北航操作系统lab5实验报告
实验思考题
Thinking 5.1
查阅资料,了解 Linux/Unix 的 /proc 文件系统是什么?有什么作用? Windows 操作系统又是如何实现这些功能的?proc 文件系统这样的设计有什么好处和可以改进的地方?
/proc文件系统是一个虚拟文件系统,只存在于内存中,而不占用外存空间。它提供了新的一种在用户空间和内核空间中进行通信的模式。用户和应用程序可以通过proc得到系统的信息,并可以改变内核的某些参数,这个过程是动态的,随着内核参数的改变而改变。用户可以获取内核信息。
Win32 API是Windows操作系统内核与应用程序之间的界面,它将内核提供的功能进行函数包装,应用程序通过调用相关函数而获得相应的系统功能,相关函数接着调用系统服务接口,最后由系统服务接口调用内核模式中的服务例程。
通过对文件系统的操作进行用户空间与内核空间的通信,更加方便快捷,不用像系统调用一样再陷入内核态。但访问的容易必将带来安全性的隐患,可能会对一些危险操作不设防吧?需要进一步判断改进。
Thinking 5.2
如果我们通过 kseg0 读写设备,我们对于设备的写入会缓存到 Cache 中。通过 kseg0 访问设备是一种错误的行为,在实际编写代码的时候这么做会引发不可预知的问题。请你思考:这么做这会引起什么问题?对于不同种类的设备(如我们提到的串口设备和 IDE 磁盘)的操作会有差异吗?可以从缓存的性质和缓存刷新的策略来考虑。
首先,kseg0中存放有与lab 1—4相关的几乎所有内核函数与数据。将设备的写入地址放入kseg0中可能会使得其地址与内核代码产生冲突。
kseg0采用cache进行读取,对于强实时交互的外设而言,cache缺失可能会大大增加与外设通信的时间,我们需要一个固定的,易访问的地址来进行与外设的操作。
Thinking 5.3
比较 MOS 操作系统的文件控制块和 Unix/Linux 操作系统的 inode 及相关概念,试述二者的不同之处。
struct inode_operations {
int (*create) (struct inode *,struct dentry *,int);
struct dentry * (*lookup) (struct inode *,struct dentry *);
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*unlink) (struct inode *,struct dentry *);
int (*symlink) (struct inode *,struct dentry *,const char *);
...
};
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char *, size_t, loff_t *);
...
};
struct inode {
...
unsigned long i_ino;
atomic_t i_count;
kdev_t i_dev;
umode_t i_mode;
nlink_t i_nlink;
uid_t i_uid;
gid_t i_gid;
kdev_t i_rdev;
loff_t i_size;
time_t i_atime;
time_t i_mtime;
time_t i_ctime;
...
struct inode_operations *i_op;
struct file_operations *i_fop;
struct super_block *i_sb;
...
};Linux系统下FCB储存了文件的所有信息,但索引结点下的FCB 进行了改进,除了文件名之外的文件描述信息都放到索引节点里,这样一来该结构体大小就可以匹配磁盘块的大小,大大提升文件检索速度。如此一来inode模块则封装了很多东西,我们应该重点关注 i_op 和 i_fop 这两个成员。i_op 成员定义对目录相关的操作方法列表,譬如 mkdir()系统调用会触发 inode->i_op->mkdir() 方法,而 link() 系统调用会触发 inode->i_op->link() 方法。而 i_fop 成员则定义了对打开文件后对文件的操作方法列表,譬如 read() 系统调用会触发 inode->i_fop->read() 方法,而 write() 系统调用会触发 inode->i_fop->write() 方法。
struct File {
u_char f_name[MAXNAMELEN]; // filename
u_int f_size; // file size in bytes
u_int f_type; // file type
u_int f_direct[NDIRECT];
u_int f_indirect;
struct File *f_dir;
// the pointer to the dir where this file is in, valid only in memory.
u_char f_pad[BY2FILE - MAXNAMELEN - 4 - 4 - NDIRECT * 4 - 4 - 4];
};
// file descriptor + file
struct Filefd {
struct Fd f_fd;
u_int f_fileid;
struct File f_file;
};
// file descriptor
struct Fd {
u_int fd_dev_id;
u_int fd_offset;
u_int fd_omode;
};
struct Dev {
int dev_id;
char *dev_name;
int (*dev_read)(struct Fd *, void *, u_int, u_int);
int (*dev_write)(struct Fd *, const void *, u_int, u_int);
int (*dev_close)(struct Fd *);
int (*dev_stat)(struct Fd *, struct Stat *);
int (*dev_seek)(struct Fd *, u_int);
};我们实验所编写的MOS文件控制块不是叫的FCB,而是File,对文件进行操作的函数却全都实现在了Dev结构体的接口里。此外我们对文件的操作是依靠进程间通信来完成的,而Linux是直接系统调用完成的。总的来说我们的MOS文件系统性能变低了,但用户空间实现使得可靠性变高了。
Thinking 5.4
查找代码中的相关定义,试回答一个磁盘块中最多能存储多少个文件 控制块?一个目录下最多能有多少个文件?我们的文件系统支持的单个文件最大为多大?
一个磁盘块中有FILE2BLK = 16个文件控制块。一个目录最多指向1024个磁盘块,因此一共目录中最多1024*16=16384个子文件。
Thinking 5.5
请思考,在满足磁盘块缓存的设计的前提下,我们实验使用的内核支持的最大磁盘大小是多少?
应该就是缓存块大小吧,1个G。
Thinking 5.6
如果将 DISKMAX 改成 0xC0000000, 超过用户空间,我们的文件系统还能正常工作吗?为什么?
不能,因为这样的话用户可以直接修改内核空间,内核都没了文件系统将何去何从呢。
Thinking 5.7
在 lab5 中,fs/fs.h、include/fs.h 等文件中出现了许多宏定义,试列举你认为较为重要的宏定义,并进行解释,写出其主要应用之处。
#define BY2SECT 512 /* Bytes per disk sector */
#define SECT2BLK (BY2BLK/BY2SECT) /* sectors to a block */
/* Disk block n, when in memory, is mapped into the file system
* server's address space at DISKMAP+(n*BY2BLK). */
#define DISKMAP 0x10000000
/* Maximum disk size we can handle (1GB) */
#define DISKMAX 0x40000000
#define BY2BLK BY2PG
// Maximum size of a filename (a single path component), including null
#define MAXNAMELEN 128
struct File {
u_char f_name[MAXNAMELEN]; // filename
u_int f_size; // file size in bytes
u_int f_type; // file type
u_int f_direct[NDIRECT];
u_int f_indirect;
struct File *f_dir; // the pointer to the dir where this file is in, valid only in memory.
u_char f_pad[BY2FILE - MAXNAMELEN - 4 - 4 - NDIRECT * 4 - 4 - 4];
};
// File types
#define FTYPE_REG 0 // Regular file
#define FTYPE_DIR 1 // Directory从上到下依次是1个扇区大小512字节,1个磁盘块是8个扇区,缓冲区地址范围为0x10000000--0x3ffffffff,一个磁盘块大小等于一个页面大小(4KB),文件名最长为128个char,File结构体用于索引,文件类型为文件或文件夹。
前面的宏主要用于内存分配,后面的宏主要用于用户操作。
Thinking 5.8
阅读 user/file.c ,你会发现很多函数中都会将一个 struct Fd * 型的指针转换为 struct Filefd * 型的指针,请解释为什么这样的转换可行。
为了降低文件控制块的复杂度,把结构体下方给下一级的结构体,在这些结构体的定义中会发现Filefd结构体的第一个元素就是Fd结构体,c语言很能容忍强制转换操作,写代码的时候经常把一个void*指针变来变去的。因此直接执行下述代码没有任何问题。
struct Fd *fd;
struct Filefd ffd = (struct Filefd *)fd;Thinking 5.9
在 lab4 的实验中我们实现了极为重要的 fork 函数。那么 fork 前后的父子进程是否会共享文件描述符和定位指针呢?请在完成上述练习的基础上编写一个程序进行验证。
文件描述符和定位指针均在用户空间实现,所以fork前后的父子进程会共享这些文件相关结构体。

Thinking 5.10
请解释 Fd, Filefd, Open 结构体及其各个域的作用。比如各个结构体会在哪些过程中被使用,是否对应磁盘上的物理实体还是单纯的内存数据等。说明形式自定,要求简洁明了,可大致勾勒出文件系统数据结构与物理实体的对应关系与设计框架。
-
struct Fd
为文件描述符结构体,其中:
-
u_int fd_dev_id;:外设id。 -
u_int fd_offset;:读写的当前位置(偏移量),在fseek中用得到。 -
u_int fd_omode;:文件打开方式,如只读,只写等。
-
-
struct Filefd
为记录文件详细信息的结构体,其中:
-
struct Fd f_fd;:即文件描述符。 -
u_int f_fileid;:文件的id。 -
struct File f_file;:对应的文件系统控制块
-
-
struct Open
用于抽象化记录打开文件这一行为,其中:
-
struct File *o_file;:指针,值向具体的file结构体。 -
u_int o_fileid;:文件的id。 -
int o_mode;:文件打开方式,指只读,只写等。 -
struct Filefd *o_ff;:打开位置的偏移量。
-
Thinking 5.11
上图中有多种不同形式的箭头,请结合 UML 时序图的规范,解释这些不同箭头的差别,并思考我们的操作系统是如何实现对应类型的进程间通信的。
同步消息,用黑三角箭头搭配黑实线表示。同步的意义:消息的发送者把进程控制传递给消息的接收者,然后暂停活动,等待消息接收者的回应消息。
返回消息,用开三角箭头搭配黑色虚线表示。返回消息和同步消息结合使用,因为异步消息不进行等待,所以不需要知道返回值。
static int
fsipc(u_int type, void *fsreq, u_int dstva, u_int *perm)
{
u_int whom;
// NOTEICE: Our file system no.1 process!
ipc_send(envs[1].env_id, type, (u_int)fsreq, PTE_V | PTE_R);
return ipc_recv(&whom, dstva, perm);
}执行open指令时会调用上述这个函数,以该函数为例,其结构简单易于分析。若ipc_send实现了lab4 中 Extra的代码,则会在消息的接收者无法接收消息时等待,而ipc_recv也会在未接收到消息时等待,如此实现同步消息的控制。
Thinking 5.12
阅读serv.c/serve函数的代码,我们注意到函数中包含了一个死循环for (;;) {...},为什么这段代码不会导致整个内核进入 panic 状态?
该函数中有一步为req = ipc_recv(&whom, REQVA, &perm);它保证了在没有文件请求时,文件系统进程会一直等待下去,所以不会进入panic状态,而且我们也需要这个文件系统进程一直循环下去
实验难点展示
磁盘驱动程序
ide_write、ide_read这两个函数如何映射和如何正确读写是一个难点。
通过对特定地址写入特定值来完成操作系统与磁盘的联系十分巧妙,之前实现的putcharc函数与计时器触发中断也是如此设计,需要注意的一点是syscall_write_dev((int)&tmp, 0x13000020, 4)这个步骤,只有向这个地址写入1或0才会读写磁盘,如果直接读写映射的缓存区地址的数据则根本不会对磁盘本身产生任何操作。
在lab 5-1-Extra中,实现了raid4磁盘阵列的读写。第一个难点是需要考虑如何对整个地址做异或操作,第二个难点是如何通过冗余的5号磁盘获取正常的数据。
void xorf(void *dst,void *src) {
char *s1 = (char *) dst;
char *s2 = (char *) src;
int i = 0;
while (i < 512) {
*(s1 + i) = (~*(s1 + i) & *(s2 + i)) | (*(s1 + i) & ~*(s2 + i));
i++;
}
}
int ifEqual(void *s,void *t) {
char *s1 = (char *) s;
char *s2 = (char *) t;
int i = 0;
while (i < 512) {
if (*(s1 + i) != *(s2 + i))
return 0;
i++;
}
return 1;
}异或的等价操作是(a&~b)|(~a&b),而最后检验数据是否一致则需要将4个磁盘异或后的数据与5号磁盘作比较。由于是在函数内声明的局部变量数组,故需要用user_bcopy清零。
最难的是读磁盘的操作,首先要知道哪些磁盘损坏,然后需要先把磁盘里的数据全部读出来(只有这样才能进行异或和比较操作),最后才是把正确的数据放到对应的地址上。
文件系统结构
文件系统部分概念太多,而结构体的定义更是数不清。
除开已经分析过的Fd, Filefd, Open块外,Block 结构体是磁盘块,Super结构体是超级块,File结构体是文件控制块,Dev结构体是磁盘操作控制块。
文件系统操作
请求的发送由file/fsipc.c函数fsipc实现,包含有以下操作:
#define FSREQ_OPEN 1
#define FSREQ_MAP 2
#define FSREQ_SET_SIZE 3
#define FSREQ_CLOSE 4
#define FSREQ_DIRTY 5
#define FSREQ_REMOVE 6
#define FSREQ_SYNC 7以open操作为例,流程图如下,红色部分为用户请求文件操作进程,蓝色部分为文件系统进程响应部分。
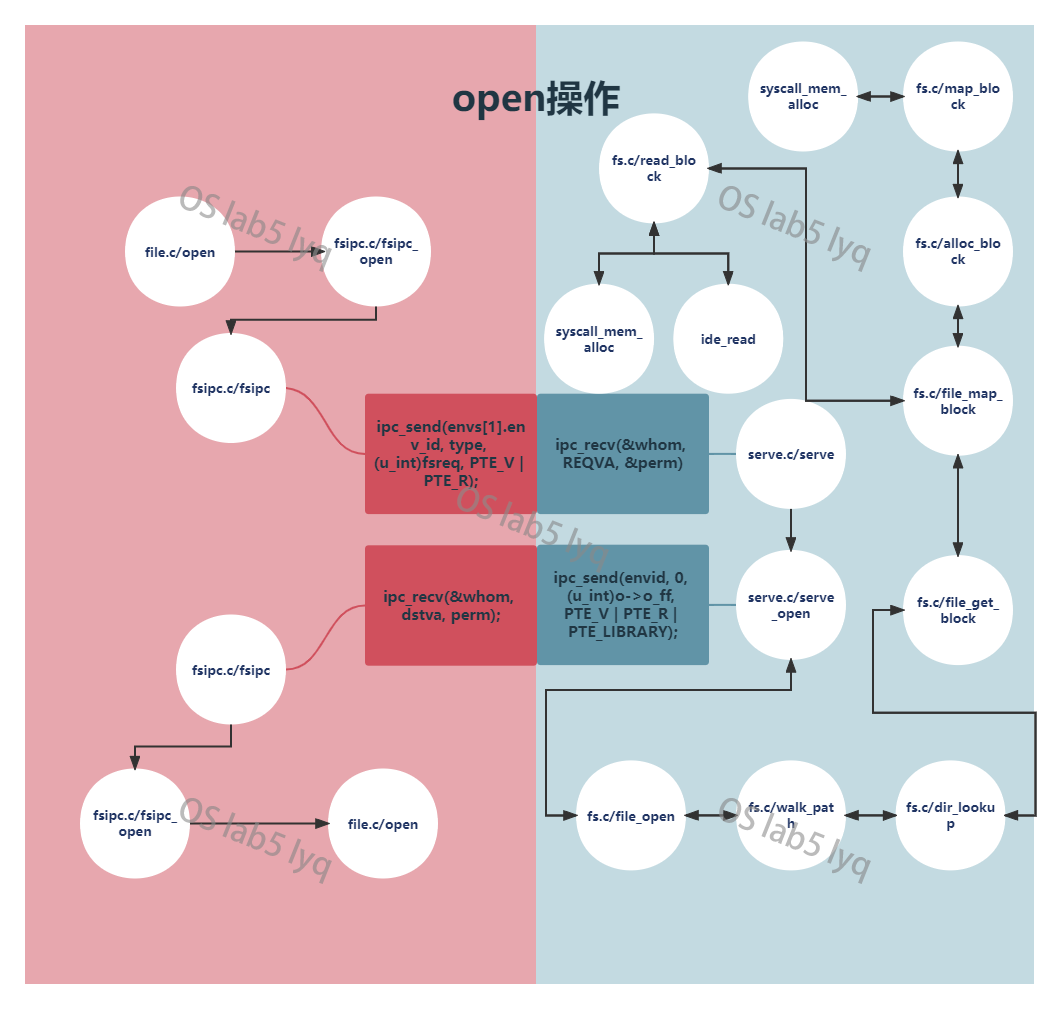
而读写文件操作不在上述7种定义的操作中,如file_read,file_write函数,它们不通过系统调用实现。
本次lab大概是看代码最痛苦的一个lab,5-1还算和平,5-2也挺核平。就单纯fs/fs.c这一个文件就有八百多行的代码,而不同函数又会相互调用,彼此的调用关系从上图就可以看出是十分的混乱。
nbitblock = (NBLOCK + BIT2BLK - 1) / BIT2BLK;,这是用于计算表示磁盘块空闲状态所需要的磁盘块的式子,想了很久不明白如何得出这式子,然后有人告诉我这其实就相当于(NBLOCK - 1) / BIT2BLK向上取整。。。
其实真正难理解的还是文件系统进程部分的代码,在我看来其实不需要真的去看那些代码,只需要知道用户进程在IPC中传入了什么,得到了什么即可。指导书里只是对大体的方向进行了介绍,对具体实现之处写的并不详细,感觉细看代码十分难受。
残留难点
针对Block这个结构体,为什么需要这1024个Block表示1024个磁盘块呢,需要的时候难道不可以直接从磁盘里读吗?若是磁盘更大一点,那么这些结构体无疑会占用更多的空间。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)