排序算法
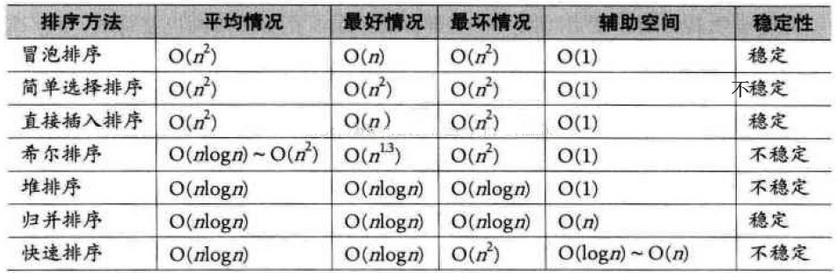
常用排序算法特性
1. 插入排序
原理:将数组分为无序区和有序区两个区,然后不断将无序区的第一个元素按大小顺序插入到有序区中去,最终将所有无序区元素都移动到有序区完成排序。
对于未排序数据(右手抓到的牌),在已排序序列(左手已经排好序的手牌)中从后向前扫描,找到相应位置并插入。
插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
#include <stdio.h> // 分类 ------------- 内部比较排序 // 数据结构 ---------- 数组 // 最差时间复杂度 ---- 最坏情况为输入序列是降序排列的,此时时间复杂度O(n^2) // 最优时间复杂度 ---- 最好情况为输入序列是升序排列的,此时时间复杂度O(n) // 平均时间复杂度 ---- O(n^2) // 所需辅助空间 ------ O(1) // 稳定性 ------------ 稳定 void InsertionSort(int A[], int n) { for (int i = 1; i < n; i++) // 类似抓扑克牌排序 { int get = A[i]; // 右手抓到一张扑克牌 int j = i - 1; // 拿在左手上的牌总是排序好的 while (j >= 0 && A[j] > get) // 将抓到的牌与手牌从右向左进行比较 { A[j + 1] = A[j]; // 如果该手牌比抓到的牌大,就将其右移 j--; } A[j + 1] = get; // 直到该手牌比抓到的牌小(或二者相等),将抓到的牌插入到该手牌右边(相等元素的相对次序未变,所以插入排序是稳定的) } } int main() { int A[] = { 6, 5, 3, 1, 8, 7, 2, 4 };// 从小到大插入排序 int n = sizeof(A) / sizeof(int); InsertionSort(A, n); printf("插入排序结果:"); for (int i = 0; i < n; i++) { printf("%d ", A[i]); } printf("\n"); return 0; }
2. 冒泡排序
原理:从数组中第一个数开始,依次遍历数组中的每一个数,通过相邻比较交换,每一轮循环下来找出剩余未排序数的中的最大数并”冒泡”至数列的顶端。
#include <stdio.h> // 分类 -------------- 内部比较排序 // 数据结构 ---------- 数组 // 最差时间复杂度 ---- O(n^2) // 最优时间复杂度 ---- 如果能在内部循环第一次运行时,使用一个旗标来表示有无需要交换的可能,可以把最优时间复杂度降低到O(n) // 平均时间复杂度 ---- O(n^2) // 所需辅助空间 ------ O(1) // 稳定性 ------------ 稳定 void Swap(int A[], int i, int j) { int temp = A[i]; A[i] = A[j]; A[j] = temp; } void BubbleSort(int A[], int n) { for (int j = 0; j < n - 1; j++) // 每次最大元素就像气泡一样"浮"到数组的最后 { for (int i = 0; i < n - 1 - j; i++) // 依次比较相邻的两个元素,使较大的那个向后移 { if (A[i] > A[i + 1]) // 如果条件改成A[i] >= A[i + 1],则变为不稳定的排序算法 { Swap(A, i, i + 1); } } } } int main() { int A[] = { 6, 5, 3, 1, 8, 7, 2, 4 }; // 从小到大冒泡排序 int n = sizeof(A) / sizeof(int); BubbleSort(A, n); printf("冒泡排序结果:"); for (int i = 0; i < n; i++) { printf("%d ", A[i]); } printf("\n"); return 0; }
3. 快速排序
快速排序使用分治策略(Divide and Conquer)来把一个序列分为两个子序列。步骤为:
1)从序列中挑出一个元素,作为"基准"(pivot).
2)把所有比基准值小的元素放在基准前面,所有比基准值大的元素放在基准的后面(相同的数可以到任一边),这个称为分区(partition)操作。
3)对每个分区递归地进行步骤1~2,递归的结束条件是序列的大小是0或1,这时整体已经被排好序了。
void sort(int *a, int left, int right) { if(left >= right)/*如果左边索引大于或者等于右边的索引就代表已经整理完成一个组了*/ { return ; } int i = left; int j = right; int key = a[left]; while(i < j) /*控制在当组内寻找一遍*/ { while(i < j && key <= a[j]) /*而寻找结束的条件就是,1,找到一个小于或者大于key的数(大于或小于取决于你想升 序还是降序)2,没有符合条件1的,并且i与j的大小没有反转*/ { j--;/*向前寻找*/ } a[i] = a[j]; /*找到一个这样的数后就把它赋给前面的被拿走的i的值(如果第一次循环且key是 a[left],那么就是给key)*/ while(i < j && key >= a[i]) /*这是i在当组内向前寻找,同上,不过注意与key的大小关系停止循环和上面相反, 因为排序思想是把数往两边扔,所以左右两边的数大小与key的关系相反*/ { i++; } a[j] = a[i]; } a[i] = key;/*当在当组内找完一遍以后就把中间数key回归*/ sort(a, left, i - 1);/*最后用同样的方式对分出来的左边的小组进行同上的做法*/ sort(a, i + 1, right);/*用同样的方式对分出来的右边的小组进行同上的做法*/ /*当然最后可能会出现很多分左右,直到每一组的i = j 为止*/ }
附:时间复杂度 O(f(n))
我们假设计算机运行一行基础代码需要执行一次运算。
int aFunc(void) { printf("Hello, World!\n"); // 需要执行 1 次 return 0; // 需要执行 1 次 }
那么上面这个方法需要执行 2 次运算
int aFunc(int n) { for(int i = 0; i<n; i++) { // 需要执行 (n + 1) 次 printf("Hello, World!\n"); // 需要执行 n 次 } return 0; // 需要执行 1 次 }
这个方法需要 (n + 1 + n + 1) = 2n + 2 次运算。
我们把 算法需要执行的运算次数 用 输入大小n 的函数 表示,即 T(n) 。
此时为了 估算算法需要的运行时间 和 简化算法分析,我们引入时间复杂度的概念。
定义:存在常数 c 和函数 f(N),使得当 N >= c 时 T(N) <= f(N),表示为 T(n) = O(f(n)) 。
如图:

当 N >= 2 的时候,f(n) = n^2 总是大于 T(n) = n + 2 的,于是我们说 f(n) 的增长速度是大于或者等于 T(n) 的,也说 f(n) 是 T(n) 的上界,可以表示为 T(n) = O(f(n))。
因为f(n) 的增长速度是大于或者等于 T(n) 的,即T(n) = O(f(n)),所以我们可以用 f(n) 的增长速度来度量 T(n) 的增长速度,所以我们说这个算法的时间复杂度是 O(f(n))。
算法的时间复杂度,用来度量算法的运行时间,记作: T(n) = O(f(n))。它表示随着 输入大小n 的增大,算法执行需要的时间的增长速度可以用 f(n) 来描述。
显然如果 T(n) = n^2,那么 T(n) = O(n^2),T(n) = O(n^3),T(n) = O(n^4) 都是成立的,但是因为第一个 f(n) 的增长速度与 T(n) 是最接近的,所以第一个是最好的选择,所以我们说这个算法的复杂度是 O(n^2) 。
那么当我们拿到算法的执行次数函数 T(n) 之后怎么得到算法的时间复杂度呢?
- 我们知道常数项对函数的增长速度影响并不大,所以当 T(n) = c,c 为一个常数的时候,我们说这个算法的时间复杂度为 O(1);如果 T(n) 不等于一个常数项时,直接将常数项省略。
比如 第一个 Hello, World 的例子中 T(n) = 2,所以我们说那个函数(算法)的时间复杂度为 O(1)。 T(n) = n + 29,此时时间复杂度为 O(n)。
- 我们知道高次项对于函数的增长速度的影响是最大的。n^3 的增长速度是远超 n^2 的,同时 n^2 的增长速度是远超 n 的。 同时因为要求的精度不高,所以我们直接忽略低此项。
比如 T(n) = n^3 + n^2 + 29,此时时间复杂度为 O(n^3)。
- 因为函数的阶数对函数的增长速度的影响是最显著的,所以我们忽略与最高阶相乘的常数。
比如 T(n) = 3n^3,此时时间复杂度为 O(n^3)。
综合起来:如果一个算法的执行次数是 T(n),那么只保留最高次项,同时忽略最高项的系数后得到函数 f(n),此时算法的时间复杂度就是 O(f(n))。为了方便描述,下文称此为 大O推导法。
由此可见,由执行次数 T(n) 得到时间复杂度并不困难,很多时候困难的是从算法通过分析和数学运算得到 T(n)。对此,提供下列四个便利的法则,这些法则都是可以简单推导出来的,总结出来以便提高效率。
- 对于一个循环,假设循环体的时间复杂度为 O(n),循环次数为 m,则这个
循环的时间复杂度为 O(n×m)。
void aFunc(int n) { for(int i = 0; i < n; i++) { // 循环次数为 n printf("Hello, World!\n"); // 循环体时间复杂度为 O(1) } }
此时时间复杂度为 O(n × 1),即 O(n)。
- 对于多个循环,假设循环体的时间复杂度为 O(n),各个循环的循环次数分别是a, b, c...,则这个循环的时间复杂度为 O(n×a×b×c...)。分析的时候应该由里向外分析这些循环。
void aFunc(int n) { for(int i = 0; i < n; i++) { // 循环次数为 n for(int j = 0; j < n; j++) { // 循环次数为 n printf("Hello, World!\n"); // 循环体时间复杂度为 O(1) } } }
此时时间复杂度为 O(n × n × 1),即 O(n^2)。
- 对于顺序执行的语句或者算法,总的时间复杂度等于其中最大的时间复杂度。
void aFunc(int n) { // 第一部分时间复杂度为 O(n^2) for(int i = 0; i < n; i++) { for(int j = 0; j < n; j++) { printf("Hello, World!\n"); } } // 第二部分时间复杂度为 O(n) for(int j = 0; j < n; j++) { printf("Hello, World!\n"); } }
此时时间复杂度为 max(O(n^2), O(n)),即 O(n^2)。
- 对于条件判断语句,总的时间复杂度等于其中 时间复杂度最大的路径 的时间复杂度。
void aFunc(int n) { if (n >= 0) { // 第一条路径时间复杂度为 O(n^2) for(int i = 0; i < n; i++) { for(int j = 0; j < n; j++) { printf("输入数据大于等于零\n"); } } } else { // 第二条路径时间复杂度为 O(n) for(int j = 0; j < n; j++) { printf("输入数据小于零\n"); } } }
此时时间复杂度为 max(O(n^2), O(n)),即 O(n^2)。
时间复杂度分析的基本策略是:从内向外分析,从最深层开始分析。如果遇到函数调用,要深入函数进行分析。
最后,我们来练习一下
一. 基础题
求该方法的时间复杂度
void aFunc(int n) { for (int i = 0; i < n; i++) { for (int j = i; j < n; j++) { printf("Hello World\n"); } } }
参考答案:
当 i = 0 时,内循环执行 n 次运算,当 i = 1 时,内循环执行 n - 1 次运算……当 i = n - 1 时,内循环执行 1 次运算。
所以,执行次数 T(n) = n + (n - 1) + (n - 2)……+ 1 = n(n + 1) / 2 = n^2 / 2 + n / 2。
根据上文说的 大O推导法 可以知道,此时时间复杂度为 O(n^2)。
二. 进阶题
求该方法的时间复杂度
void aFunc(int n) { for (int i = 2; i < n; i++) { i *= 2; printf("%i\n", i); } }
参考答案:
假设循环次数为 t,则循环条件满足 2^t < n。
可以得出,执行次数t = log(2)(n),即 T(n) = log(2)(n),可见时间复杂度为 O(log(2)(n)),即 O(log n)。
三. 再次进阶
求该方法的时间复杂度
long aFunc(int n) { if (n <= 1) { return 1; } else { return aFunc(n - 1) + aFunc(n - 2); } }
参考答案:
显然运行次数,T(0) = T(1) = 1,同时 T(n) = T(n - 1) + T(n - 2) + 1,这里的 1 是其中的加法算一次执行。
显然 T(n) = T(n - 1) + T(n - 2) 是一个斐波那契数列,通过归纳证明法可以证明,当 n >= 1 时 T(n) < (5/3)^n,同时当 n > 4 时 T(n) >= (3/2)^n。
所以该方法的时间复杂度可以表示为 O((5/3)^n),简化后为 O(2^n)。
可见这个方法所需的运行时间是以指数的速度增长的。如果大家感兴趣,可以试下分别用 1,10,100 的输入大小来测试下算法的运行时间,相信大家会感受到时间复杂度的无穷魅力。
参考:
1. 常用排序算法总结(一)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号