胶囊网络
https://blog.csdn.net/qq_45549605/article/details/126761439
https://m.thepaper.cn/baijiahao_8690116
https://www.zhihu.com/question/289666926/answer/2954204725
https://zhuanlan.zhihu.com/p/130490034
自从ResNet开始,大家逐渐使用步长为2的卷积层替代Size为2的池化层,二者都是对特征图进行下采样的操作。池化层的主要意义(目前的主流看法,但是有相关论文反驳这个观点)在于invariance(不变性),这个不变性包括平移不变性、尺度不变性、旋转不变形。其过程如下图所示。
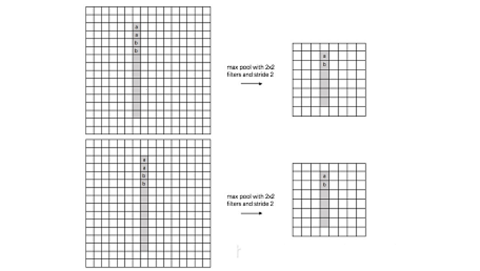
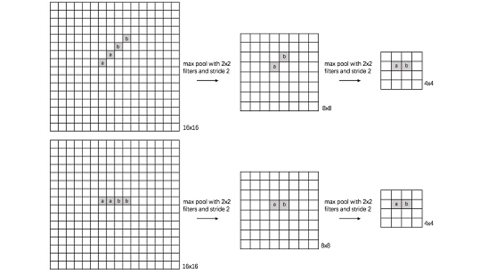

对于池化层和步长为2的卷积层来说,个人的理解是这样的,池化层是一种先验的下采样方式,即人为的确定好下采样的规则;而对于步长为2的卷积层来说,其参数是通过学习得到的,采样的规则是不确定的。下面对两种下采样方式进行一组对比实验,实验设计的可能不够严谨,欢迎大家在评论区讨论。
胶囊网络(学习笔记)
https://www.bilibili.com/video/BV1AK4y1s78Q/?spm_id_from=333.337.search-card.all.click&vd_source=be32c96488b9a4f55329e1fdc525f17e
CNN 模型的提出取得了显著的成果并解决了许多问题,但是它在某些方面还是存在许多缺陷。CNN 最大的缺陷就是它不能从整幅图像和部分图像识别出姿势,纹理和变化。具体来说,由于 CNN 中的池化操作使得模型具有了空间不变性,因此模型就不具备等变(equivariant). 如下图所示,CNN 会把第一和第二幅图都识别为人脸,而把第三幅方向翻转的图识别为不是人脸。另外,池化操作使得特征图丢失了很多信息,它们因此需要更多训练数据来补偿这些损失。就特点上而言,CNN 模型更适合那些像素扰动极大的图像分类,但是对某些不同视角的图像识别能力相对较差。
在 2011 年,Hinton 和他的同事们提出了胶囊网络 (CapsNet) 作为 CNN 模型的替代。胶囊具有等变性并且输入输出都是向量形式的神经元而不是 CNN 模型中的标量值 [1]。胶囊的这种特征表示形式可以允许它识别变化和不同视角。在胶囊网络中,每一个胶囊都由若干神经元组成,而这每个神经元的输出又代表着同一物体的不同属性。这就为识别物体提供了一个巨大的优势,即能通过识别一个物体的部分属性来识别整体。
将传统的网络池化方法,提升为路由一致性算法(胶囊之间的联结),这个方法保留了实体的位置信息(以及其他信息)。
引入路由算法就是想替换CNNs中的池化操作
动态路由算法代替池化操作
链接:https://www.zhihu.com/question/267389576/answer/455840006
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
卷积神经网络有哪些问题
在分类和数据集非常接近的图像时,卷积神经网络的效果非常好,但如果图像存在翻转、倾斜或任何其它方向性问题时,卷积神经网络的表现就比较糟糕了。通过在训练期间为同一图像添加不同的变体可以解决这个问题。在 CNN 中,每个层都以粒度级别或更细小的级别上理解图像。我们用一个例子理解一下,假如你想分类船和马的图像,CNN 的第一层会理解图像的细小边缘和曲线,第二层可能会理解图像中的直线或更细小的形状,比如船的桅杆或马尾的弯曲度,更高的层级开始理解更复杂的形状,比如整个马尾或船体。最后的层会从更整体的层面查看图片是一艘船还是一匹马。我们在每一层后应用池化,以缩短计算时间,但也会造成位置数据丢失。
池化能帮网络具有位置不变性,不然 CNN 会只拟合与训练集非常接近的图像或数据。这种不变性也会触发图像的假阳性——它们包含了船的元素但顺序却不正确。因此系统会让上面右图去匹配上面左图。我们很明显可以看出来两者的差异。
但池化层的真正用途远不止如此,它应当为网络添加位置、方向和属性不变性。但我们应用这些不变性的方法却非常不成熟,在实际中会为网络添加各种位置不变性。这样就导致网络会将检测到的上面右图看作正确的船只。我们需要并非是不变性(invariance)而是同变性(equivariance)。不变性会让CNN忽略视野中的细小变化,而同变性能让CNN理解图像的旋转或属性变化并适应改变,这样图像中的空间位置信息就不会丢失。,如下图所示,即使船变小了,CNN也能缩小尺寸来检测物体。这就引来了本文所说的新进展——胶囊网络。
一、什么是胶囊网络
1.1普通CNN的缺点:CNN在提取特征时只在乎有没有,不在乎他具体的状态是如何的。

上面第一张图片是一个人像,CNN可以正常识别出来;第二张是一个五官错位的图片,CNN仍然将其识别成一张人脸。这是因为CNN是可以识别出人像所具有的具体特征,只要包含这些特征就将其判定为一张人脸。
1.2Hinton自己说过:最大池化层表现的如此优异是一个巨大的错误,是一场灾难。
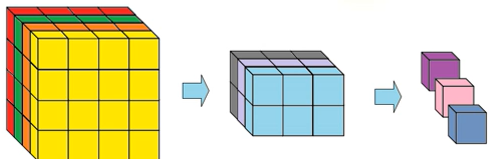
从图中不难看出最大池化将一个4*4的矩阵池化为1*1的,会丢失大量的数据特征。
1.3胶囊网络的改进
1)使用向量代替单个数据,是输入是向量,输出也是向量。
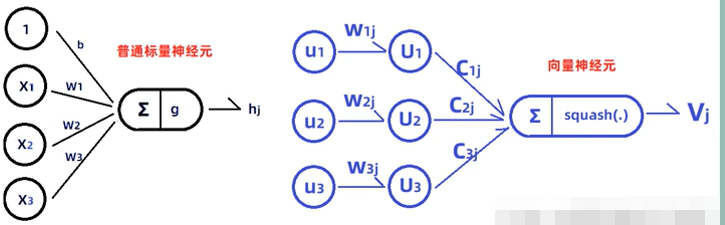
普通CNN输出的是单个数据,丢失了大量的信息;Capsule输出的是一个向量,这个向量是关注数据位置空间信息的。
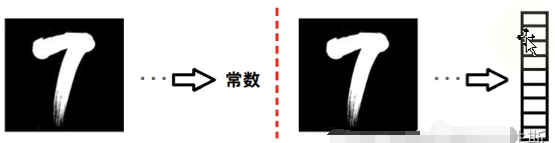
1.4胶囊网络的全貌:
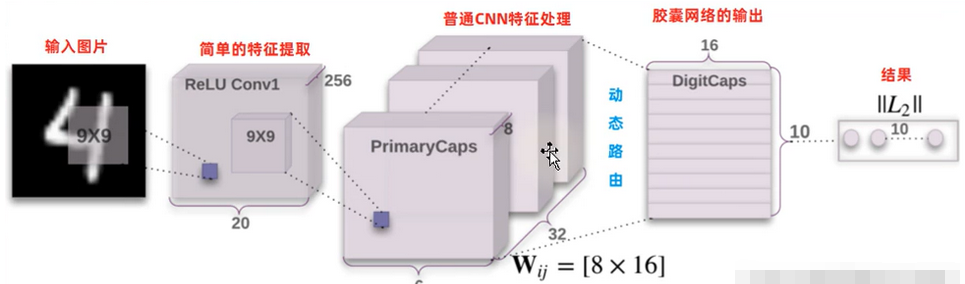
输入一张图片,通过CNN进行简单的特征提取,然后通过8个并行的CNN进行深度的特征提取,在经过胶囊网络的动态路由输出预测结果。

重建过程:提取到特征向量后采用全连接的方式将其恢复为784的向量(因为初始图片是28*28的),然后将其还原为图片。
二、胶囊网络的概览

2.1.初始卷积:就是简单的CNNConv2d以及ReLu。
核心代码:
输入图片形状1*1*28*28(B*C*W*H)
Conv2d的处理参数为in_channels=1,out_channels=256,kernel_size=9*9,stride=1.1
输出:1*256*20*20(N=(W-F+2P)/S+1)
实现了图片------>张量的过程。
2.2.PrimaryCaps网络层:由8个并行的CNN过程,用于更新权重w的。
核心代码:
输入:1*256*20*20
这里是8个并行的Conv2d,步长为2
输出:一个CNN的输出是1*32*6*6,8个并行的输出是1*8*32*6*6---->1*8*1152
实现了普通特征---->深度特征&胶囊预处理的过程
2.3.DigitCaps网络层:数字胶囊层,这一层就是胶囊网络的核心,用于更新权重b。输入的是向量,输出也是向量。
输入:1*8*1152
这一层没有网络,他是一个新的操作,所以他的网络相当于自己手写的
输出:1*10*16*1
然后用Sigmoid()函数将其转化为1*10的预测概率
三、胶囊结构
3.1整体过程
C的求法
更新的原理:
更新过程:
内容取自B站
————————————————
链接:https://blog.csdn.net/qq_45549605/article/details/126761439

 浙公网安备 33010602011771号
浙公网安备 33010602011771号