
全面了解linux TCP/IP协议栈_转
转自:https://blog.csdn.net/maxlovezyy/article/details/77824679
简要说明
自从熟悉了linux socket编程(主要做posix socket的TCP/IP)之后,就一直以来就想写一篇对TCP/IP有一个比较全面的涵盖用户空间、内核以及网卡的文章,以便帮助大家在遇到基于socket的TCP/IP问题或困惑时能进行有目的的、恰当的分析以便解决问题。只是一是本人上学时是个“不学无术”的不良少年。工作后自己也是不断学习中,还有比较忙(都是懒的借口吧,不然怎么还有时间看龙珠),一直没动笔,今天就花一下午时间来做一个介绍。如果大家发现了谬误之处,请及时留言,我好更正之、学习之。话不多说,下面就进入正题。
现如今的internet services可以说就是基于TCP/IP构建的。理解数据是如何通过network传输的,无论对你调试net IO的性能还是解决问题还是学习新的技术都是有很大助益的。本文将会全面的,尽力细致的通过内核及硬件中的数据流和控制流来介绍这方面的知识。
PS: 有一个我自认为实现的还不错的项目,有兴趣的童鞋可以参与github c/c++连接复用库实现。
TCP/IP的关键特征
我们如何设计一个数据传输协议以便保证数据快速、有序、无误?TCP/IP正是为了这样的需求被创造的。下面的几个特征用于帮助了解什么是TCP/IP协议(栈)。由于对于TCP来讲IP是紧密相关的,我们放到一起介绍。更多的内容,大家可以参考大学教材《计算机网络》(谢希仁著)以及《TCP/IP协议》三卷(国外)。
面向连接的(Connection-oriented)
一个tcp connection有两个端(endpoint),每一个endpoint可以用一个***(ip、port)来表达,所以两端的话就可以用(local IP address, local port number, remote IP address, remote port number)***来表达。
数据是双向流动的
双向的传递二进制流。
按序传送的
接受者接收数据一定是会按照发送者发送数据的顺序的。通过一个32-bit integer做标记。通过ACK来保证可靠性,如果发送者收不到接受者的ACK,则会重新发送。
流量控制
发送方会根据接收方提供的的窗口大小来决定如何发送数据,不会超过接收方的缓冲能力。
拥塞控制
拥塞窗口(congestion window)区别于receive window,是发送方自己根据包ACK的状态结合特定的拥塞算法计算出的一个window。它表达的当前的网络状态。发送发发送的数据上限受到流量控制和拥塞控制共同的作用。
数据传送
数据通过网络协议栈发送,如下图1。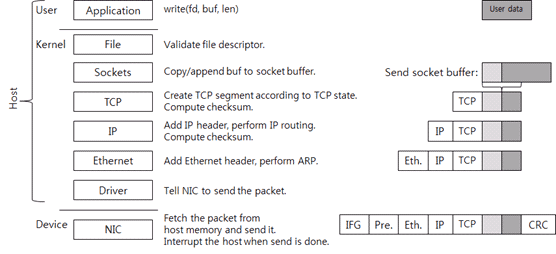
图1:数据发送的流动过程
借用于国外大神的图(下文也会借用很多,不一一说明了),其表达了数据的流动过程。这里为了防止大家不认真看,我要强调一下右侧黑色方块表达用户write的新的数据,而灰色的代表发送缓冲区中已有的数据,大括号圈的灰黑两块结合代表了一个TCP报文段。整个过程可以分为三个区域,user、kernel和device,其中user和kernel的部分要吃CPU的。这里的device就是我们说的网卡(Network Interface Card)。
内核socket关联了两个缓冲区:
一个发送缓冲区为了数据发送。
一个接收缓冲区为了接收数据。
在内核中有一个TCP control block(TCB)关联到socket。TCB包含了连接需要处理的一系列数据,这里面包含了TCP的state(LISTEN, ESTABLISHED, TIME_WAIT),receive window, congestion window, sequence number, resending timer等等。
内核中如果当前的TCP状态允许数据发送,则一个新的TCP报文段(或者说包)就会被创建。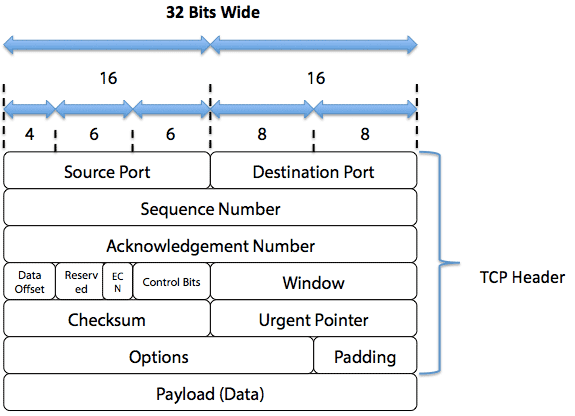
图2:TCP报文段
之后报文段流向IP层。IP层在TCP的报文段上加上IP头并执行IP路由。IP路由是寻找到达目的IP的下一跳的一个程序。IP层计算完并加上IP头的checksum之后就会把数据发送到链路层。链路层通过ARP和下一跳的IP地址查找到下一跳的MAC地址,之后链路层把其头加到数据中。至此主机端数据包完成。之后就是调用网卡驱动了。此时如果有包捕获程序比如tcpdump或者Wireshark处于运行中,内核会把数据包拷贝给它们一份。
驱动根据硬件厂商定义的协议请求传送数据。网卡在接到数据传送请求之后把数据包从主存拷贝到它的存储空间中,之后把数据打到网线。这时,为了遵从以太网标准,网卡会添加IFG(帧间隔)到数据包以便区分数据包的开始。网卡发送完数据包之后就会产生一个CPU中断,每一个中断都一个特定的中断号,OS根据中断号选择合适的驱动对中断进行处理(驱动启动的时候会注册一个对应中断号的处理函数)。
数据接收
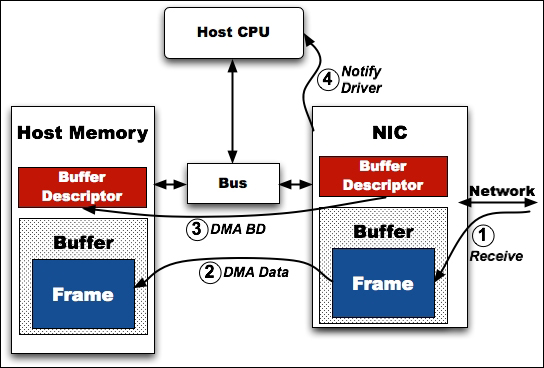
现在我们来看看是怎么接收数据的,如图3。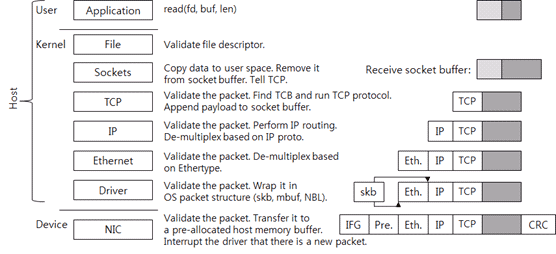
图3:数据流入过程
首先网卡把接收到的数据包写入到它的内存之中。然后对其进行校验,通过后发送到主机的主存之中。主存中的buffer是驱动分配好的,驱动会把分配好的buffer描述告诉网卡,如果没有足够的buffer接受网卡的数据包,网卡会将数据包丢弃。一旦数据包拷贝到主存完成,网卡会通过中断告知主机OS。
之后驱动会检查它是否能处理这个新的包。如果能处理,驱动会把数据包包装成OS认识的结构(linux sk_buffer)并推送到上层。
链路层接收到帧后检查通过的话会按照协议解帧并推送至IP层。
IP层会在解包之后根据包中包含的IP信息决定推送至上层还是转发到其他IP。如果判断需要推送至上层,则会解掉IP包头并推送至TCP层。
TCP在解报之后会根据其四元组找到对应的TCB,之后通过TCP协议处理这个报文。在接收到报文后,会把报文加到接受报文,之后根据TCP的状态发送一个ACK给对端。
当然上述过程会受到NAT等等Netfilter的作用,这里不谈了,也没深研究过。当然为了性能,大牛们方方面面也做了很多努力,比如大到RDMA、DPDK等大的软硬件技术,小到zero-copy、checksum offload等。
数据结构
下面介绍一下关键数据结构sk_buff(skb)。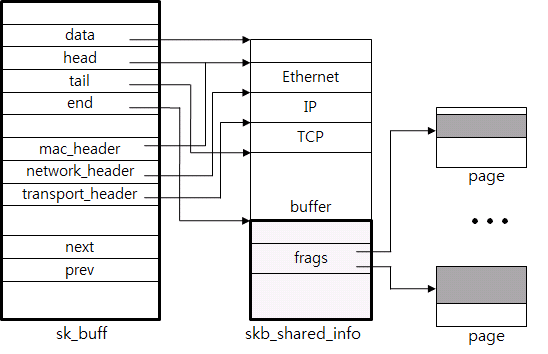
图4:sk_buffer(意为socket buffer?)
一个skb就是一个发送缓冲区可发送的数据包。从图4中可以看到其各个指针。不同层级的数据包头的添加和删除、数据包的联合和分割都是通过控制这些指针来实现的。真正的数据结构可能比这复杂很多,但是基本思路是一致的。
TCP control block
一个TCB代表了一个connection,这里TCB是一个抽象,linux用tcp_sock这个结构表达。下图5可以看出tcp_sock和fd、socket之间的关系。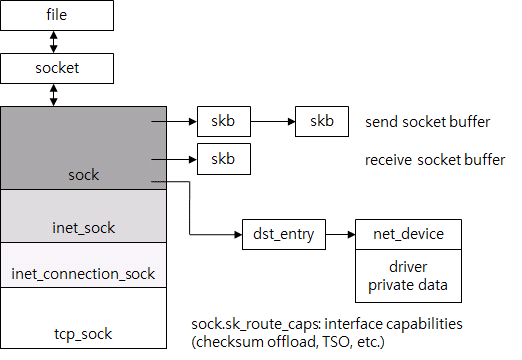
图5:TCP connection结构
当调用系统调用的时候,OS先找到file结构。对于类unix系统,socket、本地file、device都被抽象成file。因此file拥有最少的信息。对于socket,有其自己的结构关联到file,tcp_sock也会关联到socket。tcp_sock只是socket的一类,其他还有诸如inet_sock等支持各种协议的sock。所有TCP相关的信息都在tcp_sock中,比如序号啊,各种窗口等。
发送和接收缓冲区就是sk_buffer的list。dst_entry就是路由的结果,为了避免太频繁的路由,他们是sock关联的。dst_entry允许简单的ARP查找,它也是路由表的一部分。tcp_sock通过对四元组进行hash来索引。
驱动和网卡的交互
这一部分的知识可能是网上最难搜索到的部分,很大一部分原因应该是很少有人关注吧,但是了解了这部分知识会让你更通透。
驱动和网卡之间是异步通信。驱动在请求发送数据之后CPU就去干别的事情去了。网卡发送完包之后通过中断通知CPU,CPU再通过驱动程序了解到结果。和发送数据一样,接收数据也是异步的。网卡把数据倒腾到主存之后再通过中断通知CPU。
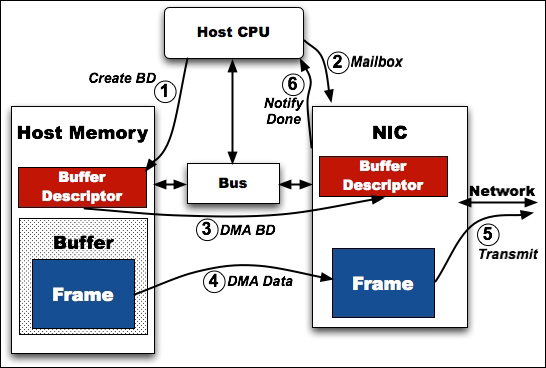
因此,预留一些空间来缓存发送和接受的buffer是必要的。大多数情况下,网卡使用环结构,这个环基本上就是一个队列,它具有固定的条目数,每一个条目存储一个发送或者接受的数据。条目被顺序的轮流使用,可以复用。如下图6,可以看到数据传送过程。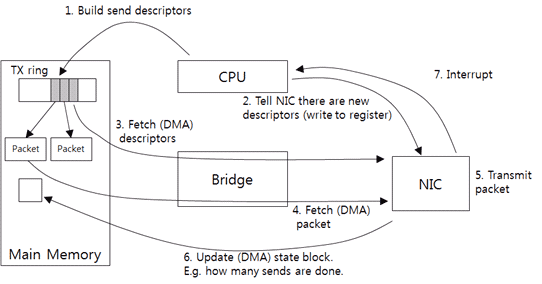
图6:驱动与网卡发送数据流
驱动接收上层的数据并创建一个网卡可以理解的数据包描述(send descriptor),包含了主存地址和大小。由于网卡只认识物理地址,所以驱动还需将虚拟地址转换成物理地址,之后把send descriptor放到Tx ring之中。下一步通过通知网卡有新的数据了,之后网卡通过DMA(直接内存访问)获取元数据和数据发送出去。发送完之后通过DMA把结果写回,之后发送中断通知。
数据的接收和发送反推过程差不多,自己看图7说话吧;-)。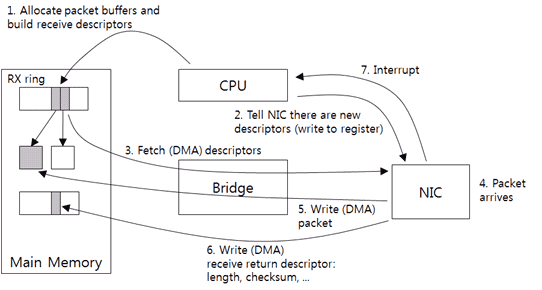
图7:驱动与网卡接收数据流
协议栈buffer和控制流
协议栈中的控制流分为几个阶段。图8显示了buffer的发送过程。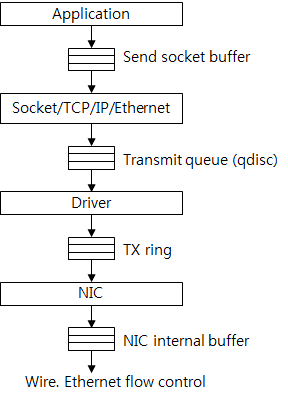
图8:buffer发送流
首先应用程序创建数据并加入到发送缓冲区。如果缓冲区不足则调用失败或者阻塞调用线程。因此应用程序向内核灌入数据的速率收到缓冲区大小的限制。
之后TCP创建包并通过传输队列(qdisc)发送给驱动。qdisc是一个FIFO结构并且是固定大小,这个大小可以通过ifconfig命令查看,其中的txqueuelen便是,一般情况下它是千级别的。
在驱动和网卡之间是TX ring。之前提到它是定长的,如果它没有足够的空间,那么当传输队列(qdisc)也满了之后包就会被drop,就形成了之下而上的反压。
下图9表现了buffer接收流。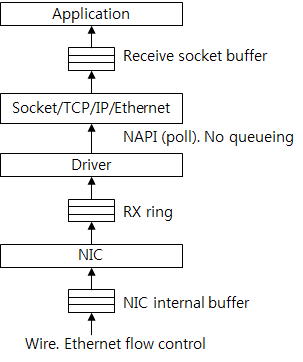
图9:buffer接收流
很容易通过发送流反推。值得注意的是驱动和协议栈之间没有了队列,数据是通过poll直接获取的。如果主机处理的速度没有网卡接收的快,则Rx ring会满,就会有包被丢弃。一般情况下丢弃不会是因为TCP连接导致的,因为TCP连接有流量控制,但是UDP是没有的。可以通过ifconfig命令看到很多信息,比如drop、error等包的数量。
最后
现代的软硬件TCP/IP协议栈单链接发送速率到1~2GiB/s完全没有任何问题(经过实测)。如果你想探索更优秀的性能,你可以尝试RMDA等技术,他们通过绕过内核以减少拷贝等方式优化了性能,当然可能依赖硬件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号