

ht-6 hashSet特性
Set接口:
Set接口是Collection接口的另外一个常用子接口,Set接口描述的是一种比较简单的集合,集合中的对象并不按特定的方式排序,并且不能保存重复的对象,即set接口可以存储一组唯一的无序的对象。
为什么要用HahSet?
假如我们现在想要在一大堆数据中查找X数据。LinkedList的数据结构就不说了,它的数据结构决定了它的查找效率低的可怕。如果使用ArrayList,在不知道数据的索引,且需要全部遍历的情况下,效率一样的低下。为此,Java集合提供了一个查找效率高的集合类HashSet,该类实现了Set接口,是使用Set集合是最常用的一个实现类,HashSet特性如下:
(1)集合内的元素是无序排列的
(2)HashSet类是非线程安全的
(3)允许集合元素值为null
HashSet类常用方法:
boolean add(Object o) 如果此set集合中尚未傲寒指定元素o,则添加指定元素o
void clear() 从Set集合中移除所有元素
int size() 返回set集合中元素的数量
boolean is Empty() 如果此Set不包含任何元素,则返回true
boolean contains(Object o) 如果此Set包含指定元素,则返回true
boolean remove(Object o) 如果指定元素存在于此Set中,则将其移除
简单示例:
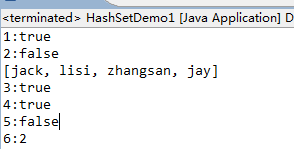
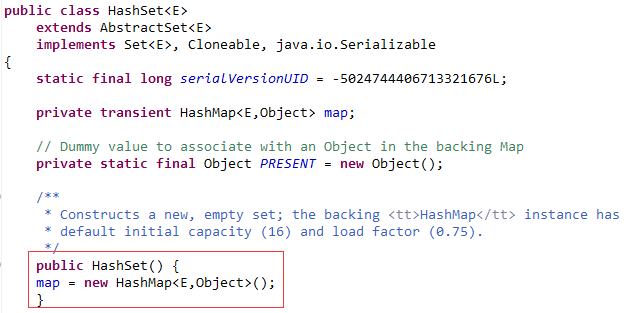
1 package com.iotek.set; 2 3 import java.util.HashSet; 4 5 public class HashSetDemo1 { 6 7 public static void main(String[] args) { 8 HashSet<String> data = new HashSet<String>(); 9 // 创建一个HashSet容器对象 10 data.add("zhangsan"); 11 data.add("lisi"); 12 System.out.println("1:" + data.add("jay")); // 如果添加成功, add()方法返回true 13 data.add("jack"); 14 System.out.println("2:" + data.add("jay")); 15 System.out.println(data); 16 HashSet<Student> stuSet = new HashSet<Student>(); 17 // 把Student对象作为HashSet底层的HashMap里边的键 18 System.out.println("3:" + stuSet.add(new Student("zhangsan", 20))); 19 System.out.println("4:" + stuSet.add(new Student("lisi", 20))); 20 System.out.println("5:" + stuSet.add(new Student("zhangsan", 20))); 21 // 没有重写hashCode()和equals()前,这个重复的对象可以添加进去,重写了之后,就无法添加 22 System.out.println("6:" + stuSet.size()); 23 } 24 25 } 26 27 class Student { 28 private String name; 29 private int age; 30 31 public Student(String name, int age) { 32 super(); 33 this.name = name; 34 this.age = age; 35 } 36 37 public String getName() { 38 return name; 39 } 40 41 public void setName(String name) { 42 this.name = name; 43 } 44 45 public int getAge() { 46 return age; 47 } 48 49 public void setAge(int age) { 50 this.age = age; 51 } 52 53 // 只有当2个对象的hashCode和equals()返回值都相同,才能认定为是同一个对象 54 @Override 55 public int hashCode() { 56 final int prime = 31; 57 int result = 1; 58 result = prime * result + age; 59 result = prime * result + ((name == null) ? 0 : name.hashCode()); 60 return result; 61 } 62 63 @Override 64 public boolean equals(Object obj) { 65 if (this == obj) 66 return true; 67 if (obj == null) 68 return false; 69 if (getClass() != obj.getClass()) 70 return false; 71 Student other = (Student) obj; 72 if (age != other.age) 73 return false; 74 if (name == null) { 75 if (other.name != null) 76 return false; 77 } else if (!name.equals(other.name)) 78 return false; 79 return true; 80 } 81 82 } 83 /* 84 * HashSet原理分析: (1)当调用HashSet的无参构造方法创建一个HashSet对象时, 其内部自动创建了一个HashMap对象,如下所示: 85 * public HashSet() { map = new HashMap<E,Object>(); } 86 * 87 * (2)HashSet没有put()方法,只有add()方法,原因是,这个add()方法其实调用的 88 * 是HashSet()构造方法创建的map对象的put()方法来对数据进行存储,其实操作的是 HashMap对象里的键,值是定义的一个静态常量PRESENT 89 * public boolean add(E e) { return map.put(e, PRESENT)==null; } 90 * (3)size()方法:其实就是返回map对象里的size()方法返回的数据个数 public int size() { return 91 * map.size(); } 92 */
结果如下
HashSet本质:
HashSet底层维护了一个hashMap, set中添加的元素,被作为这个HashMap的key, hashmap键是不能重复的,所以HashSet内部的元素也是不能重复的 ,对于HashSet中保存的对象,需要正确重写equals方法和hashCode方法,以保证放入Set对象的唯一性,正因为这样的原理,HashSet集合是非常高效的,比如,要查找集合中是否包含某个对象,首先计算对象的hashCode,折算出位置号,到该位置上去找就可以了,而不用和所有的元素都比较一遍
参考文章:
https://blog.csdn.net/sugar_rainbow/article/details/68257208
https://www.cnblogs.com/whgk/p/6114842.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号