
kafka消息队列
一、概述
Kafka is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.
官网:Apache Kafka 官网文档
行为流数据是几乎所有站点在对其网站使用情况做报表时都要用到的数据中最常规的部分:包括页面访问量PV,页面曝光Expose,页面点击click等行为事件。
1.1 设计目标
kafka是一种分布式的、基于发布/订阅的消息系统,主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展
1.2 为何使用消息系统
- 解耦
- 冗余
- 扩展性
- 灵活性&峰值处理能力
- 可恢复性
- 顺序保证
- 缓冲
- 异步通讯
二、基础概念
2.1 topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。topic在逻辑可以被认为是一个queue,每条消费都必须指定它的topic,可以简单理解为必须指明把这条消息放到哪个queue里。我们把一类消息按照主题来分类,有点类似数据库中的表。
2.2 Partition
为了使得kafka的吞吐率可以线性提高,物理上把topic分成一个或多个Partition。对应到系统上就是一个或若干个目录。
每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
2.3 Broker
kafka集群包含一个或多个服务器,每个服务器节点称为一个Broker。
broker存储topic的数据。如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
每一条消息被发送到Broker中,会根据Partition规则选择被存储到哪一个Partition。如果Partition规则设置的合理,所有消息可以均匀分布到不同的Partition中。
2.4 Producer
生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
2.5 consumer
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
2.6 consumer group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
2.7 leader
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
2.8 Follower
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
三、存储原理
kafka的消息存在文件系统上,高度依赖文件系统来存储和缓存消息。
kafka正是利用顺序IO,以及Page Cache达成超高吞吐。任何发布到Partition的消息都会被追加到Partition数据文件的尾部,这样的顺序写磁盘操作让kafka效率非常高。
Kafka集群保留所有发布的message,不管这个message有没有被消费过,kafka提供可配置的保留策略去删除旧数据(还有一种策略根据分区大小删除数据)。
3.1 offset
每条消息都有一个当前Partition下唯一的64字节的offset,它是相当于当前分区第一条消息的偏移量,即第几条消息。
消费者可以指定消费的位置信息,当消费者挂掉再重新恢复的时候,可以从消费位置继续消费。
3.2 文件存储
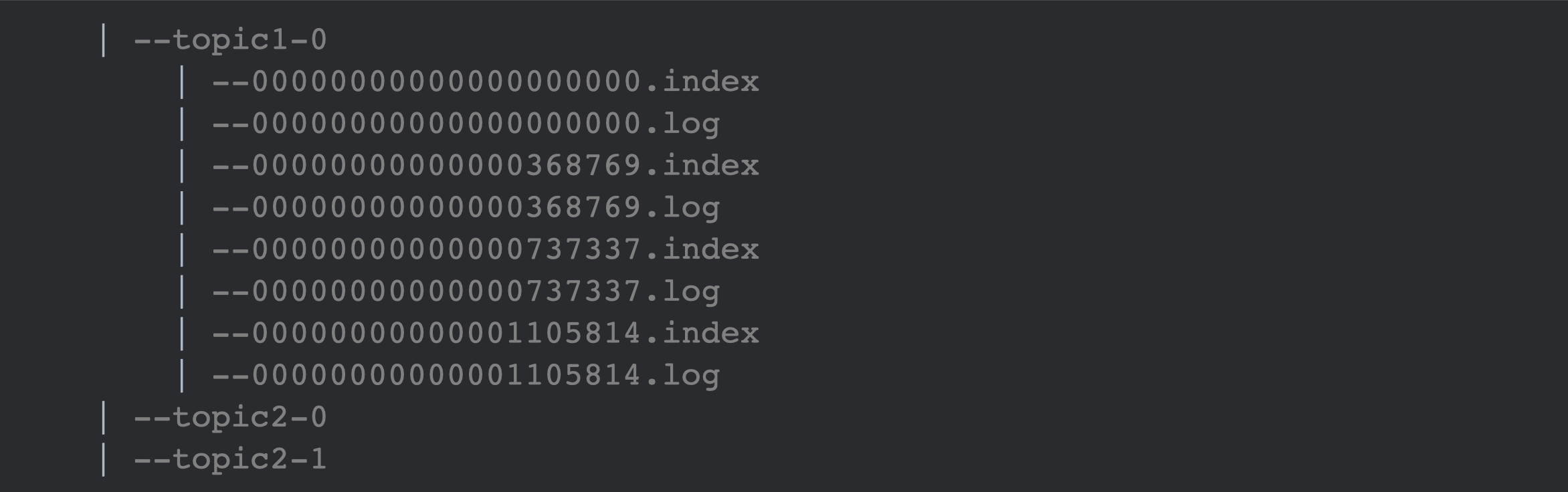
在kafka的文件存储中,同一Topic下有多个不同的Partition,每个Partition都为一个目录。
而每一个目录又被平均分配成多个大小相等的 Segment File 中,Segment File 又由 index file 和 data file 组成,他们总是成对出现,后缀 ".index" 和 ".log" 分表表示 Segment 索引文件和数据文件。
index文件
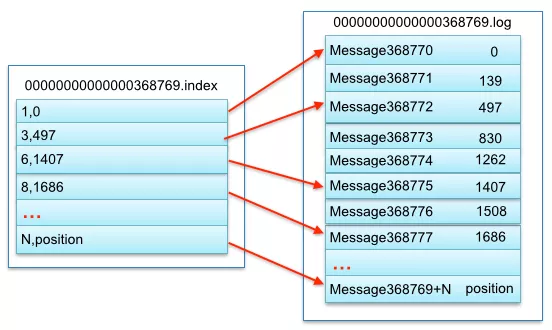
其中以索引文件中元数据 < 3, 497> 为例,依次在数据文件中表示第 3 个 Message(在全局 Partition 表示第 368769 + 3 = 368772 个 message)以及该消息的物理偏移地址为 497。
注意该 Index 文件并不是从0开始,也不是每次递增 1 的,这是因为 Kafka 采取稀疏索引存储的方式,每隔一定字节的数据建立一条索引。
它减少了索引文件大小,使得能够把 Index 映射到内存,降低了查询时的磁盘 IO 开销,同时也并没有给查询带来太多的时间消耗。
因为其文件名为上一个 Segment 最后一条消息的 Offset ,所以当需要查找一个指定 Offset 的 Message 时,通过在所有 Segment 的文件名中进行二分查找就能找到它归属的 Segment。
再在其 Index 文件中找到其对应到文件上的物理位置,就能拿出该 Message。
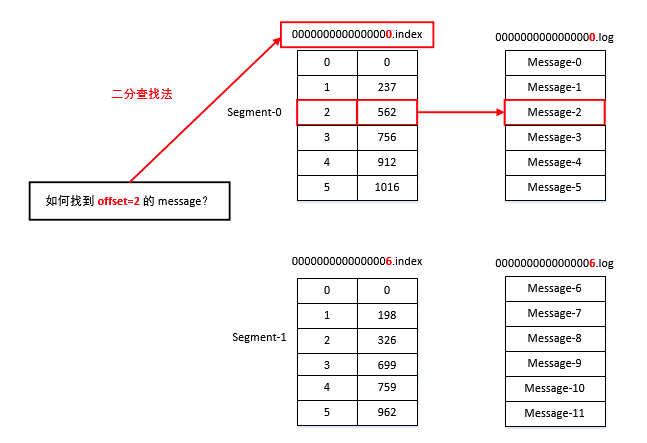
Kafka 是如何准确的知道 Message 的偏移的呢?
这是因为在 Kafka 定义了标准的数据存储结构,在 Partition 中的每一条 Message 都包含了以下三个属性:
- Offset:表示 Message 在当前 Partition 中的偏移量,是一个逻辑上的值,唯一确定了 Partition 中的一条 Message,可以简单的认为是一个 ID。
- MessageSize:表示 Message 内容 Data 的大小。
- Data:Message 的具体内容。
四、Producer和consumer
4.1 Producer
Producer 发送消息到 Broker 时,会根据Paritition 机制选择将其存储到哪一个Partition。如果 Partition 机制设置合理,所有消息可以均匀分布到不同的 Partition里,这样就实现了负载均衡。
- 指明 Partition 的情况下,直接将给定的 Value 作为 Partition 的值。
- 没有指明 Partition 但有 Key 的情况下,将 Key 的 Hash 值与分区数取余得到 Partition 值。
- 既没有 Partition 有没有 Key 的情况下,第一次调用时随机生成一个整数(后面每次调用都在这个整数上自增),将这个值与可用的分区数取余,得到 Partition 值,也就是常说的 Round-Robin 轮询算法。
为保证 Producer 发送的数据,能可靠地发送到指定的 Topic,Topic 的每个 Partition 收到 Producer 发送的数据后,都需要向 Producer 发送 ACK。如果 Producer 收到 ACK,就会进行下一轮的发送,否则重新发送数据。
- 选择完分区后,生产者知道了消息所属的主题和分区,它将这条记录添加到相同主题和分区的批量消息中,另一个线程负责发送这些批量消息到对应的 Kafka Broker。
- 当 Broker 接收到消息后,如果成功写入则返回一个包含消息的主题、分区及位移的 RecordMetadata 对象,否则返回异常。
- 生产者接收到结果后,对于异常可能会进行重试。
4.2 Consumer
可以通过增加消费组的消费者来进行水平扩展提升消费能力。这也是为什么建议创建主题时使用比较多的分区数,这样可以在消费负载高的情况下增加消费者来提升性能。
另外,消费者的数量不应该比分区数多,因为多出来的消费者是空闲的,没有任何帮助。
如果我们的 C1 处理消息仍然还有瓶颈,我们如何优化和处理?
把 C1 内部的消息进行二次 sharding,开启多个 goroutine worker 进行消费,为了保障 offset 提交的正确性,需要使用 watermark 机制,保障最小的 offset 保存,才能往 Broker 提交。
4.3 Consumer Group
Kafka 一个很重要的特性就是,只需写入一次消息,可以支持任意多的应用读取这个消息。
换句话说,每个应用都可以读到全量的消息。为了使得每个应用都能读到全量消息,应用需要有不同的消费组。
对于上面的例子,假如我们新增了一个新的消费组 G2,而这个消费组有两个消费者如图。
在这个场景中,消费组 G1 和消费组 G2 都能收到 T1 主题的全量消息,在逻辑意义上来说它们属于不同的应用。
最后,总结起来就是:如果应用需要读取全量消息,那么请为该应用设置一个消费组;如果该应用消费能力不足,那么可以考虑在这个消费组里增加消费者。
可以看到,当新的消费者加入消费组,它会消费一个或多个分区,而这些分区之前是由其他消费者负责的。
另外,当消费者离开消费组(比如重启、宕机等)时,它所消费的分区会分配给其他分区。这种现象称为重平衡(Rebalance)。
重平衡是 Kafka 一个很重要的性质,这个性质保证了高可用和水平扩展。不过也需要注意到,在重平衡期间,所有消费者都不能消费消息,因此会造成整个消费组短暂的不可用。
而且,将分区进行重平衡也会导致原来的消费者状态过期,从而导致消费者需要重新更新状态,这段期间也会降低消费性能。
消费者通过定期发送心跳(Hearbeat)到一个作为组协调者(Group Coordinator)的 Broker 来保持在消费组内存活。这个 Broker 不是固定的,每个消费组都可能不同。
当消费者拉取消息或者提交时,便会发送心跳。如果消费者超过一定时间没有发送心跳,那么它的会话(Session)就会过期,组协调者会认为该消费者已经宕机,然后触发重平衡。
可以看到,从消费者宕机到会话过期是有一定时间的,这段时间内该消费者的分区都不能进行消息消费。
通常情况下,我们可以进行优雅关闭,这样消费者会发送离开的消息到组协调者,这样组协调者可以立即进行重平衡而不需要等待会话过期。
在 0.10.1 版本,Kafka 对心跳机制进行了修改,将发送心跳与拉取消息进行分离,这样使得发送心跳的频率不受拉取的频率影响。
另外更高版本的 Kafka 支持配置一个消费者多长时间不拉取消息但仍然保持存活,这个配置可以避免活锁(livelock)。活锁,是指应用没有故障但是由于某些原因不能进一步消费。
但是活锁也很容易导致连锁故障,当消费端下游的组件性能退化,那么消息消费会变的很慢,会很容易出发 livelock 的重新均衡机制,反而影响力吞吐。
Partition 会为每个 Consumer Group 保存一个偏移量,记录 Group 消费到的位置。
4.4 consumer commit offset
消费端可以通过设置参数 enable.auto.commit 来控制是自动提交还是手动,如果值为 true 则表示自动提交,在消费端的后台会定时的提交消费位移信息,时间间隔由 auto.commit.interval.ms(默认为5秒)。
可能存在重复的位移数据提交到消费位移主题中,因为每隔5秒会往主题中写入一条消息,不管是否有新的消费记录,这样就会产生大量的同 key 消息,其实只需要一条,因此需要依赖前面提到日志压缩策略来清理数据。
重复消费,假设位移提交的时间间隔为5秒,那么在5秒内如果发生了 rebalance,则所有的消费者会从上一次提交的位移处开始消费,那么期间消费的数据则会再次被消费。
我们来看看集中 Delivery Guarantee:
读完消息先 commit 再处理消息。这种模式下,如果 Consumer 在 commit 后还没来得及处理消息就 crash 了,下次重新开始工作后就无法读到刚刚已提交而未处理的消息,这就对应于 At most once。
读完消息先处理再 commit。这种模式下,如果在处理完消息之后 commit 之前 Consumer crash 了,下次重新开始工作时还会处理刚刚未 commit 的消息,实际上该消息已经被处理过了。这就对应于At least once。
4.5 Push vs Pull
作为一个消息系统,Kafka遵循了传统的方式,选择由 Producer 向 Broker push 消息并由 Consumer 从 Broker pull 消息。一些 logging-centric system,比如 Facebook 的 Scribe 和 Cloudera 的 Flume,采用 push 模式。事实上,push 模式 和 pull 模式各有优劣。
push 模式很难适应消费速率不同的消费者,因为消息发送速率是由 Broker 决定的。push 模式的目标是尽可能以最快速度传递消息,但是这样很容易造成 Consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而 pull 模式则可以根据Consumer 的消费能力以适当的速率消费消息。
对于 Kafka 而言,pull 模式更合适。pull 模式可简化 Broker 的设计,Consumer 可自主控制消费消息的速率,同时 Consumer 可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
而 Pull 模式则可以根据 Consumer 的消费能力以适当的速率消费消息。Pull 模式不足之处是,如果 Kafka 没有数据,消费者可能会陷入循环中,一直返回空数据。
因为消费者从 Broker 主动拉取数据,需要维护一个长轮询,针对这一点, Kafka 的消费者在消费数据时会传入一个时长参数 timeout。如果当前没有数据可供消费,Consumer 会等待一段时间之后再返回,这段时长即为 timeout。
五、Leader和Follower
5.1 Leader
引入 Replication 之后,同一个 Partition 可能会有多个 Replica,而这时需要在这些Replication 之间选出一个 Leader,Producer 和 Consumer 只与这个 Leader 交互,其它 Replica 作为 Follower 从 Leader 中复制数据。
因为需要保证同一个 Partition 的多个 Replica 之间的数据一致性(其中一个宕机后其它 Replica 必须要能继续服务并且即不能造成数据重复也不能造成数据丢失)。
如果没有一个 Leader,所有 Replica 都可同时读/写数据,那就需要保证多个 Replica 之间互相(N×N条通路)同步数据,数据的一致性和有序性非常难保证,大大增加了 Replication 实现的复杂性,同时也增加了出现异常的几率。而引入 Leader 后,只有 Leader 负责数据读写,Follower 只向 Leader 顺序 Fetch 数据(N条通路),系统更加简单且高效。
ACK机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等 ISR 中的 Follower 全部接受成功。只有被 ISR 中所有 Replica 同步的消息才被 Commit,但Producer 发布数据时,Leader 并不需要 ISR 中的所有 Replica 同步该数据才确认收到数据。
0:Producer 不等待 Broker 的 ACK,这提供了最低延迟,Broker 一收到数据还没有写入磁盘就已经返回,当 Broker 故障时有可能丢失数据。
1:Producer 等待 Broker 的 ACK,Partition 的 Leader 落盘成功后返回 ACK,如果在 Follower 同步成功之前 Leader 故障,那么将会丢失数据。
-1(all):Producer 等待 Broker 的 ACK,Partition 的 Leader 和 Follower 全部落盘成功后才返回 ACK。但是在 Broker 发送 ACK 时,Leader 发生故障,则会造成数据重复。
六、quickstart
参考:kafka.apache.org/quickstart
sudo yum install java-1.8.0-openjdk
https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.8.0/kafka_2.13-2.8.0.tgz
tar xvf kafka_2.13-2.8.0.tgz
bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-server-start.sh config/server.properties
bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092
bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092
bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092
bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
// stop
Stop the producer and consumer clients with Ctrl-C, if you haven't done so already.
Stop the Kafka broker with Ctrl-C.
Lastly, stop the ZooKeeper server with Ctrl-C.
rm -rf /tmp/kafka-logs /tmp/zookeeper
zookeeper占用的端口号是2181,kafka占用的端口号是9092。kafka连接的zookeeper是上面所启动的2181端口号,所以kafka是依赖zookeeper启动的,如果要启动多个kafka形成一个集群,那么设定的连接zookeeper的服务是同一个。
常用命令
查看broker详情
kafka-log-dirs.sh --describe --bootstrap-server kafka:9092 --broker-list 1
topic
查看列表
kafka-topics.sh --list --zookeeper zookeeper:2181
创建
kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 1 --partitions 3 --topic [topic_name]
查看详情
kafka-topics.sh --describe --zookeeper zookeeper:2181 --topic [topic_name]
删除
kafka-topics.sh --zookeeper zookeeper:2181 --delete --topic [topic_name]
topic消费情况
topic offset 最小
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 -topic [topic_name] --time -2
topic offset最大
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 -topic [topic_name] --time -1
生产
添加数据
kafka-console-producer.sh --broker-list localhost:9092 --topic [topic_name]
消费
从头部开始消费
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic [topic_name] --from-beginning
从尾部开始消费,必需要指定分区
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic [topic_name] --offset latest --partition 0
从某个位置开始消费(--offset [n])
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic [topic_name] --offset 100 --partition 0
消费指定个数(--max-messages [n])
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic [topic_name] --offset latest --partition 0 --max-messages 2
消费组
创建消费组(group.id)
bin/kafka-console-consumer.sh --bootstrap-server myhost:9092 --topic mytopic --consumer-property group.id=mygroup
查看消费组列表
kafka-consumer-groups.sh --list --bootstrap-server localhost:9092
查看消费组情况
kafka-consumer-groups.sh --bootstrap-server kafka:9092 --describe --group [group_id]
offset 偏移设置为最早
kafka-consumer-groups.bat --bootstrap-server kafka:9092 --group kafka_consumer_session --reset-offsets --to-earliest --all-topics --execute
offset 偏移设置为新
kafka-consumer-groups.bat --bootstrap-server kafka:9092 --group kafka_consumer_session --reset-offsets --to-latest --all-topics --execute
offset 偏移设置为指定位置
kafka-consumer-groups.bat --bootstrap-server kafka:9092 --group kafka_consumer_session --reset-offsets --to-offset 2000 --all-topics --execute
offset 偏移设置某个时间之后最早位移
kafka-consumer-groups.bat --bootstrap-server kafka:9092 --group kafka_consumer_session --reset-offsets --to-datetime 2020-12-28T00:00:00.000 --all-topics --execute
参考:
1.Kafka学习之路 (一)Kafka的简介
2.Kafka in a Nutshell
3.How to choose the number of topics/partitions in a Kafka cluster? - 对Kafka Partition的深入讲解和性能优化指导
4.zookeeper教程
5. go操作kafka

 浙公网安备 33010602011771号
浙公网安备 33010602011771号