作业 4:词频统计——基本功能
一、基本信息
1.1 本次作业的地址:https://edu.cnblogs.com/campus/ntu/Embedded_Application/homework/2088
1.2 项目 Git地址:https://gitee.com/ntucs/PairProg.git
1.3 结对成员:唐庆阳 1613072009
戴俊明 1613072010
二、项目分析
2.1 程序运行模块
2.1.1 这个函数里的循环为了计算确切行数,去掉了空行最后返回一个总的文本字符串。
def process_file(path, files):
try:
with open(path, 'r', encoding='gbk') as file:
text = file.read()
count = 0
# 下面的循环为了计算行数
for word in text.splitlines():
if (word):
count += 1
print("lines:", count, file=files)#在所有需要的print参数里加入文件参数file,将输出结果添加到指定文件里
except IOError:
print("Read File Error!")
return None
return text
2.1.2 对单词和词组进行序列化
任务一:单词
生成一个键为单个单词,值为该单词出现次数的字典。
def process_buffer(textString, file):
"""当只统计单词时(num == 1),生成<str,int>形式的键值对,
当统计短语时,生成字典套字典的形式,具体参考sample.json文件"""
import re
if textString:
word_freq = {}
word_prelist = re.sub('(?!\’)\W', ' ', textString)
word_list = re.sub('\s[\’]', ' ', word_prelist).lower().split()
wordlength = word_list.__len__()
print("words:", wordlength, file=file);
#从stop_words.txt里图提取所有停止词,并进行过滤
with open('stop_words.txt', 'r', encoding='gbk') as file:
text = file.read().split()
for word in word_list:
if word in text:
continue
if word in word_freq:
word_freq[word] += 1
else:
word_freq[word] = 1
return word_freq
任务二:多个单词组成的词组
生成一个森林,具体数据结构参考:对英文文档中的单词与词组进行频率统计
#对词组进行统计,num为自促所包含的单词数目
def process_wordgroupcount(textString, num):
import re
if textString:
word_freq = {}
word_prelist = re.sub('(?!\’)\W', ' ', textString)
word_list = re.sub('\s[\’]', ' ', word_prelist).lower().split()
count = len(word_list)
i = 0
while i < count: # 因为需要用到索引遍历列表,只能使用while来遍历列表
finish = i
start = i - num + 1 # num表示词组的单词个数限制,start表示以该单词作为词组结尾的第一个单词的索引
if start < 0:
start = 0 # 处理开始时索引前面没有单词的特殊情况
index = i
while index >= start: # 做num次建立节点
if word_list[i] in get_dict_value(word_freq, word_list[index: finish]).keys():
get_dict_value(word_freq, word_list[index: finish])[word_list[i]]['Value'] += 1
else:
get_dict_value(word_freq, word_list[index: finish]).update({word_list[i]: {'Value': 1}})
index -= 1
i += 1
return word_freq
注:并没有使用nltk的语料库,仅仅使用一个列表作为停词表。停词表来自名为stop_words.txt的文本文件。该文本文件中包含几乎所有英文文档中的停词
2.1.3 字典格式化
数据已经存储到了森林中,接下来就是如何把森林格式化成普通的字典。
相比深度优先遍历,选择的是更易理解与实现的广度优先遍历。
def format_dict(word_freq={}):
"""对统计短语的情况生成的复杂字典进行格式化,格式化后的形式为<str,int>"""
formated_word_freq = {}
phrases = []
for word in word_freq.keys():
phrases.append(word)
index = 0
while phrases[index] != phrases[-1]:
phrase = phrases[index]
if len(get_dict_value(word_freq, phrase)) == 1 and type(phrase).__name__ == 'list':
formated_word_freq[' '.join(phrase)] = get_dict_value(word_freq, phrase)['Value']
else:
for next_word in get_dict_value(word_freq, phrase):
temp = []
if type(phrase).__name__ == 'str':
temp.append(phrase)
else:
temp.extend(phrase)
if next_word != 'Value':
temp.append(next_word)
phrases.append(temp)
index += 1
if len(get_dict_value(word_freq, phrases[-1])) == 1 and type(phrases[-1]).__name__ == 'list':
formated_word_freq[' '.join(phrases[-1])] = get_dict_value(word_freq, phrases[-1])['Value']
# print(formated_word_freq)
return formated_word_freq
2.1.4 对单词出现次数进行排序输出。
def output_result(word_freq, file):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
for item in sorted_word_freq[:10]:
print("<", item[0], ">:", item[1], file=file)
2.1.5 主函数
进行函数参数设置和判定字母数量并把输出结构存到result.txt文件。
将词组里的单词的数量作为参数之一。
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('path') #将path作为目录加入命令行参数
parser.add_argument('num',nargs='?')#将num作为一个可空的参数,当num为空时args.num为None
args = parser.parse_args()
path = args.path
if args.num == None:
num = 1
else:
num = int(args.num)
file = open('result.txt', 'w+')
buffer = process_file(path, file)
if buffer:
word_freq = process_buffer(buffer, file)
output_result(word_freq, file)
if num != 1:
word_freq = process_wordgroupcount(buffer, num)
word_freq = format_dict(word_freq)
output_result(word_freq, file)
file.close()
2.2 程序算法的时间、空间复杂度分析
2.2.1 单词
对文本单词列表进行遍历放入字典中,时间复杂度为O(n),空间复杂度为O(n)。
2.2.2 词组
由于要构建森林,在对单词列表进行遍历时,要对森林的每一层查找该单词,其时间复杂度为O(n^m)(m为词组的单词个数)。又因为使用森林存储单词,其空间复杂度为O(logmn)。
2.3 程序运行案例截图
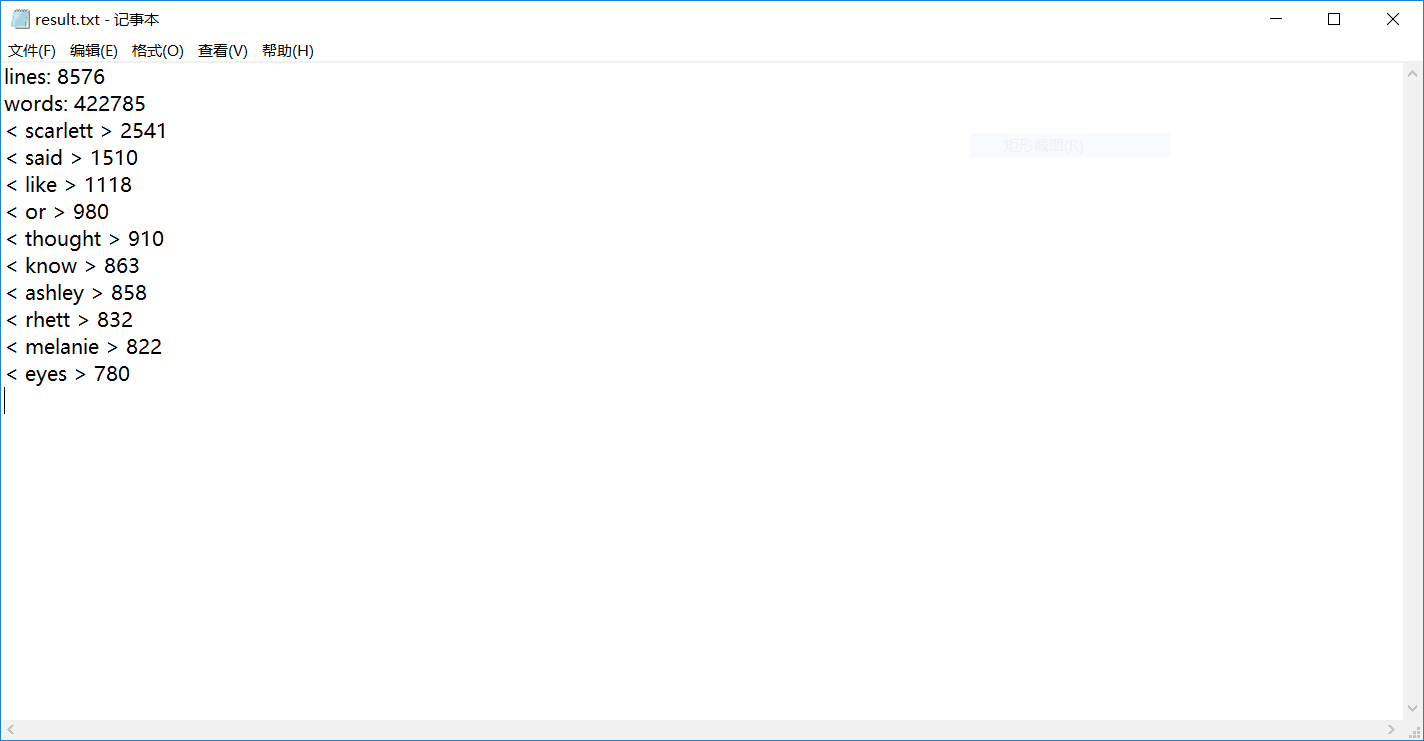
三、性能分析
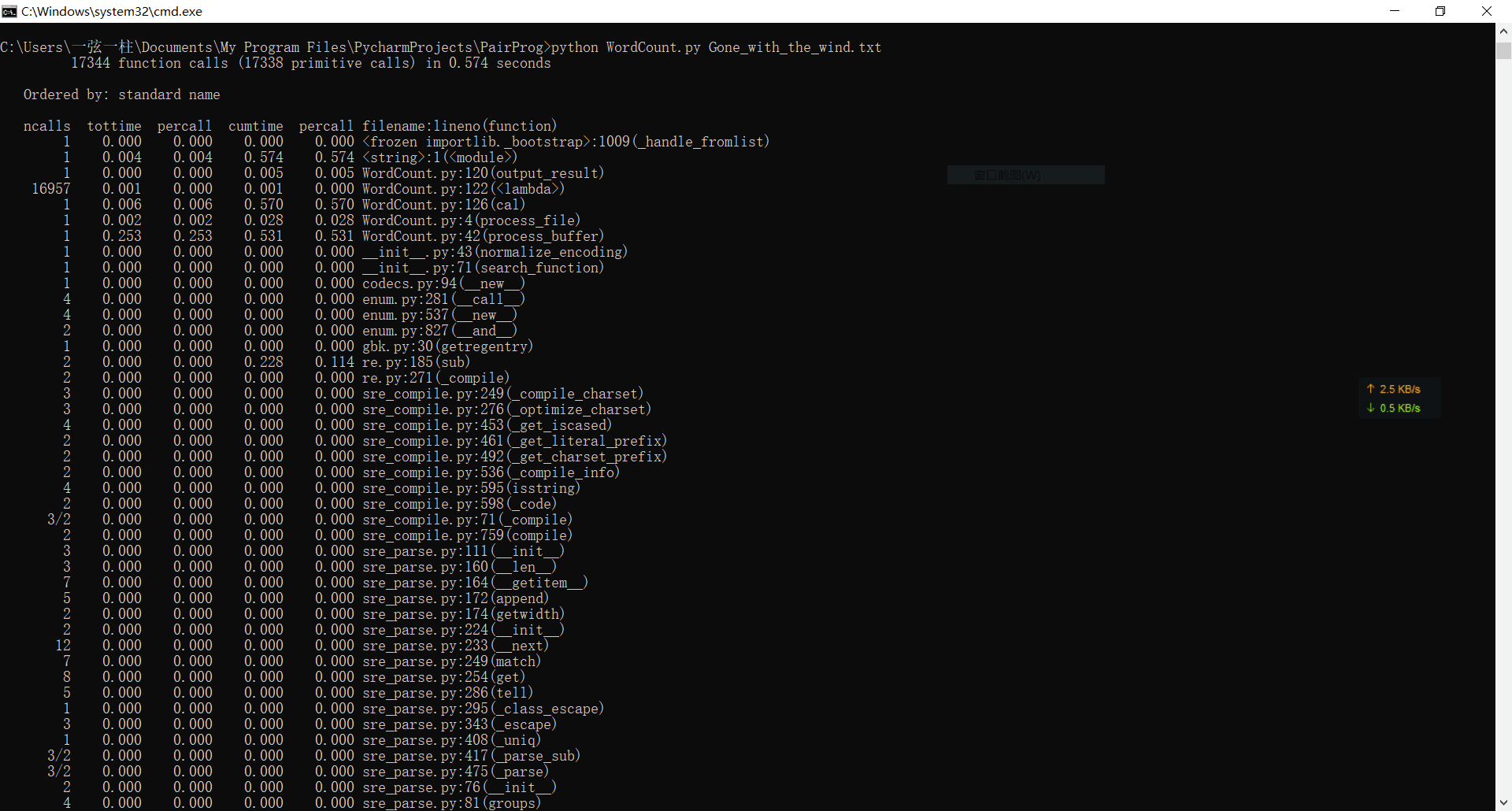
1、单词的运行时间为0.5秒左右。
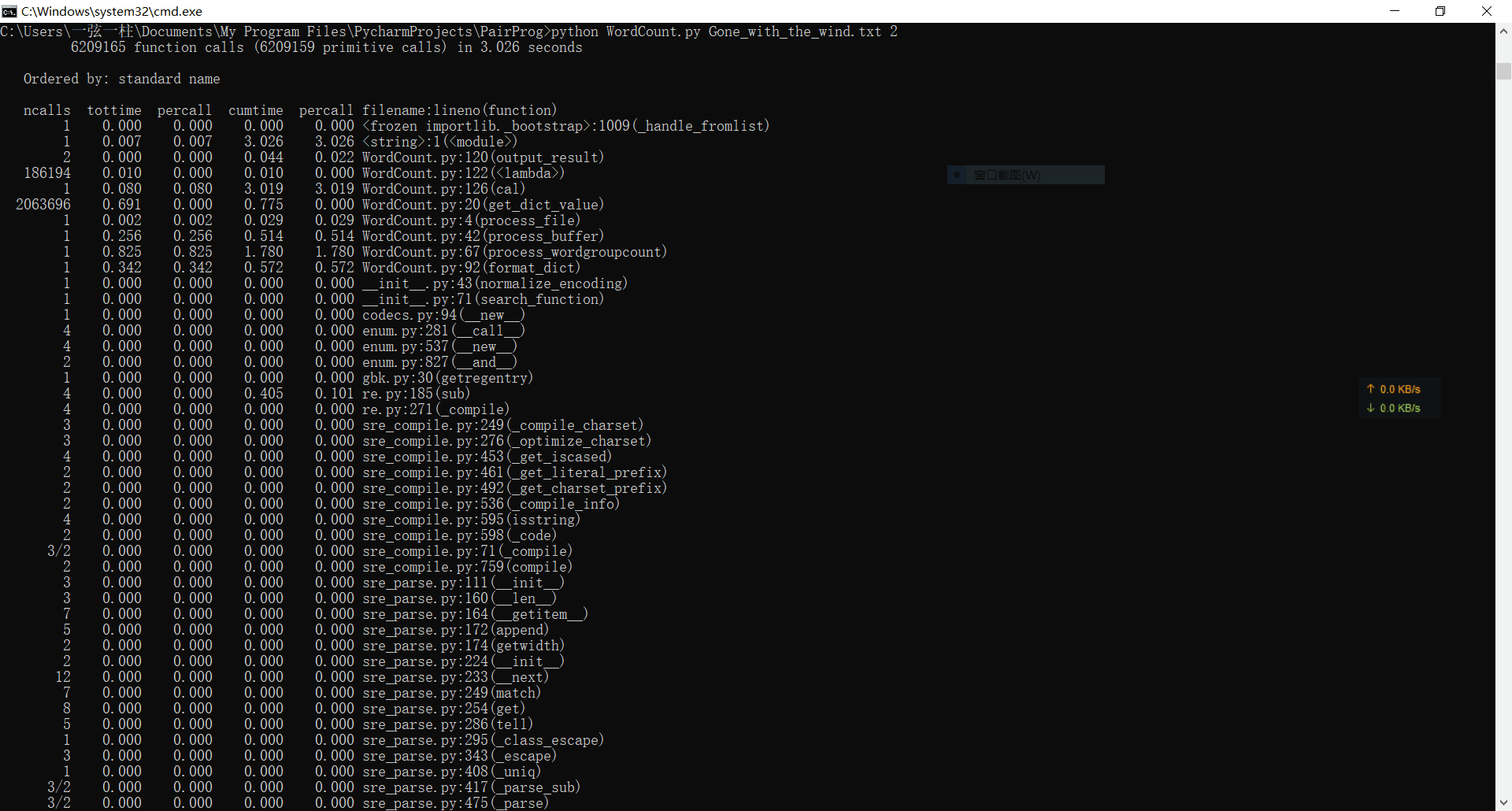
2、词组的运行时间为3秒
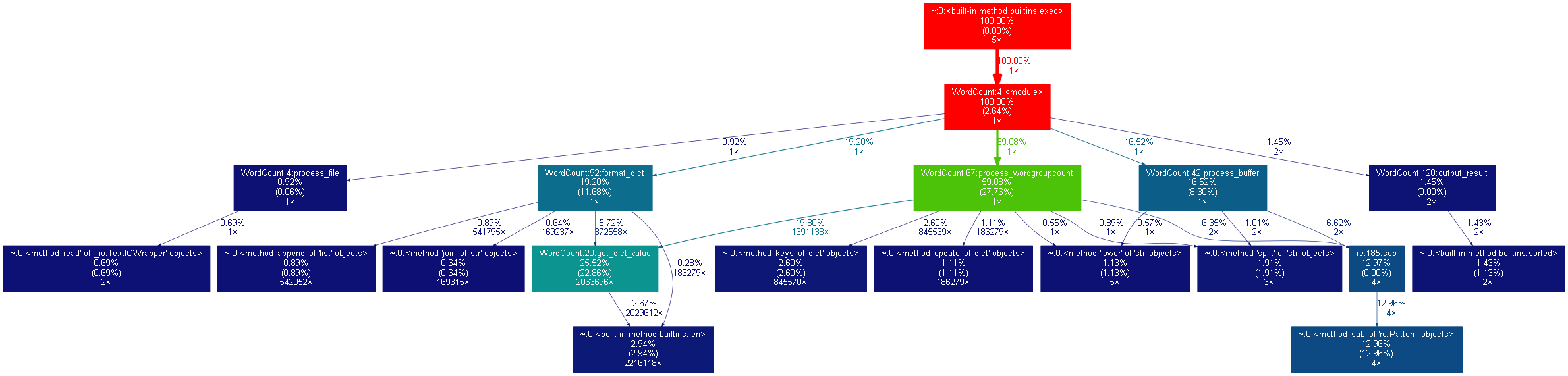
3.对广度优先遍历的优化
由于广度优先遍历存在一个双向队列来存储节点,而对于大数据来说,频繁地出队与入队太消耗时间,而入队是不能避免的,所以我们只能省掉它的出队操作,以空间换时间,将原来的6秒多缩减到目前的3秒多。
四、其他
4.1 结对编程时间开销
经过一星期左右的探索与否定,我们修改了原本的format函数,降低了广度优先遍历的时间损耗。并且我么将原本的不给修复了一部分,比如停词,英文缩写形式等等。
4.2 结对编程照片

五、事后分析与总结
5.1 简述结对编程时,针对某个问题的讨论决策过程
在讨论格式化森林时,唐庆阳觉得深度优先遍历的性能损耗的更少,而戴俊明觉得使用广度优先遍历的优化版本更好。事实证明,深度遍历同样需要频繁地出队与入队,而省去出队操作的广度优先遍历 在性能上更胜一筹。
5.2 评价对方。
唐庆阳对戴俊明的评价:我觉得我的伙伴对数据的存储结构以及算法有很好的了解,并能够以代码的形式实现自己的想法。在与他讨论问题地过程中,能够从他身上学到很多关于算法的知识,并且也能 够很好地听取我的意见。
戴俊明对唐庆阳的评价:我觉得我的伙伴对python的运用上十分出色,尤其在用正则处理文档中英文缩写的情况减少了不少时间。而且,我的伙伴沟通良好,善于总结,不断地测试每一段的代码,将此 解决方案的性能优化到极致。
5.3 评价整个过程:关于结对过程的建议
提议设置更加开放的题目与需求,结对编程过程中,我们常因为一项需求而导致抛弃性能更加优越的解决方案。
5.4 其它
python拥有成熟的大数据分析的库,对于初学者来说,使用这些库还是有点困难的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号