JavaScript的进制与编码
一、进制:
1、数值类型声明
JavaScript中允许使用字面量的形式声明不同进制的数字:
var a = 0b10; // 2 声明一个二进制 var b = 010; // 8 八进制,严格模式下会报错 var c = 10; // 10 十进制 var d = 0x10 // 16 十六进制
其中八进制字面量在严格模式下会报错,数字超过范围,将会忽略前导 0 ,解析为十进制数字
var f = 08 ; //8
2、进制之间转换:
调用toString方法,可以在进制之间进行转换。
d.toString(2); //"10000" d.toString(8); //"20" d.toString(10);//"16"
二、字符编码
1、unicode字符集
包括世界上大部分的文字系统的通用字符集的标准。它从0开始,为每个符号指定一个编号,这叫做"码点"(code point)。
Unicode不是一次性定义的,而是分区定义。每个区可以存放65536个(216)字符,称为一个平面(plane)。目前,一共有17个(25)平面,也就是说,整个Unicode字符集的大小现在是221。
最前面的65536个字符位,称为基本平面(缩写BMP),剩下的字符都放在辅助平面(缩写SMP),码点范围从U+010000一直到U+10FFFF。引用
2、utf-32编码
四个字节表示一个码点,字节内容一一对应码点,高位使用0补齐。对于常用字符,均位于2个字节的基本平面中,而使用UTF-32编码的字符均使用4个字节;这种编码方式浪费空间。
3、utf-16编码
utf-16编码规定:位于unicode字符集的基本平面的使用两个字节表示,辅助平面的字符使用4个字节表示。
其中,基本平面的从U+D800( 55296 )到U+DFFF( 57343 )是一个空段,不对应任何一个字符。
辅助平面的字符最长使用20个二进制位表示,这20位拆成两半,前10位映射在U+D800到U+DBFF(空间大小210),称为高位(H),后10位映射在U+DC00到U+DFFF(空间大小210),称为低位(L)。
当遇到码点在U+D800到U+DBFF之间,紧跟在后面的两个字节的码点,应该在U+DC00到U+DFFF之间,这四个字节需要一起解析。
高位、低位转换公式:
H = Math.floor((c-0x10000) / 0x400)+0xD800 L = (c - 0x10000) % 0x400 + 0xDC00
4、utf-8编码
计算机内存中是连续的,按照上述 utf-32 编码方式,就可以每四个字节进行读取字符;utf-16 可以通过高位字节位置判断需要2个字节读取还是4个字节读取。而utf-8作为一种可变长的编码方式,字节除了要表示原有的码点值以外,还要表示当前需要按照几个字节进行读取。
编码规则如下:引用
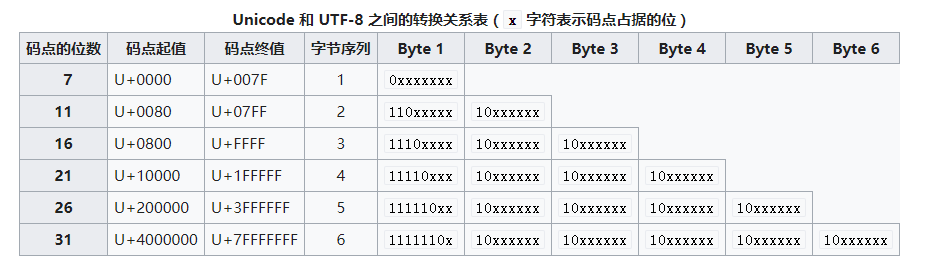
第一个字节高位1连续出现的次数表示当前字符所占的字节数;
例如 :
码点值 位于0-127之间,使用0xxxxxx表示,表示当前字符占用一个字节;
超过127的码点值,使用110xxxxx 10xxxxxx 表示,第一个字节高位连续出现了两个11,表示当前字符占用两个字节;
以博客园的 ‘博’为例,它的码点值:
'博'.charCodeAt(); //21338
经过UTF-8编码之后:
var d = new TextEncoder(); d.encode('博'); // Uint8Array(3) [229, 141, 154]
二进制后格式为:["11100101", "10001101", "10011010"]
将表示字符数量的位去掉。剩下位即是代表码点值。这里去掉第一个字节的‘111’,第二个字节的‘10’,第三个字节的‘10’,剩下即 '00101' , '001101', '011010',拼接后使用二进制表示为
0b00101001101011010 // 21338
三、JavaScript中的编码
1、字符串声明:
JavaScript中没有字符概念。JavaScript允许使用字面量的形式声明一个字符串;
var a = 'a'; //"a" 字面量声明; var b = '\x61';//"a" 使用ASCII码的格式声明一个字符串;\x后面跟的是ASCII 16进制的格式。 var c = '\u0061' // "a" 使用unicode编码声明的字符串;都是16进制格式。
2、码点值与字符转换
码点 => 字符:
String.fromCodePoint() ,返回使用指定的代码点序列创建的字符串;
String.fromCodePoint(97) //"a" 十进制的码点,一串 Unicode 编码位置 String.fromCodePoint(0x61) //"a" 十六进制编码位置
String.fromCharCode() ,返回由指定的UTF-16代码单元序列创建的字符串;
String.fromCodePoint(97);// "a" String.fromCodePoint(0x61); // "a"
两者区别在于fromCharCode参数是UTF-16代码单元的数字。 范围介于0到65535(0xFFFF)之间。 大于0xFFFF的数字将被截断。 不进行有效性检查。
字符 => 码点:
String.prototype.charCodeAt()方法返回0到65535之间的整数,表示给定索引处的UTF-16代码单元;
'a'.charCodeAt(0) //97
String.prototype.codePointAt()
'a'.codePointAt(0);//97 '中'.codePointAt(0);//20013
3、 utf-8编码与字符转换
TextEncoder 接受代码点流作为输入,并提供 UTF-8 字节流作为输出。默认使用 UTF-8 编码。
var d = new TextEncoder(); d.encode('博'); // Uint8Array(3) [229, 141, 154]
TextDecoder 接口表示一个文本解码器、支持特定文本编码,例如 utf-8、iso-8859-2、koi8、cp1261,gbk 等。
let utf8decoder = new TextDecoder() let u8arr = new Uint8Array([229, 141, 154]); console.log(utf8decoder.decode(u8arr)); // 博
参考:
https://zh.wikipedia.org/wiki/UTF-8;
http://www.ruanyifeng.com/blog/2014/12/unicode.html
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
https://developer.mozilla.org/zh-CN/docs/Web/API/TextDecoder

 浙公网安备 33010602011771号
浙公网安备 33010602011771号