阿里工程师的综述(包括多标签分类)
- 文本的分布式表示:词向量(word embedding)
- 深度学习的结构一般为:把文本表示为词向量(比如word2vec,需fine-tune) -- 接一个CNN/RNN提取特征 -- 用一个softmax分类
- 最新的结构是:TextRNN + Attention;
- 实际中文本分类任务单纯用CNN已经足以取得很不错的结果了,我们的实验测试RCNN对准确率提升大约1%,并不是十分的显著。最佳实践是先用TextCNN模型把整体任务效果调试到最好,再尝试改进模型。
- 一些工程技巧:如超参调节、如何避免训练震荡
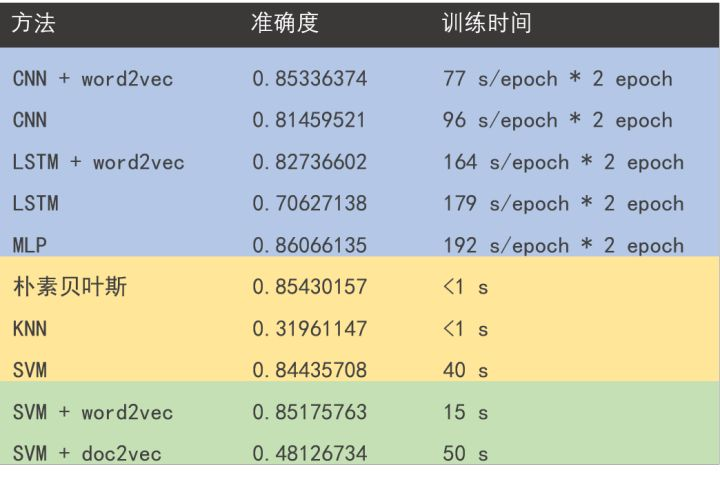
传统与深度学习模型7种实验及代码
- 作者的模型都设计的很简单,所以训练时间较短;工程中需改进模型
- 深度学习方法对比了是否使用word2vec,结论是使用更好;
- 与传统方法相比,深度学习省去了设计特征工程的时间,但是难点在超参调节和训练;
- 参数调节时,画图记录并观察何时收敛是一种有效方法;
Keras: Text & sequences examples
CNN例子:pretrained_word_embeddings.py
CNN + LSTM/GRU 较为常用,工程中的例子参见github-TextCate
word2vec篇
语料库
Build a Spam Filter
http://pythonforengineers.com/build-a-spam-filter/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号