

RAFT:Reward rAnked FineTuning for Generative Foundation Model Alignment
给一批Prompt,先让大模型生成对每一个prompt生成一个answer,然后让RM去给这些prompt-answer对进行打分,把得分高的选出来用于Fine-tune大模型,得分不高的prompt-answer对直接舍弃。
RRHF:Rank Responses to Align Language Models with Human Feedback without tears
对某一个prompt,通过不同的方式(ChatGPT、人类专家等)生成很多个answer,让RM去打分,然后选出好的去Fine-tune大模型,此外,让大模型也算一下这些answers的似然概率当做评分,让这个评分和RM的打分尽可能对齐(通过Rank loss的监督学习目标)。
总结:1. 这两个工作(github的star都不少)都是只用了RM去给个评分,然后用监督学习的方法更新,没有用到RL,所以不能算是严格的RLHF; 2. 这种Data-centric的思路,即用模型本身 (或者更大的模型)生成的数据(可以看成是数据增强)来微调自己,是general的(Segment anything也是这个思路)。
RL相比于SFT,训练LLM的优势?
- Token-wise有考虑累计回报奖励的潜力;
- RLHF是使用模型生成的样本训练而非SFT中最大似然数据集中的样本,一方面,训练reward model对样本质量要求没那么高(不太好的样本给低评分就好),可以通过一些次优的样本生成更优的策略;另一方面,相比于直接用样本进行最大似然,让模型自己去生成可以允许更多样化的输出(RRHF和RAFT也有这个优势)。
- RLHF可以允许负反馈,而包括RRHF、RAFT的SFT只用了生成出的得分高的样本训练。这样导致的结果是:SFT会让模型过于自信的泛化,而RL能引导模型回答“我不知道”。
- RL优化Agent行为以达到其他特定目标(通过修改奖励函数),比监督学习更灵活。
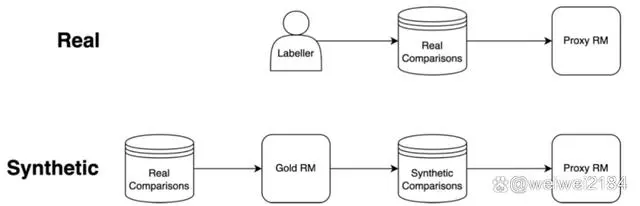
当我们用RL去拟合一个没那么准的RM的时候,就会发生过度优化的情况。OpenAI实验的方法,是用InstructGPT那份真实的数据去训练一个Gold RM,再用Gold RM生成数据去训练一个Proxy RM(下图Synthetic部分):
从结果可以看到,虽然Proxy RM的分数会一直上升(虚线),但真实效果,也就是Gold RM会饱和甚至下降(实线):
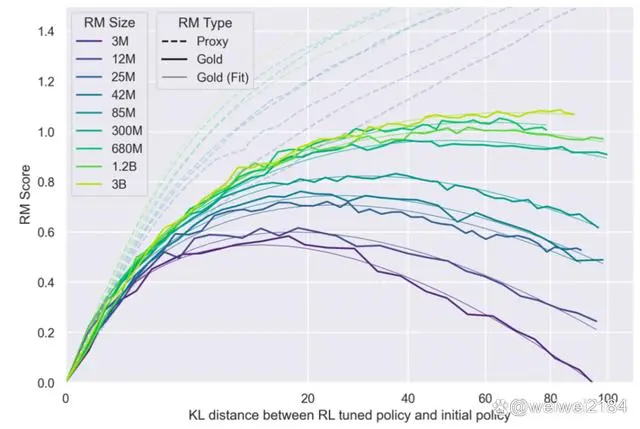
所以由于RM的效果限制,现阶段的RLHF还不太完美,只是Human Feedback的一个降级方案。
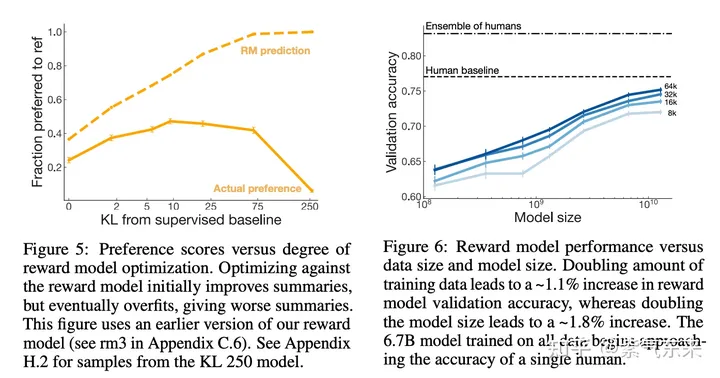
将两个模型的生成文本进行比较计算差异的惩罚项,通常设计为输出词分布序列之间的 Kullback–Leibler (KL) 散度的缩放;这一项被用于惩罚 RL 策略在每个训练批次中生成大幅偏离初始模型,以确保模型输出合理连贯的文本。如果去掉这一惩罚项可能导致模型在优化中生成乱码文本来愚弄奖励模型提供高奖励值。
下面看一下 reward model。 左图比较了在不同的 KL penalty 权重下模型的表现。我们看到当 KL penalty 小即在图的左端,模型的实际表现很糟。这也说明了KL项的必要性。随着惩罚项增大,RM预测的效果开始提升,但当惩罚项过大时,RM 预测不再提升,即与SFT保持一致。右图说明了对于reward model,模型越大,数据越多效果越好。
指令微调也就是对齐阶段的数据质量>>数量,少量+多样+高质量的对齐数据,就能让你快速拥有效果杠杠的模型。注意以上三者是充分必要关系,不是说数据越少越好,是三者的有机统一。构建质量更高,覆盖范围更广的数据,是否比随机造大量的指令数据效果要更好。毕竟你抖音刷1000条杂七杂八的中医养生小知识,可能比不上精读黄帝内经+神农本草不是。模型的知识和能力几乎全部是预训练阶段注入的。而指令微调阶段的对齐只是学习和人类交互的回答形式。因此一个输入多样,输出形式一致的高质量指令数据集能帮模型快速学到回答形式;论文反复强调一致的回答风格可以加速模型收敛
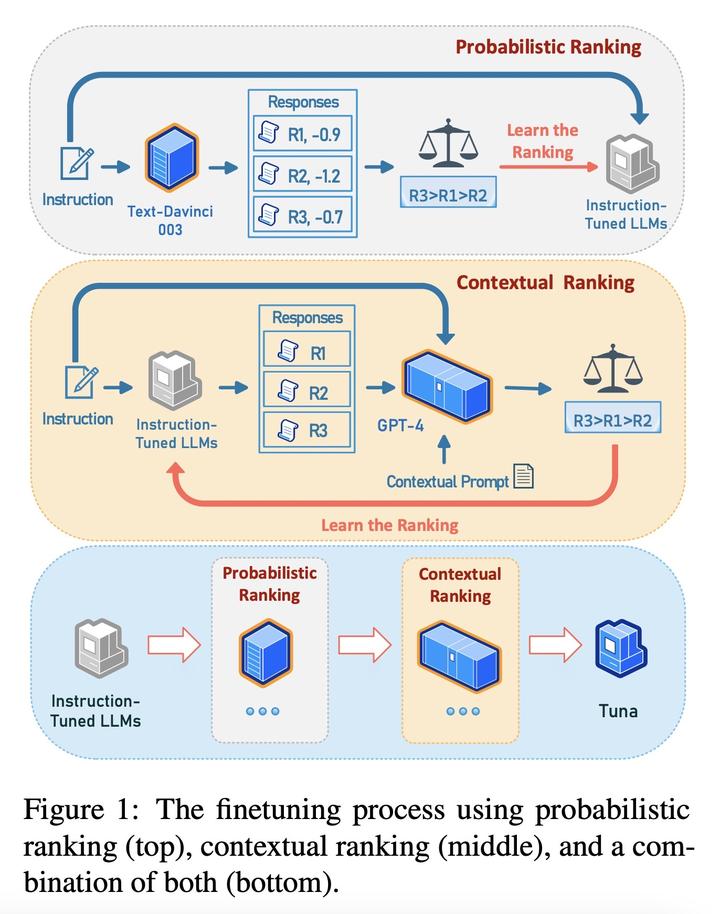
Tuna: 使用来自大型语言模型的反馈进行指令微调
要点:
- 使用更强大的语言模型比如InstructGPT和GPT-4的输出来指令微调开源大型语言模型比如LLaMA,是使模型行为与人类偏好保持一致的经济高效的方式。但是,接受指令微调的模型对每个指令只看到一个回复,缺乏对潜在更好回复的认知。
- 提出采用新的概率排序和上下文排序方法来进一步微调接受指令微调的语言模型,以提高生成更好回复的可能性。
- 概率排序使模型可以继承老师模型对高质量和低质量回复的相对排序,上下文排序则利用更强大的语言模型的上下文理解能力来优化模型自己的回复分布。
- 这两种排序方法顺序地应用于接受指令微调的语言模型。得到的Tuna模型在Super Natural Instructions(119个任务)、LMentry(25个任务)和Vicuna QA上的表现均有持续改进,甚至超过了几个强大的强化学习基准模型。
动机:目前,通过对大型语言模型(LLM)进行指令微调可以使其行为与人类偏好相一致。然而,现有的方法只能提供每个指令的单个响应,并且缺乏了解潜在更好响应的能力。
方法:提出一种新的概率排序和上下文排序方法,通过对指令微调的LLM进行微调,增加生成更好响应的可能性。概率排序使得指令微调的模型可以继承来自教师LLM的高质量和低质量响应的相对排序。而上下文排序则利用更强的LLM的上下文理解能力,使模型能优化自身的响应分布。此外,本文还将概率排序和上下文排序依次应用于指令微调的LLM。
优势:所提出的Tuna模型在Super Natural Instructions、LMentry、Vicuna QA等测试任务上表现出色,甚至比强化学习基线模型取得更好的结果。
一句话总结:
提出一种通过概率排序和上下文排序方法对指令微调的LLM进行微调的方法,从而提高生成更好响应的能力。Tuna模型在多个基准测试任务上表现出色,超过了强化学习基线模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号