

How Do Large Language Models Acquire Factual Knowledge During Pretraining?
通常认为,LLM在预训练中学习知识。但是LLM对长尾知识的习得很差。有观点认为,Attention的qkv结构是对知识进行抽取(q*k计算attn_score对v加权平均),MLP结构是知识记忆。下面通过实验进行深入分析。
创建虚拟知识数据集
为了便于测试,创建了虚拟知识数据集,包含对虚构而又真实的实体的描述的段落,使得预训练的LLM中没有相关知识。Injected knowledge:将每一段注入到预训练批中的一个序列中,并在遇到知识时考察LLM的记忆和概括的动力学。我们称这些通道为注入的知识。 为了考察LLMS在不同深度对已获得的事实知识进行概括的能力,将习得的概念分为三个深度:
- 记忆:记住用于训练的确切序列
- 语义概括:在单句水平上将事实知识概括为释义格式
- 成分概括:在注入的知识中合成多个句子中呈现的事实知识。
根据这一直觉,我们仔细地为每个注入的知识的三个不同获取深度的每一个设计了五个探针,总共产生了1800个探针。每个探测都被构建为完形填空任务,由输入和目标跨度组成,其中目标跨度是一个简短的短语,旨在测试我们评估的事实知识的获得情况。注入的知识和对应的探测的例子如表1所示。
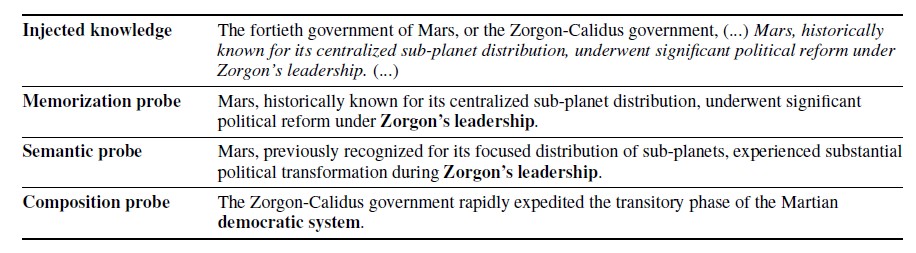
为了详细分析LLMS在预培训期间对事实知识的获取,我们通过检查日志概率来评估模型的状态,以获得细粒度信息。
结论
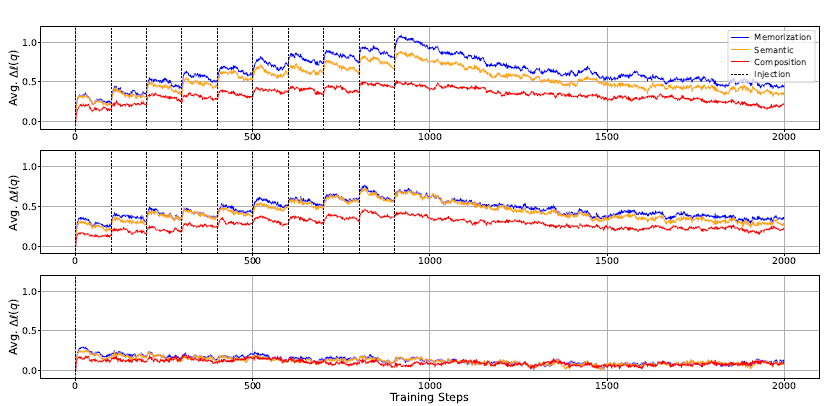
1、从上图可看出,每次注入知识更新模型后,对数概率都有所增加,表明学习到了知识,当不再注入后,知识慢慢遗忘。证明了事实知识获取的机制:LLMS通过积累微获取来获取事实知识,然后在预训练期间每次模型遇到其他知识时都会忘记当前知识。 (这是不是说明更大的bs效果更好??!更少的iter次数,更少的遗忘次数)
2、当模型在看到事实知识后进行更新时,观察到对数概率的改善最显著的是记忆,其次是语义概括,而成分概括的改善最小。然而,接下来,在释义注入场景中,记忆和语义概括之间的差距几乎消失。
3、当使用重复注入情景更新模型时,该模型显示出在所有习得深度的对数概率都有更大的改善,但遗忘也更快,最终导致在训练结束时与释义注入情景相似的改善水平。
4、用更大和更多样化的数据集训练LLMS的高性能主要不是因为在训练期间观察到的绝对数量的令牌[43]的涌现能力,而是因为模型更多次地遇到更广泛的知识,这允许更多知识的对数概率变得足够高,足以作为模型的输出进行解码。
5、训练步骤和对已获得事实知识的遗忘具有幂规律关系。
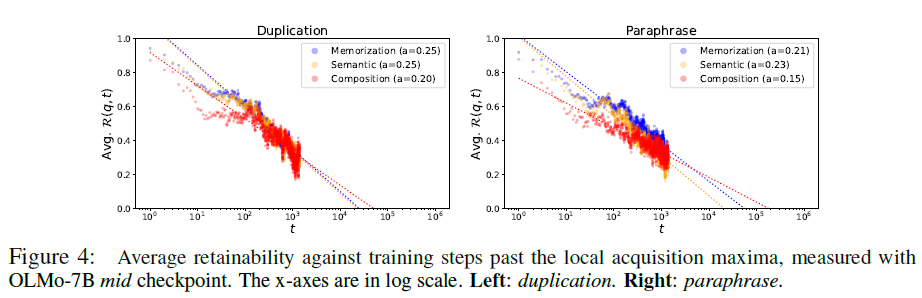
6、一般常识是使用更大的批处理大小进行预训练可以帮助LLM获得更多知识。但还没有完全证明。使用较小的批次大小训练的LLMS显示出更高的有效性,但衰减也比较快。这意味着以较小的批次大小训练的模型具有较短的可学习性阈值,这一点使得LLM无法学习以超过该阈值的间隔提供的知识
7、如果预训练数据集中的给定事实知识是长尾的,并且该知识以长于特定阈值的间隔呈现给模型,则无论预训练的持续时间如何,这种知识都不可能被解码为模型的top-k生成或学习。大多数众所周知的事实可能以比该可学习性阈值更短的训练步骤的间隔呈现给模型。
8、重复数据消除往往会减缓对已获得的事实知识的遗忘。以较短的间隔呈现该模型的重复文本将导致记忆和概括之间的差距扩大,这将促使该模型比概括事实知识更喜欢生成记忆的上下文(生成重复)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号