是以此为基础。数据结构为ndarray,一般有三种方式来创建。
Numpy基本函数
.ndim :维度
.shape :各维度的尺度 (2,5)
.size :元素的个数 10
.dtype :元素的类型 dtype(‘int32’)
.itemsize :每个元素的大小,以字节为单位 ,每个元素占4个字节
ndarray数组的创建
np.arange(n) ; 元素从0到n-1的ndarray类型
np.ones(shape): 生成全1
np.zeros((shape), ddtype = np.int32) : 生成int32型的全0
np.full(shape, val): 生成全为val
np.eye(n) : 生成单位矩阵
np.ones_like(a) : 按数组a的形状生成全1的数组
np.zeros_like(a): 同理
np.full_like (a, val) : 同理
np.linspace(1,10,4): 根据起止数据等间距地生成数组
np.linspace(1,10,4, endpoint = False):endpoint 表示10是否作为生成的元素
np.concatenate():
numpy.empty
numpy.empty 方法用来创建一个指定形状(shape)、数据类型(dtype)且未初始化的数组:
numpy.empty(shape, dtype = float, order = 'C')
实例:
|
1
2
3
|
import numpy as npx = np.empty([3,2], dtype = int)print (x) |
numpy.asarray
numpy.asarray 类似 numpy.array,但 numpy.asarray 参数只有三个,比 numpy.array 少两个。
实例:
|
1
2
3
4
|
import numpy as np x = [1,2,3]a = np.asarray(x, dtype = float) print (a) |
NumPy 从数值范围创建数组
numpy.arange
numpy 包中的使用 arange 函数创建数值范围并返回 ndarray 对象,函数格式如下:
numpy.arange(start, stop, step, dtype)
NumPy 切片和索引
ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。
ndarray 数组可以基于 0 - n 的下标进行索引,切片对象可以通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新数组。
NumPy 统计函数
NumPy 提供了很多统计函数,用于从数组中查找最小元素,最大元素,百分位标准差和方差等。 函数说明如下:
numpy.amin() 用于计算数组中的元素沿指定轴的最小值。
numpy.amax() 用于计算数组中的元素沿指定轴的最大值。
numpy.ptp()函数计算数组中元素最大值与最小值的差(最大值 - 最小值)。
numpy.median() 函数用于计算数组 a 中元素的中位数(中值)
numpy.mean() 函数返回数组中元素的算术平均值。
numpy.average() 函数根据在另一个数组中给出的各自的权重计算数组中元素的加权平均值。
Numpy矩阵库
|
1
2
3
4
5
6
7
8
9
10
|
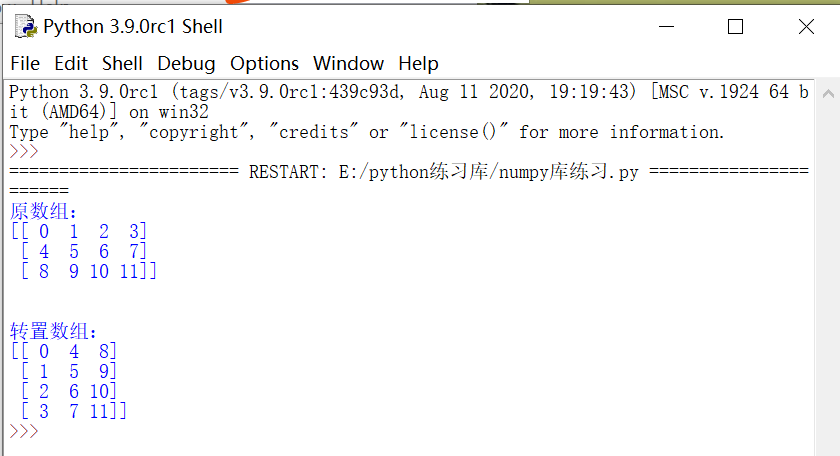
import numpy as np a = np.arange(12).reshape(3,4) print ('原数组:')print (a)print ('\n') print ('转置数组:')print (a.T) |
输出结果:
Pandas:
基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。最具有统计意味的工具包,某些方面优于R软件。数据结构有一维的Series,二维的DataFrame(类似于Excel或者SQL中的表,如果深入学习,会发现Pandas和SQL相似的地方很多,例如merge函数),三维的Panel(Pan(el) + da(ta) + s,知道名字的由来了吧)。
1.汇总和计算描述统计,处理缺失数据 ,层次化索引
2.清理、转换、合并、重塑、GroupBy技术
3.日期和时间数据类型及工具(日期处理方便地飞起)
Matplotlib:
Python中最著名的绘图系统,很多其他的绘图例如seaborn(针对pandas绘图而来)也是由其封装而成。
绘制的图形可以大致按照ggplot的颜色显示,但是还是感觉很鸡肋。但是matplotlib的复杂给其带来了很强的定制性。其具有面向对象的方式及Pyplot的经典高层封装。
需要掌握的是:
1.散点图,折线图,条形图,直方图,饼状图,箱形图的绘制。
2.绘图的三大系统:pyplot,pylab(不推荐),面向对象
3.坐标轴的调整,添加文字注释,区域填充,及特殊图形patches的使用
4.金融的同学注意的是:可以直接调用Yahoo财经数据绘图
Scipy:
方便、易于使用、专为科学和工程设计的Python工具包.它包括统计,优化,整合,线性代数模块,傅里叶变换,信号和图像处理,常微分方程求解器等等。基本可以代替Matlab,但是使用的话和数据处理的关系不大,数学系,或者工程系相对用的多一些。
近期发现有个statsmodel可以补充scipy.stats,时间序列支持完美。
SciPy是一个用于数学、科学、工程领域的常见软件包,可以处理插值、积分、优化、图像处理、常微分方程数值解的求解,信号处理等问题,它用于有效计算Numpy矩阵,使Numpy和SciPy协同工作,高效解决问题。
SciPy常见的函数:
实例分析:
|
1
2
3
|
from scipy import integratex2=lambda x:x**2integrate.quad(x2,0,4) |
结果:

一。 数组要比列表效率高很多
numpy高效的处理数据,提供数组的支持,python默认没有数组。pandas、scipy、matplotlib都依赖numpy。
pandas主要用于数据挖掘,探索,分析
matplotlib用于作图,可视化
scipy进行数值计算,如:积分,傅里叶变换,微积分
statsmodels用于统计分析
Gensim用于文本挖掘
sklearn机器学习, keras深度学习
二。
numpy和mkl 下载安装
pandas和maiplotlib网络安装
scipy 下载安装
statsmodels和Gensim网络安装
三numpy的操作。
import numpy
# 创建数一维数组组
# numpy.array([元素1,元素2,......元素n])
x = numpy.array(['a', '9', '8', '1'])
# 创建二维数组格式
# numpy.array([[元素1,元素2,......元素n],[元素1,元素2,......元素n],[元素1,元素2,......元素n]])
y = numpy.array([[3,5,7],[9,2,6],[5,3,0]])
# 排序
x.sort()
y.sort()
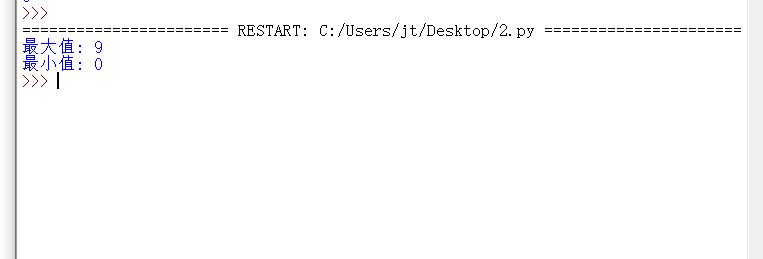
# 取最大值
y1 = y.max()
# 取最小值
y2 = y.main()
# 切片
四pandas的操作。
pandas是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
数据对象的创建
实例分析:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
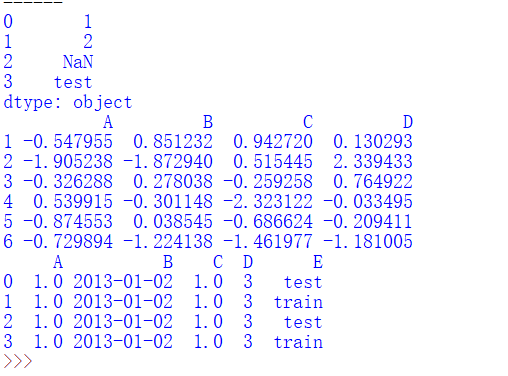
import pandas as pdimport numpy as np # 通过一维数组初始化Seriess = pd.Series([1, 2.0, np.nan, 'test'])print(s) # 通过二维数组初始化DataFramearr = np.random.randn(6, 4)arr_df = pd.DataFrame(arr, index=np.arange(1, 7), columns=list('ABCD'))print(arr_df)# 通过字典dict初始化DataFramedic = {'A': 1., 'B': pd.Timestamp('20130102'), 'C': pd.Series(1, index=list(range(4)), dtype='float32'), 'D': np.array([3] * 4, dtype='int32'), 'E': pd.Categorical(["test", "train", "test", "train"]) }dic_df = pd.DataFrame(dic)print(dic_df) |
- Pandas数据类型操作
重新索引
reindex(index=None, columns=None,…)方法 可改变或重排Series和DataFrame索引
reindex(index=None, columns=None,…)
index, colums 新的行列自定义索引
fill_value 在重新索引,用于填充缺失位置的值
method 填充方法,ffill当前值向前填充, bfill向后填充
limit 最大填充量
copy 默认为True,生成新的对象,False时,新旧相等,但不复制
d.reindex(index = [‘d’, ‘c’, ‘b’, ‘a’ ])
d.reindex(colums = [‘two’, ‘one’])

newc = d.colums.insert( 4, ‘新增’) newc为一个colums
- 索引类型常用方法
.append(idx) 连接另外一个Index对象,产生新的Index对象
.diff(idx) 计算差集,产生新的Index对象
.intersection(idx) 计算交集,产生新对象
.union(idx) 计算并集
.delete(loc) 删除loc位置处的元素
.insert(loc, e) 在loc位置增加一各元素e

删除指定索引对象
.drop()可删除Series或DataFrame制定的行或列
d.drop([‘c1’, ‘c2’]) # 此处生成新对象,原对象d不改变
d.drop(‘one’,axis=1) 要删除列,需要加上axis = 1.
- Pandas库数据类型运算
算术运算法则
根据行列索引进行运算,补齐(NaN)后运算,运算默认产生浮点数
二维和一维、一维和零维时,采用广播运算,即低的于高的每一维运算
算术运算方法形式的运算
.add(d, **argws) .sub(d, **argws) .mul(d, **argws) .div(d, **argws)
**argws为可选参数:
fill_value,补齐时填充的值;
广播运算时,一维的列默认作用到二维的行(axis=1),要更改到列,则需要增加参数
a.add(b, axis=0 )
比较运算
同维度需要有相同的shape
不同维度时,默认为在1轴运算
- 数据排序
.sort_index()方法在指定轴上根据索引进行排序,默认升序。
.sort_index(axis=0,ascending = True) ascending是指递增排序
.sort_values()方法在指定轴上根据数值进行排序,默认升序。
Serier.sort_values(axis= 0, ascending=True)
DataFrame.sort_values(by, axis = 0, ascending = True)
by: 只对axis轴上的某个 索引 或 索引列表 进行排序
NaN空值,保持在排序末尾
- Pandas统计分析函数
.sum() 计算数据总和,按0轴计算
.count() 非NaN值的数量
.mean() .median() 计算算术平均值、算术中位数
.var() .var() 计算方差、标准差
.min() .max 计算最小、大值
.argmin() .argmax() 计算最大、小值所在位置的索引(针对自动索引的)(适用于Series类型:)
.idxmin() .idxmax() 计算最大、小值所在位置的索引(针对自定义索引的)(适用于Series类型:)
.describe() 针对0轴(各列)的统计汇总
import pandas as pda
# 使用pandas生成数据
# Series代表某一串数据 index指定行索引名称,Series索引默认从零开始
# DataFrame代表行列整合出来的数据框,columns 指定列名
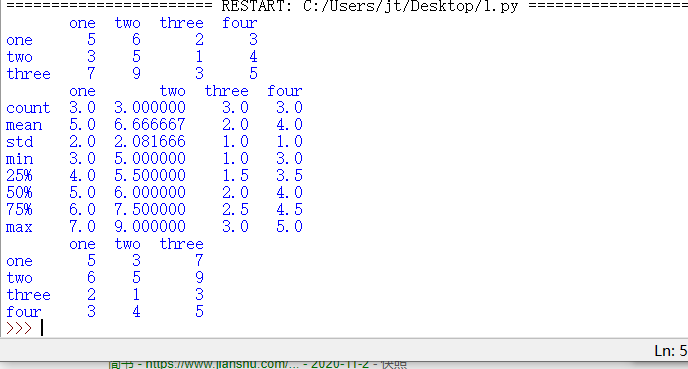
a = pda.Series([8, 9, 2, 1], index=['one', 'two', 'three', 'four'])
# 以列表的格式创建数据框
b = pda.DataFrame([[5,6,2,3],[3,5,1,4],[7,9,3,5]], columns=['one', 'two', 'three', 'four'],index=['one', 'two', 'three'])
# 以字典的格式创建数据框
c = pda.DataFrame({
'one':4, # 会自动补全
'two':[6,2,3],
'three':list(str(982))
})
# b.head(行数)# 默认取前5行头
# b.tail(行数)# 默认取后5行尾
# b.describe() 统计数据的情况 count mean std min 25% max
e = b.head()
f = b.describe()
# 数据的转置,及行变成列,列变成行
g = b.T
print(e)
print(f)
print(g)
matplotlib 是python最著名的绘图库,它提供了一整套和matlab相似的命令API,十分适合交互式地行制图。而且也可以方便地将它作为绘图控件,嵌入GUI应用程序中。在处理数学运算、绘制图表,或者在图像上绘制点、直线和曲线时,这个库都十分实用。
plt.savefig(‘test’, dpi = 600) :将绘制的图画保存成png格式,命名为 test
plt.ylabel(‘Grade’) : y轴的名称
plt.axis([-1, 10, 0, 6]) : x轴起始于-1,终止于10 ,y轴起始于0,终止于6
plt.subplot(3,2,4) : 分成3行2列,共6个绘图区域,在第4个区域绘图。排序为行优先。也可 plt.subplot(324),将逗号省略。
.plot函数
plt.plot(x, y, format_string, **kwargs): x为x轴数据,可为列表或数组;y同理;format_string 为控制曲线的格式字符串, **kwargs 第二组或更多的(x, y,
format_string)
format_string: 由 颜色字符、风格字符和标记字符组成。
颜色字符:‘b’蓝色 ;‘#008000’RGB某颜色;‘0.8’灰度值字符串
风格字符:‘-’实线;‘--’破折线; ‘-.’点划线; ‘:’虚线 ; ‘’‘’无线条
标记字符:‘.’点标记 ‘o’ 实心圈 ‘v’倒三角 ‘^’上三角
pyplot文本显示函数:
plt.xlabel():对x轴增加文本标签
plt.ylabel():同理
plt.title(): 对图形整体增加文本标签
plt.text(): 在任意位置增加文本
plt. annotate(s, xy = arrow_crd, xytext = text_crd, arrowprops = dict)
: 在图形中增加带箭头的注解。s表示要注解的字符串是什么,xy对应箭头所在的位置,xytext对应文本所在位置,arrowprops定义显示的属性
eg:
plt.xlabel(‘横轴:时间’, fontproperties = ‘SimHei’, fontsize = 15, color = ‘green’)
plt.ylabel(‘纵轴:振幅’, fontproperties = ‘SimHei’, fontsize = 15)
plt.title(r’正弦波实例 $y=cons(2\pi x)$’ , fontproperties = ‘SimHei’, fontsize = 25)
plt.annotate (r’%mu=100$, xy = (2, 1), xytext = (3, 1.5),
arrowprops = dict(facecolor = ‘black’, shrink = 0.1, width = 2)) # width表示箭头宽度
plt.text (2, 1, r’$\mu=100$, fontsize = 15)
plt.grid(True)
plt. annotate(s, xy = arrow_crd, xytext = text_crd, arrowprops = dict)
plt子绘图区域
plt.subplot2grid(GridSpec, CurSpec, colspan=1, rowspan=1):设定网格,选中网格,确定选中行列区域数量,编号从0开始。
eg:
plt.subplot2grid((3, 3), (1, 0), colspan = 2) : (3,3)表示分为3行3列,(1,0)表示选中第1行,第0列的区域进行绘图,colspan=2表示在选中区域的延伸
Plot的图表函数
plt.plot(x,y , fmt) :绘制坐标图
plt.boxplot(data, notch, position): 绘制箱形图
plt.bar(left, height, width, bottom) : 绘制条形图
plt.barh(width, bottom, left, height) : 绘制横向条形图
plt.polar(theta, r) : 绘制极坐标图
plt.pie(data, explode) : 绘制饼图
plt.scatter(x, y) :绘制散点图
plt.hist(x, bings, normed) : 绘制直方图
实例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
from PIL import Imagefrom pylab import *import rofim = array(Image.open('empire.jpg').convert('L'))U,T = rof.denoise(im,im)figure()gray()imshow(U)axis('equal')axis('off')show() |
五python数据的导入
import pandas as pad
f = open('d:/大.csv','rb')
# 导入csv
a = pad.read_csv(f, encoding='python')
# 显示多少行多少列
a.shape()
a.values[0][2] #第一行第三列
# 描述csv数据
b = a.describe()
# 排序
c = a.sort_values()
# 导入excel
d = pad.read_excel('d:/大.xls')
print(d)
print(d.describe())
# 导入mysql
import pymysql
conn = pymysql.connect(host='localhost', user='root', passwd='root', db='')
sql = 'select * from mydb'
e = pad.read_sql(sql, conn)
# 导入html表格数据 需要先安装 html5lib和bs4
g = pad.read_html('https://book.douban.com/subject/30258976/?icn=index-editionrecommend')
# 导入文本数据
h = pad.read_table('d:/lianjie.txt','rb', engine='python')
print(h.describe())
六matplotlib的使用
# 折线图/散点图用plot
# 直方图用hist
import matplotlib.pylab as pyl
import numpy as npy
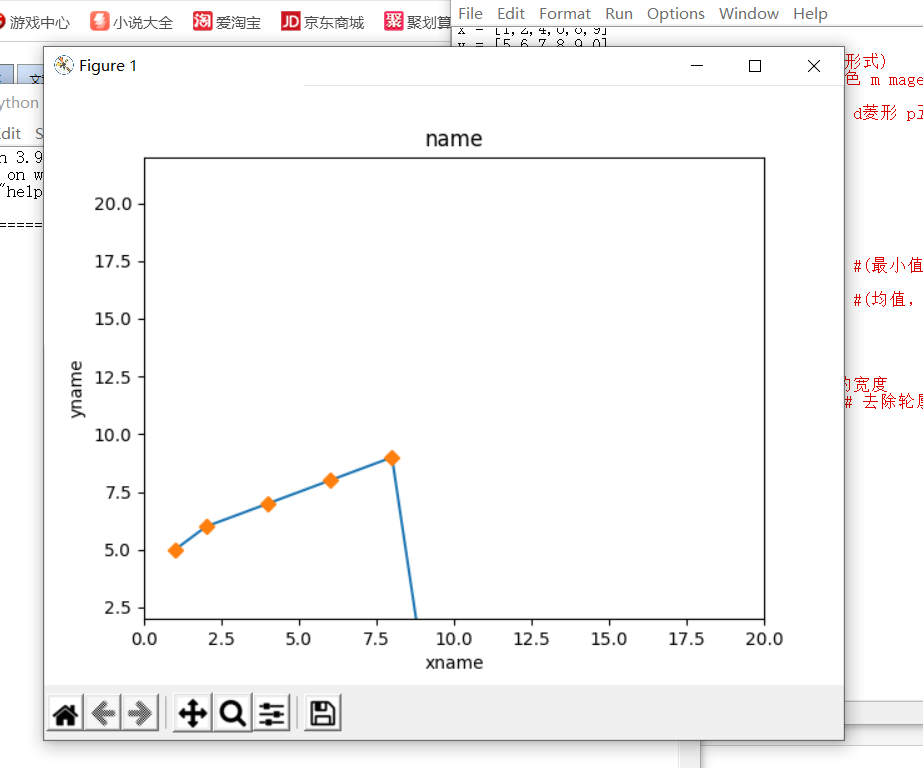
x = [1,2,4,6,8,9]
y = [5,6,7,8,9,0]
pyl.plot(x, y) #plot(x轴数据,y轴数据,展现形式)
# o散点图,默认是直线 c cyan青色 r red红色 m magente品红色 g green绿色 b blue蓝色 y yellow黄色 w white白色
# -直线 --虚线 -. -.形式 :细小虚线
# s方形 h六角形 *星星 + 加号 x x形式 d菱形 p五角星
pyl.plot(x, y, 'D')
pyl.title('name') #名称
pyl.xlabel('xname') #x轴名称
pyl.ylabel('yname') #y轴名称
pyl.xlim(0,20) #设置x轴的范围
pyl.ylim(2,22) #设置y轴的范围
pyl.show()
# 随机数的生成
data = npy.random.random_integers(1,20,100) #(最小值,最大值,个数)
# 生成具有正态分布的随机数
data2 = npy.random.normal(10.0, 1.0, 10000) #(均值,西格玛,个数)
# 直方图hist
pyl.hist(data)
pyl.hist(data2)
# 设置直方图的上限下限
sty = npy.arange(2,20,2) #步长也表示直方图的宽度
pyl.hist(data, sty, histtype='stepfilled') # 去除轮廓
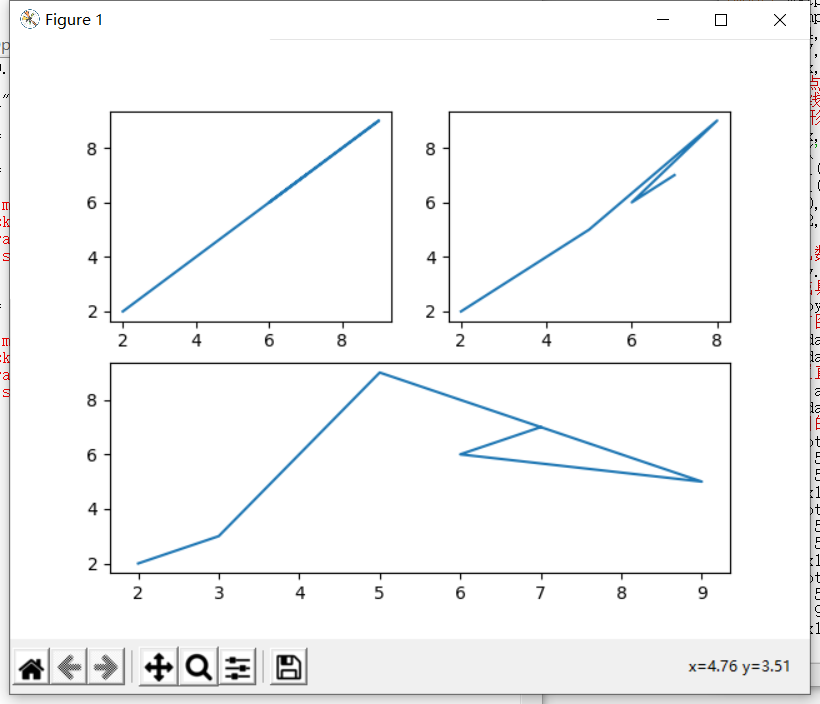
# 子图的绘制和使用
pyl.subplot(2, 2, 2) # (行,列,当前区域)
x1 = [2,3,5,8,6,7]
y1 = [2,3,5,9,6,7]
pyl.plot(x1, y1)
pyl.subplot(2, 2, 1) # (行,列,当前区域)
x1 = [2,3,5,9,6,7]
y1 = [2,3,5,9,6,7]
pyl.plot(x1, y1)
pyl.subplot(2, 1, 2) # (行,列,当前区域)
x1 = [2,3,5,9,6,7]
y1 = [2,3,9,5,6,7]
pyl.plot(x1, y1)
pyl.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号