Informer: 一个基于Transformer的效率优化的长时间序列预测模型
Informer: 一个基于Transformer的效率优化的长时间序列预测模型
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting[1]是来自北航的一项工作,获得了AAAI 2021的Best Paper,恰巧我在工作中也曾涉及过时间序列处理,所以决定拜读下。
背景
时间序列预测(Time-Series Forecasting)任务在工业界应用场景还是挺多的,比如银行的交易量预测、电力系统的用电量预测、云服务的访问量预测,如果能提前预测到未来一段时间内的访问量/用电量,就可以提前进行资源部署,防止访问量过大耗尽现有计算资源,拖垮服务。
当然大家最喜闻乐见的估计还是股票预测。
预测明天一天的访问量并不难,我们可以假设局部平滑,利用今天和前几天的数据就能保证一定的准确性,但是如果要预测未来一个月的访问量,任务的难度就大大不同了。也就是随着预测序列长度增加,预测难度越来越高,本文就是针对长序列预测的,也就是Long sequence time-series forecasting,以下简称LSTF。
LSTF由于预测序列很长,所以模型需要具有较强的解决长距离依赖(long-range dependency)问题的能力,作者想到了最近几年在NLP领域大杀特杀的Transformer模型,在Informer之前,已经有很多工作将Transformer应用到时间序列任务了,作者认为应用Transformer结构,有几个问题需要解决:
- self-attention的时间和空间复杂度都是
- 表示序列长度
- encoder-decoder结构在解码时step-by-step,预测序列越长,预测时间也就越长
针对上面两个问题,Informer在Transformer基础上提出了三点改进:
- 提出了ProbSparse self-attention机制,时间复杂度为
-
- 提出了self-attention蒸馏机制来缩短每一层的输入序列长度,序列长度短了,计算量和存储量自然就下来了
- 提出了生成式的decoder机制,在预测序列(也包括inference阶段)时一步得到结果,而不是step-by-step,直接将预测时间复杂度由
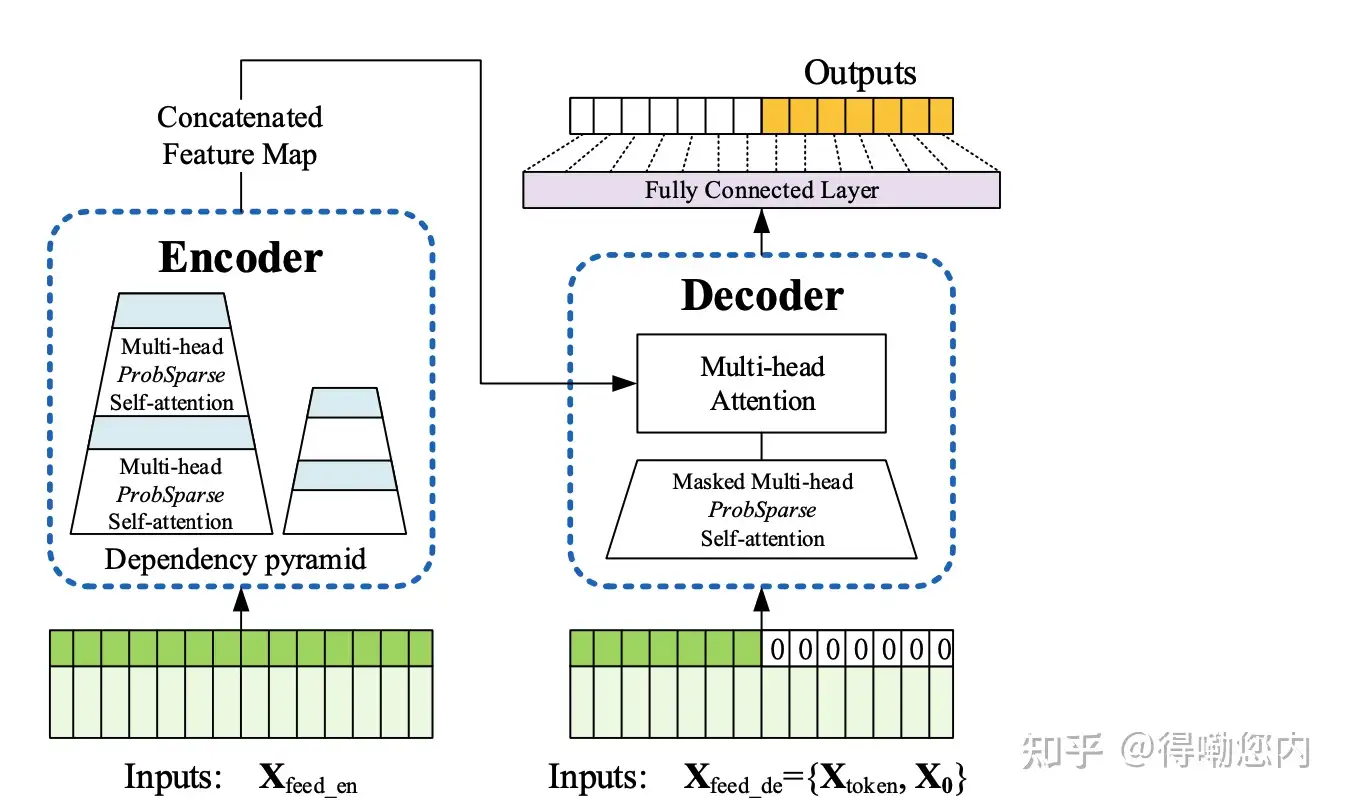
ok,下面让我们看一下这三个创新点是什么意思?
Informer创新点介绍
ProbSparse self-attention
已经有很多的研究工作来优化self-attention的
问题,感兴趣的同学可以读一下20年9月份的一篇综述[2],包含了十几种优化self-attention计算效率的结构:
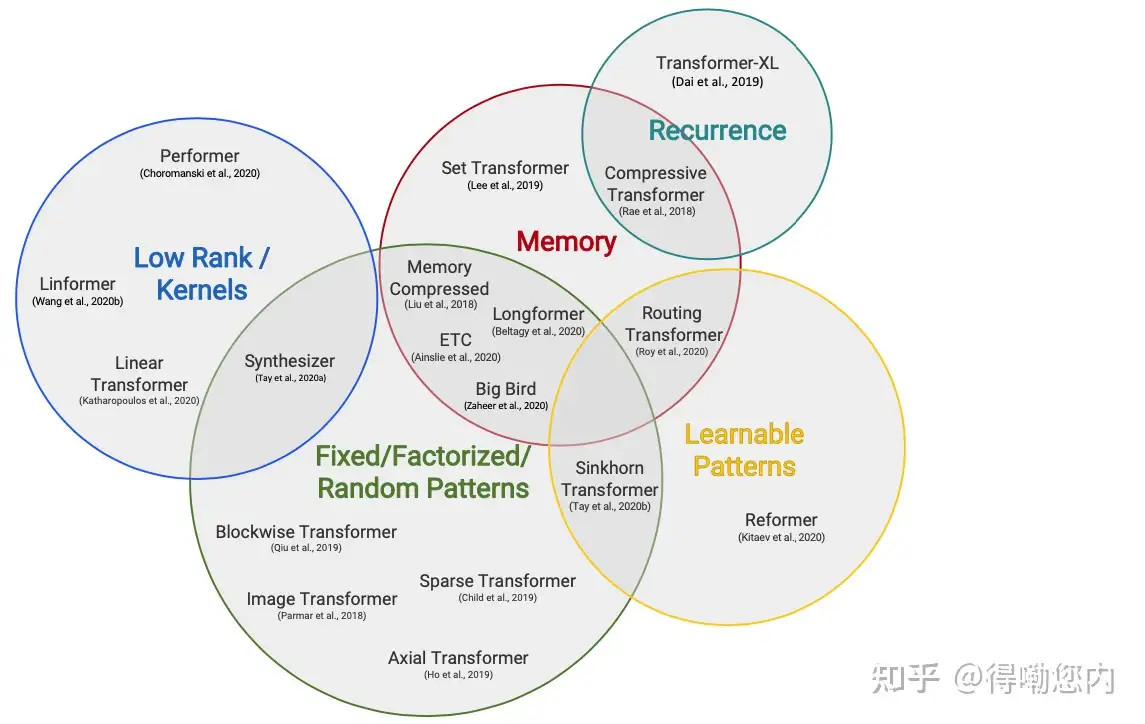
我们来看下Informer中的ProbSparse self-attention是如何优化self-attention的,作者提到,虽然已经有很多优化self-attention的工作,但是他们:
- 缺少理论分析
- 对于multi-head self-attention,每个head都采取相同的优化策略
作者的insight是,如果将self-attention中的点积结果进行可视化分析,会发现服从长尾分布,
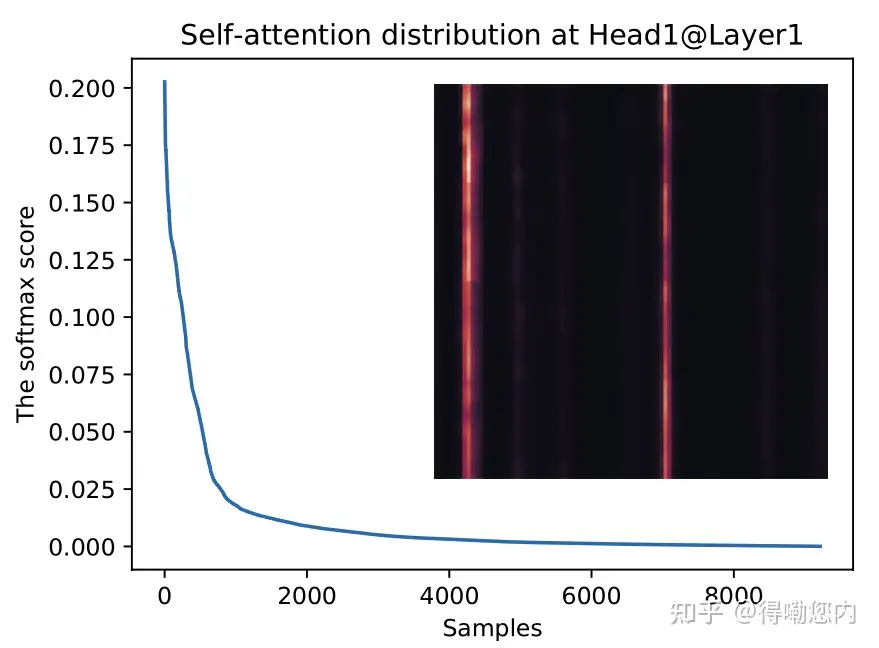
也就是少数的几个query和key的点积计算结果主导了softmax后的分布,这种稀疏性分布是有现实含义的:序列中的某个元素一般只会和少数几个元素具有较高的相似性/关联性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号