
那么,什么是机器学习呢?机器学习这个词是英文名称Meaching Learning的直译,从字面意义不难知道,这门技术是让计算机具有“自主学习”的能力,因此她是人工智能的一个分支。我个人还是比较喜欢Tom Mitchell在《Machine Learning》一书中对其的定义:
A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
关于机器学习的具体概念及介绍,有很多这方面的资料,有兴趣的话大家可以去查看,在这里我就不赘述。简而言之,机器学习方法就是计算机利用已有的数 据(经验),得出某种模型,并利用模型来预测未来的一种方法,这种方法很类似于人类的思考方式(见图2)。也就是说,机器学习的一个主要目的就是把人类思 考归纳经验的过程转化为计算机对数据的处理计算得出模型的过程。
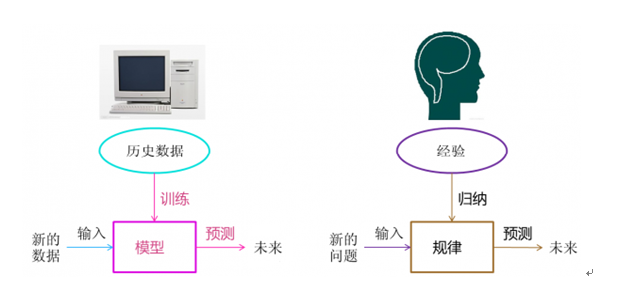
图2:机器学习与人类思考的对比
机器学习算法的类型
一般来说,机器学习算法可以分为监督学习,无监督学习,半监督学习,强化学习(Reinforcement learning)以及推荐这几大类。各部分常见应用场景和算法详见图3。
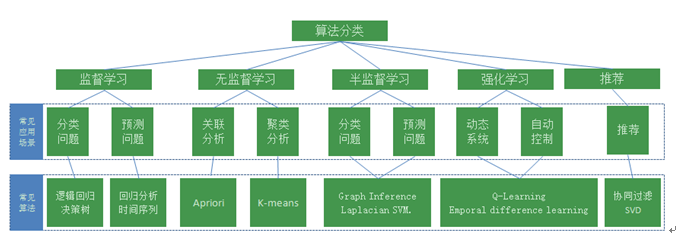
图3:机器学习算法分类
机器学习在互联网金融行业中的应用
在企业数据的应用的场景下,人们最常用的主要是监督学习和无监督学习的模型,在金融行业中一个天然而又典型的应用就是风险控制中对借款人进行信用评估。因此互联网金融企业依托互联网获取用户的网上消费行为数据、通讯数据、信用卡数据、第三方征信数据等丰富而全面的数据,可以借助机器学习的手段搭建互联网金融企业的大数据风控系统。
除了在放贷前的信用审核外,互联网金融企业还可以借助机器学习完成传统金融企业无法做到的放贷过程中对借款人还贷能力进行实时监控,以及时对后续可能无法还贷的人进行事前的干预,从而减少因坏账而带来的损失。以点融网为例,经过这两年的发展,我们积累了很多用户的借款还款信息,这为我们提供了高质量的模型训练样本,也为我们搭建点融的大数据自动化审批系统奠定了坚实的基础。除了自动化审批系统外,后续我们将在用户还款能力实时监控,标的的有效组合,资产的合理配置等方面进行发力。
目前互联网金融企业以及第三方征信公司在信用评估这方面比较常用的架构是规则引擎加信用评分卡。说到信用评分卡,最常用的算法就是Logistic Regression,这也是被银行信用卡中心或金融工程方面奉为法宝的算法。的确,Logistic Regression因其简单、易于解释、开发及运维成本较低而受到追捧。然而互联网中获取的用户的数据维度较多,以离散或分类属性变量居多,且缺失数据 较多,在这种情况下,Logistic Regression的适应性会较差。而且规则引擎和信用评分卡模型分开的模式,有时会因为规则引擎里面某些规则过强而拒绝掉很多优质客户。比如,某人因 学生时代的助学贷款在刚毕业时未能及时偿还而发生过逾期,按现有银行审批规则是无论现在怎样,申请信用卡时一律拒绝。因此比较好的改进方法是,将规则引擎作为一系列弱的分类器,与信用卡评分分类器一块构成强的分类器模型。在这方面,GBDT将是一个不错选择。
GBDT(Gradient Boosting Decision Tree)又叫MART(Multiple Additive Regression Tree), 该模型不像决策树模型那样仅由一棵决策树构成,而是由多棵决策树构成,通常都是上百棵树,而且每棵树规模都较小(即树的深度会比较浅)。模型预测的时候, 对于输入的一个样本实例,首先会赋予一个初值,然后会遍历每一棵决策树,每棵树都会对预测值进行调整修正,最后得到预测的结果。
F(x)=F_0+β_1 T_1 (x)+β_2 T_2 (x)+⋯+β_m T_m (x)
其中,F_0为设置的初值,T_i是一棵棵的决策树(弱的分类器)。
GBDT在被提出之初就和SVM一起被认为是泛化能力(generalization)较强的算法。近些年更因被广泛应用于搜索排序以及推荐中而引 起大家的关注,如Yahoo, Ebay等大型互联网公司就采用过GBDT进行搜索排序。在国内,我在携程工作时就曾应用GBDT算法对客人进行酒店noshow和延住的预测,为公司每 年带来千万的收入,该项目是携程技术驱动业务发展的典型代表。
GBDT作为一种boosting算法,自然包含了boosting的思想,即将一系列弱分类器组合起来构成一个强分类器。它不要求每个分类器都学到太多的东西,只要求每个分类器都学一点点知识,然后将这些学到的知识累加起来构成一个强大的模型。
分类模型的性能评估
分类模型应用较多的除上面讲的Logistic Regression和GBDT,还有Decision Tree、SVM、Random forest等。实际应用中不仅要知道会选用这些模型,更重要的是要懂得对所选用的模型的性能做评估与监控。
涉及到评估分类模型的性能指标有很多,常见的有Confusion Matrix(混淆矩阵),ROC,AUC, Recall, Performance, lift, Gini ,K-S之类。其实这些指标之间是相关与互通的,实际应用时只需选择其中几个或者是你认为是重要的几个即可,无须全部都关注。下面就以Logistic Regression为例对这些常见的指标做些简单的说明,以方便大家理解与应用。
注: 以下所有说明均以信用评分中的好坏用户为例,坏客户(坏人)标识为1(也称正例),好客户(好人)标识为0(也称负例)。
1)Confusion Matrix
一个完美的分类模型就是,一个客户实际上属于坏的类别,模型也将其预测为坏人,实际上是好人时也预测为好人。而实际情况是模型不可能做到这一点,即常说的模型会存在误判,因此我们必须知道模型预测对的有多少,预测错的部分又占了多少,混淆矩阵就是囊括了这些所有信息。

注:
- a是把负例预测成负例的数量,False Negative(FN)
- b是把负例预测成正例的数量,False Positive (FP)
- c是把正例预测成负例的数量,True Negative(TN)
- d是把正例预测成正例的数量,True Positive(TP)
- a+b是实际上为负例的数量,Actual Negative
- c+d是实价上为正例的数量,Actual Positive
- a+c是预测成负例的数量,Predicted Negative
- b+d是预测成正例的数量,Predicted Positive
2)Accuracy(准确分类率)
Accuracy=(true positive and true negative)/total=(a+d)/(a+b+c+d)
3)Error Rate(误分类率)
Error Rate=(false positive and false negative)/total=(c+b)/(a+b+c+d)
4)Recall(正例覆盖率)
recall也称为sensitivity,在机器学习中称recall较多,而sensitivity是生物统计中的常用叫法
Recall=(true positive )/(actual positive)=d/(c+d)
5)Performance也称为Precision(正例的命中率简称命中率)
Performance=(true positive )/(predicted positive)=d/(b+d)
6)Specificity(负例覆盖率)
Specificity=(true negative )/(actual negative)=a/(a+b)
7)Negative predicted value (负例命中率)
Negative predicted value=(true negative )/(predicted negative)=a/(a+c)
一般在工业化应用中看重的是recall和performance,以信用审批为例,我们更关注的是在一定审批通过率的情况下,尽量降低坏账率。
8)ROC
ROC曲线就是不同的阈值下,Sensitivity和1-Specificity的组合,ROC曲线是根据与45度线的偏离来判断模型好坏。
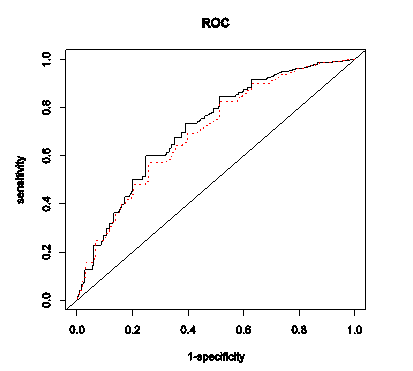
图4:ROC曲线图
9)AUC与GINI
AUC=ROC曲线下的面积
GINI=2AUC-1
10)K-S
用于衡量好坏两个群体分布之间的最大差异,KS=max(Sensitivity-Specificity),KS取值处即为统计意义上的最佳cutoff切点
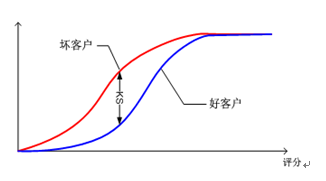
图5:KS关系图
结语
本文简单介绍了下什么是机器学习,机器学习的常用算法,应用机器学习搭建大数据风控系统的探索以及分类模型的性能评估指标。机 器学习听起来很高大上,在实际工作中也经常会遇到一味炒作概念的人,过分夸大机器学习所能起到的作用,或者盲目的追求高深复杂的算法。我个人的观点还是一 方面现阶段机器学习是可以帮我们提高工作效率的科学方法,另外一个方面就是能用简单方法解决问题绝不为了高大上而去选择复杂的方法,毕竟算法是没有三六九 等之分。最后,希望有更多的同学加入到统计与机器学习的研究中来。
作者:甘华来(点融黑帮),现任点融网高级数据分析师,曾在Ebay和携程从事数据分析与机器学习方面的工作,关注统计与机器学习方面的研究、大数据风控系统的建设。
本文由 @甘华来 原创发布于人人都是产品经理 ,未经许可,禁止转载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号