《Machine Learning in Action》
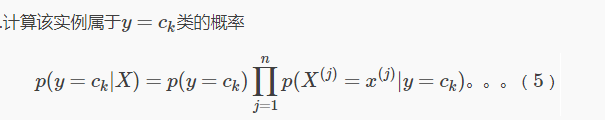
为防止连续乘法时每个乘数过小,而导致的下溢出(太多很小的数相乘结果为0,或者不能正确分类)
训练:
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
p0Num = ones(numWords);p1Num = ones(numWords)#计算频数初始化为1
p0Denom = 2.0;p1Denom = 2.0 #即拉普拉斯平滑
for i in range(numTrainDocs):
if trainCategory[i]==1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom)#注意
p0Vect = log(p0Num/p0Denom)#注意
return p0Vect,p1Vect,pAbusive#返回各类对应特征的条件概率向量
#和各类的先验概率
分类:
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1)#注意
p0 = sum(vec2Classify * p0Vec) + log(1-pClass1)#注意
if p1 > p0:
return 1
else:
return 0
def testingNB():#流程展示
listOPosts,listClasses = loadDataSet()#加载数据
myVocabList = createVocabList(listOPosts)#建立词汇表
trainMat = []
for postinDoc in listOPosts:
trainMat.append(bagOfWord2VecMN(myVocabList,postinDoc))
p0V,p1V,pAb = trainNB0(trainMat,listClasses)#训练
#测试
testEntry = ['love','my','dalmation']
thisDoc = bagOfWord2VecMN(myVocabList,testEntry)
print testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)
注意:上述代码中标有注意的地方,是公式中概率连乘变成了对数概率相加。此举可以在数学上证明不会影响分类结果,且在实际计算中,避免了因概率因子远小于1而连乘造成的下溢出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号