一行代码从PDF提取Excel文件
最近几天,paddleOCR开发了新的功能,通过将图片中的表格提取出来,效果还不错,今天,作者按照步骤测试了一波。
首先,讲下这个工具是干什么用的:它的功能主要是针对一张完整的PDF图片,可以对文档图片中的文本、表格、图片、标题与列表区域进行分类。同时还可以利用表格识别技术完整地提取表格结构信息,使得表格图片变为可编辑的Excel文件。如下图所示可以进行版面分析+表格识别。

核心技术在于两个:一个是PP-Structure的版面分析技术,另一个是PaddleDetection开源的高效检测算法PP-YOLO v2。
PP-Structure Pipeline介绍:
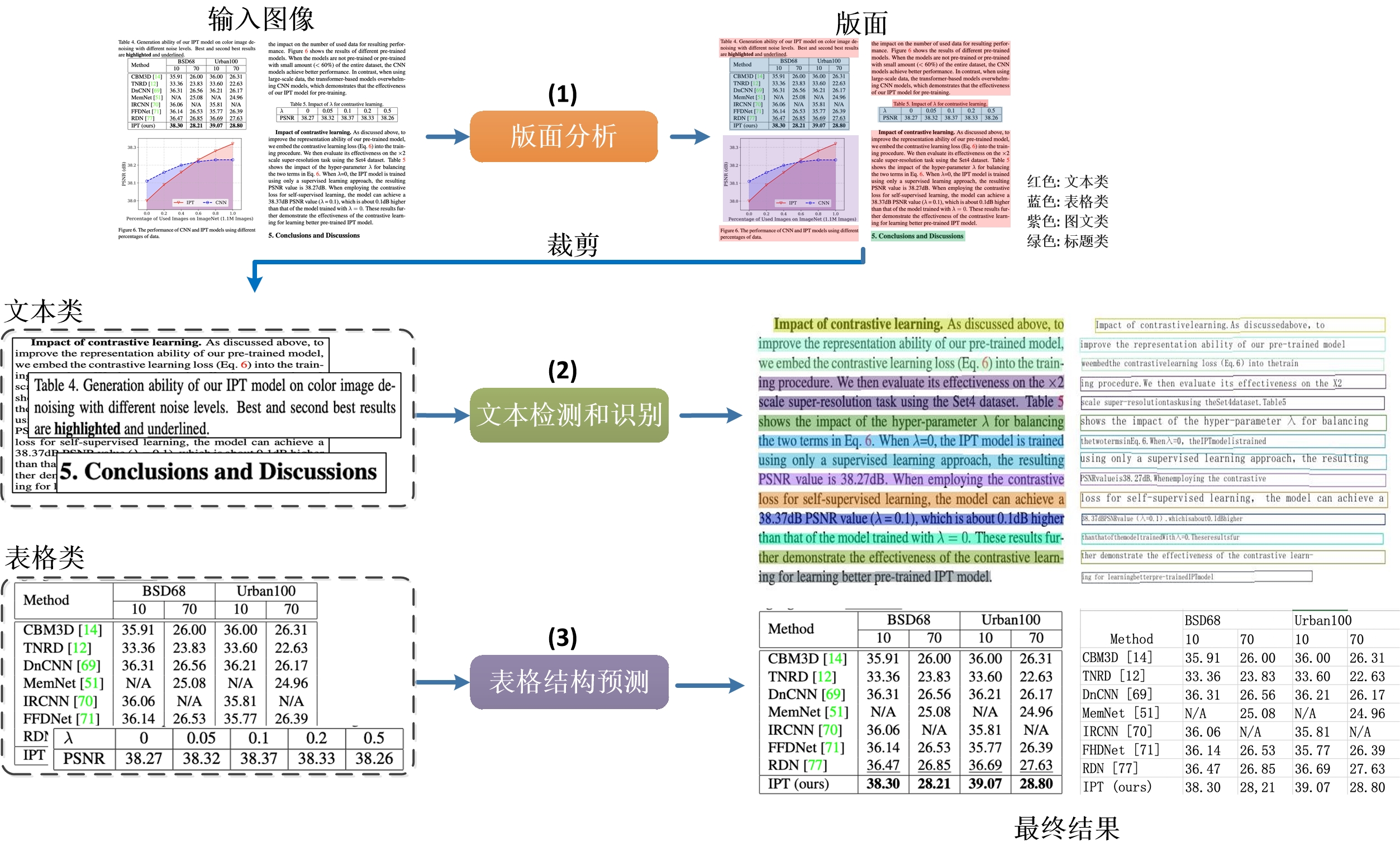
下面作者按照官网的说明进行安装(https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/ppstructure/README_ch.md):
#step1: 首先需要安装paddle # GPU安装 python -m pip install paddlepaddle-gpu==2.1.1 -i https://mirror.baidu.com/pypi/simple # CPU安装(作者在这里使用CPU安装) python -m pip install paddlepaddle==2.1.1 -i https://mirror.baidu.com/pypi/simple #step2:安装 Layout-Parser pip install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl #step3:安装PaddleOCR(包含PP-OCR和PP-Structure) pip install "paddleocr>=2.2"
这样就算安装好了,但是途中会有一些报错信息,一个是 "ImportError: DLL load failed: 找不到指定的模块。" ,在查阅了相关的资料之后,发现重新安装也没有用,作者是通过安装旧版本的软件,就解决了这个问题。另一个报错,是cv2.imread读取图像结果为none,这个错误是由于你的路径中有中文字体,全部修改为英文的即可。
接下来就是运行主要的程序代码,
1 import os 2 import cv2 3 from paddleocr import PPStructure,draw_structure_result,save_structure_res 4 5 table_engine = PPStructure(show_log=True) 6 7 #你的文件结果目录 8 save_folder = 'C:/Users/hp/Desktop/pdf_ocr/output/table' 9 10 #输入的图片 11 img_path = 'C:/Users/hp/Desktop/pdf_ocr/table/5.png' 12 img = cv2.imread(img_path) 13 14 result = table_engine(img) 15 save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0]) 16 17 for line in result: 18 line.pop('img') 19 print(line) 20 21 from PIL import Image 22 23 #字体路径,可以从paddleOCR的github上面下载 24 font_path = 'C:/Users/hp/Desktop/pdf_ocr/fonts/simfang.ttf'
25 image = Image.open(img_path).convert('RGB') 26 im_show = draw_structure_result(image, result,font_path=font_path) 27 im_show = Image.fromarray(im_show) 28 im_show.save('result.jpg')
运行完成后,每张图片会在output字段指定的目录下有一个同名目录,图片里的每个表格会存储为一个excel,图片区域会被裁剪之后保存下来,excel文件和图片名名为表格在图片里的坐标。
这样,就可以看到识别出来的excel表格了。
参考资料:
1、https://mp.weixin.qq.com/s?__biz=MzUzODkxNzQzMw==&mid=2247491570&idx=1&sn=09eabf5ac6679dd785a316690869fd0d&chksm=fad130a4cda6b9b21be478a07f6a3c5ad4e40baf689317767346e61df611a5e8a878929ff209&mpshare=1&scene=1&srcid=0810NrT1vbTrqxIvWoU9AnBj&sharer_sharetime=1628553672500&sharer_shareid=546bd079429f4880a353b991a015fc00&key=65026dce4f4248b55f4903e0445572eb42dbc3a5832201e1d7e729561e5077b72e2a874681641c9743f5b5b99cd5eb608fb71514d56970623a0ac1922a19d505fd46d7f45b0971d9d8e46315178b4ae88f0eb8067c1a1b4053aa027d64b5d0bee4a68ebce3fd0d2473264f8fd5fd1cd76c74763a0070b499db907e7ad0ac766d&ascene=1&uin=NjQ3MTEwMDA1&devicetype=Windows+10+x64&version=6209007b&lang=zh_CN&exportkey=AWZ05MZsgkPJNBjok6heBaI%3D&pass_ticket=UwQ2CEB3lWMMEaQsVFjIb43GL8ytB91uf64qzznTito5hFbvyA3WtFS%2Bnk3KQZju&wx_header=0
2、https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/ppstructure/README_ch.md
3、https://blog.csdn.net/blueheart20/article/details/80985132
4、https://blog.csdn.net/weixin_39866966/article/details/111209027
posted on 2021-08-11 15:53 enhaofrank 阅读(1613) 评论(0) 编辑 收藏 举报


