聚类外部评价指标(纯度,兰德指数,RI,ARI)
REF
https://zhuanlan.zhihu.com/p/343667804
聚类纯度
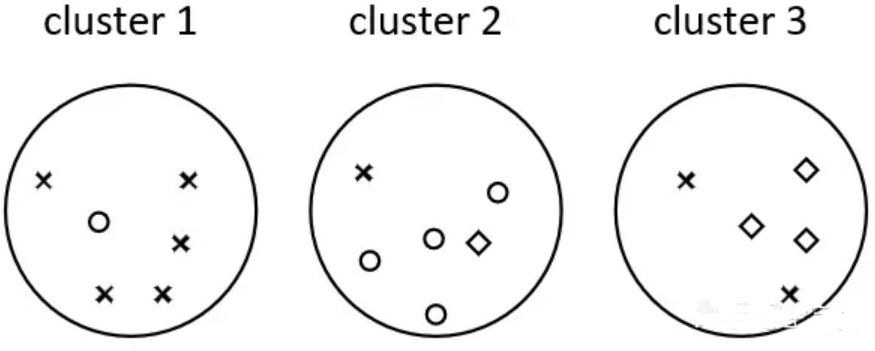
真实的簇如下C1,C2,C3, 样本总数为17.
C1: X 【8个X】
C2:O 【5个O】
C3:◊ 【4个◊】
聚类之后的结果如下: cluster 1 (w1), cluster 2(w2), cluster 3 (w3)

图 1. 文本聚类结果
在聚类结果的评估标准中,一种最简单最直观的方法就是计算它的聚类纯度(purity),别看纯度听起来很陌生,但实际上和分类问题中的准确率有着异曲同工之妙。
因为聚类纯度的总体思想也用聚类正确的样本数除以总的样本数,因此它也经常被称为聚类的准确率。
只是对于聚类后的结果我们并不知道每个簇所对应的真实类别,因此需要取每种情况下的最大值。具体的,纯度的计算公式定义如下:

其中
N表示总的样本数;
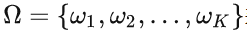
表示一个个聚类后的簇,而

表示正确的类别;wk表示聚类后第k个簇中的所有样本,cj表示第j个类别中真实的样本。在这里P的取值范围为[0,1],越大表示聚类效果越好。
有了公式(1)之后,我们就可以通过它来计算图1中聚类结果的纯度。对于第一个簇来说:

可以看出我们此时假设c1对应的是叉形、c2对应的是圆形、c3对应的是菱形(这个对应顺序没有任何关系)。
因此第一个簇聚类正确的样本数就为5。同理,按照这样的方法可以计算得到第二个簇和第三个簇聚类正确的样本数4和3
。所以,对于图1所示的聚类结果来说,其最终的纯度为:

计算过程:
1)先把 cluster 1 (w1) 和每一个真实的簇(C1,C2,C3)求交集,每一个交集求得一个数量(相同的簇的样本的数量;相同的样本的数量),有三个真实的簇,因此,获得三个数量:5,1,0
k=1,j=1,2,3,
最大值为5
2)把 cluster 2 (w2) 和每一个真实的簇(C1,C2,C3)求交集,每一个交集求得一个数量(相同的簇的样本的数量;相同的样本的数量),有三个真实的簇,因此,获得三个数量:
k=2,j=1,2,3,
w2∩c1= 1 ,w2∩c2= 4 ,w2∩c3=1 ,
最大值为4
3)把 cluster 3 (w3) 和每一个真实的簇(C1,C2,C3)求交集,每一个交集求得一个数量(相同的簇的样本的数量;相同的样本的数量),有三个真实的簇,因此,获得三个数量:
k=3,j=1,2,3,
w3∩c1= 2 ,w3∩c2= 0 ,w3∩c3=3 ,
最大值为3
4)求和:5+4+3=12, 除以N,N为样本总数17. 12/17=0.706
兰德系数
把这三个簇想象成三个黑色的布袋。
那么对于任意一个布袋来说:
①如果你从里面任取两个样本出来均是同一个类别,这就表示这个布袋中的所有样本都算作是聚类正确的;
②相反,如果取出来发现存在两个样本不是同一类别的情况,则就说明存在着聚类错误的情况。
其次,对于任意两个布袋来说:
③如果你任意从两个布袋中各取一个样本发现两者均是不同类别,这就表示两个布袋中的样本都被聚类正确了;
④相反,如果发现取出来的两个样本存在相同的情况,则说明此时也存在着聚类错误的情况。
大家想一想,应该再也找不出第五种情况了。
由此,我们可以做出如下定义:
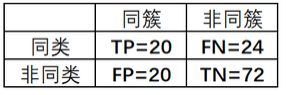
- TP:表示两个同类样本点在同一个簇(布袋)中的情况数量;
- FP:表示两个非同类样本点在同一个簇中的情况数量;
- TN:表示两个非同类样本点分别在两个簇中的情况数量;
- FN:表示两个同类样本点分别在两个簇中的情况数量;
由此,我们便能得到如下所示的对混淆矩阵(Pair Confusion Matrix):

图2 混淆矩阵
在线计算组合数(https://zh.numberempire.com/combinatorialcalculator.php)
TP: cluster 1: X 5取2的组合=10, cluster 2:O 4取2的组合=6, cluster 3: ◊ 3取2的组合=3,X 2取2的组合=1, 10+6+3+1=20
FP:cluster 1: O与X 5 , cluster 2:O与X 4,O与◊ 4,X与◊ 1; cluster 3: X与◊ 6 , 5+4+4+1+6=20
TN:cluster 1与 cluster 2: O与X 1+20,O与◊ 1,X与◊ 5; cluster 1与 cluster 3: O与X 2,O与◊ 3,X与◊ 15 cluster 2与 cluster 3:O与X 8,O与◊ 12,X与◊ 3+2 1+20+1+5+2+3+15+8+12+3+2=72
FN:X: w1与w2 5,w1与w3 10,w2与w3 2 O: w1与w2 4,w1与w3 0,w2与w3 0 ◊: w1与w2 0,w1与w3 0,w2与w3 3 5+10+2+4+3=24
其中图2右边所示的矩阵就是根据图1中的聚类结果计算而来。因此,TP=20的含义就是在所有簇中,任一簇中任取两个样本均是同一类别的情况总数;
TN=72则表示在所有簇中,任两簇中各取一个样本均不是同一类别的情况总数。
有了上面各种情况的统计值,我们就可以定义出兰德系数和F值的计算公式:

从上面的计算公式来看,(3)(4)从形式上看都非常像分类问题中的准确率与F值,但是有着本质的却别。同时,在这里RI和Fb的取值范围均为[0,1],越大表示聚类效果越好。





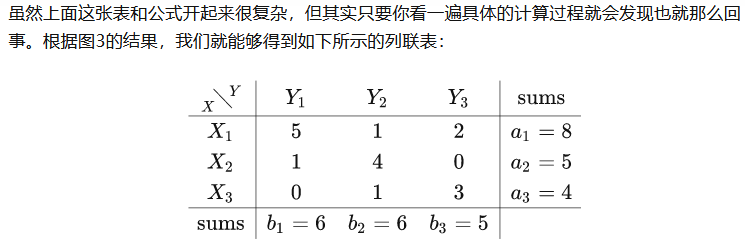


3 实现
3.1 聚类纯度
对于如何实现聚类纯度的代码,其关键就在于:①找到每个聚类标签所对应的真实样本;②统计真实样本中每个类别的样本数,并取最大值。具体代码如下:
def accuracy(labels_true, labels_pred):
clusters = np.unique(labels_pred)
labels_true = np.reshape(labels_true, (-1, 1))
labels_pred = np.reshape(labels_pred, (-1, 1))
count = []
for c in clusters:
idx = np.where(labels_pred == c)[0]
labels_tmp = labels_true[idx, :].reshape(-1)
count.append(np.bincount(labels_tmp).max())
return np.sum(count) / labels_true.shape[0]其中第7行就是用来查找每个聚类标签所对应的真实样本的索引,第8行则是取对应的真实样本;而第9行则是用来计算真实样本中每个类别的样本数并取最大值。
3.2 兰德系数与F值
通过上面的介绍可知,计算兰德系数、F值和调整兰德系统的关键就在于得到这个对混淆矩阵。不过好在sklearn中已经有了现成的方法,我们直接拿过来用就行了。三个指标的实现方法如下:
def get_rand_index_and_f_measure(labels_true, labels_pred, beta=1.):
(tn, fp), (fn, tp) = pair_confusion_matrix(labels_true, labels_pred)
ri = (tp + tn) / (tp + tn + fp + fn)
ari = 2. * (tp * tn - fn * fp) / ((tp + fn) * (fn + tn) + (tp + fp) * (fp + tn))
p, r = tp / (tp + fp), tp / (tp + fn)
f_beta = (1 + beta**2) * (p * r / ((beta ** 2) * p + r))
return ri, ari, f_beta这样,我们根据上述代码就能够计算得到相应的评估指标:
if __name__ == '__main__':
y_pred = [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 2, 2, 2, 2, 2]
y_true = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 2, 2, 2, 2, 0, 0]
purity = accuracy(y_true, y_pred)
ri, ari, f_beta = get_rand_index_and_f_measure(y_true, y_pred, beta=1.)
print(f"purity:{purity}\nri:{ri}\nari:{ari}\nf_measure:{f_beta}")
#
1 purity:0.7058823529411765
2 ri:0.6764705882352942
3 ari:0.242914979757085
4 f_measure:0.47619047619047616
4 总结
在本篇文章中,首先介绍了四种常见的聚类外部评价指标,包括纯度、F值、兰德系数和调整兰德系数;同时还介绍了这四种评价指标的基本原理和详细的计算步骤;最后,还介绍了如何来用代码实现这四种评价指标。在下一篇文章中,将会介绍三种常见的内部评价指标,即在没有标签的情况下如何对聚类结果进行评估。
REF
https://zhuanlan.zhihu.com/p/530944459

 浙公网安备 33010602011771号
浙公网安备 33010602011771号