Cloud Text-to-Speech 中使用了WaveNet,用于TTS,页面上有Demo。目前是BETA版
使用方法
- 注册及认证参考:Quickstart: Text-to-Speech
- 安装google clould 的python库
- 安装 Google Cloud Text-to-Speech API Python 依赖(Dependencies),参见github说明
- ----其中包括了,安装pip install google-cloud-texttospeech==0.1.0
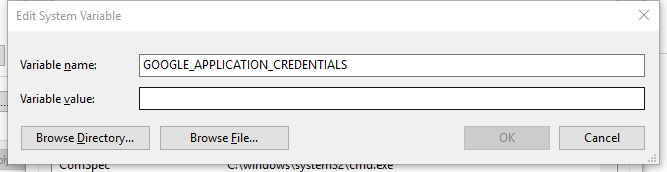
为了implicit调用,设置环境变量GOOGLE_APPLICATION_CREDENTIALS到你的API Key(json文件),完成后重启
python脚本:text到mp3
# [START tts_synthesize_text]
def synthesize_text(text):
"""Synthesizes speech from the input string of text."""
from google.cloud import texttospeech
client = texttospeech.TextToSpeechClient()
input_text = texttospeech.types.SynthesisInput(text=text)
# Note: the voice can also be specified by name.
# Names of voices can be retrieved with client.list_voices().
voice = texttospeech.types.VoiceSelectionParams(
language_code='en-US',
ssml_gender=texttospeech.enums.SsmlVoiceGender.FEMALE)
audio_config = texttospeech.types.AudioConfig(
audio_encoding=texttospeech.enums.AudioEncoding.MP3)
response = client.synthesize_speech(input_text, voice, audio_config)
# The response's audio_content is binary.
with open('output.mp3', 'wb') as out:
out.write(response.audio_content)
print('Audio content written to file "output.mp3"')
# [END tts_synthesize_text]
WaveNet特性
目前支持的6种voice type


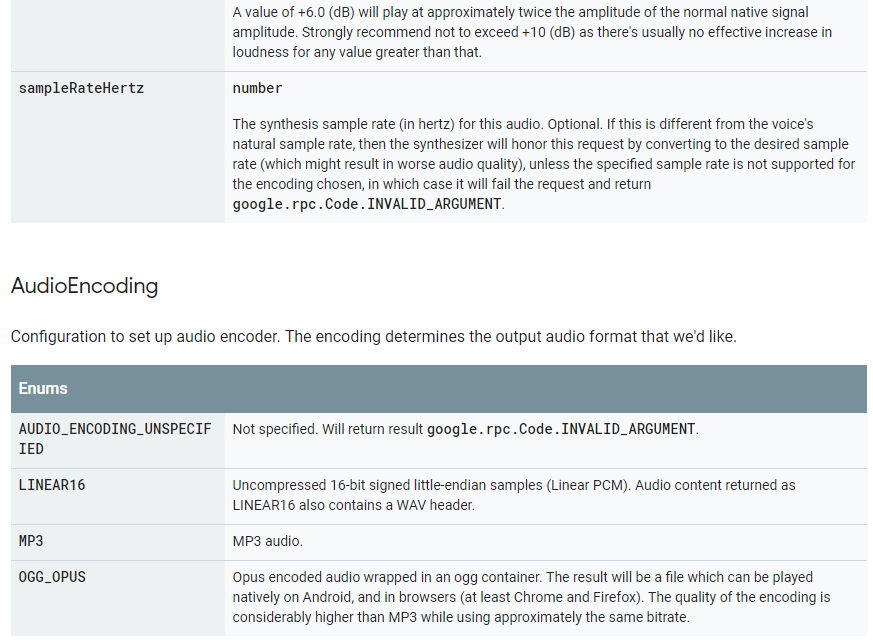
参数说明
https://cloud.google.com/text-to-speech/docs/reference/rest/v1beta1/text/synthesize#audioconfig
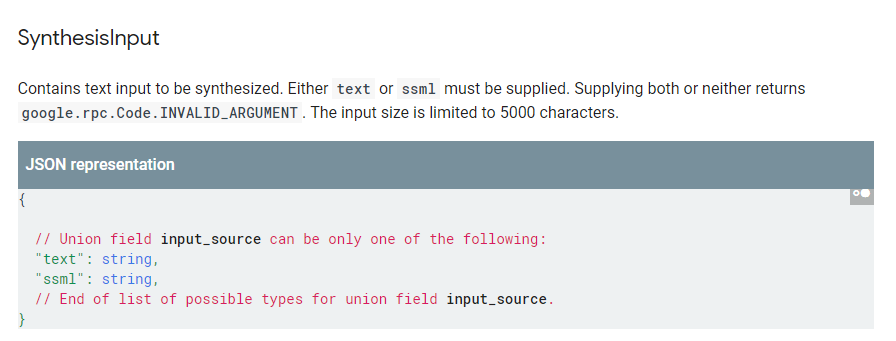
- input_text
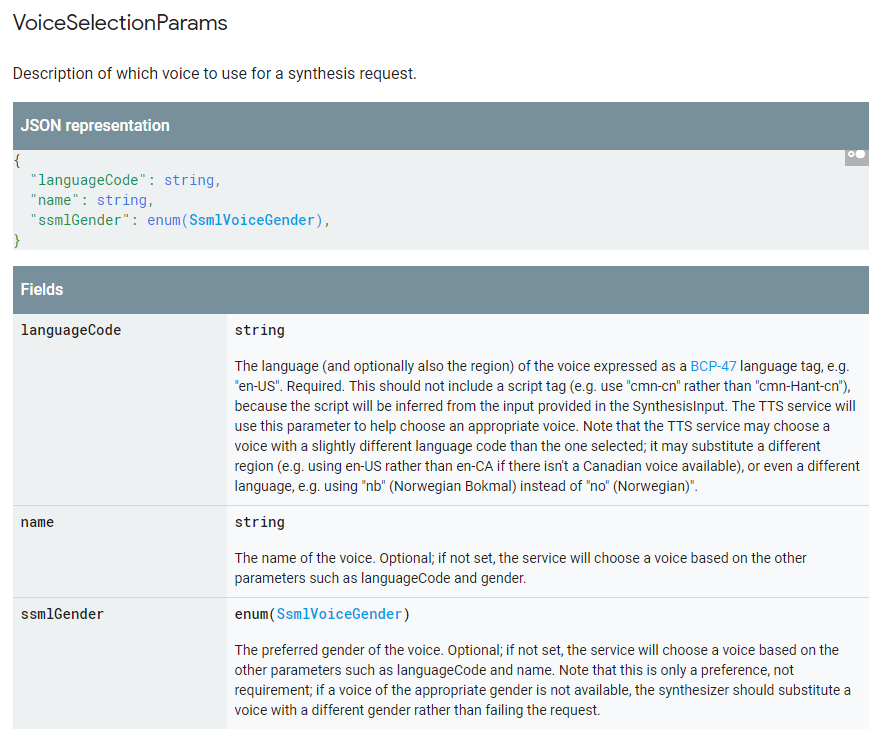
- voice
- audio_config