字符,字节与编码
英文字母和中文汉字在不同字符集编码中占用的字节数
字符占字节数,需要看编码格式。
ANSI:英文占1个字节,中文占2个字节。
ASCII(128-255):英文占1个字节,中文占2个字节。
英文字母
字节数 : 1;编码:GB2312
字节数 : 1;编码:GBK
字节数 : 1;编码:GB18030
字节数 : 1;编码:ISO-8859-1
字节数 : 1;编码:UTF-8
字节数 : 4;编码:UTF-16
字节数 : 2;编码:UTF-16BE
字节数 : 2;编码:UTF-16LE
中文:
字节数 : 2;编码:GB2312
字节数 : 2;编码:GBK
字节数 : 2;编码:GB18030
字节数 : 1;编码:ISO-8859-1
字节数 : 2~4;编码:UTF-8
字节数 : 4;编码:UTF-16
字节数 : 2;编码:UTF-16BE
字节数 : 2;编码:UTF-16LE
发展历史
从计算机字符编码的发展历史角度来看,大概经历了三个阶段:
第一阶段:ASCII字符集和ASCII编码
计算机刚开始只支持英语(即拉丁字符),其它语言不能够在计算机上存储和显示。ASCII用一个字节(Byte)的7位(bit)表示一个字符,第一位置0。后来为了表示更多的欧洲常用字符又对ASCII进行了扩展,又有了EASCII,EASCII用8位表示一个字符,使它能多表示128个字符,支持了部分西欧字符。
第二阶段:ANSI编码(本地化)
为使计算机支持更多语言,通常使用 0x80~0xFF 范围的2个字节来表示1个字符。比如:汉字 ‘中’ 在中文操作系统里,使用 [0xD6,0xD0] 这两个字节存储。不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用2个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码。不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。
第三阶段:UNICODE编码(国际化)
为了使国际间信息交流更加方便,国际组织制定了 UNICODE 字符集,为各种语言中的每一个字符设定了统一并且唯一的数字编号,以满足跨语言、跨平台进行文本转换、处理的要求。UNICODE 常见的有三种编码方式:UTF-8(1个字节表示)、UTF-16((2个字节表示))、UTF-32(4个字节表示)。
简单历史描述:
1.美国人首先对其英文字符进行了编码,也就是最早的ASCII码,用一个字节的第7位来表示英文的128个字符,高1位统一为0;
2.后来欧洲人发现尼玛你这128位哪够用,比如我高贵的法国人字母上面的还有注音符,这个怎么区分,得把高1位编进来吧,这样欧洲普遍使用一个全字节进行编码,最多可表示256位。欧美人就是喜欢直来直去,字符少,编码用得位数少;
3.但是即使位数少,不同国家地区用不同的字符编码,虽然0–127表示的符号是一样的,但是128–255这一段的解释完全乱套了,即使2进制完全一样,表示的字符完全不一样,比如135在法语,希伯来语,俄语编码中完全是不同的符号;
4.更麻烦的是,电脑高科技传到我们中国后,中国人发现我们有10万多个汉字,你们欧美这256字塞牙缝都不够。于是就发明了GB2312这些汉字编码,典型的用2个字节来表示绝大部分的常用汉字,最多可以表示65536个汉字字符,这样就不难理解有些汉字你在新华字典里查得到,但是电脑上如果不处理一下你是显示不出来的了吧。
5.这下各用各的字符集编码,这世界咋统一?俄国人发封Email给中国人,两边字符集编码不同,尼玛显示都是乱码啊。为了统一,于是就发明了Unicode,将世界上所有的符号都纳入其中,每一个符号都给予一个独一无二的编码,现在Unicode可以容纳100多万个符号,每个符号的编码都不一样,这下可统一了,所有语言都可以互通,一个网页页面里可以同时显示各国文字。
6.然而,Unicode虽然统一了全世界字符的二进制编码,但没有规定如何存储啊亲。x86和AMD体系结构的电脑小端序和大端序都分不清,别提计算机如何识别到底是Unicode还是ASCII了。如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,文本文件的大小会因此大出两三倍,这对于存储来说是极大的浪费。这样导致一个后果:出现了Unicode的多种存储方式。
7.互联网的兴起,网页上如果要显示各种字符,就必须统一。UTF-8就是Unicode最重要的实现方式之一。另外还有UTF-16、UTF-32等。UTF-8不是固定字长编码的,而是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。这是种比较巧妙的设计,如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
8.注意Unicode的字符编码和UTF-8的存储编码表示是不同的,例如”严”字的Unicode码是4E25,UTF-8编码是E4B8A5,这个在7步骤里面做过解释,UTF-8编码不仅考虑了编码,还考虑了存储,E4B8A5是在存储识别编码的基础上塞进了4E25。
9.UTF-8 使用一至四个字节为每个字符编码。128 个ASCII字符(Unicode 范围由 U+0000 至 U+007F)只需一个字节,带有变音符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及马尔代夫语(Unicode 范围由 U+0080 至 U+07FF)需要二个字节,其他基本多文种平面(BMP)中的字符(CJK属于此类)使用三个字节,其他 Unicode 辅助平面的字符使用四字节编码。
10.最后,常规来看,中文汉字在UTF-8中到底占几个字节:一般是3个字节,最常见的编码方式是1110xxxx 10xxxxxx 10xxxxxx。
由ASCII发展而来的各个字符集和编码的分支如下图:
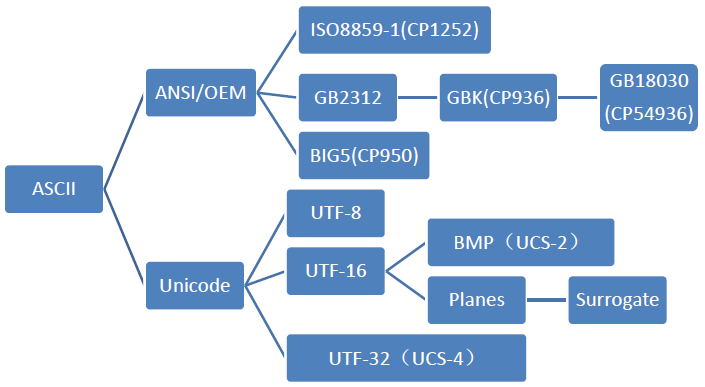
详细内容
ASCII码
我们知道,在计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。
ASCII 码一共规定了128个字符的编码,比如空格SPACE是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
| 二进制 | 十进制 | 十六进制 | 字符/缩写 | 解释 |
|---|---|---|---|---|
| 00000000 | 0 | 00 | NUL (NULL) | 空字符 |
| 00000001 | 1 | 01 | SOH (Start Of Headling) | 标题开始 |
| 00000010 | 2 | 02 | STX (Start Of Text) | 正文开始 |
| 00000011 | 3 | 03 | ETX (End Of Text) | 正文结束 |
| 00000100 | 4 | 04 | EOT (End Of Transmission) | 传输结束 |
| 00000101 | 5 | 05 | ENQ (Enquiry) | 请求 |
| 00000110 | 6 | 06 | ACK (Acknowledge) | 回应/响应/收到通知 |
| 00000111 | 7 | 07 | BEL (Bell) | 响铃 |
| 00001000 | 8 | 08 | BS (Backspace) | 退格 |
| 00001001 | 9 | 09 | HT (Horizontal Tab) | 水平制表符 |
| 00001010 | 10 | 0A | LF/NL(Line Feed/New Line) | 换行键 |
| 00001011 | 11 | 0B | VT (Vertical Tab) | 垂直制表符 |
| 00001100 | 12 | 0C | FF/NP (Form Feed/New Page) | 换页键 |
| 00001101 | 13 | 0D | CR (Carriage Return) | 回车键 |
| 00001110 | 14 | 0E | SO (Shift Out) | 不用切换 |
| 00001111 | 15 | 0F | SI (Shift In) | 启用切换 |
| 00010000 | 16 | 10 | DLE (Data Link Escape) | 数据链路转义 |
| 00010001 | 17 | 11 | DC1/XON | |
| 00010010 | 18 | 12 | DC2 (Device Control 2) | 设备控制2 |
| 00010011 | 19 | 13 | DC3/XOFF | |
| 00010100 | 20 | 14 | DC4 (Device Control 4) | 设备控制4 |
| 00010101 | 21 | 15 | NAK (Negative Acknowledge) | 无响应/非正常响应/拒绝接收 |
| 00010110 | 22 | 16 | SYN (Synchronous Idle) | 同步空闲 |
| 00010111 | 23 | 17 | ETB (End of Transmission Block) | 传输块结束/块传输终止 |
| 00011000 | 24 | 18 | CAN (Cancel) | 取消 |
| 00011001 | 25 | 19 | EM (End of Medium) | 已到介质末端/介质存储已满/介质中断 |
| 00011010 | 26 | 1A | SUB (Substitute) | 替补/替换 |
| 00011011 | 27 | 1B | ESC (Escape) | 逃离/取消 |
| 00011100 | 28 | 1C | FS (File Separator) | 文件分割符 |
| 00011101 | 29 | 1D | GS (Group Separator) | 组分隔符/分组符 |
| 00011110 | 30 | 1E | RS (Record Separator) | 记录分离符 |
| 00011111 | 31 | 1F | US (Unit Separator) | 单元分隔符 |
| 00100000 | 32 | 20 | (Space) | 空格 |
| 00100001 | 33 | 21 | ! | |
| 00100010 | 34 | 22 | " | |
| 00100011 | 35 | 23 | # | |
| 00100100 | 36 | 24 | $ | |
| 00100101 | 37 | 25 | % | |
| 00100110 | 38 | 26 | & | |
| 00100111 | 39 | 27 | ' | |
| 00101000 | 40 | 28 | ( | |
| 00101001 | 41 | 29 | ) | |
| 00101010 | 42 | 2A | * | |
| 00101011 | 43 | 2B | + | |
| 00101100 | 44 | 2C | , | |
| 00101101 | 45 | 2D | - | |
| 00101110 | 46 | 2E | . | |
| 00101111 | 47 | 2F | / | |
| 00110000 | 48 | 30 | 0 | |
| 00110001 | 49 | 31 | 1 | |
| 00110010 | 50 | 32 | 2 | |
| 00110011 | 51 | 33 | 3 | |
| 00110100 | 52 | 34 | 4 | |
| 00110101 | 53 | 35 | 5 | |
| 00110110 | 54 | 36 | 6 | |
| 00110111 | 55 | 37 | 7 | |
| 00111000 | 56 | 38 | 8 | |
| 00111001 | 57 | 39 | 9 | |
| 00111010 | 58 | 3A | : | |
| 00111011 | 59 | 3B | ; | |
| 00111100 | 60 | 3C | < | |
| 00111101 | 61 | 3D | = | |
| 00111110 | 62 | 3E | > | |
| 00111111 | 63 | 3F | ? | |
| 01000000 | 64 | 40 | @ | |
| 01000001 | 65 | 41 | A | |
| 01000010 | 66 | 42 | B | |
| 01000011 | 67 | 43 | C | |
| 01000100 | 68 | 44 | D | |
| 01000101 | 69 | 45 | E | |
| 01000110 | 70 | 46 | F | |
| 01000111 | 71 | 47 | G | |
| 01001000 | 72 | 48 | H | |
| 01001001 | 73 | 49 | I | |
| 01001010 | 74 | 4A | J | |
| 01001011 | 75 | 4B | K | |
| 01001100 | 76 | 4C | L | |
| 01001101 | 77 | 4D | M | |
| 01001110 | 78 | 4E | N | |
| 01001111 | 79 | 4F | O | |
| 01010000 | 80 | 50 | P | |
| 01010001 | 81 | 51 | Q | |
| 01010010 | 82 | 52 | R | |
| 01010011 | 83 | 53 | S | |
| 01010100 | 84 | 54 | T | |
| 01010101 | 85 | 55 | U | |
| 01010110 | 86 | 56 | V | |
| 01010111 | 87 | 57 | W | |
| 01011000 | 88 | 58 | X | |
| 01011001 | 89 | 59 | Y | |
| 01011010 | 90 | 5A | Z | |
| 01011011 | 91 | 5B | [ | |
| 01011100 | 92 | 5C | \ | |
| 01011101 | 93 | 5D | ] | |
| 01011110 | 94 | 5E | ^ | |
| 01011111 | 95 | 5F | _ | |
| 01100000 | 96 | 60 | ` | |
| 01100001 | 97 | 61 | a | |
| 01100010 | 98 | 62 | b | |
| 01100011 | 99 | 63 | c | |
| 01100100 | 100 | 64 | d | |
| 01100101 | 101 | 65 | e | |
| 01100110 | 102 | 66 | f | |
| 01100111 | 103 | 67 | g | |
| 01101000 | 104 | 68 | h | |
| 01101001 | 105 | 69 | i | |
| 01101010 | 106 | 6A | j | |
| 01101011 | 107 | 6B | k | |
| 01101100 | 108 | 6C | l | |
| 01101101 | 109 | 6D | m | |
| 01101110 | 110 | 6E | n | |
| 01101111 | 111 | 6F | o | |
| 01110000 | 112 | 70 | p | |
| 01110001 | 113 | 71 | q | |
| 01110010 | 114 | 72 | r | |
| 01110011 | 115 | 73 | s | |
| 01110100 | 116 | 74 | t | |
| 01110101 | 117 | 75 | u | |
| 01110110 | 118 | 76 | v | |
| 01110111 | 119 | 77 | w | |
| 01111000 | 120 | 78 | x | |
| 01111001 | 121 | 79 | y | |
| 01111010 | 122 | 7A | z | |
| 01111011 | 123 | 7B | { | |
| 01111100 | 124 | 7C | ||
| 01111101 | 125 | 7D | } | |
| 01111110 | 126 | 7E | ~ | |
| 01111111 | 127 | 7F | DEL (Delete) | 删除 |
备注:
数值 8、9、10 和 13 可以分别转换为退格符、制表符、换行符和回车符。这些字符都没有图形表示,但是对于不同的应用程序,这些字符可能会影响文本的显示效果。
非ASCII编码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0-127表示的符号是一样的,不一样的只是128-255的这一段。至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是 GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示 256 * 256 = 65536 个符号。
中文编码的问题需要专文讨论,这篇笔记不涉及。这里只指出,虽然都是用多个字节表示一个符号,但是GB类的汉字编码与后文的 Unicode 和 UTF-8 是毫无关系的。
| 十进制 | 十六进制 | 字符 | 十进制 | 十六进制 | 字符 |
|---|---|---|---|---|---|
| 128 | 0x80 | € | 160 | 0xA0 | [空格] |
| 129 | 0x81 | | 161 | 0xA1 | ¡ |
| 130 | 0x82 | ‚ | 162 | 0xA2 | ¢ |
| 131 | 0x83 | ƒ | 163 | 0xA3 | £ |
| 132 | 0x84 | „ | 164 | 0xA4 | ¤ |
| 133 | 0x85 | … | 165 | 0xA5 | ¥ |
| 134 | 0x86 | † | 166 | 0xA6 | ¦ |
| 135 | 0x87 | ‡ | 167 | 0xA7 | § |
| 136 | 0x88 | ˆ | 168 | 0xA8 | ¨ |
| 137 | 0x89 | ‰ | 169 | 0xA9 | © |
| 138 | 0x8A | Š | 170 | 0xAA | ª |
| 139 | 0x8B | ‹ | 171 | 0xAB | « |
| 140 | 0x8C | Π| 172 | 0xAC |  |
| 141 | 0x8D | | 173 | 0xAD | |
| 142 | 0x8E | Ž | 174 | 0xAE | ® |
| 143 | 0x8F | | 175 | 0xAF | ¯ |
| 144 | 0x90 | | 176 | 0xB0 | ° |
| 145 | 0x91 | ‘ | 177 | 0xB1 | ± |
| 146 | 0x92 | ’ | 178 | 0xB2 | ² |
| 147 | 0x93 | “ | 179 | 0xB3 | ³ |
| 148 | 0x94 | ” | 180 | 0xB4 | ´ |
| 149 | 0x95 | • | 181 | 0xB5 | µ |
| 150 | 0x96 | – | 182 | 0xB6 | ¶ |
| 151 | 0x97 | — | 183 | 0xB7 | · |
| 152 | 0x98 | ˜ | 184 | 0xB8 | ¸ |
| 153 | 0x99 | ™ | 185 | 0xB9 | ¹ |
| 154 | 0x9A | š | 186 | 0xBA | º |
| 155 | 0x9B | › | 187 | 0xBB | » |
| 156 | 0x9C | œ | 188 | 0xBC | ¼ |
| 157 | 0x9D | | 189 | 0xBD | ½ |
| 158 | 0x9E | ž | 190 | 0xBE | ¾ |
| 159 | 0x9F | Ÿ | 191 | 0xBF | ¿ |
| 十进制 | 十六进制 | 字符 | 十进制 | 十六进制 | 字符 |
|---|---|---|---|---|---|
| 192 | 0xC0 | À | 224 | 0xE0 | à |
| 193 | 0xC1 | Á | 225 | 0xE1 | á |
| 194 | 0xC2 | Â | 226 | 0xE2 | â |
| 195 | 0xC3 | Ã | 227 | 0xE3 | ã |
| 196 | 0xC4 | Ä | 228 | 0xE4 | ä |
| 197 | 0xC5 | Å | 229 | 0xE5 | å |
| 198 | 0xC6 | Æ | 230 | 0xE6 | æ |
| 199 | 0xC7 | Ç | 231 | 0xE7 | ç |
| 200 | 0xC8 | È | 232 | 0xE8 | è |
| 201 | 0xC9 | É | 233 | 0xE9 | é |
| 202 | 0xCA | Ê | 234 | 0xEA | ê |
| 203 | 0xCB | Ë | 235 | 0xEB | ë |
| 204 | 0xCC | Ì | 236 | 0xEC | ì |
| 205 | 0xCD | Í | 237 | 0xED | í |
| 206 | 0xCE | Î | 238 | 0xEE | î |
| 207 | 0xCF | Ï | 239 | 0xEF | ï |
| 208 | 0xD0 | Ð | 240 | 0xF0 | ð |
| 209 | 0xD1 | Ñ | 241 | 0xF1 | ñ |
| 210 | 0xD2 | Ò | 242 | 0xF2 | ò |
| 211 | 0xD3 | Ó | 243 | 0xF3 | ó |
| 212 | 0xD4 | Ô | 244 | 0xF4 | ô |
| 213 | 0xD5 | Õ | 245 | 0xF5 | õ |
| 214 | 0xD6 | Ö | 246 | 0xF6 | ö |
| 215 | 0xD7 | × | 247 | 0xF7 | ÷ |
| 216 | 0xD8 | Ø | 248 | 0xF8 | ø |
| 217 | 0xD9 | Ù | 249 | 0xF9 | ù |
| 218 | 0xDA | Ú | 250 | 0xFA | ú |
| 219 | 0xDB | Û | 251 | 0xFB | û |
| 220 | 0xDC | Ü | 252 | 0xFC | ü |
| 221 | 0xDD | Ý | 253 | 0xFD | ý |
| 222 | 0xDE | Þ | 254 | 0xFE | þ |
| 223 | 0xDF | ß | 255 | 0xFF | ÿ |
Unicode编码
世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode,就像它的名字都表示的,这是一种所有符号的编码。
Unicode 当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
Unicode的问题
需要注意的是,Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。比如,汉字"严"的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。这里就有两个严重的问题,第一个问题是,如何才能区别 Unicode 和 ASCII ?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:
1.出现了 Unicode 的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示 Unicode。
2.Unicode 在很长一段时间内无法推广,直到互联网的出现。
UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8 是 Unicode 的实现方式之一。UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
1.对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2.对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位:
Unicode符号范围 | UTF-8编码方式
| (十六进制) | (二进制) |
|---|---|
| 0000 0000-0000 007F | 0xxxxxxx |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
下面,还是以汉字"严"为例,演示如何实现 UTF-8 编码。
严的 Unicode 是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5。
Unicode 与 UTF-8之间的转换
通过以上的例子,可以看到严的 Unicode码 是4E25,UTF-8 编码是E4B8A5,两者是不一样的。它们之间的转换可以通过程序实现。
Windows平台,有一个最简单的转化方法,就是使用内置的记事本小程序notepad.exe。打开文件后,点击文件菜单中的另存为命令,会跳出一个对话框,在最底部有一个编码的下拉条。
以下为Win10系统记事本截图

里面有五个选项:ANSI,UTF-16LE,UTF-16BE和UTF-8及带BOM的UTF-8。
- ANSI是默认的编码方式。对于英文文件是ASCII编码,对于简体中文文件是GB2312编码(只针对 Windows 简体中文版,如果是繁体中文版会采用 Big5 码)。
- UTF-16LE其后缀是 LE 即 little-endian,小端的意思。小端就是将高位的字节放在高地址表示。
- UTF-16BE其后缀是 BE 即 big-endian,大端的意思。大端就是将高位的字节放在低地址表示。
- UTF-8编码,也就是以上谈到的编码方法。
- UTF-8 BOM又叫UTF-8 签名,UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。当文本程序读取到以 EF BB BF开头的字节流时,就知道这是UTF-8编码了。Windows就是使用BOM来标记文本文件的编码方式的。
选择完"编码方式"后,点击"保存"按钮,文件的编码方式就立刻转换好了。
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
扩展:
Unicode的学名是"Universal Multiple-Octet Coded Character Set",简称为UCS。UCS可以看作是"Unicode Character Set"的缩写。在UCS 编码中有一个叫做 "Zero Width No-Break Space",中文译名作“零宽无间断间隔”的字符,它的编码是 FEFF。而 FFFE 在 UCS 中是不存在的字符,所以不应该出现在实际传输中。UCS 规范建议我们在传输字节流前,先传输字符 "Zero Width No-Break Space"。这样如果接收者收到 FEFF,就表明这个字节流是 Big-Endian 的;如果收到FFFE,就表明这个字节流是 Little- Endian 的。因此字符 "Zero Width No-Break Space" (“零宽无间断间隔”)又被称作 BOM(即Byte Order Mark)。
LE(Little Endian) 和 BE(Big Endian)
UCS-2 格式可以存储 Unicode 码(码点不超过0xFFFF)。以汉字严为例,Unicode 码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,这就是 Big endian 方式;25在前,4E在后,这是 Little endian 方式。
这两个古怪的名称来自英国作家斯威夫特的《格列佛游记》。在该书中,小人国里爆发了内战,战争起因是人们争论,吃鸡蛋时究竟是从大头(Big-endian)敲开还是从小头(Little-endian)敲开。为了这件事情,前后爆发了六次战争,一个皇帝送了命,另一个皇帝丢了王位。
第一个字节在前,就是"大头方式"(Big endian),第二个字节在前就是"小头方式"(Little endian)。
那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码?
Unicode 规范定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(zero width no-break space),用FEFF表示。这正好是两个字节,而且FF比FE大1。如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。
BOM格式编码
BOM(Byte Order Mark),是UTF编码方案里用于标识编码的标准标记。
| UTF编码 | Byte Order Mark |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16LE | FF FE |
| UTF-16BE | FE FF |
| UTF-32LE | FF FE 00 00 |
| UTF-32BE | 00 00 FE FF |
在UTF-16里本来是FF FE,变成UTF-8就成了EF BB BF。这个标记是可选的,因为UTF8字节没有顺序,所以它可以被用来检测一个字节流是否是UTF-8编码的。
微软做这种检测,但有些软件不做这种检测, 而把它当作正常字符处理。
这个BOM头只是建议添加,不是强制的,所以不少软件和系统没有添加这个BOM头(所以有些软件格式中有带BOM头和NoBOM头的选择)
总结
UTF-8,UTF-16,UTF-32的区别:
-
UTF-8为可变长的编码方式,根据不同的符号而变化字节长度,节省存储空间
-
UTF-16奇葩,使用 2 个或者 4 个字节来存储
-
UTF-32固定为4个字节,直接存储 Unicode 编号即可,不需要任何编码转换。浪费了空间,提高了效率。
只有 UTF-8 兼容 ASCII,UTF-16 和 UTF-32 都不兼容 ASCII,因为它们没有单字节编码。
摘要:
摘自:https://www.cnblogs.com/hongdada/p/9901246.html
作者:hongdada

