数据集收集
情感/观点/评论 倾向性分析
ChnSentiCorp_htl_all 数据集
数据概览:7000 多条酒店评论数据,5000 多条正向评论,2000 多条负向评论
下载地址:
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/ChnSentiCorp_htl_all/intro.ipynb
waimai_10k 数据集
数据概览:某外卖平台收集的用户评价,正向 4000 条,负向 约 8000 条
下载地址:
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/waimai_10k/intro.ipynb
online_shopping_10_cats 数据集
数据概览:10 个类别,共 6 万多条评论数据,正、负向评论各约 3 万条, 包括书籍、平板、手机、水果、洗发水、热水器、蒙牛、衣服、计算机、酒店
下载地址:
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/online_shopping_10_cats/intro.ipynb
weibo_senti_100k 数据集
数据概览:10 万多条,带情感标注 新浪微博,正负向评论约各 5 万条
下载地址:
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/weibo_senti_100k/intro.ipynb
simplifyweibo_4_moods 数据集
数据概览:36 万多条,带情感标注 新浪微博,包含 4 种情感, 其中喜悦约 20 万条,愤怒、厌恶、低落各约 5 万条
下载地址:
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/simplifyweibo_4_moods/intro.ipynb
dmsc_v2 数据集
数据概览:28 部电影,超 70 万 用户,超 200 万条 评分/评论 数据
下载地址:
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/dmsc_v2/intro.ipynb
yf_dianping 数据集
数据概览:24 万家餐馆,54 万用户,440 万条评论/评分数据
下载地址:
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/yf_dianping/intro.ipynb
yf_amazon 数据集
数据概览:52 万件商品,1100 多个类目,142 万用户,720 万条评论/评分数据
下载地址:
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/yf_amazon/intro.ipynb
Reference
中文自然语言处理 语料/数据集
————————————————
版权声明:本文为CSDN博主「清风醉雨」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Firewall5788/article/details/120497069
=====================================================
Images Analysis 图像分析
| 数据集 | 介绍 | 备注 | 网址 |
|---|---|---|---|
| Flickr30k | 图片描述 | 31,783 images,每张图片5个语句标注 | 传送门 |
| Microsoft COCO | 图片描述 | 330,000 images,每张图片至少5个语句标注 | 传送门 |
| ESP Game | 多标签定义图像 | 20,770 images,268 tags,诸如bed, light man,music | 传送门 |
| IAPRTC-12 | 多标签定义图像 | 19,452 images,291 tags | 传送门 |
| NUS-WIDE | 多标签定义图像 | 269,648 images,several tags (2-5 on average) per image | 传送门 |
| CUHK-PEDES | 以文搜图 | 34,054 images,每张图片2条描述 | 传送门 |
| VRD | 视觉关系检测 | 5,000 images, 100目录,37,993对关系 | 传送门 |
| sVG | 视觉关系检测 | 108,000 images, 998,000对关系 | 传送门 |
| Visual Genome Dataset | 图像属性检测 | 108,077 images, 5.4 M 区域块,2.8 M 属性,2.3 M 关系 | 传送门 |
| VQA | 问答系统 | 1,105,904问题,11,059,040 回答 | 传送门 |
| Visual7W | 问答系统 | 327,939 问答对 | 传送门 |
| TID2013 | 图像质量评价 | 25张参考图像,24个失真类型 | 传送门 |
| CSIQ | 图像质量评价 | 30张参考图像,6个失真类型 | 传送门 |
| LIVE | 图像质量评价 | 29张参考图像,5个失真类型 | 传送门 |
| WATERLOO | 图像质量评价 | 4744张参考图像,20个失真类型 | 传送门 |
| photo .net | 图像美观评价 | 20,278张图像,打分[0,10] | 传送门 |
| DPChallenge .com | 图像美观评价 | 16,509张图像,打分[0,10] | 传送门 |
| CUHK | 图像美观评价 | 28,410张图像,只分高质量和低质量 | 传送门 |
| AVA | 图像美观评价 | 255,500张图像,打分[0,10] | 传送门 |
Image Motion & Tracking 图像运动与跟踪
| 数据集 | 介绍 | 备注 | 网址 |
|---|---|---|---|
| CUHK03 | Person re-identification(人重识别) | image num:13164 person num:1360 camera num:10( 5 pairs) | 传送门 |
| CUHK02 | Person re-identification(人重识别) | image num:7264 person num:1816 camera num:10( 5 pairs) | 传送门 |
| CUHK01 | Person re-identification(人重识别) | image num:3884 person num:971 camera num: 2 | 传送门 |
| VIPeR | Person re-identification(人重识别) | image num:1264 person num:632 camera num:2 | 传送门 |
| ETH1,2,3 | Person re-identification(人重识别) | image num:8580 person num:83,35,28 camera num:1 | 传送门 |
| PRID2011 | Person re-identification(人重识别) | image num:24541 person num:934 camera num:2 | 传送门 |
| MARS | Person re-identification(人重识别) | image num:11910031 person num:1261 camera num:6 | 传送门 |
| Market1501 | Person re-identification(人重识别) | image num:32217 person num:1501 camera num:6 | 传送门 |
| Epic Fail (EF) dataset | Risk Assessment(风险评估) | video num:3000 | 传送门 |
| Street Accident (SA) dataset | Risk Assessment(风险评估) | video num:1733 | 传送门 |
| OTB-50 | visual tracking(跟踪) | video num:50 | 传送门 |
| OTB-100 | visual tracking(跟踪) | video num:100 | 传送门 |
| VOT2015 | visual tracking(跟踪) | video num:60 | 传送门 |
| ALOV300 | visual tracking(跟踪) | video num:314 | 传送门 |
| MOT | visual tracking(跟踪) | video num train:11 test:11 | 传送门 |
| THUMOS | Temporal action localization(动作定位) | video num:~3K activities class:20 instances:~3K | 传送门 |
| ActivityNet | Temporal action localization(动作定位) | video num:20k activities class:200 instances:7.6K | 传送门 |
| Mexaction2 | Temporal action localization(动作定位) | activities class:2 instances:1975 | 传送门 |
| FlyingChairs dataset | optical flow(光流) | image pairs:22k | 传送门 |
| FlyingThings3D | optical flow(光流) | image pairs:22k | 传送门 |
| KITTI benchmark suite | optical flow(光流) | image pairs:1600 | 传送门 |
| MPI Sintel | optical flow(光流) | image pairs:1064 | 传送门 |
Video Analysis & Scene Understanding 影像分析与情景理解
| 数据集 | 介绍 | 备注 | 网址 |
|---|---|---|---|
| UCF101 | 动作行为识别 | 13320 video,101类动作,主要是五大类:1)人-物交互;2)肢体运动;3)人-人交互;4)弹奏乐器;5)运动 | 传送门 |
| HMDB51 | 动作行为识别 | 7000 videos,51类,包括人脸表情动作,身体动作,人与人交互等 | 传送门 |
| Moments-in-Time | 动作行为识别 | 1,000,000 videos,339类 | 传送门 |
| ActivityNet 1.3 | 动作行为识别 | 20,000 videos,200类 | 传送门 |
| Kinetics | 动作行为识别 | 300,000 videos,400类 | 传送门 |
| AVA | 动作行为识别 | 57,600 videos,80类 | 传送门 |
| Collective Activity Dataset | 群体活动行为识别 | 44 videos,穿叉、行走、等待、交谈和排队 五类 | 传送门 |
| Choi’s New Dataset | 群体活动行为识别 | 32 videos,聚会,谈话,分开,一起走,追逐和排队 六类 | None |
| ActivityNet 1.3 | 检测动作事件的起始时间和终止时间 | 20,000 videos,200类动作的起始时间和终止时间 | 传送门 |
| THUMOS | 检测动作事件的起始时间和终止时间 | 15,000 videos,101类动作的起始时间和终止时间 | 传送门 |
| MED | 事件检测 | 32,744 videos,20个事件 | 传送门 |
| EventNet | 事件检测 | 90,000 videos,500个事件 | 传送门 |
| Columbia Consumer Video | 事件检测 | 9,317 videos,20个事件 | 传送门 |
| ADE20K | 事件检测 | 20,210 videos,900个事件 | 传送门 |
| DAVIS | 视频主物体分割 | 50 videos,分割标注 | 传送门 |
| FBMS | 视频主物体分割 | 59 videos,分割标注 | 传送门 |
| IJB-C | 视频人脸识别 | 11,000 videos | 传送门 |
| YouTube Faces | 视频人脸识别 | 3,425 videos,1595 人 | 传送门 |
| MS-Celeb-1M | 视频人脸识别 | 1,000,000 images,21,000人 | 传送门 |
| MSVD | 视频描述 | 1,970 videos | 传送门 |
| MSR-VTT-10K | 视频描述 | 10,000 videos | 传送门 |
3D Computer Vision 3d计算机视觉
| 数据集 | 介绍 | 备注 | 网址 |
|---|---|---|---|
| photoface database | 基于光度立体视觉的二维和三维人脸识别数据库 | 总共7356张图像,包含1839个session和261个subjects | None |
| NYU Depth V2 dataset | 关于RGBD 图像场景理解的数据库 | 提供1449张深度图片和他们的密集2d点类标注 | 传送门 |
| SUN RGBD dataset | 是上面的NYU Depth V2 dataset的超集,多了3D bounding boxes和room layouts的标注。 | 有10,000张RGB-D图片,有58,657个3D包围框和146,617 个2d包围框。 | 传送门 |
| PASCAL3D+ | 新的三维物体检测和姿态估计数据集,从PASCAL VOC 演化而来,包含图像,注解,和3D CAD模型 | 总共12个类,平均每个类别有3000多个实例 | 传送门 |
| IKEA | 包含典型室内场景的三维模型的数据库,例如桌子椅子等 | 包含大约759张图片和219个3D模型 | 传送门 |
| New Tsukuba Dataset | 包含了很多立体物体对的数据库,用于立体物体匹配 | 总共1800个立体物体对,以及每立体对的立体视差图、遮挡图和不连续图 | 传送门 |
| Oxford RobotCar Dataset | 关于户外自动驾驶的数据集。 | 包含在驾驶汽车过程从6个摄像头收集的2000w张图片,和当时的激光雷达,GPS和地面实况标注。 | 传送门 |
| Middlebury V3 | 包含高分辨率物体立体视差标注的数据库 | 包含33个类,没有明说每类有多少数据 | 传送门 |
| ShapeNet | 包含3D模型,和3d模型的类别标注的数据集,覆盖了常用的3D数据集PASCAL 3D+。 | 它涵盖55个常见的对象类别,有大约51,300个3D模型 | 传送门 |
| MICC dataset | 包含了3D人脸扫描和在不同分辨率,条件和缩放级别下的几个视频序列的数据库。 | 有53个人的立体人脸数据 | 传送门 |
| CMU MoCap Dataset | 包含了3D人体关键点标注和骨架移动标注的数据集。 | 有6个类别和23个子类别,总共2605个数据。 | 传送门 |
| DTU dataset | 关于3D场景的数据集。 | 有124个场景,每场景有49/64个位置的RGB图像和结构光标注。 | 传送门 |
Analyzing Humans in Images 人类分析形象化
| 数据集 | 介绍 | 备注 | 网址 |
|---|---|---|---|
| MSR-Action3D | 包含深度的动作识别数据集, 有20个动作, | 总共557个序列。 | 传送门 |
| Florence-3D | 包含深度的动作识别数据集, | 有9个动作,总共215个动作序列。 | 传送门 |
| Berkeley MHAD | 包含深度的动作识别数据集, | 有11个动作,产生660个动作序列。 | 传送门 |
| Online Action Detection | 包含深度的动作识别数据集, | 数据集包含59个长序列,包含10种不同的日常生活行为。 | 传送门 |
| ChaLearn LAP IsoGD Dataset | RGB-D图像的手势识别的数据集。 | 包括47933个RGB-D手势视频,有249个手势标签。Training有35878视频,Validation有5784个,test有6271个 | 传送门 |
| MAFA dataset | 关于面部遮挡问题的数据集 | 有30, 811张人脸和35806张有遮挡的脸组成。 | 传送门 |
| MSRC-12 Kinect Gesture Dataset | 手势识别数据集 | 有4900张图片,包含12个不同手势, | 传送门 |
| 2013 Chalearn Gesture Challenge dataset | 手势识别数据集 | 有11000张图片,包含20个不同手势, | 传送门 |
| WIDER FACE | 人脸检测数据集 | 有 32,203 张图片,标注了393703个人脸。 | 传送门 |
| FDDB | 人脸检测数据集 | 2845张图片,标注了5171张人脸。 | 传送门 |
| 300-VW dataset | 面部表情数据集 | 包含114个视频和总计218,595帧。 | 传送门 |
| HMDB51 | 人类行为识别的数据集 | 包含51个动作,总共有6766个视频剪辑 | 传送门 |
| MPII Cooking Activities Dataset | 人类行为识别的数据集 | 包含65个动作,有5609个视频 | 传送门 |
| UCF101 | 人类行为识别的数据集 | 包含101个动作,有13320个视频 | 传送门 |
| IJB-A dataset | 包含视频和图片人脸识别的数据集 | 包含5712个图像和2085个视频 | 传送门 |
| YouTube celebrities | 视频人脸识别的数据集 | 包含47位名人的1910个视频 | 传送门 |
| COX | 视频人脸识别的数据集 | 包含1000个主题的4000个视频 | 传送门 |
| Human3.6M | 人体姿态估计的数据集 | 360万张3D照片,11名受试者在4个视点下执行15个了不同的动作 | 传送门 |
| iLIDS | 行人重识别的数据集 | 476 张图像,包含119个人 | 传送门 |
| VIPeR | 行人重识别的数据集 | 632个行人图片对(由两个相机拍摄) | 传送门 |
| CUHK01 | 行人重识别的数据集 | 包含971行人, 3884张图片 | 传送门 |
| CUHK03 | 行人重识别的数据集 | 包含1360行人, 13164张图片 | 传送门 |
| RWTH-PHOENIX-Weather multi-signer 2014 | 手语识别的数据集 | 包含了5672个德语手语的句子,有65,227个手语姿势和799,006帧 | 传送门 |
| AFLW | 人类面部关键点的数据集 | 总共约有25k张脸,每幅图像标注了大约21个位置。 | 传送门 |
| CMU mocap database | 动作识别的数据集 | 2235个数据,包含144个不同的动作。 | 传送门 |
| Georgia Tech (GT) database | 人脸识别数据库 | 50个人每人15张人脸。 | 传送门 |
| ORL | 人脸识别数据库 | 40个人每个人10张图。 | 传送门 |
Application 应用
| 数据集 | 介绍 | 备注 | 网址 |
|---|---|---|---|
| DogCentric Activity Dataset | 第一视角的狗和人之间的相互行为的数据集(视频) | 总共有10类,具体数据量没有明说,y是动作类别 | 传送门 |
| JPL First-Person Interaction Dataset | 第一视角观察动作的数据集 | 57个视频,8个大类,y是动作类别 | 传送门 |
| NUS-WIDE | 关于图像文本匹配的数据集 | 269,648个图像和对应的标签 | 传送门 |
| LabelMe Dataset | 关于图像文本匹配的数据集 | 3825个图像和对应标签 | 传送门 |
| Pascal Dataset | 关于图像文本匹配的数据集 | 5011张训练图像和4952张测试图像 | None |
| ICDAR 2015 | 关于文本检测的数据集 | 1500张训练,1000张测试,y为四边形的四个顶点。 | 传送门 |
| COCO-Text | 关于文本检测的数据集 | 63686张图片,其中43686张被选为训练集,剩下的2万用于测试。 | 传送门 |
| MSRA-TD500 | 关于文本检测的数据集 | 300个训练,200个测试图像 | 传送门 |
| Microsoft 7-Scenes Dataset | 室内人体运动的数据集 | 有7种不同室内环境,每包含500-1000张图像视频序列。 | 传送门 |
| Oxford RobotCar | 户外自动驾驶数据集 | 包含图像,激光扫描结果和GPS数据。 | 传送门 |
Low- & Mid-Level Vision 中低水平视觉
| 数据集 | 介绍 | 备注 | 网址 |
|---|---|---|---|
| Deep Video Deblurring for Hand-held Cameras | video/image deblurring(图像去模糊) | video num:71 video time: 3-5s blurry and sharp pair image num:6708 | 传送门 |
| GOPRO dataset | video/image deblurring(图像去模糊) | blurry and sharp pair image num:3214 train num:2103 test num:1111 | 传送门 |
| BSD68 | image restoration(图像修复)/高斯降噪 | image num:68 | 传送门 |
| BSD100 | “image restoration(图像修复)super resolution超分辨率重建” | image num:100 | 传送门 |
| Set5 | “image restoration(图像修复)super resolution超分辨率重建” | image num:5 | 传送门 |
| Set14 | “image restoration(图像修复)super resolution超分辨率重建” | image num:14 | 传送门 |
| Urban100 | “image restoration(图像修复)super resolution超分辨率重建” | image num:100 | 传送门 |
| NYU v2 dataset | “image restoration(图像修复)depth super resolution深度超分辨率重建” | image num:1449 | 传送门 |
| Middlebury dataset | “image restoration(图像修复)depth super resolution深度超分辨率重建” | image pair num: 33 | 传送门 |
| alpha matting benchmark | Natural image matting(抠图) | “train num:27,test num:8” | 传送门 |
| real image benchmark | Natural image matting(抠图) | “train num:49300,test num:1000” | 传送门 |
| MSRA10K/MSRA-B | Image saliency detection(显著性区域检测) | image num(MSRA10K):10000 image num(MSRA-B):5000 | 传送门 |
| ECSSD | Image saliency detection(显著性区域检测) | image num:1000 | 传送门 |
| DUT-OMRON | Image saliency detection(显著性区域检测) | image num:5168 | 传送门 |
| PASCAL-S | Image saliency detection(显著性区域检测) | image num:850 | 传送门 |
| HKU-IS | Image saliency detection(显著性区域检测) | image num:4447 | 传送门 |
| SOD | Image saliency detection(显著性区域检测) | image num:300 | 传送门 |
| Describable Textures Dataset | texture synthesis(纹理合成) | image num:5640 category num:47 split train:val:test = 1:1:1 | 传送门 |
| CVPPP leaf segmentation | Instance segmentation(样例分割) | image num: 161 train num: 128 test num: 33 | 传送门 |
| KITTI car segmentation | Instance segmentation(样例分割) | image num: 3976 train num: 3712 test num: 144 val:120 | 传送门 |
| Cityscapes | Instance segmentation(样例分割) | image num: 5000 train num: 2975 test num: 1525 val:500 | 传送门 |
| SYMMAX | Symmetry Detection(对称性检测) | image num: train:200 test:100 | 传送门 |
| WHSYMMAX | Symmetry Detection(对称性检测) | image num: train:228 test:100 object num: 1 | 传送门 |
| SK506 | Symmetry Detection(对称性检测) | image num: train:300 test:206 object num: 16 | 传送门 |
| Sym-PASCAL | Symmetry Detection(对称性检测) | image num: train:648 test:787 object num: 14 | 传送门 |
| Color Checker Dataset | Color constancy(颜色恒定) | image num: 568 | 传送门 |
| NUS 8-Camera Dataset | Color constancy(颜色恒定) | image num: 1736 | 传送门 |
Text 文本
| 数据集 | 介绍 | 备注 | 网址 |
|---|---|---|---|
| Stanford Sentiment Treebank | 文本情感分析 | 11855个句子划分为239231个短语,每个短语有个概率值,越小越负面,越大越正面 | 传送门 |
| IMDB | 文本情感分析 | 100,000句子,正面负面两类 | 传送门 |
| Yelp | 文本情感分析 | 无 | 传送门 |
| Multi-Domain Sentiment Dataset(Amazon product) | 文本情感分析 | 100,000+句子,正面负面2类或强正面、弱正面、中立、弱负面、强负面5类 | 传送门 |
| SemEval | 文本情感分析 | 20,632句子,三类(正面、负面、中立) | 传送门 |
| Sentiment140(STS) | 文本情感分析 | 1,600,000句子,三类(正面、负面、中立) | 传送门 |
情感/观点/评论 倾向性分析
| 数据集 | 备注 | 网址 |
|---|---|---|
| ChnSentiCorp_htl_all | 7000 多条酒店评论数据,5000 多条正向评论,2000 多条负向评论 | 传送门 |
| waimai_10k | 某外卖平台收集的用户评价,正向 4000 条,负向 约 8000 条 | 传送门 |
| online_shopping_10_cats | 10 个类别,共 6 万多条评论数据,正、负向评论各约 3 万条, 包括书籍、平板、手机、水果、洗发水、热水器、蒙牛、衣服、计算机、酒店 |
传送门 |
| weibo_senti_100k | 10 万多条,带情感标注 新浪微博,正负向评论约各 5 万条 | 传送门 |
| simplifyweibo_4_moods |
36 万多条,带情感标注 新浪微博,包含 4 种情感, 其中喜悦约 20 万条,愤怒、厌恶、低落各约 5 万条 |
传送门 |
| dmsc_v2 | 28 部电影,超 70 万 用户,超 200 万条 评分/评论 数据 |
传送门 |
| yf_dianping | 24 万家餐馆,54 万用户,440 万条评论/评分数据 | 传送门 |
| yf_amazon | 52 万件商品,1100 多个类目,142 万用户,720 万条评论/评分数据 | 传送门 |
更多数据集可前往github搜索“chineseNLP”下载,传送门:
https://github.com/search?utf8=%E2%9C%93&q=chineseNLP&type=
==============================================
自然语言处理
20 newsgroups:分类任务,将出现的单词映射到新闻组 ID。用于文本分类的经典数据集之一,通常可用作纯分类的基准或任何 IR /索引算法的验证。
路透社新闻数据集:(较旧)纯粹基于分类的数据集,包含来自新闻专线的文本。常用于教程。
宾州树库:用于下一个单词或字符预测。
UCI‘s Spambase:来自著名的 UCI 机器学习库的(旧版)经典垃圾邮件数据集。根据数据集的组织细节,可以将它作为学习私人垃圾邮件过滤的基线。
Broadcast News:大型文本数据集,通常用于下一个单词预测。
文本分类数据集:来自 Zhang et al., 2015。用于文本分类的八个数据集合集。这些是用于新文本分类基线的基准。样本大小从 120K 至 3.6M 不等,范围从二进制到 14 个分类问题。数据集来自 DBPedia、亚马逊、Yelp、Yahoo!和 AG。
WikiText:来自维基百科高质量文章的大型语言建模语料库,由 Salesforce MetaMind 策划。
SQuAD:斯坦福问答数据集——应用广泛的问答和阅读理解数据集,其中每个问题的答案都以文本形式呈现。
Billion Words 数据集:一种大型通用语言建模数据集。通常用于训练分布式单词表征,如 word2vec。
Common Crawl:网络的字节级抓取——最常用于学习单词嵌入。可从 Amazon S3 上免费获取。也可以用作网络数据集,因为它可在万维网进行抓取。
NLP Chinese Corpus:大规模中文自然语言处理语料
腾讯中文词NLP数据集:该数据包含800多万中文词汇,其中每个词对应一个200维的向量。相比现有的公开数据集,在覆盖率、新鲜度及准确性上大幅提高。在对话回复质量预测、医疗实体识别等自然语言处理方向的业务应用方面,腾讯内部效果提升显著。
NarrativeQA:DeepMind机器阅读理解数据集,是第一个基于整本书或整个剧本的大规模问答数据集。数据集中该有的所有文档
非正式汉语数据集:收集了3700万条图书评论和5万条bbs回帖,作为大型非正式汉语数据集(LSICC)。内容来源分别是“豆瓣读书”和Chiphell论坛。豆瓣读书评论:Chiphell回帖:
SQuAD:一个最新的阅读理解数据集。该数据集包含 10 万个(问题,原文,答案)三元组,原文来自于 536 篇维基百科文章。
安然数据集:安然集团高级管理层的电子邮件数据。
Google Books Ngram:来自Google书籍的词汇集合。
博客语料库:从blogger.com收集的681,288篇博客文章。每个博客至少包含200个常用的英语单词。
维基百科链接数据(Wikipedia Links data):维基百科全文。该数据集包含来自400多万篇文章,近19亿字。你可以对字、短语或段落本身的一部分进行搜索。
Gutenberg电子图书列表:Project Gutenberg的附加注释的电子书列表。
Hansards加拿大议会的文本块(Hansards text chunks of Canadian Parliament):来自第36届加拿大议会记录的130万对文本。
危险边缘 (Jeopardy):来自问答游戏节目《危险边缘》(Jeopardy) 的超过 20 万个问题的存档。
英文SMS垃圾邮件收集(SMS Spam Collection in English):包含5,574条英文垃圾邮件的数据集。
Yelp评论(Yelp Reviews):Yelp发布的一个开放数据集,包含超过500万次评论。
UCI的垃圾邮件库(UCI’s Spambase):一个大型垃圾邮件数据集,用于垃圾邮件过滤。
亚马逊评论:包含18年来亚马逊上的大约3500万条评论,数据包括产品和用户信息,评级和文本审核。
问答
Maluuba News QA 数据集:CNN 新闻文章中的 12 万个问答对。地址:
Quora 问答对:Quora 发布的第一个数据集,包含重复/语义相似性标签。地址:
CMU Q / A 数据集:手动生成的仿真问/答对,维基百科文章对其难度评分很高。地址:
Maluuba 面向目标的对话:程序性对话数据集,对话旨在完成任务或做出决定。常用于聊天机器人。地址:
bAbi:来自 Facebook AI Research(FAIR)的综合阅读理解和问答数据集。地址:
The Children’s Book Test:Project Gutenberg 提供的儿童图书中提取的(问题+背景、答案)对的基线。用于问答(阅读理解)和仿真查找。地址:
Baby AI Image And Question Dataset:一个问题-图像-答案数据集。
Topical Chat数据集:亚马逊将公布超过最大会话和知识数据集,超410万单词21万句子的语料库将于2019年9月17日发布。主题聊天数据集将包含超过210,000个句子(超过4,100,000个单词),可支持高质量,可重复的研究,将成为研究界公开可用的最大社交对话和知识数据集
数学题海数据集:DeepMind 发布,包含大量不同类型的数学问题(练习题级别),旨在考察模型的数学学习和代数推理能力。包含 200 万(问题答案)对和 10000 个预生成测试样本,问题的长度限制为 160 字符,答案的长度限制为 30 字符。每个问题类型中的训练数据被分为「容易训练」、「中等训练难度」和「较难训练」三个级别。
GQA图像场景图问答数据集:斯坦福大学教授 Christopher Manning 及其学生 Drew Hudson 一同打造的,旨在推动场景理解与视觉问答研究领域的进步。包含高达 20M 的各种日常生活图像,主要源自于 COCO 和 Flickr。每张图像都与图中的物体、属性与关系的场景图(scene graph)相关,创建上基于最新清洁版本的 Visual Genome。此外,每个问题都与其语义的结构化表示相关联,功能程序上指定必须采取一定的推理步骤才能进行回答。
Natural Questions数据集:Google发布一个新的大规模训练和评估开放领域超难问答数据集「自然问题」,能够训练AI阅读维基百科,并找到各种开放领域问题的答案。1、超过30万组问答,其中训练集有307,372组问答,包含152,148组长答案问答和110,724组短答案问答;2、开发示例问答,包含有7830组“一问五答”的问答,也就是同一个问题,找五个人分别从维基百科中寻找答案,以此来衡量QA问答系统的表现;3、测试集有7842组问答。
GQA图像场景图问答数据集 :GQA 是斯坦福大学教授 Christopher Manning 及其学生 Drew Hudson 一同打造的全新图像场景图问答数据集,旨在推动场景理解与视觉问答研究领域的进步。该数据集包含高达 20M 的各种日常生活图像,主要源自于 COCO 和 Flickr。每张图像都与图中的物体、属性与关系的场景图(scene graph)相关,创建上基于最新清洁版本的 Visual Genome。此外,每个问题都与其语义的结构化表示相关联,功能程序上指定必须采取一定的推理步骤才能进行回答。
NLPCC2016KBQA数据集:基于知识图谱的问答系统,其包含 14,609 个问答对的训练集和包含 9870 个问答对的测试集。并提供一个知识库,包含 6,502,738 个实体、 587,875 个属性以及 43,063,796 个三元组。知识库文件中每行存储一个事实(fact),即三元组 ( 实体、属性、属性值) 。原数据中本只有问答对(question-answer),并无标注三元组(triple),本人所用问答对数据来自该比赛第一名的预处理。
HotpotQA:面向自然语言和多步推理问题,新型问答数据集,具有自然、多跳问题的问答数据集,具有支持事实的强大监督,以实现更易于解释的问答系统。
CoQA:斯坦福最新问答数据集,囊括来自 7 个不同领域的文本段落里 8000 个对话中的 127,000 轮问答。
推荐系统
Amazon Co-Purchasing:亚马逊评论从「购买此产品的用户也购买了……」这一部分抓取数据,以及亚马逊相关产品的评论数据。适合在网络中试行推荐系统。
Friendster 社交网络数据集:在变成游戏网站之前,Friendster 以朋友列表的形式为 103,750,348 名用户发布了匿名数据。
Movielens:来自 Movielens 网站的电影评分数据集,各类大小都有。
Million Song 数据集:Kaggle 上元数据丰富的大型开源数据集,可以帮助人们使用混合推荐系统。
Last.fm:音乐推荐数据集,可访问深层社交网络和其它可用于混合系统的元数据。
Book-Crossing 数据集:来自 Book-Crossing 社区。包含 278,858 位用户提供的约 271,379 本书的 1,149,780 个评分。
Jester:来自 73,421 名用户对 100 个笑话的 410 万个连续评分(分数从-10 至 10)。
Netflix Prize:Netflix 发布了他们的电影评级数据集的匿名版;包含 480,000 名用户对 17,770 部电影的 1 亿个评分。首个主要的 Kaggle 风格数据挑战。随着隐私问题的出现,只能提供非正式版。
yf_amazon 数据集:52 万件商品,1100 多个类目,142 万用户,720 万条评论/评分数据
yf_dianping 数据集:24 万家餐馆,54 万用户,440 万条评论/评分数据
dmsc_v2 数据集:28 部电影,超 70 万 用户,超 200 万条 评分/评论 数据
ez_douban 数据集:5 万多部电影(3 万多有电影名称,2 万多没有电影名称),2.8 万 用户,280 万条评分数据
亚马逊评论:3500万条来自亚马逊的评论,时间长度为18年。数据包括产品和用户信息、评级等。
情感/观点/评论 倾向性分析
多领域情绪分析数据集:较旧的学术数据集。
IMDB:用于二元情感分类的较旧、较小数据集。对文献中的基准测试无法支持更大的数据集。
Stanford Sentiment Treebank:标准情感数据集,在每个句子解析树的每个节点都有细粒度的情感注释。
yf_amazon 数据集:52 万件商品,1100 多个类目,142 万用户,720 万条评论/评分数据
yf_dianping 数据集:24 万家餐馆,54 万用户,440 万条评论/评分数据
dmsc_v2 数据集:28 部电影,超 70 万 用户,超 200 万条 评分/评论 数据
simplifyweibo_4_moods 数据集:36 万多条,带情感标注 新浪微博,包含 4 种情感, 其中喜悦约 20 万条,愤怒、厌恶、低落各约 5 万条
weibo_senti_100k 数据集:10 万多条,带情感标注 新浪微博,正负向评论约各 5 万条
online_shopping_10_cats 数据集:10 个类别,共 6 万多条评论数据,正、负向评论各约 3 万条, 包括书籍、平板、手机、水果、洗发水、热水器、蒙牛、衣服、计算机、酒店
waimai_10k 数据集:某外卖平台收集的用户评价,正向 4000 条,负向 约 8000 条
ChnSentiCorp_htl_all 数据集:7000 多条酒店评论数据,5000 多条正向评论,2000 多条负向评论
多域情感分析数据集(Multidomain sentiment analysis dataset):一个比较有历史的数据集,里面还有一些来自亚马逊的产品评论。
IMDB评论: 影评,也是比较有历史的二元情绪分类数据集、数据规模相对较小,里面有 25,000 条电影评论。
斯坦福情感树银行(Stanford Sentiment Treebank):带有情感注释的标准情绪数据集。
Sentiment140:一个流行的数据集,它使用16万条推文,并把表情等等符号剔除了。
Twitter 美国航空公司情绪数据集 (Twitter US Airline Sentiment):自 2015 年 2 月以来美国航空公司的 Twitter 数据,分类为正面、负面和中性推文。
中文命名实体识别
dh_msra 数据集:5 万多条中文命名实体识别标注数据(包括地点、机构、人物)
————————————————
版权声明:本文为CSDN博主「守望者白狼」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_44356285/article/details/86421494
=========================================
1.THUCNews数据集:
THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。我们在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。使用THUCTC工具包在此数据集上进行评测,准确率可以达到88.6%。
数据集地址: http://thuctc.thunlp.org/
2.今日头条新闻文本分类数据集:
数据来源:今日头条客户端 数据规模:共382688条,分布于15个分类中。 数据格式:6552431613437805063_!_102_!_news_entertainment_!_谢娜为李浩菲澄清网络谣言,之后她的两个行为给自己加分_!_佟丽娅,网络谣言,快乐大本营,李浩菲,谢娜,观众们
每行为一条数据,以_!_分割的个字段,从前往后分别是 新闻ID,分类code(见下文),分类名称(见下文),新闻字符串(仅含标题),新闻关键词
数据集地址:https://github.com/fate233/toutiao-text-classfication-dataset
3.全网新闻数据(SogouCA):
来自若干新闻站点2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻数据,提供URL和正文信息
数据格式为
<doc>
<url>页面URL</url>
<docno>页面ID</docno>
<contenttitle>页面标题</contenttitle>
<content>页面内容</content>
</doc>注意:content字段去除了HTML标签,保存的是新闻正文文本
数据集地址: https://www.sogou.com/labs/resource/ca.php
4.搜狐新闻数据(SogouCS):
来自搜狐新闻2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻数据,提供URL和正文信息
数据格式为
<doc>
<url>页面URL</url>
<docno>页面ID</docno>
<contenttitle>页面标题</contenttitle>
<content>页面内容</content>
</doc>注意:content字段去除了HTML标签,保存的是新闻正文文本
数据集地址: https://www.sogou.com/labs/resource/cs.php
5.ChnSentiCorp_htl_all数据集:
7000 多条酒店评论数据,5000 多条正向评论,2000 多条负向评论
数据字段:
Label:1表示正向评论,0表示负向评论
Review:评论内容

6.waimai_10k数据集:
某外卖平台收集的用户评价,正向4000 条,负向约 8000 条
数据字段:
Label:1表示正向评论,0表示负向评论
Review:评论内容
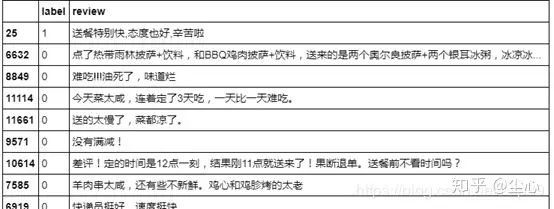
7.online_shopping_10_cats数据集:
10 个类别(书籍、平板、手机、水果、洗发水、热水器、蒙牛、衣服、计算机、酒店),共 6 万多条评论数据,正、负向评论各约 3 万条


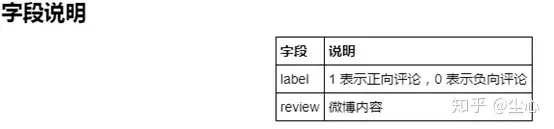
8.weibo_senti_100k数据集:
10 万多条,带情感标注 新浪微博,正负向评论约各 5 万条。

数据集下载地址: https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/weibo_senti_100k/intro.ipynb
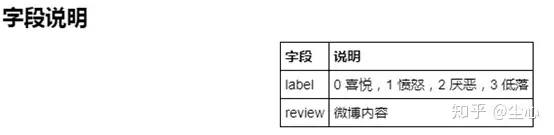
9.simplifyweibo_4_moods数据集:
36 万多条,带情感标注 新浪微博,包含 4 种情感,其中喜悦约 20 万条,愤怒、厌恶、低落各约 5 万条

数据集下载地址: https://pan.baidu.com/s/16c93E5x373nsGozyWevITg
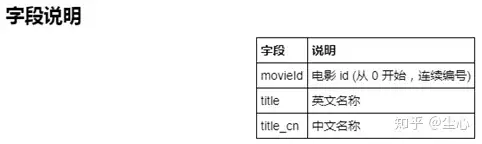
10.dmsc_v2数据集:
28部电影,超70万用户,超200万条评分/评论数据
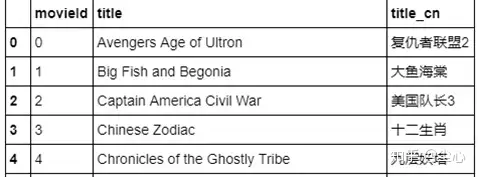
数据集地址:https://pan.baidu.com/s/1c0yn3TlkzHYTdEBz3T5arA
原始数据集地址:https://www.kaggle.com/utmhikari/doubanmovieshortcomments
11.yf_dianping数据集:
24 万家餐馆,54 万用户,440 万条评论/评分数据

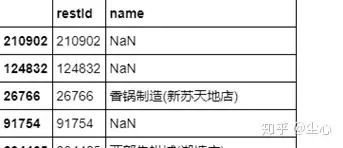
数据集地址:https://pan.baidu.com/s/1yMNvHLl6QYsGbjT7u51Nfg 原始数据集地址:http://yongfeng.me/dataset/
12.yf_amazon数据集:
52 万件商品,1100 多个类目,142 万用户,720 万条评论/评分数据


原始数据集地址:http://yongfeng.me/dataset/ 数据集地址:https://pan.baidu.com/s/1SbfpZb5cm-g2LmnYV_af8Q
13.Datahub数据中心:
包含文本分类、情感分析以及知识图谱的数据集
相关地址:http://www.datahub.ileadall42.com/data/list?category=2&parent_category=1
14.知乎看山杯数据集:
数据集下载地址:https://pan.baidu.com/s/1qUr6IQQn6DzrMlbaAUZslQ 提取码: qbiw
15.AI_challenger情感分析数据集:
数据集分为训练、验证、测试A与测试B四部分。数据集中的评价对象按照粒度不同划分为两个层次,层次一为粗粒度的评价对象,例如评论文本中涉及的服务、位置等要素;层次二为细粒度的情感对象,例如“服务”属性中的“服务人员态度”、“排队等候时间”等细粒度要素。
数据集下载地址:https://github.com/nju161250102/AI_challenger/tree/master/data
16.复旦中文文本分类语料库
数据链接:https://pan.baidu.com/s/1833mT2rhL6gBMlM0KnmyKg 密码:zyxa
===================================================

 浙公网安备 33010602011771号
浙公网安备 33010602011771号