
前言
最近,深度学习在许多时间序列分析任务中表现出色。深度神经网络的优越性能严重依赖于大量训练数据以避免过度拟合。然而,许多现实世界时间序列应用的标记数据可能受到限制,例如医学时间序列中的分类和AIOps中的异常检测。作为提高训练数据规模和质量的有效途径,数据扩充对于深度学习模型在时间序列数据上的成功应用至关重要。在本文中,我们系统地回顾了时间序列的不同数据增强方法。我们为所审查的方法提出了一个分类法,然后通过强调这些方法的优点和局限性,为这些方法提供了一个结构化的审查。我们还根据经验比较了不同任务的不同数据增强方法,包括时间序列分类、异常检测和预测。最后,我们讨论并强调了五个未来方向,以提供有用的研究指导。
(对于数据扩充毫无兴趣,手头处理过的时序数据基本没有什么小样本的问题,我主要对增强+对比感兴趣,不知道这里的增强方案能不能放到时序时序的对比学习里去)
深度学习在许多领域取得了显著的成功,包括计算机视觉(CV)、自然语言处理(NLP)和语音处理等。最近,它越来越多地被用于解决时间序列相关任务,包括时间序列分类[Fawaz等人,2019]、时间序列预测[Han等人,2019]和时间序列异常检测[Gamboa,2017]。深度学习的成功很大程度上依赖于大量的训练数据来避免过度拟合。不幸的是,许多时间序列任务没有足够的标记数据。作为一种提高训练数据规模和质量的有效工具,数据扩充对于深度学习模型的成功应用至关重要。数据扩充的基本思想是生成覆盖未探索输入空间的合成数据集,同时保持正确的标签(这个是比较麻烦的地方)。数据增强已在许多应用中显示出其有效性,例如AlexNet[Krizhevsky等人,2012]用于ImageNet分类。
然而,针对时间序列数据寻找更好的数据增强方法的研究较少。
在这里,我们强调了时间序列数据的数据增强方法所带来的一些挑战。
时间序列数据增强的难点
首先,当前的其它领域的数据增强方法没有充分利用时间序列数据的固有特性。时间序列数据的一个独特特性是所谓的时间相关性。与图像数据不同,时间序列数据可以被转换到时域(一般都在时域上)和频域上,并且可以在转换域中设计和实现有效的数据增强方法。
当我们对多变量时间序列进行建模时,这变得更加复杂,我们需要考虑这些变量在时间上的潜在复杂动态关联。
因此,简单地应用来自图像和语音处理的那些数据增强方法可能不会产生有效的合成数据。其次,数据扩充方法也依赖于任务。例如,适用于时间序列分类的数据增强方法可能对时间序列异常检测无效。此外,在许多时间序列分类问题中,数据扩充变得更为关键,因为在这些问题中,经常会观察到类不平衡。在这种情况下,如何有效地生成具有较少样本的标签的大量合成数据仍然是一个挑战。
不同于CV的数据扩充[Shorten和Khoshgoftaar,2019年]或演讲[Cui等人,2015年],就我们所知,时间序列的数据扩充尚未得到全面和系统的审查。与我们密切相关的一项工作是[Iwana和Uchida,2020],它对时间序列分类的现有数据增强方法进行了调查。然而,它没有审查其他常见任务的数据增强方法,如时间序列预测[Bandara等人,2020;Hu等人,2020年;Lee和Kim,2020]和异常检测[Lim等人,2018;Zhou等人,2019;Gao等人,2020]。此外,时间序列数据扩充的未来研究机会的潜在途径也缺失。
在本文中,我们旨在通过总结常见任务(包括时间序列预测、异常检测、分类)中现有的时间序列数据增强方法来填补上述空白,并提供有洞察力的未来方向。为此,我们提出了时间序列数据增强方法的分类,如图1所示。
基于分类,我们系统地回顾了这些数据增强方法。
时间序列数据增强的划分
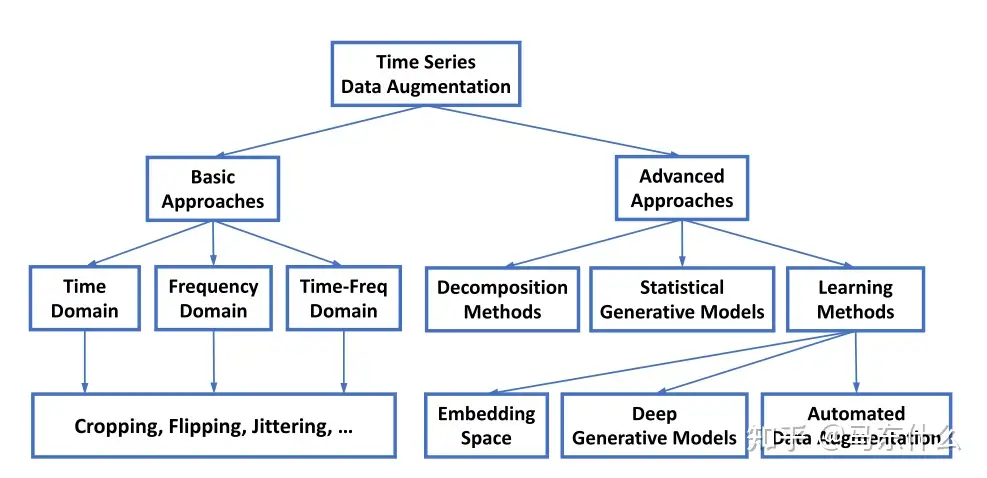
简单直接增强法
Time Domain
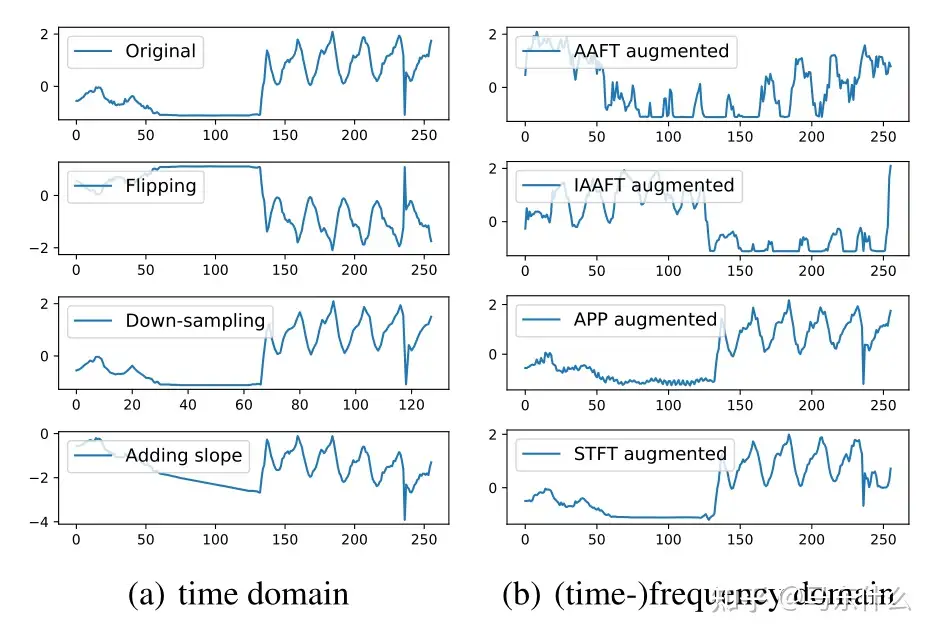
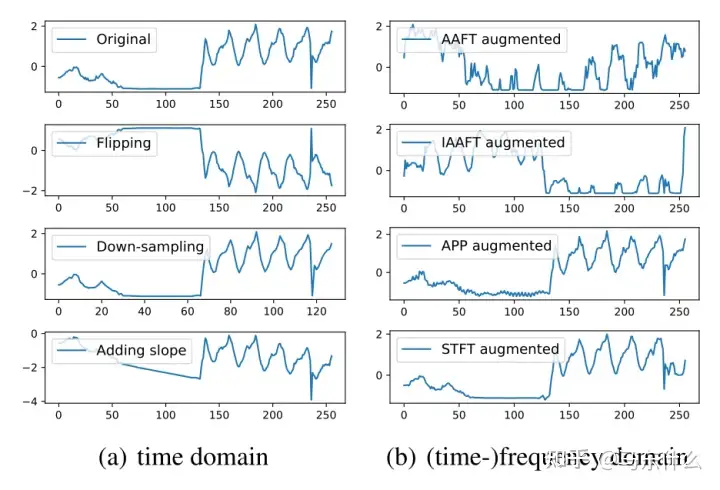
时域中的变换是时间序列数据最直接的数据扩充方法。它们中的大多数直接操纵原始输入时间序列,如注入高斯噪声或更复杂的噪声模式,如尖峰、阶梯状趋势和斜坡状趋势。除了这种简单的方法,我们还将讨论一种用于时间序列异常检测的特定数据增强方法,即时域中的标签扩展。
[Le Guennec等人,2016]中提到了窗口裁剪或切片。[Cui et al,2016]中介绍,窗口裁剪与CV区域的裁剪相似。这是一种从原始时间序列中随机提取连续切片的子采样方法。切片的长度是一个可调参数。对于分类问题,切片样本的标签与原始时间序列相同。在测试期间,使用多数投票对测试时间序列中的每个切片进行分类。对于异常检测问题,异常标签将与值序列一起切片。
窗口扭曲是时间序列的一种独特的增强方法。与动态时间扭曲(DTW)类似,该方法选择一个随机时间范围,然后压缩(下采样)或扩展(上采样)它,同时保持其他时间范围不变。窗口扭曲会改变原始时间序列的总长度,因此它应该与深度学习模型的窗口裁剪一起进行。该方法包含正常的下采样,在原始时间序列的整个长度上下采样。
翻转是另一种通过翻转原始时间序列x1,··,xN的符号生成新序列x01,···,x0N的方法,其中x0t=−xt中,这是基于假设我们在上下方向之间具有对称性,对于异常检测和分类,标签仍然相同(因为异常检测和分类关注的主要是shape)。
另一种有趣的扰动和基于系综的方法在[Fawaz等人,2018年]中介绍,该方法使用DTW生成新的时间序列,然后通过重心平均(DBA)算法的加权版本对其进行ensemble,它显示了一些UCR数据集中分类的改进。
噪声注入是一种在不改变相应标签的情况下将少量噪声/离群值注入时间序列的方法。这包括注入高斯噪声、尖峰、阶梯状趋势和斜坡状趋势等。对于尖峰,我们可以随机选择指数和方向,随机分配幅度,但受原始时间序列标准偏差的倍数限制。对于阶梯状趋势,它是从左指数到右指数的峰值的累积总和。
斜坡状趋势是将线性趋势添加到原始时间序列中。这些方案主要在[Wen和Keyes,2019]中提到
在时间序列异常检测中,异常通常在连续跨度内持续足够长的时间,因此起点和终点有时会“模糊”。因此,在时间距离和值距离方面接近标记异常的数据点很可能是异常。在这种情况下,建议使用标签扩展方法将这些数据点及其标签更改为异常(通过为其分配异常分数或切换其标签),这为时间序列异常检测带来了性能改进,如[Gao等人,2020]所示。
Frequency Domain
虽然大多数现有的数据增强方法都侧重于时域,但也有少数研究从时间序列的频域角度研究数据增强。
[Gao等人,2020]中的一项最新工作提出利用频域中振幅谱和相位谱中的扰动,通过卷积神经网络在时间序列异常检测中进行数据增强。具体而言,对于输入时间序列x1,··,xN,其通过傅里叶变换的频谱F(ωk)计算为:
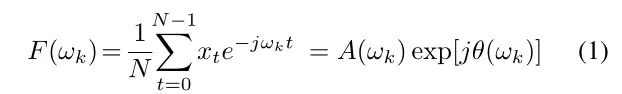
其中,ωk=2πk N是角频率,A(ωk)是振幅谱,θ(ωk)是相位谱。对于振幅谱A(ωk)中的扰动,通过考虑振幅谱中的原始均值和方差,将随机选择的段的振幅值替换为高斯噪声。而对于相位谱θ(ωk)中的扰动,随机选择段的相位值由相位谱中的额外零平均高斯噪声相加。基于振幅和相位扰动(APP)的数据增强与上述时域增强方法相结合时间序列异常检测的改进,如[Gao等人,2020]的实验所示
(这篇貌似写了挺多的东西的 Jingkun Gao, Xiaomin Song, Qingsong Wen,Pichao Wang, Liang Sun, and Huan Xu. Robusttad: Robust time series anomaly detection via decomposition and convolutional neural networks. MileTS’20: 6th KDD Workshop on Mining and Learning from Time Series, pages 1–6, 2020.)
[Lee等人,2019年]的另一项最新工作提出利用替代数据来改善深度神经网络中康复时间序列的分类性能。工作中采用了两种传统类型的替代时间序列:振幅调整傅里叶变换(AAFT)和迭代AAFT(IAAFT)[Schreiber和Schmitz,2000]。其主要思想是在傅里叶变换之后在相位谱中执行随机相位shuffle,然后在傅里叶逆变换之后执行时间序列的秩排序。从AAFT和IAAFT生成的时间序列可以近似地保留原始时间序列的时间相关性、功率谱和幅度分布。在[Lee等人,2019年]的实验中,作者通过AAFT和IAAFT方法将数据扩展10倍,然后扩展100倍,进行了两种类型的数据扩充,并证明了与没有数据扩充的原始时间序列相比,分类准确度有很大提高
Time-Frequency Domain
时频分析是一种广泛应用的时间序列分析技术,可以作为深度神经网络的一种适当的输入特征。然而,类似于频域的数据增强,只有少数研究考虑了时间序列的时频域数据增强。
【Steven Eyobu和Han,2018】中的作者采用短时傅里叶变换(STFT)为传感器时间序列生成时频特征,并通过深度LSTM神经网络对用于人类活动分类的时频特征进行数据增强。具体而言,提出了两种增强技术。一种是基于定义标准的局部平均,生成的特征附加在特征集的尾端。另一种方法是对特征向量进行shuffle,以在数据中产生变化。类似地,在语音时间序列中,最近提出SpecAugment[Park等人,2019]以Mel Frequency(基于语音时间序列STFT的时频表示)进行数据增强,其中增强方案包括扭曲特征、频率信道的mask block和时间步长的mask block。他们证明SpecAugment可以大大提高语音识别神经网络的性能,并获得最先进的结果。
为了说明,我们总结了图中时间、频率和时频域中的几种典型时间序列数据增强方法。
总结
复杂间接增强法
Decomposition-based Methods
基于分解的时间序列增强也已被采用,并在许多与时间序列相关的任务中显示出成功,例如预测和异常检测。常见的分解方法,如STL〔Cleveland等人,1990〕或RobustSTL〔Wen等人,2019b〕将时间序列xt分解为
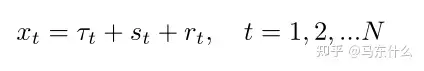
其中τt是趋势信号,st是季节性/周期性信号,rt表示残差信号。
在[Kegel等人,2018]中,作者讨论了生成新时间序列的分解方法。STL之后,它用确定性分量和随机分量重新组合新的时间序列。通过调整基础、趋势和季节性的权重来重建确定性部分。
随机部分是通过建立基于残差的复合统计模型(例如自回归模型)生成的。通过检查到其原始信号的基于特征的距离是否在一定范围内来验证求和生成的时间序列。同时,[Bergmeir等人,2016]中的作者提出在STL分解残差上应用boostrap来生成增强信号,然后将其与趋势和季节性相加,以组装新的时间序列。增强时间序列上的预测模型的集合始终优于原始预测模型,证明了基于分解的时间序列增强方法的有效性。
最近,在[Gao et al,2020]中,作者表明,与没有增强的相同方法相比,对使用稳健分解生成的分解残差应用时域和频域增强[Wen et al,2020;Wen et al.,2019a]可以帮助显著提高异常检测的性能。
Statistical Generative Models
基于统计生成模型的时间序列增强方法通常涉及使用统计模型对时间序列的动态进行建模。在[Cao等人,2014年]中,作者提出了一种称为高斯树混合的简约统计模型,用于建模多模态少数类时间序列数据,以解决不平衡分类问题,与不利用相邻点之间的时间序列相关性的现有过采样方法相比,该模型显示了优势。[Smyl和Kuber,2016]中的作者使用了通过称为LGT(局部和全局趋势)的统计算法计算的参数和预测路径的样本。最近,在[Kang等人,2020]中,研究人员使用混合自回归(MAR)模型来模拟时间序列集合,并调查时间序列特征空间中生成的时间序列的多样性和覆盖范围。
本质上,这些模型通过假设时间t的值取决于先前的点来描述时间序列的条件分布。一旦初始值被扰动,可以按照条件分布生成新的时间序列
Learning-based Methods
时间序列数据增强方法不仅能够生成不同的样本,而且能够模拟真实数据的特征。在本节中,我们总结了一些具有此类潜力的近期基于学习的方案。
Embedding Space
在[DeVries和Taylor,2017]中,提出了在学习嵌入空间(又名,潜在空间)中执行数据增强。它假设,由于特征空间中的流形展开,应用于编码输入而不是原始输入的简单变换将产生更合理的合成数据。注意,此框架中表示模型的选择是开放的,取决于特定的任务和数据类型。当时间序列数据被寻址时,在[DeVries和Taylor,2017]中选择序列自动编码器。具体而言,应用插值和外推来生成新样本。识别变换空间中具有相同标签的前k个最近标签。
然后,对于每对相邻样本,生成一个新样本,这是它们的线性组合。插值和外推的区别在于样本生成中的权重选择。如[DeVries和Taylor,2017]所示,该技术对时间序列分类特别有用。最近,在[Cheung and Yeung,2021]中提出了嵌入空间中的另一种数据增强方法,名为MODALS(Modalityagnostic Automated data augmentation in the Latent space)。MODALS方法不是训练自动编码器来学习潜在空间并生成额外的合成数据用于训练,而是联合潜在空间增强的不同组成来训练分类模型,并证明了这种方法在时间序列分类问题的优异性能。
Deep Generative Models
深度生成模型(DGM)最近被证明能够生成接近真实的高维数据对象,例如图像和序列。为序列数据(如音频和文本)开发的DGM通常可以扩展到时间序列数据模型。在DGM中,生成对抗网络(GAN)是生成合成样本并有效增加训练集的流行方法。尽管GAN框架在许多领域受到了极大的关注,但如何生成有效的时间序列数据仍然是一个具有挑战性的问题。在本小节中,我们简要回顾了最近关于时间序列数据增强的GAN的几项工作。
在[Eesteban等人,2017]中,提出了一种递归GAN(RGAN)和递归条件GAN(RCGAN)来生成真实的实值多维时间序列数据。
RGAN在生成器和鉴别器中采用RNN,而RCGAN采用基于辅助信息的两个RNN。除了RGAN和RCGAN在时间序列数据增强方面的理想性能外,差异隐私可以用于训练RCGAN,以获得更严格的隐私保障,如医学或其他敏感领域。
最近,[Y oon等人,2019]提出了TimeGAN,这是一种在各个领域生成真实时间序列数据的自然框架。TimeGAN是一个生成的时间序列模型,通过学习的嵌入空间进行对抗性和联合训练,具有监督和非监督损失。具体而言,引入逐步监督损失来学习数据中的逐步条件分布。它还引入了嵌入网络,以提供特征和潜在表示之间的可逆映射,从而降低对抗性学习空间的高维度。注意,通过联合训练嵌入网络和生成器网络来最小化监督损失。
Automated Data Augmentation
自动数据增强的思想是通过强化学习、元学习或进化搜索自动搜索最佳数据增强策略[Ratner等人,2017年;Cubuk等人,2019年;Zhang等人,2020年;Cheung和Y eung,2021]。[Ratner等人,2017]中的TANDA(用于数据增强的变换对抗网络)方案被设计为使用类GAN框架中的强化学习来训练特定变换函数上的生成序列模型,这在包括图像识别和自然语言理解任务在内的一系列应用中比常见的启发式数据增强方法产生了强大的增益。[Cubuk等人,2019]提出了一种名为AutoAugment的程序,以在强化学习框架中自动搜索改进的数据增强策略。它采用控制器RNN网络从搜索空间预测增强策略,并训练另一个网络以实现收敛精度。
然后,精度被用作奖励,以在下一次迭代中更新RNN控制器以获得更好的策略。实验结果表明,AutoAugment在广泛的数据集中显著提高了现代图像分类器的准确性。
对于时间序列数据增强,MODALS[Cheung and Yeung,2021]旨在使用基于人口增强(PBA)的进化搜索策略来寻找用于数据增强的潜在空间变换的最佳组合[Ho et al,2019],这证明了在连续和离散时间序列数据的分类问题上具有优异的性能。[Fons等人,2021]提出了另一项关于自动数据增强的最新工作,其中专门为时间序列数据设计了两种样本自适应自动加权方案:一种学习加权增强样本对损失的贡献,另一种基于预测训练损失的排名选择变换子集。这两种自适应策略都证明了对多个时间序列数据集中的分类问题的改进。
Preliminary Evaluation
在本节中,我们演示了三个常见时间序列任务的初步评估,以显示数据增强对性能改进的有效性。
Time Series Classification
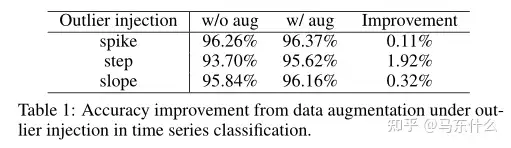
在这个实验中,我们比较了有和没有数据增强的分类性能。具体来说,我们从阿里云监控系统中收集了5000个时间序列,时间序列为一周,间隔为5分钟,带有二分类标签(季节性或非季节性)。数据被随机分成训练集和测试集,其中训练包含总样本的80%。我们训练一个完全卷积网络[Wang等人,2017],以对训练集中的每个时间序列进行分类。在我们的实验中,我们将不同类型的异常值(包括尖峰、阶跃和斜率)注入测试集,以评估训练分类器的鲁棒性。应用的数据扩充方法包括裁剪、扭曲和翻转。表1总结了当将不同类型的异常值注入测试集时,数据增加和不增加的精度。可以观察到,数据增加导致0.1%∼ 精度提高1.9%。
Time Series Anomaly Detection
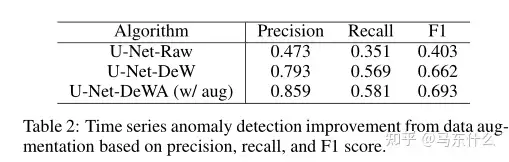
考虑到时间序列异常检测中的数据稀缺和数据不平衡的挑战,采用数据增强来生成更多标记数据是有益的。
我们简要总结了[Gao等人,2020]中的结果,其中基于U-Net的网络是在公共Y ahoo上设计和评估的!时间序列异常检测的数据集[Laptev等人,2015年]。表2总结了不同设置下的性能比较,包括将模型应用于原始数据(U-Net-raw)、分解残差(U-Net-DeW)和数据增强残差(U-Net-DeW A)。应用的数据增强方法包括翻转、裁剪、标签扩展和基于APP的频域增强。可以观察到,分解有助于F1分数的增加,数据的增加进一步提高了性能。
Time Series Forecasting
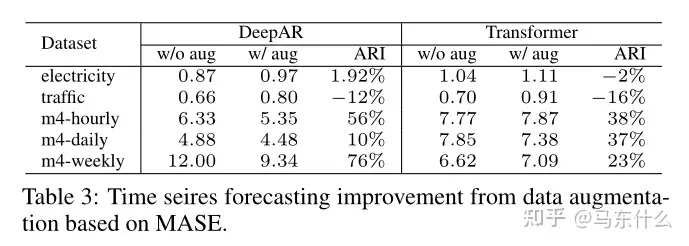
在本小节中,我们展示了两个流行的深度模型DeepAR中数据增强的实际效果[Salinas等人,2019]和Transformer[V aswani等人,2017]。
在表3中,我们报告了几个公共数据集上的平均绝对缩放误差(MASE)的性能改进:UCI学习库1和1中的电力和交通http://archive.ics.uci.edu/ml/datasets.php来自M4比赛的3个数据集2。我们考虑了基本的增强方法,包括裁剪、扭曲、翻转和基于APP的频域增强。在表3中,我们总结了没有增加的平均MASE,增加和平均相对改善(ARI),其计算为(MASEw/o aug)的平均值− MASEw aug)/MASEw aug.我们观察到,数据增强方法在平均意义上为所有模型带来了有希望的结果。然而,对于特定的数据/模型对,仍然可以观察到负面结果。作为未来的工作,它激励我们寻找先进的自动化数据增强策略,以稳定数据增强的影响,特别是时间序列预测。
Discussion for Future Opportunities
Augmentation in Time-Frequency Domain
如第2.3节所述,到目前为止,在时间-频率域中,基于STFT的时间序列数据增强方法研究有限。除了STFT,小波变换及其变体(包括连续小波变换(CWT)和离散小波变换(DWT))是表征时间序列时变特性的另一类自适应时频域分析方法。
与STFT相比,它们可以更有效和鲁棒地处理非平稳时间序列和非高斯噪声。
在许多小波变换变体中,最大重叠离散小波变换(MODWT)对于时间序列分析特别有吸引力【Percival and Walden,2000;Wen et al,2021】,因为具有以下优点:
1)与CWT相比,计算效率更高;
2) 处理任何时间序列长度的能力;
3) 与DWT相比,在更粗的尺度上提高了分辨率。
[Keylock,2006]中提出了基于MODWT的替代时间序列,其中通过将迭代幅度调整傅里叶变换(IAAFT)方案结合到每个级别的MODWT系数来设计小波迭代幅度调整傅立叶变换(WIAAFT)。与IAAFT不同的是,WIAAFT不假设有系统性,并且可以在时间演变方面大致保持原始数据的形状。除了WIAAFT之外,我们还可以将振幅谱和相位谱的扰动作为数据增强方案,在MODWT系数的每个级别上[Gao等人,2020]
研究如何利用不同的小波变换(CWT、DWT、MODWT等)在深度神经网络中进行有效的基于时频域的时间序列数据增强将是一个有趣的未来方向。
Augmentation for Imbalanced Class
在时间序列分类中,类不平衡现象非常频繁。解决不平衡分类问题的一种经典方法是作为合成少数群体过采样技术(SMOTE)对少数群体类进行过采样[Fernández等人,2018],以人为缓解不平衡。然而,这种过采样策略可能会改变原始数据的分布并导致过拟合。另一种方法是使用调整损失函数设计成本敏感模型[耿和罗,2018]。此外,[Gao等人,2020]在卷积神经网络的损失函数中设计了基于标签的权重和基于值的权重,其考虑了类别标签的权重调整和每个样本的邻域。因此,明确考虑了类不平衡和时间依赖。
同时对不平衡类进行数据扩充和加权将是一个有趣而有效的方向。最近的一项研究在CV和NLP领域调查了这一主题[Hu等人,2019],这显著改善了低数据状态和不平衡类别问题下的文本和图像分类。在未来,通过联合考虑时间序列数据中不平衡类的数据增强和加权来设计深度网络是很有意思的。
Augmentation Selection and Combination
给定图1中总结的不同数据增强方法,一个关键策略是如何选择和组合各种增强方法。
[Um等人,2017]中的实验表明,三种基本时域方法(排列、旋转和时间扭曲)的组合优于单一方法,并在时间序列分类中获得最佳性能。此外,[Rashid和Louis,2019]中的结果表明,当使用深度神经网络时,通过结合四种数据增强方法(即抖动、缩放、旋转和时间扭曲),时间序列分类任务的性能显著提高。然而,考虑到各种数据增强方法,直接组合不同的增强可能会产生大量数据,并且可能对性能改进无效。最近,RandAugment[Cubuk等人,2020]被提出作为图像分类和对象检测中增强组合的实用方法。对于每个随机生成的数据集,RandAugment仅基于两个可解释的超参数N(要组合的增强方法的数量)和M(所有增强方法的大小),其中每个增强都是从K=14个可用的增强方法中随机选择的。此外,这种随机组合的增强和简单的网格搜索可以用于基于强化学习的数据增强,如[Cubuk等人,2019],用于有效的空间搜索。
一个有趣的未来方向是如何设计适合深度学习中时间序列数据的有效增强选择和/或组合策略。针对时间序列优化的定制强化学习和元学习可能是潜在的方法。此外,算法效率是实践中的另一个重要考虑因素。
Augmentation with Gaussian Processes
高斯过程(GP)[Rasmussen和Williams,2005]是适用于时间序列分析的著名贝叶斯非参数模型[Roberts等人,2013]。从函数空间的观点来看,GP在函数上引起分布,即随机过程。时间序列可以被视为以时间为输入、以观察为输出的函数,因此可以用GP建模。A GP f(t)∼ GP(m(t),k(t,t0))由均值函数m(t,和协方差核函数k(t)表征。内核的选择允许对建模函数的一些一般性质进行假设,例如平滑度、尺度、周期性和噪声水平。核可以通过加法和乘法组合,从而产生组合函数特性,如伪周期性、可加分解性和变化点。GP通常应用于插值和外推任务,与时间序列分析中的插补和预测相对应。此外,深度高斯过程(DGPs)[Damianou和Lawrence,2013;Salimbni和Deisenroth,2017],这是一种更丰富的模型,具有GP的分层组成,在许多情况下往往显著超过标准(单层)GP,但尚未对时间序列进行充分研究。我们相信GP和DGP是未来的方向,因为它们允许通过内核设计对具有上述属性的时间序列进行采样,并通过利用其插值/外推能力从现有数据实例生成新的数据实例。
Augmentation with Deep Generative Models
当前用于时间序列数据扩充的DGM主要是GAN。然而,其他DGM在时间序列建模方面也有很大的潜力。例如,深度自回归网络(DARN)表现出对时间序列的自然拟合,因为它们以顺序方式生成数据,遵循物理时间序列数据生成过程的因果方向。Wavenet等DARN[Oord等人,2016年]和Transformer[V aswani等人,2017年]在时间序列预测任务中表现出了良好的性能[Androv等人,2020年]。另一个例子是标准化流(NFs)[Kobyzev等人,2020],其最近在建模时间序列随机过程方面取得了成功,在给定观测数据的情况下,具有出色的插值/外推性能[Deng等人,202]。最近,基于变分自动编码器(V AE)的数据增强[Fu等人,2020]被研究用于人类活动识别。
总之,除了常见的GAN架构之外,如何利用其他深度生成模型,如DARN、NF和VAE,这些模型在时间序列数据扩充方面的研究较少,仍然是令人兴奋的未来机会。
相关开源实现
本文对应的github repo,良心啊
https://github.com/uchidalab/time_series_augmentation
https://github.com/arundo/tsaug 对标nlpaug,真希望这些xx-aug 越多越好啊哈哈
tsai - Time Series Data Augmentation fastai还是一如既往的优秀!
https://github.com/sdv-dev/SDV SDV中设计了gan和vae这类比较advance的方法,对于tabular gan的功能相当出色~
https://github.com/zzw-zwzhang/awesome-of-time-series-augmentation?ref=https://githubhelp.com
汇总的awesome系列
https://github.com/makcedward/nlpaug nlpaug里关于音频的增强也可以无缝用在时间序列数据上
https://waterprogramming.wordpress.com/2021/11/29/data-augmentation-for-time-series-application/
总结
time series 通过符号近似可以转化为nlp,而通过格拉姆角场或递归图可以转化为picture,因此实际上nlp和cv中丰富的数据增强方法也是可以尝试放进来的尤其是 timeseries2picture,可以通过循环递归图将多变量时间序列转化到一张picture上,其实是有很多非常有意思的东西可以尝试的。
关于time series的转换,这两天写完发出来的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号