风控模型---贷后催收模型
做过风控模型或者有过这方面基础的同学们应该都知道评分卡其实也分很多种,按照时间线来划分的有:
申请评分卡—> 欺诈评分卡—> 行为评分卡—> 市场评分卡—> 催收评分卡(又分为失联模型、还款率模型、是否还款模型、迁徙率模型)
本文主要介绍的是催收评分卡:
一、目标变量定义:
衡量还款能力客户为正负样本,这里面正负样本的定义很重要,所以在做模型工作之前需要把正负样本的定义和业务方面沟通,根据实际情况定义好正负样本。
二、数据预处理:
缺失值以及一致性高的特征处理:如果特征超过50%是缺失的,则删除该特征;剩下的特征分两步走,离散型数据用众数填充,连续型特征用KNN方法填充。另外,对一致性高的特征处理:删除一致性很高的特征,因为这些特征对于目标变量没有预测能力。
在进行分箱之前,应该先对数据集进行切分,划分为训练集和测试集。从训练数据进行woe和iv,之后对iv进行特征选择。我看到很多博客里面的内容是不在这一步划分训练和测试集,而是在入模型的时候才划分,我觉得那样做的话,在做分箱这一步相当于看了测试集的结果,会造成过拟合。
#划分训练集和测试集
train_x,test_x,train_y,test_y=train_test_split(data.iloc[:,1:],data.iloc[:,0],train_size=0.7)
train=pd.concat([train_y,train_x],axis=1)
train=train.reset_index(drop=True)
test=pd.concat([test_y,test_x],axis=1)
test=test.reset_index(drop=True)
WOE
WOE(weight of Evidence)字面意思证据权重,对分箱后的每组进行。假设good为好客户(未违约),bad为坏客户(违约)。
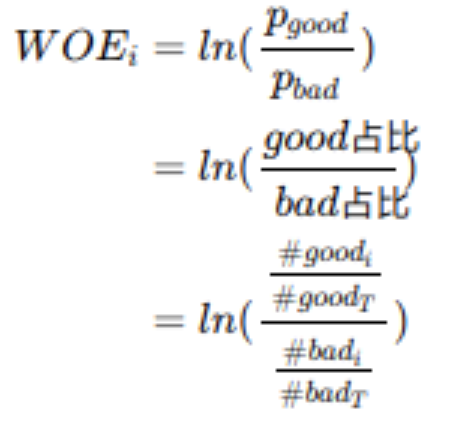
#good(i)表示每组中标签为good的数量,#good(T)为good的总数量;bad相同。这里说一下,有的地方计算WOE时使用的是bad占比/good占比的,其实是没有影响的,因为我们计算WOE的目的其实是通过WOE去计算IV,从而达到预测的目的。后面IV计算中,会通过相减后相乘的方式把负号给抵消掉。所以不管谁做分子,谁做分母,最终的IV预测结果是不变的。
IV
IV(information value)衡量的是某一个变量的信息量,公式如下:
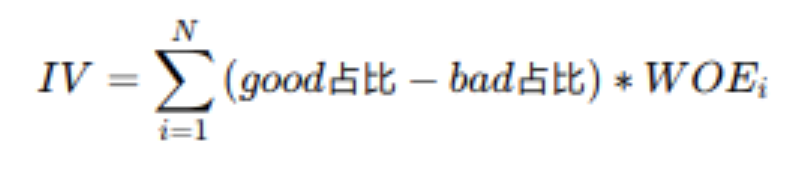
N为分组的组数;
IV可用来表示一个变量的预测能力。
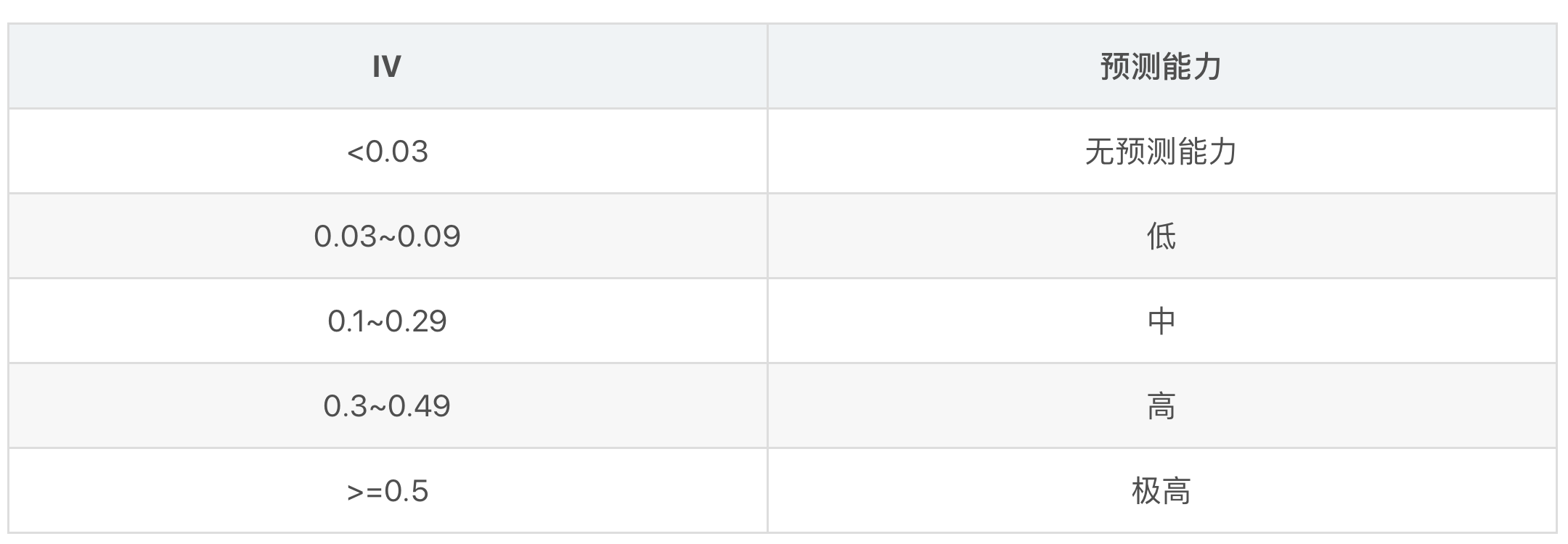
三、变量分箱以及分箱优化:
对分箱结果进行优化,分箱选择上注意事项:
1、一个好的分箱,需保持与业务逻辑一致,WOE趋势呈现单调递增或单调递减或成U形趋势
2、原则上一个变量的分箱大致在5-8组左右,且不同分箱间的WOE值需要一定的差异,差异小于0.1,则建议合并
3、各分箱人群比例不宜太小(<5%),也不宜过度集中(>25%),除非有特殊情况的调整
4、各分箱中,必须同时有好客户和坏客户,不能有一个为0的情况
注意点:WOE通常在-2和+2之间,若超过+/-2,变量本身为极强变量,使用上可能需要*0.3,这样可以防止仅依靠某个特征。
之后用分箱之后的结果对数据进行WOE编码。四、特征选择
基于IV值、相关性、多重共线性、PSI来选择合适的特征,以及结合业务逻辑来选择。
五、建立模型
模型:逻辑回归模型
参数优化:gridsearch进行参数优化,max_iter,C参数等。
样本不平衡处理:过采样、下采样、class_weight='balanced',样本不平衡,导致样本不是总体样本的无偏估计,从而可能导致我们的模型预测能力下降。遇到这种情况,我们可以通过调节样本权重来尝试解决这个问题。调节样本权重的方法有两种,第一种是在class_weight使用balanced。第二种是在调用fit函数时,通过sample_weight来自己调节每个样本权重。这里面用的是class_weight。如果class_weight选择balanced,那么类库会根据训练样本量来计算权重。某种类型样本量越多,则权重越低,样本量越少,则权重越高。
六、模型评估
评价指标:KS,AUC
KS(Kolmogorov-Smirnov):KS用于模型风险区分能力进行评估, 指标衡量的是好坏样本累计分部之间的差值。
好坏样本累计差异越大,KS指标越大,那么模型的风险区分能力越强。ks越大,表示计算预测值的模型区分好坏用户的能力越强。
| ks值 | 含义 |
|---|---|
| > 0.3 | 模型预测性较好 |
| 0,2~0.3 | 模型可用 |
| 0~0.2 | 模型预测能力较差 |
| < 0 | 模型错误 |
AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。从AUC 判断分类器(预测模型)优劣的标准:
-
AUC = 1,是完美分类器。
-
AUC = [0.85, 0.95], 效果很好
七、建立评分卡
信用评分卡主要使用的算法模型是逻辑回归。logistic模型客群变化的敏感度不如其他高复杂度模型,因此稳健更好,鲁棒性更强。另外,模型直观,系数含义好阐述、易理解,使用逻辑回归优点是可以得到一个变量之间的线性关系式和对应的特征权值,方便后面将其转成一一对应的分数形式。

八、模型监控
监控指标:PSI、lift提升度
在模型评估中,我们常用到增益/提升(Gain/Lift)图来评估模型效果,其中的Lift是“运用该模型”和“未运用该模型”所得结果的比值。以信用评分卡模型的评分结果为例,我们通常会将打分后的样本按分数从低到高排序,取10或20等分(有同分数对应多条观测的情况,所以各组观测数未必完全相等),并对组内观测数与坏样本数进行统计。用评分卡模型捕捉到的坏客户的占比,可由该组坏样本数除以总的坏样本数计算得出;而不使用此评分卡,以随机选择的方法覆盖到的坏客户占比,等价于该组观测数占总观测数的比例(分子分母同时乘以样本整体的坏账率)。对两者取累计值,取其比值,则得到提升度Lift,即该评分卡抓取坏客户的能力是随机选择的多少倍。
PSI:群体稳定性指标(population stability index)
公式:psi = sum((实际占比-预期占比)* ln(实际占比/预期占比))
举个例子解释下,比如训练一个logistic回归模型,预测时候会有个概率输出p。你测试集上的输出设定为p1吧,将它从小到大排序后10等分,如0-0.1,0.1-0.2,......。
现在你用这个模型去对新的样本进行预测,预测结果叫p2,按p1的区间也划分为10等分。
实际占比就是p2上在各区间的用户占比,预期占比就是p1上各区间的用户占比。
意义就是如果模型跟稳定,那么p1和p2上各区间的用户应该是相近的,占比不会变动很大,也就是预测出来的概率不会差距很大。
一般认为psi小于0.1时候模型稳定性很高,0.1-0.25一般,大于0.25模型稳定性差,建议重做。
参考资料:
1、https://zhuanlan.zhihu.com/p/36635780
2、https://zhuanlan.zhihu.com/p/30461746
3、https://zhuanlan.zhihu.com/p/70602209
4、https://zhuanlan.zhihu.com/p/40360380
5、https://www.cnblogs.com/pinard/p/6035872.html
6、https://blog.csdn.net/kevin7658/article/details/50780391
7、https://www.jianshu.com/p/ff0eb70d31ec
8、https://blog.csdn.net/q337100/article/details/80693548
9、https://zhuanlan.zhihu.com/p/37319202
10、https://www.jianshu.com/p/72b4b8fed525
11、https://www.cnblogs.com/daliner/p/10268299.html
12、https://www.cnblogs.com/daliner/p/10268350.html
13、https://blog.csdn.net/yilulvxing/article/details/87070624
14、https://www.jianshu.com/p/72b4b8fed525
15、https://www.cnblogs.com/pinard/p/6035872.html
16、https://blog.csdn.net/q337100/article/details/80693548
17、https://www.cnblogs.com/daliner/p/10268299.html
18、https://www.jianshu.com/p/ff0eb70d31ec
19、https://zhuanlan.zhihu.com/p/94015866
20、https://blog.csdn.net/weixin_41358871/article/details/100046694
21、https://blog.csdn.net/u010654299/article/details/103714200
22、https://zhuanlan.zhihu.com/p/79682292/
23、https://blog.csdn.net/sscc_learning/article/details/78591210
24、https://zhuanlan.zhihu.com/p/33417994
25、https://zhuanlan.zhihu.com/p/92691256/
26、https://zhuanlan.zhihu.com/p/90251922
27、https://mp.weixin.qq.com/s?__biz=MzU1NTMyOTI4Mw==&mid=2247515438&idx=1&sn=29457dcc0bdd510554747daaf1d427a5&chksm=fbd70f42cca08654fcad59f86c749db4a09a4bf7ea6af3731197e52ea9f93fb12df7446d2551&mpshare=1&scene=1&srcid=1208LdcTEnjhcs93CYq23bb6&sharer_sharetime=1607433611390&sharer_shareid=546bd079429f4880a353b991a015fc00&key=8395845d7ade1932d4d55c30f5e2176bcc380b1b74357dad0f2e66ef0b02cf21f5a2533f5233eee381e8685270c9ff77602df978004af2ed51ff182d6c520accf1089f8f78e57df74f4ecb712e95b6f6c85205f822f509e32572105056df01594f75c0f6e6fbad8fc48ce9630a334f94cbc09061d005a695d63c5f241a201ca0&ascene=1&uin=NjQ3MTEwMDA1&devicetype=Windows+10+x64&version=6209007b&lang=zh_CN&exportkey=AQr1ypDKSOepV3ktF6J4WGY%3D&pass_ticket=C35kZgcKGqJKVlcAYDLo60GzJ3BOmrOvPEt4ovlYj42dbVsGD827psc1GGcSXScI&wx_header=0
28、https://www.cnblogs.com/daliner/p/10268350.html
posted on 2020-06-03 16:18 enhaofrank 阅读(3976) 评论(0) 编辑 收藏 举报


