informer自定义数据集(时序数据 数据集)
目录
informer相关
模型数据集划分
模型参数
跑通自定义数据集
预测结果可视化
informer相关
论文:https://arxiv.org/abs/2012.07436
感谢论文作者对AI科学做出的贡献,才能像我这种普通人能有机会接触这么nice的文章。作者的github:GitHub - zhouhaoyi/Informer2020: The GitHub repository for the paper "Informer" accepted by AAAI 2021.
模型数据集划分
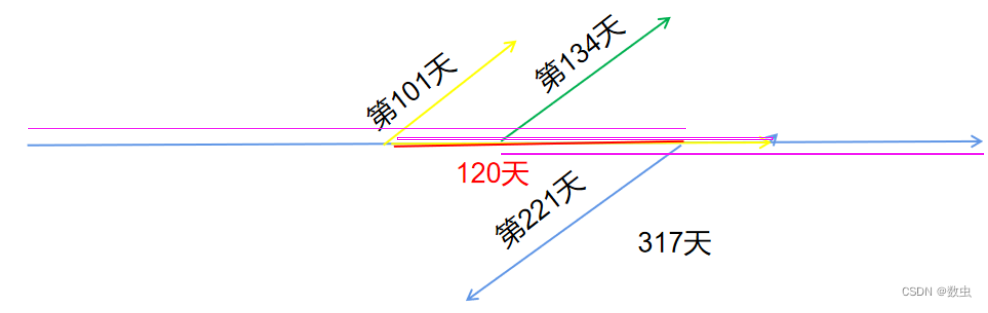
假设数据维度是317天的数据,滑动窗口为120天预测未来20天数据,num_train = 221 , num_test = 63 ,num_vali = 33 , border1s = [0, 101, 134] ,border2s = [221, 254, 317],
训练集数据:0-222天,120天滑动窗口预测未来30天,训练样本数量:222-120-30+1=72条
验证集数据:102天-254天 ,验证集样本数:254-101-120-30+1=4条
测试集数据:134天-317天 ,测试集样本数:317-134-120-30+1=34条
源码中代码部分如下:
# init
assert flag in ['train', 'test', 'val']
type_map = {'train':0, 'val':1, 'test':2}
self.set_type = type_map[flag]
#自定义数据划分训练集、验证集、测试集部分
num_train = int(len(df_raw)*0.7)
num_test = int(len(df_raw)*0.2)
num_vali = len(df_raw) - num_train - num_test
border1s = [0, num_train-self.seq_len, len(df_raw)-num_test-self.seq_len]
border2s = [num_train, num_train+num_vali, len(df_raw)]
border1 = border1s[self.set_type]
border2 = border2s[self.set_type]
模型参数
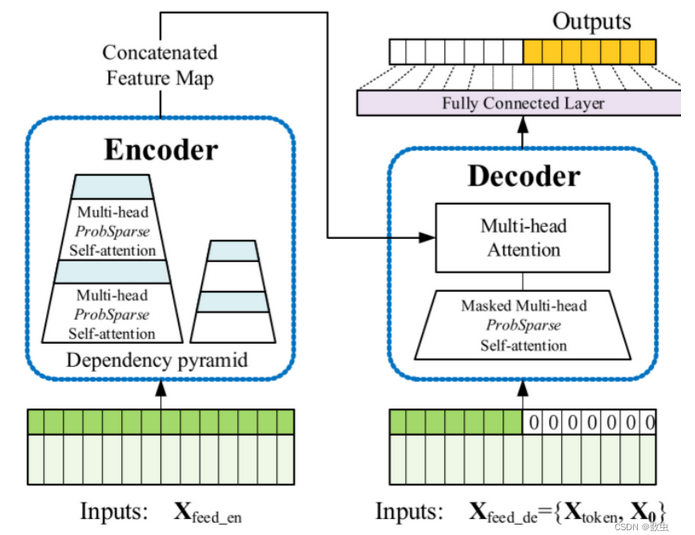
论文中提出的模型的整体框架如下图所示,可以看出提出的Informer模型仍然保存了Encoder-Decoder的架构:
model:可以设置为informer、informersack、informerlight(待定);
data:数据集名称
root_path:数据文件的根路径(默认为./data/ETT/)
data_path:数据文件名(默认为ETTh1.csv)
features:预测任务(默认为M)。这可以设置为M、S、MS(M:多变量预测多变量,S:单变量预测单变量,MS:多变量预报单变量)
target:S或MS任务中的目标目标特征(默认为OT)
freq:用于时间特征编码的freq freq(默认为h)。这可以设置为s,t,h,d,b,w,m(s:秒,t:分钟,h:小时,d:每天,b:工作日,w:每周,m:每月)。
checkpoints:模型保存的位置(默认为./checkpoints/)
seq_len: Informer编码器的输入序列长度(默认为96)
label_len:Informer解码器的起始标记长度(默认为48)
pred_len:预测序列长度(默认为24)
enc_in:编码器输入大小(默认为7)
dec_in:解码器输入大小(默认为7)
c_out:输出大小(默认为7)
d_model:模型的尺寸(默认为512)
n_heads:头数(默认为8)
e_layers:编码器层数(默认为2)
d_layers:解码器层数(默认为1)
s_layers:堆栈编码器层数(默认为3,2,1)
d_ff:全连接层神经元个数(默认为2048)
factor:采样因子数(默认为5)
padding:1D卷积核
distil:是否需要序列长度衰减
dropout:神经网络正则化操作
attn:attention计算方式
embed:时间特征编码方式
activation:激活函数
output_attention:是否输出attention
do_predict:是否需要预测
mix:是否在生成解码器中使用混合注意力,使用此参数意味着不使用混合注意力(默认为True)
cols:数据文件中的某些cols作为输入
itr:试验次数(默认为2)
train_epochs:训练epochs(默认为6)
batch_size:训练输入数据的批量大小(默认为32)
patience:早停策略(默认为3)
learning_rate:优化器学习率(默认为0.0001)
loss:loss计算方式
lradj:学习率衰减参数
use_amp:是否使用自动混合精度训练
inverse:是否反转输出结果
跑通自定义数据集
将自定义数据序列数据集文件夹添加到data文件夹下之后,前往代码修改以下几个地方:
1、自定义数据集的时间列的字段名称 要是“date”;
2、main_informer里面,需要修改、注意的地方如下:
#想要获得最终预测的话这里应该设置为True;否则将是获得一个标准化的预测。
parser.add_argument('--inverse', action='store_true', help='inverse output data', default=True)
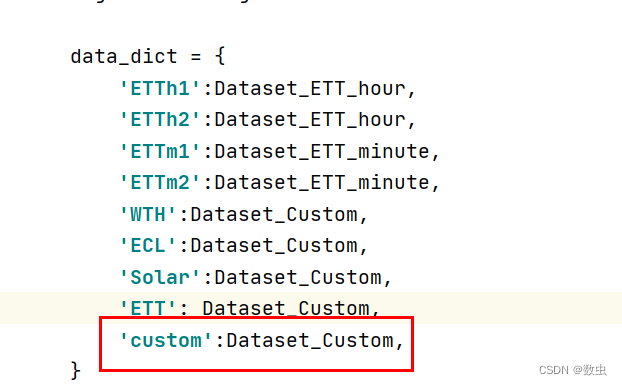
data_parser = {
'ETTh1':{'data':'ETTh1.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]},
'ETTh2':{'data':'ETTh2.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]},
'ETTm1':{'data':'ETTm1.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]},
'ETTm2':{'data':'ETTm2.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]},
'WTH':{'data':'WTH.csv','T':'WetBulbCelsius','M':[12,12,12],'S':[1,1,1],'MS':[12,12,1]},
'ECL':{'data':'ECL.csv','T':'MT_320','M':[321,321,321],'S':[1,1,1],'MS':[321,321,1]},
'Solar':{'data':'solar_AL.csv','T':'POWER_136','M':[137,137,137],'S':[1,1,1],'MS':[137,137,1]},
'custom':{'data':'train.csv','T':'flow','M':[5,5,5],'S':[1,1,1],'MS':[5,5,1]}
}
#'M':[5,5,5],其中5表示输入数据特征有5个
3、exp_informer文件的这里,需要修改、注意的地方如下:
预测结果可视化
1、在不更改任何参数的情况下跑完代码,会在项目文件夹中生成两个子文件夹:checkpoints文件夹中包含训练完成的模型,后缀名为.pth,该模型文件包含完整的模型架构与各层权重,可以通过torch.load函数加载模型
2、results文件夹中包含metrics.npy、pred.npy、true.npy三个文件,pred.npy表示模型预测值,true.npy表示序列真实值
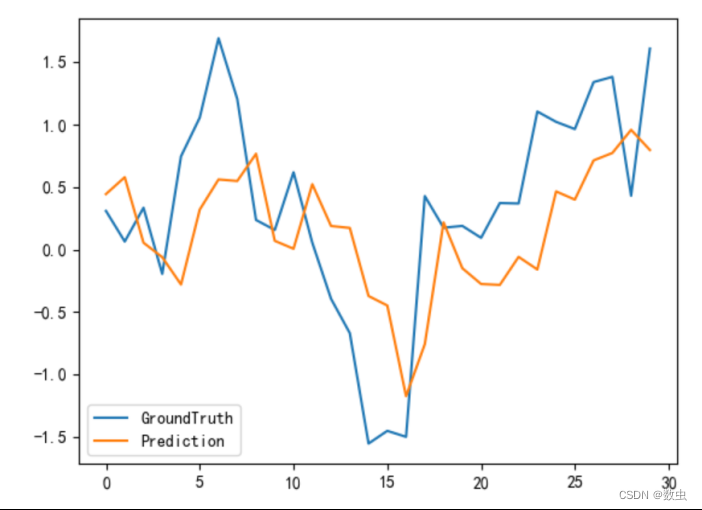
3、pred.npy与true.npy文件作图进行对比,观察模型效果
setting = 'informer_ETT_ftMS_sl120_ll90_pl30_dm256_nh8_el2_dl1_df2048_atprob_fc5_ebtimeF_dtTrue_mxTrue_test_0'
exp = Exp_Informer(args)
exp.predict(setting, True)
preds = np.load('D:Informer2020-main/results/' + setting + '/pred.npy')
trues = np.load('D:Informer2020-main/results/' + setting + '/true.npy')
print(trues.shape)
print(preds.shape)
plt.figure()
plt.plot(trues[0,:,-1].reshape(-1),label='GroundTruth')
plt.plot(preds[0,:,-1].reshape(-1),label='Prediction')
plt.legend()
plt.show()
4、预测结果代码
在pycharm模型训练之前将参数'--do_predict'由'store_true'变为'store_false',这样在代码运行完以后results文件夹中会多出一个文件real_prediction.npy,该文件中即是模型预测的序列值;
#预测结果30天
setting = 'informer_ETT_ftMS_sl120_ll90_pl30_dm256_nh8_el2_dl1_df2048_atprob_fc5_ebtimeF_dtTrue_mxTrue_test_0'
preds = np.load('D:Informer2020-main/results/' + setting + '/real_prediction.npy')
print(preds .shape)
————————————————
链接:https://blog.csdn.net/qq_31807039/article/details/130485293

 浙公网安备 33010602011771号
浙公网安备 33010602011771号