
golang之map进阶
一、按照指定顺序遍历map
map按key顺序获取value
package main import ( "fmt" "sort" ) func main() { m := make(map[string]int, 5) fmt.Printf("%T[%p](%d): %v\n", m, &m, len(m), m) m["wang"] = 1 m["wangq"] = 2 m["wangh"] = 3 m["hua"] = 4 m["huaq"] = 5 fmt.Printf("%T[%p](%d): %v\n", m, &m, len(m), m) m["huaw"] = 6 m["qing"] = 7 m["qingw"] = 8 fmt.Printf("%T[%p](%d): %v\n", m, &m, len(m), m) mlen := len(m) ss := make([]string, 0, mlen) for k := range m { ss = append(ss, k) } sort.Strings(ss) sort.Sort(sort.Reverse(sort.StringSlice(ss))) // 反序 fmt.Println(ss) for _, v := range ss { fmt.Printf("%s:%d ", v, m[v]) } } ////// map[string]int[0xc000136018](0): map[] map[string]int[0xc000136018](5): map[hua:4 huaq:5 wang:1 wangh:3 wangq:2] map[string]int[0xc000136018](8): map[hua:4 huaq:5 huaw:6 qing:7 qingw:8 wang:1 wangh:3 wangq:2] [wangq wangh wang qingw qing huaw huaq hua] wangq:2 wangh:3 wang:1 qingw:8 qing:7 huaw:6 huaq:5 hua:4
注:map() make时大小无关,An empty map is allocated with enough space to hold the specified number of elements. The size may be omitted, in which case a small starting size is allocated.
二、map实现原理
map的源码位于 src/runtime/map.go中 笔者go的版本是1.12在go中,map同样也是数组存储的的,每个数组下标处存储的是一个bucket,这个bucket的类型见下面代码,每个bucket中可以存储8个kv键值对,当每个bucket存储的kv对到达8个之后,会通过overflow指针指向一个新的bucket,从而形成一个链表,看bmap的结构,我想大家应该很纳闷,没看见kv的结构和overflow指针啊,事实上,这两个结构体并没有显示定义,是通过指针运算进行访问的。
//bucket结构体定义 b就是bucket type bmap{ // tophash generally contains the top byte of the hash value // for each key in this bucket. If tophash[0] < minTopHash, // tophash[0] is a bucket evacuation state instead. //翻译:top hash通常包含该bucket中每个键的hash值的高八位。 // 如果tophash[0]小于mintophash,则tophash[0]为桶疏散状态 //bucketCnt 的初始值是8 tophash [bucketCnt]uint8 // Followed by bucketCnt keys and then bucketCnt values. // NOTE: packing all the keys together and then all the values together makes the // code a bit more complicated than alternating key/value/key/value/... but it allows // us to eliminate padding which would be needed for, e.g., map[int64]int8. // Followed by an overflow pointer. //翻译:接下来是bucketcnt键,然后是bucketcnt值。 //注意:将所有键打包在一起,然后将所有值打包在一起, //使得代码比交替键/值/键/值/更复杂。但它允许//我们消除可能需要的填充, //例如map[int64]int8./后面跟一个溢出指针 }
看上面代码以及注释,我们能得到bucket中存储的kv是这样的,tophash用来快速查找key值是否在该bucket中,而不同每次都通过真值进行比较;还有kv的存放,为什么不是k1v1,k2v2..... 而是k1k2...v1v2...,我们看上面的注释说的 map[int64]int8,key是int64(8个字节),value是int8(一个字节),kv的长度不同,如果按照kv格式存放,则考虑内存对齐v也会占用int64,而按照后者存储时,8个v刚好占用一个int64,从这个就可以看出go的map设计之巧妙。
最后我们分析一下go的整体内存结构,阅读一下map存储的源码,如下图所示,当往map中存储一个kv对时,通过k获取hash值,hash值的低八位和bucket数组长度取余,定位到在数组中的那个下标,hash值的高八位存储在bucket中的tophash中,用来快速判断key是否存在,key和value的具体值则通过指针运算存储,当一个bucket满时,通过overfolw指针链接到下一个bucket。
三、一致性hash
参考:动手写分布式缓存 - GeeCache第四天 一致性哈希(hash)
3.1 算法原理
一致性哈希算法将 key 映射到 2^32 的空间中,将这个数字首尾相连,形成一个环。
- 计算节点/机器(通常使用节点的名称、编号和 IP 地址)的哈希值,放置在环上。
- 计算 key 的哈希值,放置在环上,顺时针寻找到的第一个节点,就是应选取的节点/机器。
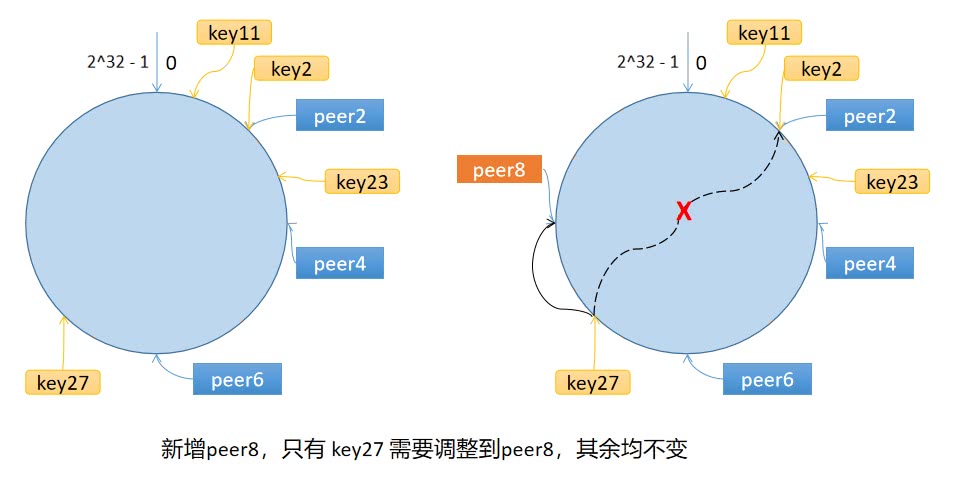
环上有 peer2,peer4,peer6 三个节点,key11,key2,key27 均映射到 peer2,key23 映射到 peer4。此时,如果新增节点/机器 peer8,假设它新增位置如图所示,那么只有 key27 从 peer2 调整到 peer8,其余的映射均没有发生改变。
也就是说,一致性哈希算法,在新增/删除节点时,只需要重新定位该节点附近的一小部分数据,而不需要重新定位所有的节点,这就解决了上述的问题。
3.2 数据倾斜问题
如果服务器的节点过少,容易引起 key 的倾斜。例如上面例子中的 peer2,peer4,peer6 分布在环的上半部分,下半部分是空的。那么映射到环下半部分的 key 都会被分配给 peer2,key 过度向 peer2 倾斜,缓存节点间负载不均。
为了解决这个问题,引入了虚拟节点的概念,一个真实节点对应多个虚拟节点。
假设 1 个真实节点对应 3 个虚拟节点,那么 peer1 对应的虚拟节点是 peer1-1、 peer1-2、 peer1-3(通常以添加编号的方式实现),其余节点也以相同的方式操作。
- 第一步,计算虚拟节点的 Hash 值,放置在环上。
- 第二步,计算 key 的 Hash 值,在环上顺时针寻找到应选取的虚拟节点,例如是 peer2-1,那么就对应真实节点 peer2。
虚拟节点扩充了节点的数量,解决了节点较少的情况下数据容易倾斜的问题。而且代价非常小,只需要增加一个字典(map)维护真实节点与虚拟节点的映射关系即可。
package consistenthash import ( "hash/crc32" "sort" "strconv" ) // Hash maps bytes to uint32 type Hash func(data []byte) uint32 // Map constains all hashed keys type Map struct { hash Hash replicas int keys []int // Sorted hashMap map[int]string } // New creates a Map instance func New(replicas int, fn Hash) *Map { m := &Map{ replicas: replicas, hash: fn, hashMap: make(map[int]string), } if m.hash == nil { m.hash = crc32.ChecksumIEEE } return m } // Add adds some keys to the hash. func (m *Map) Add(keys ...string) { for _, key := range keys { for i := 0; i < m.replicas; i++ { hash := int(m.hash([]byte(strconv.Itoa(i) + key))) m.keys = append(m.keys, hash) m.hashMap[hash] = key } } sort.Ints(m.keys) } // Get gets the closest item in the hash to the provided key. func (m *Map) Get(key string) string { if len(m.keys) == 0 { return "" } hash := int(m.hash([]byte(key))) // Binary search for appropriate replica. idx := sort.Search(len(m.keys), func(i int) bool { return m.keys[i] >= hash }) return m.hashMap[m.keys[idx%len(m.keys)]] }
参考:
1. map实现原理 topgoer

 浙公网安备 33010602011771号
浙公网安备 33010602011771号