
2023牛客寒假算法基础集训营2
B.Tokitsukaze and a+b=n (medium) (求交集)
题目大意:
给定两个区间[l1,r1],[l2,r2],从两个区间各取一个数[a,b],求满足a+b == n的个数(a,b中只要一个不同就算不同的选法)
解题思路:
考虑第一个区间[l1,r1],如果从中选的a一定能产生答案,那么b一定属于区间p=[n-r1,n-l1]
再考虑给定的区间2[l2,r2],对 区间p,c求交集,就是答案的个数
举例:
n = 5
区间1:[2,4],区间2:[1,3]
p = [n-4,n-2] = [1,3]
p和区间2的交集为[1,3]所以答案为(3-1+1) = 3
代码实现:
代码
# include<bits/stdc++.h>
using namespace std;
# define int long long
const int N = 2e5+10;
void solve(){
int n;
cin>>n;
int l1,r1,l2,r2;
cin>>l1>>r1>>l2>>r2;
int r = min(n-l2,r1);
int l = max(n-r2,l1);
int ans = max(r-l+1,0ll);
cout<<ans<<endl;
}
signed main(){
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int __;
cin>>__;
while(__--) solve();
return 0;
}
C.Tokitsukaze and a+b=n (hard)(线段树优化B)
题目大意:
给定m个区间,从中选择两个区间i,j(i!=j),分别从中选一个数a,b。
只要i,j,a,b有一个不同,就算不同的选法,问满足a+b==n的选法个数
解题思路:
C的题目比较于B只多了m个区间中选2个区间,所以实际上判断a+b==n的方法仍然和之前相同,还是O(1)的去求交集。
因为是多个区间求交集,所以我们可以考虑每次取一个区间,然后考虑一个满足答案的区间p,求所有区间满足区间p的个数。这个时候我们可以可以把这个求所有区间满足区间p的个数的过程看作是对答案区间进行求和,比如p = [1,3],我们就是要看剩余m-1个区间有多少个区间可以在[1,3]内产生贡献,就是对区间[1,3]求和。
所以我们引入线段树来维护这个区间和。
--记得考虑因为i != j,所以每次要先将当前枚举的区间去掉,然后再求答案,求完答案以后原加回去
代码实现:
代码
# include<bits/stdc++.h>
using namespace std;
# define int long long
# define pii pair<int,int>
# define mk(a,b) make_pair(a,b)
# define fi first
# define se second
# define ls (u<<1)
# define rs (u<<1|1)
const int N = 4e5+10,mod = 998244353;
int n,m;
struct seg{
int sum[4*N];
int lazy[4*N];
void pushup(int u){
(sum[u] = sum[ls]+sum[rs])%=mod;
}
void build(int u,int l,int r){
}
void pushdown(int u,int l,int r){
int mid = (l+r)>>1;
if(lazy[u] == 0) return;
(sum[ls] += (mid-l+1)*lazy[u]+mod)%=mod;
(sum[rs] += (r-mid)*lazy[u]+mod)%=mod;
(lazy[ls] += lazy[u]+mod)%=mod;
(lazy[rs] += lazy[u]+mod)%=mod;
lazy[u] = 0;
}
void modify(int u,int l,int r,int L,int R,int c){
if(l>R||r<l) return;
if(l>=L&&r<=R){
(sum[u] += c*(r-l+1)+mod)%=mod;
(lazy[u] += c + mod)%=mod;
return;
}
pushdown(u,l,r);
int mid = (l+r)>>1;
if(mid>=L) modify(ls,l,mid,L,R,c);
if(mid<R) modify(rs,mid+1,r,L,R,c);
pushup(u);
}
int query(int u,int l,int r,int L,int R){
if(l>R||r<l) return 0;
if(l>=L&&r<=R){
return sum[u];
}
int mid = (l+r)>>1;
int res = 0;
pushdown(u,l,r);
if(mid>=L) (res+=query(ls,l,mid,L,R)+mod)%=mod;
if(mid<R) (res+= query(rs,mid+1,r,L,R)+mod)%=mod;
return res;
}
}tr;
signed main(){
cin>>n>>m;
vector<pii> v;
for(int i = 1;i <= m;++i){
int l,r;
cin>>l>>r;
tr.modify(1,1,n,l,r,1);
v.push_back(mk(l,r));
}
int ans = 0;
for(int i = 0;i < m;++i){
int l = v[i].fi,r = v[i].se;
int nowl = n-r,nowr = n-l;
if(nowr<nowl) swap(nowr,nowl);
tr.modify(1,1,n,l,r,-1);
nowl = max(0ll,nowl),nowr = max(0ll,nowr);
nowl = min(nowl,n),nowr = min(nowr,n);
(ans += tr.query(1,1,n,nowl,nowr))%=mod;
tr.modify(1,1,n,l,r,1);
}
cout<<ans<<endl;
return 0;
}
D.Tokitsukaze and Energy Tree(dfs+贪心)
题目大意:
给定n个节点的有根树(根为1),同时有n个能量果,第i个能量果的能量为v\(_i\),每次我们可以将一个能量果放在有根树的一个节点上,同时获得该节点及其子节点的能量总和。
求最后所能获得的最大能量总和。
解题思路:
手写一下样例我们其实可以发现,对于每一个节点的能量值的获取次数实际上与他的深度相关,比如样例中的节点4的深度为3,所以它的能量值被获取了三次(4,3,1)。
由此可以得到一种贪心的思想,对于节点深度越大的点就要放能量值越高的能量果。
所以我们先dfs求节点深度,然后分别对深度和能量果排序,最终\(\sum\)deep\(_i\)*v\(_i\)就是可以获得的最大能量值。
代码实现:
代码
#include<bits/stdc++.h>
using namespace std;
# define int long long
const int N= 2e5+10;
vector<int > e[N];
int deep[N];
void dfs(int u,int fa){
for(auto v:e[u]){
if(v == fa) continue;
deep[v] = deep[u]+1;
dfs(v,u);
}
}
int a[N];
signed main(){
int n;
cin>>n;
for(int i = 2;i <= n;++i){
int fa;
cin>>fa;
e[fa].push_back(i);
}
for(int i = 1;i <= n;++i) cin>>a[i];
deep[1] =1;
dfs(1,0);
sort(deep+1,deep+1+n);
sort(a+1,a+1+n);
int ans = 0;
for(int i = 1;i <= n;++i) ans += a[i]*deep[i];
cout<<ans<<endl;
return 0;
}
F.Tokitsukaze and Gold Coins (easy)(bfs/dp)
题目大意:
给定一个n*3的迷宫,其中有k个点不能进入,其余各个点上有一个金币。现在我们的主角在(1,1)点,他的目标为(n,3)点,他每次只能向右或者向下移动,即(x+1,y)||(x,y+1),当他到达终点时他可以选择结束游戏或者重新出现在(1,1)点。问主角最终所能获得的最大金币数量(到达终点时)。
解题思路:
一个很经典的模型,只有当从起点能够到达终点,并且反向从终点到达起点的路径点才是有效路径,所以只需要正反做两次bfs或者两次dp标记到达节点,最终只有同时有两个标记的点才是有效路径。
解释一下为什么不能单向bfs:
对于单向bfs扩展,因为每次是扩展一层的向右或者向下,很有可能在扩展的时候,有些点它最终不能到达终点,但是任然可以扩展到,例如:
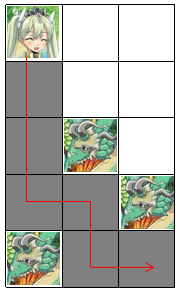
对于节点(1,2)、(1,3)、(2,2)、(2,3)、(3,3)如果只进行单向bfs他是可以扩展到的,但是他并不能到达终点,所以需要我们进行反向bfs将这一部分点剔除
代码实现:
代码
# include<bits/stdc++.h>
using namespace std;
# define int long long
const int N = 5e5+10;
int g[N][5];
int f[N][5];
int f2[N][5];
void solve(){
int n,k;
cin>>n>>k;
for(int i = 0;i <= n+1;++i){
for(int j = 0;j <= 4;++j){
g[i][j] = f[i][j] = f2[i][j] = 0;
}
}
for(int i = 1;i <= k;++i){
int x,y;
cin>>x>>y;
g[x][y]^=1;
}
f[1][1] = 1;
f2[n][3] = 1;
for(int i = 1;i <= n;++i){
for(int j = 1;j<=3;++j){
if(!g[i][j])
f[i][j] |= (f[i-1][j]|f[i][j-1]);
}
}
for(int i = n;i >=1;--i){
for(int j = 3;j >=1;--j){
if(!g[i][j]){
f2[i][j]|=f2[i+1][j]|f2[i][j+1];
}
}
}
int ans = 0;
for(int i = 1;i <= n;++i){
for(int j = 1;j <= 3;++j){
ans += (f[i][j]&&f2[i][j]);
}
}
cout<<max(ans-1,0ll)<<endl;
}
signed main(){
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int __;
cin>>__;
while(__--) solve();
return 0;
}
H.Tokitsukaze and K-Sequence(求解每一部分的贡献(前缀和+二分优化))
题目大意:
给定一个长度为n的整形序列,将其分为k个非空子序列,我们定义一个非空子序列的价值为只出现一次的数的个数。(子序列不一定连续),求将序列分为k = 1....n个非空子序列之后,子序列的价值之和最大为多少。
解题思路:
由于子序列不一定连续,所以我们首先想到的是先统计每个数出现的次数,统计完以后就形成了一个新的数组b表示每个数出现的次数。经过手动模拟几次样例以后我们发现,对于k如果我们的b\(_i\)小于等于k我们一定可以将其完全分配到k个子序列中,所以他的贡献就是b\(_i\)。如果b\(_i\)大于k,我们可以考虑在k-1个子序列中只放一个,其余的全放在最后一个序列中,所以它的贡献就为k-1。
总结一下:
- b\(_i\)<=k, ans+=b\(_i\)
- b\(_i\) > k , ans+=k-1
在考虑完规律之后我们其实对于k只需要每次找到最后一个b\(_i\)<=k,剩余的贡献就是(n-i)*(k-1),而之前的贡献我们就可以用前缀和提前算出,所以对于k,ans = pre[i]+(n-i)*(k-1)
代码实现:
代码
# include<bits/stdc++.h>
using namespace std;
# define int long long
# define endl "\n"
const int N = 1e5+10;
int a[N],b[N];
int cnt[N];
int pre[N];
void solve(){
for(int i = 1; i <= 100000; i ++)
cnt[i] = 0;
int n;
cin>>n;
for(int i = 1;i <= n;++i){
int x;
cin>>x;
a[i] = x;
b[i] =a[i];
}
sort(b+1,b+1+n);
int nn = unique(b+1,b+1+n)-b-1;
for(int i = 1;i <= n;++i){
cnt[lower_bound(b+1,b+1+nn,a[i])-b]++;
}
sort(cnt+1,cnt+nn+1);
for(int i = 1;i <= nn;++i)
pre[i] = pre[i-1]+cnt[i];
for(int i = 1;i <= n;++i){
int ans = 0;
int l = 1,r = nn;
int now = 0;
while(l<=r){
int mid = (l+r)>>1;
if(cnt[mid]<=i){
l = mid+1;
now = mid;
}
else r = mid-1;
}
if(i == 1) cout<<pre[now]<<endl;
else{
ans = pre[now] +(i-1)*(nn-now);
cout<<ans<<endl;
}
}
}
signed main(){
int tt;
cin>>tt;
while(tt--) solve();
return 0;
}
J.Tokitsukaze and Sum of MxAb(找规律算贡献)
题目大意:
给定一个长度为n的序列a,定义Mxab(i,j) = max(|a\(_i\)+a\(_j\)|,|a\(_i\)-a\(_j\)|),
求\(\sum_{i = 1}^n\)\(\sum_{j = 1}^n\)Mxab(i,j)
解题思路:
随便推两个例子就发现,这是个诈骗题,对于每个值他对于答案的最终贡献为2*n*(abs(a\(_i\)))
所以最终 ans = \(\sum_{i=1}^n\) 2*n*(abs(a\(_i\)))
代码实现:
代码
# include<bits/stdc++.h>
using namespace std;
# define int long long
const int N = 2e5+10;
int a[N];
void solve(){
int n;
cin>>n;
for(int i = 1;i <= n;++i) cin>>a[i],a[i] = abs(a[i]);
int ans = 0;
for(int i = 1;i <= n;++i){
ans += 2*n*a[i];
}
cout<<ans<<endl;
}
signed main(){
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int __;
cin>>__;
while(__--) solve();
return 0;
}
L.Tokitsukaze and Three Integers(预处理求贡献)
题目大意:
给定一个长度为n的序列和一个整数p,对于所有x = 0,1,...,p-1,求三元组[i,j,k]满足
- i!=j!=k
- (a\(_i\)*a\(_j\)+a\(_k\)) = x(mod p)
的数量。
解题思路:
我们考虑(a\(_i\)*a\(_j\)+a\(_k\)) = x(mod p)这个式子,明显a\(_i\)*a\(_j\)这一部分我们可以看作一个部分处理出来,然后再反过来从x-a\(_k\) = a\(_i\)*a\(_j\)(mod p)的角度考虑满足条件的三元组个数。
我们先将每一个数出现的次数处理出来-cnt[i]
首先先处理a\(_i\)*a\(_j\)这一部分,这一部分的贡献有两种可能,如果a\(_i\)==a\(_j\),那么他对于a\(_i\)*a\(_j\)的贡献就是cnt[i]*(cnt[i]-1),否则就是cnt[i]*cnt[j]。这可以看作组合数学嘛:
- a\(_i\)==a\(_j\): ans = C(cnt[a\(_i\)],1)*C(cnt[a\(_i\)]-1,1)
- a\(_i\) !=a\(_j\): ans = C(cnt[a\(_i\)],1)*C(cnt[a\(_j\)],1)
最终我们处理出来所有的s[a\(_i\)*a\(_j\)]的贡献
然后处理k,因为要考虑i!=j!=k,在处理i*j的时候已经处理过i!=j,现在要确保k!=i,k!=j,所以我们还需要存储当now = i*j时,因子为i||j的贡献以便于后续当i == k || j == k时将这一部分去掉,所以我们需要另外维护一个mp[now][i],mp[now][j]表示当乘积为now时,其中一个因子为i所做的贡献
最后遍历x:[0 ~ p-1],k:[0 ~ p-1],考虑now = (x-k+p)%p,此时它对于答案的贡献为k出现的次数*s[now]再减去当now中有因子为k时的贡献,即:ans += cnt[k]*s[now],ans -= mp[now][k]
代码实现:
代码
# include<bits/stdc++.h>
using namespace std;
# define int long long
const int N = 5050;
int cnt[N];
int s[N];
int mp[N][N];
signed main(){
int n,p;
cin>>n>>p;
for(int i = 1;i <= n;++i){
int x;
cin>>x;
cnt[x%p] ++;
}
for(int i = 0;i<p;++i){
for(int j = 0;j<p;++j){
int t;
if(i == j){
t = cnt[i]*(cnt[i]-1);
}
else t = cnt[i]*cnt[j];
int now = (i*j+p)%p;
s[now] += t;
if(t) mp[now][i]+=t,mp[now][j]+=t;
}
}
for(int x = 0;x < p;++x){
int ans = 0;
for(int k = 0;k< p;++k){
int now = (x-k+p)%p;
ans += cnt[k]*s[now];
ans -= mp[now][k];
}
cout<<ans<<" ";
}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号