mysql数据库分库分表
关系型数据库以MySQL为例,单机的存储能力、连接数是有限的,它自身就很容易会成为系统的瓶颈。当单表数据量在百万以里时,我们还可以通过添加从库、优化索引提升性能。一旦数据量朝着千万以上趋势增长,再怎么优化数据库,很多操作性能仍下降严重。为了减少数据库的负担,提升数据库响应速度,缩短查询时间,这时候就需要进行分库分表。
ps:基本上单机数据库可以支撑10万用户量级别。一般情况下像数据库吃不消就升级硬件,优化数据库配置,主从同步,读写分离,优化代码、引入redis等。只有在真的不行了才分库分表。
一、什么是分库分表?
其实就是字面意思,很好理解:
- 分库:从单个数据库拆分成多个数据库的过程,将数据散落在多个数据库中。
- 分表:从单张表拆分成多张表的过程,将数据散落在多张表内。
二、为什么要分库分表?
关键字:提升性能、增加可用性。
从性能上看
随着单库中的数据量越来越大、数据库的查询QPS越来越高,相应的,对数据库的读写所需要的时间也越来越多。数据库的读写性能可能会成为业务发展的瓶颈。对应的,就需要做数据库性能方面的优化。本文中我们只讨论数据库层面的优化,不讨论缓存等应用层优化的手段。
如果数据库的查询QPS过高,就需要考虑拆库,通过分库来分担单个数据库的连接压力。比如,如果查询QPS为3500,假设单库可以支撑1000个连接数的话,那么就可以考虑拆分成4个库,来分散查询连接压力。
如果单表数据量过大,当数据量超过一定量级后,无论是对于数据查询还是数据更新,在经过索引优化等纯数据库层面的传统优化手段之后,还是可能存在性能问题。这是量变产生了质变,这时候就需要去换个思路来解决问题,比如:从数据生产源头、数据处理源头来解决问题,既然数据量很大,那我们就来个分而治之,化整为零。这就产生了分表,把数据按照一定的规则拆分成多张表,来解决单表环境下无法解决的存取性能问题。
从可用性上看
单个数据库如果发生意外,很可能会丢失所有数据。尤其是云时代,很多数据库都跑在虚拟机上,如果虚拟机/宿主机发生意外,则可能造成无法挽回的损失。因此,除了传统的 Master-Slave、Master-Master 等部署层面解决可靠性问题外,我们也可以考虑从数据拆分层面解决此问题。
此处我们以数据库宕机为例:
- 单库部署情况下,如果数据库宕机,那么故障影响就是100%,而且恢复可能耗时很长。
- 如果我们拆分成2个库,分别部署在不同的机器上,此时其中1个库宕机,那么故障影响就是50%,还有50%的数据可以继续服务。
- 如果我们拆分成4个库,分别部署在不同的机器上,此时其中1个库宕机,那么故障影响就是25%,还有75%的数据可以继续服务,恢复耗时也会很短。
当然,我们也不能无限制的拆库,这也是牺牲存储资源来提升性能、可用性的方式,毕竟资源总是有限的。
三、数据库瓶颈
不管是IO瓶颈还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载的活跃连接数的阈值。在业务service来看, 就是可用数据库连接少甚至无连接可用,接下来就可以想象了(并发量、吞吐量、崩溃)。
IO瓶颈
第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询会产生大量的IO,降低查询速度->分库和垂直分表
第二种:网络IO瓶颈,请求的数据太多,网络带宽不够 ->分库
CPU瓶颈
第一种:SQl问题:如SQL中包含join,group by, order by,非索引字段条件查询等,增加CPU运算的操作->SQL优化,建立合适的索引,在业务Service层进行业务计算。
第二种:单表数据量太大,查询时扫描的行太多,SQl效率低,增加CPU运算的操作。->水平分表。
四、如何分库分表?
分库分表就是要将大量数据分散到多个数据库中,使每个数据库中数据量小响应速度快,以此来提升数据库整体性能。
核心理念就是对数据进行切分(Sharding),以及切分后如何对数据的快速定位与整合。

1、水平分库
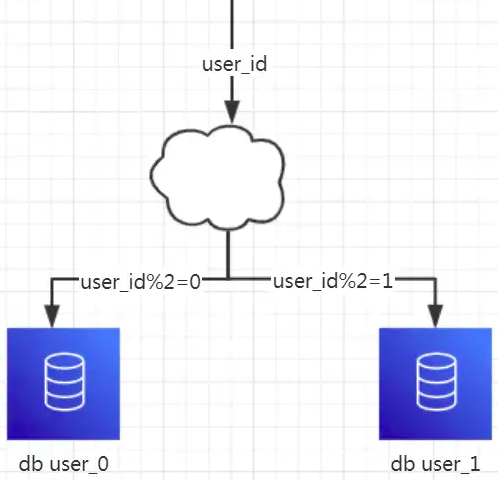
1、概念:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
2、结果:每个库的结构都一样。每个库中的数据不一样,没有交集。所有库的数据并集是全量数据。
3、场景:系统绝对并发量上来了,分表难以根本上解决问题,并且还没有明显的业务归属来垂直分库的情况下。
4、分析:库多了,io和cpu的压力自然可以成倍缓解
2、水平分表

1、概念:以字段为依据,按照一定策略(hash、range等),讲一个表中的数据拆分到多个表中。
2、结果:每个表的结构都一样,每个表的数据不一样,没有交集,所有表的并集是全量数据。
3、场景:系统绝对并发量没有上来,只是单表的数据量太多,影响了SQL效率,加重了CPU负担,以至于成为瓶颈,可以考虑水平分表。
4、分析:单表的数据量少了,单次执行SQL执行效率高了,自然减轻了CPU的负担。
3、垂直分库
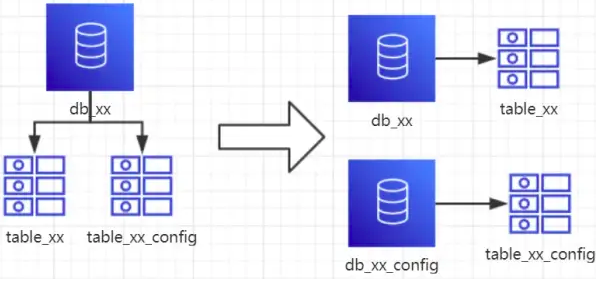
1、概念:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
2、结果:每个库的结构都不一样每个库的数据也不一样,没有交集。所有库的并集是全量数据。
3、场景:系统绝对并发量上来了,并且可以抽象出单独的业务模块的情况下。
4、分析:到这一步,基本上就可以服务化了。例如:随着业务的发展,一些公用的配置表、字典表等越来越多,这时可以将这些表拆到单独的库中,甚至可以服务化。再者,随着业务的发展孵化出了一套业务模式,这时可以将相关的表拆到单独的库中,甚至可以服务化。
4、垂直分表
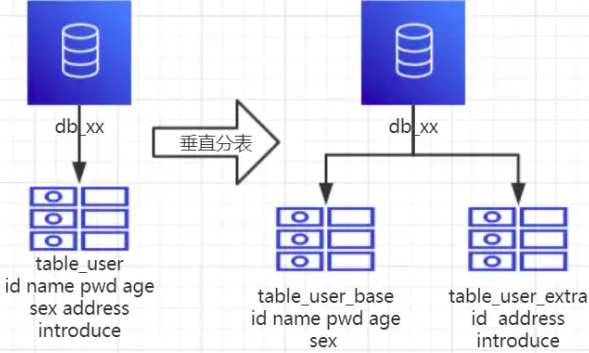
1、概念:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表中(主表和扩展表)。
2、结果:每个表的结构不一样。每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,一般是主键,用于关联数据。所有表的并集是全量数据。
3、场景:系统绝对并发量并没有上来,表的记录并不多,但是字段多,并且热点数据和非热点数据在一起,单行数据所需的存储空间较大,以至于数据库缓存的数据行减少,查询时回去读磁盘数据产生大量随机读IO,产生IO瓶颈。
4、分析:可以用列表页和详情页来帮助理解。垂直分表的拆分原则是将热点数据(可能经常会查询的数据)放在一起作为主表,非热点数据放在一起作为扩展表,这样更多的热点数据就能被缓存下来,进而减少了随机读IO。拆了之后,要想获取全部数据就需要关联两个表来取数据。
但记住千万别用join,因为join不仅会增加CPU负担并且会将两个表耦合在一起(必须在一个数据库实例上)。关联数据应该在service层进行,分别获取主表和扩展表的数据,然后用关联字段关联得到全部数据。
五、分库分表后引入问题
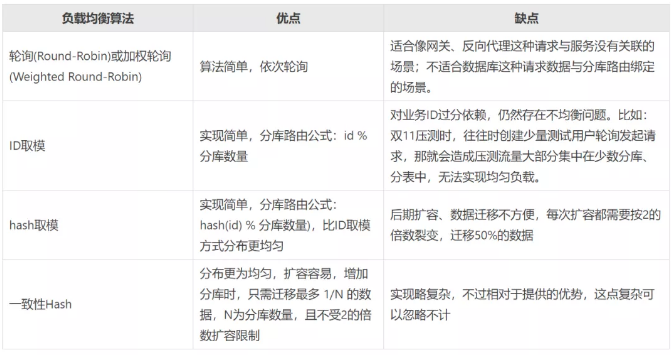
0、如何让数据均匀散落在各个分库分表内
1、事务一致性问题
由于表分布在不同库中,不可避免会带来跨库事务问题。一般可使用"XA协议"和"两阶段提交"处理,但是这种方式性能较差,代码开发量也比较大。
通常做法是做到最终一致性的方案,往往不苛求系统的实时一致性,只要在允许的时间段内达到最终一致性即可,可采用事务补偿的方式。
2、分页、排序的坑
日常开发中分页、排序是必备功能,而多库进行查询时limit分页、order by排序,着实让人比较头疼。
分页需按照指定字段进行排序,如果排序字段恰好是分片字段时,通过分片规则就很容易定位到分片的位置;一旦排序字段非分片字段时,就需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序,最终返回给用户,过程比较复杂。
3、全局唯一主键问题
由于分库分表后,表中的数据同时存在于多个数据库,而某个分区数据库的自增主键已经无法满足全局唯一,所以此时一个能够生成全局唯一ID的系统是非常必要的。那么这个全局唯一ID就叫分布式ID。
可以参考我之前写的这篇文章《一口气说出9种分布式ID生成方式,面试官有点懵了》:
UUID,数据库自增ID,数据库多主模式,号段模式,Redis
雪花算法(SnowFlake),滴滴出品(TinyID),百度 (Uidgenerator),美团(Leaf)
参考:
1. 大厂面试必问:数据库如何分库分表,需要注意哪些问题? 拉钩教育
2. 浅谈分库分表那些事儿 阿里技术

 浙公网安备 33010602011771号
浙公网安备 33010602011771号