Chinese-Text-Classification-PyTorch
Chinese-Text-Classification
Github项目地址:
https://github.com/JackHCC/Chinese-Text-Classification-PyTorch
作者:JackHCC
链接:https://www.jianshu.com/p/9438fd0fea8c
https://www.jianshu.com/p/9438fd0fea8c
中文文本分类,基于pytorch,开箱即用。
-
神经网络模型:TextCNN,TextRNN,FastText,TextRCNN,BiLSTM_Attention, DPCNN, Transformer
-
预训练模型:Bert,ERNIE
模型介绍、数据流动过程:参考
数据以字为单位输入模型,预训练词向量使用 搜狗新闻 Word+Character 300d,点这里下载
| 模型 | 介绍 |
|---|---|
| TextCNN | Kim 2014 经典的CNN文本分类 |
| TextRNN | BiLSTM |
| TextRNN_Att | BiLSTM+Attention |
| TextRCNN | BiLSTM+池化 |
| FastText | bow+bigram+trigram, 效果出奇的好 |
| DPCNN | 深层金字塔CNN |
| Transformer | 效果较差 |
预训练模型
| 模型 | 介绍 | 备注 |
|---|---|---|
| bert | 原始的bert | |
| ERNIE | ERNIE | |
| bert_CNN | bert作为Embedding层,接入三种卷积核的CNN | bert + CNN |
| bert_RNN | bert作为Embedding层,接入LSTM | bert + RNN |
| bert_RCNN | bert作为Embedding层,通过LSTM与bert输出拼接,经过一层最大池化层 | bert + RCNN |
| bert_DPCNN | bert作为Embedding层,经过一个包含三个不同卷积特征提取器的region embedding层,可以看作输出的是embedding,然后经过两层的等长卷积来为接下来的特征抽取提供更宽的感受眼,(提高embdding的丰富性),然后会重复通过一个1/2池化的残差块,1/2池化不断提高词位的语义,其中固定了feature_maps,残差网络的引入是为了解决在训练的过程中梯度消失和梯度爆炸的问题。 | bert + DPCNN |
环境
python 3.7pytorch 1.1
tqdm
sklearn
tensorboardX
中文数据集
我从THUCNews中抽取了20万条新闻标题,已上传至github,文本长度在20到30之间。一共10个类别,每类2万条。数据以字为单位输入模型。
类别:财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐。
数据集划分:
| 数据集 | 数据量 |
|---|---|
| 训练集 | 18万 |
| 验证集 | 1万 |
| 测试集 | 1万 |
更换数据集
- 按照THUCNews数据集的格式来格式化自己的中文数据集。
- 对于神经网络模型:
- 如果用字,按照数据集的格式来格式化你的数据。
- 如果用词,提前分好词,词之间用空格隔开,
python run.py --model TextCNN --word True - 使用预训练词向量:utils.py的main函数可以提取词表对应的预训练词向量。
实验效果
机器:一块2080Ti , 训练时间:30分钟。
| 模型 | acc | 备注 |
|---|---|---|
| TextCNN | 91.22% | Kim 2014 经典的CNN文本分类 |
| TextRNN | 91.12% | BiLSTM |
| TextRNN_Att | 90.90% | BiLSTM+Attention |
| TextRCNN | 91.54% | BiLSTM+池化 |
| FastText | 92.23% | bow+bigram+trigram, 效果出奇的好 |
| DPCNN | 91.25% | 深层金字塔CNN |
| Transformer | 89.91% | 效果较差 |
| bert | 94.83% | 单纯的bert |
| ERNIE | 94.61% | 说好的中文碾压bert呢 |
| bert_CNN | 94.44% | bert + CNN |
| bert_RNN | 94.57% | bert + RNN |
| bert_RCNN | 94.51% | bert + RCNN |
| bert_DPCNN | 94.47% | bert + DPCNN |
原始的bert效果就很好了,把bert当作embedding层送入其它模型,效果反而降了,之后会尝试长文本的效果对比。
预训练语言模型
bert模型放在 bert_pretain目录下,ERNIE模型放在ERNIE_pretrain目录下,每个目录下都是三个文件:
- pytorch_model.bin 模型
- bert_config.json 配置
- vocab.txt 词表
预训练模型下载地址:
bert_Chinese: 模型 https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese.tar.gz
词表 https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-vocab.txt
来自这里
备用:模型的网盘地址:https://pan.baidu.com/s/1qSAD5gwClq7xlgzl_4W3Pw
ERNIE_Chinese: https://pan.baidu.com/s/1lEPdDN1-YQJmKEd_g9rLgw
来自这里
解压后,按照上面说的放在对应目录下,文件名称确认无误即可。
神经网络方法
# 训练并测试,训练模型+验证+测试:
# TextCNN
python run.py --model TextCNN
# TextRNN
python run.py --model TextRNN
# TextRNN_Att
python run.py --model TextRNN_Att
# TextRCNN
python run.py --model TextRCNN
# FastText, embedding层是随机初始化的
python run.py --model FastText --embedding random
# DPCNN
python run.py --model DPCNN
# Transformer
python run.py --model Transformer
预训练方法
下载好预训练模型(三个文件,模型,配置,词表)就可以跑了:
# 预训练模型训练并测试:
# bert
python pretrain_run.py --model bert
# bert + 其它
python pretrain_run.py --model bert_CNN
# ERNIE
python pretrain_run.py --model ERNIE
预测
预训练模型:
python pretrain_predict.py
神经网络模型:
python predict.py
参数
模型都在models目录下,超参定义和模型定义在同一文件中。
======================
使用记录:
pip install tensorboardX -i https://pypi.douban.com/simple/
pip list
run.py
parser.add_argument('--model', type=str, required=True, default="TextCNN", help='choose a model: TextCNN, TextRNN, FastText, TextRCNN, TextRNN_Att, DPCNN, Transformer')
parser.add_argument('--model', type=str, default='TextCNN', help='choose a model: TextCNN, TextRNN, FastText, TextRCNN, TextRNN_Att, DPCNN, Transformer')
运行结果:
E:\Eprogramfiles\Anaconda3\python.exe E:/other/lightvit/Chinese-Text-Classification-PyTorch/run.py
Microsoft Visual C++ Redistributable is not installed, this may lead to the DLL load failure.
It can be downloaded at https://aka.ms/vs/16/release/vc_redist.x64.exe
Loading data...
0it [00:00, ?it/s]Vocab size: 4762
26612it [00:00, 83118.42it/s]
10000it [00:00, 92071.41it/s]
10000it [00:00, 66401.82it/s]
Time usage: 0:00:01
<bound method Module.parameters of Model(
(embedding): Embedding(4762, 300)
(convs): ModuleList(
(0): Conv2d(1, 256, kernel_size=(2, 300), stride=(1, 1))
(1): Conv2d(1, 256, kernel_size=(3, 300), stride=(1, 1))
(2): Conv2d(1, 256, kernel_size=(4, 300), stride=(1, 1))
)
(dropout): Dropout(p=0.5, inplace=False)
(fc): Linear(in_features=768, out_features=10, bias=True)
)>
Epoch [1/20]
Iter: 0, Train Loss: 2.3, Train Acc: 12.50%, Val Loss: 2.6, Val Acc: 11.05%, Time: 0:00:06 *
Iter: 100, Train Loss: 0.73, Train Acc: 73.44%, Val Loss: 0.69, Val Acc: 78.57%, Time: 0:00:32 *
Iter: 200, Train Loss: 0.68, Train Acc: 79.69%, Val Loss: 0.55, Val Acc: 83.12%, Time: 0:00:59 *
Epoch [2/20]
Iter: 300, Train Loss: 0.41, Train Acc: 88.28%, Val Loss: 0.5, Val Acc: 84.09%, Time: 0:01:27 *
Iter: 400, Train Loss: 0.55, Train Acc: 83.59%, Val Loss: 0.47, Val Acc: 85.14%, Time: 0:01:54 *
Epoch [3/20]
Iter: 500, Train Loss: 0.45, Train Acc: 83.59%, Val Loss: 0.45, Val Acc: 86.11%, Time: 0:02:22 *
Iter: 600, Train Loss: 0.43, Train Acc: 88.28%, Val Loss: 0.45, Val Acc: 86.16%, Time: 0:02:50
Epoch [4/20]
Iter: 700, Train Loss: 0.19, Train Acc: 93.75%, Val Loss: 0.46, Val Acc: 85.80%, Time: 0:03:17
Iter: 800, Train Loss: 0.2, Train Acc: 94.53%, Val Loss: 0.44, Val Acc: 86.71%, Time: 0:03:53 *
Epoch [5/20]
Iter: 900, Train Loss: 0.17, Train Acc: 96.09%, Val Loss: 0.47, Val Acc: 86.17%, Time: 0:04:25
Iter: 1000, Train Loss: 0.17, Train Acc: 96.09%, Val Loss: 0.49, Val Acc: 85.89%, Time: 0:04:54
Epoch [6/20]
Iter: 1100, Train Loss: 0.12, Train Acc: 97.66%, Val Loss: 0.47, Val Acc: 86.29%, Time: 0:05:22
Iter: 1200, Train Loss: 0.092, Train Acc: 97.66%, Val Loss: 0.47, Val Acc: 86.80%, Time: 0:05:52
Epoch [7/20]
Iter: 1300, Train Loss: 0.075, Train Acc: 98.44%, Val Loss: 0.47, Val Acc: 86.43%, Time: 0:06:21
Iter: 1400, Train Loss: 0.051, Train Acc: 99.22%, Val Loss: 0.5, Val Acc: 86.38%, Time: 0:06:49
Epoch [8/20]
Iter: 1500, Train Loss: 0.065, Train Acc: 97.66%, Val Loss: 0.5, Val Acc: 86.47%, Time: 0:07:19
Iter: 1600, Train Loss: 0.043, Train Acc: 99.22%, Val Loss: 0.54, Val Acc: 86.24%, Time: 0:07:47
Epoch [9/20]
Iter: 1700, Train Loss: 0.039, Train Acc: 99.22%, Val Loss: 0.52, Val Acc: 86.78%, Time: 0:08:17
Iter: 1800, Train Loss: 0.04, Train Acc: 99.22%, Val Loss: 0.56, Val Acc: 86.25%, Time: 0:08:45
No optimization for a long time, auto-stopping...
Test Loss: 0.42, Test Acc: 87.18%
Precision, Recall and F1-Score...
precision recall f1-score support
finance 0.8907 0.8560 0.8730 1000
realty 0.9063 0.8900 0.8981 1000
stocks 0.8373 0.7720 0.8033 1000
education 0.9414 0.9310 0.9361 1000
science 0.7986 0.8090 0.8038 1000
society 0.8718 0.8980 0.8847 1000
politics 0.8253 0.8740 0.8490 1000
sports 0.8861 0.9410 0.9127 1000
game 0.9092 0.8510 0.8791 1000
entertainment 0.8566 0.8960 0.8759 1000
accuracy 0.8718 10000
macro avg 0.8723 0.8718 0.8716 10000
weighted avg 0.8723 0.8718 0.8716 10000
Confusion Matrix...
[[856 19 55 1 17 13 17 16 1 5]
[ 13 890 20 1 16 16 14 8 3 19]
[ 63 28 772 8 53 4 48 6 10 8]
[ 0 3 3 931 10 15 10 11 3 14]
[ 7 8 37 6 809 20 44 10 36 23]
[ 4 17 3 20 9 898 27 5 5 12]
[ 12 9 21 7 16 36 874 7 4 14]
[ 2 1 1 2 6 8 7 941 3 29]
[ 1 1 9 4 66 9 8 25 851 26]
[ 3 6 1 9 11 11 10 33 20 896]]
Time usage: 0:00:06
Process finished with exit code 0
=======================================================
{
"attention_probs_dropout_prob": 0.1, #乘法attention时,softmax后dropout概率
"hidden_act": "gelu", #激活函数
"hidden_dropout_prob": 0.1, #隐藏层dropout概率
"hidden_size": 768, #隐藏单元数
"initializer_range": 0.02, #初始化范围
"intermediate_size": 3072, #升维维度
"max_position_embeddings": 512,#一个大于seq_length的参数,用于生成position_embedding
"num_attention_heads": 12, #每个隐藏层中的attention head数
"num_hidden_layers": 12, #隐藏层数
"type_vocab_size": 2, #segment_ids类别 [0,1]
"vocab_size": 30522 #词典中词数
}
=======================================================
vocab_size:词表大小
hidden_size:隐藏层神经元数,可以理解为dmodel,即单个Transformer block第一层(输入层后面链接的层)和最后一层(输出层)的节点数,对应于论文中的H
num_hidden_layers:Transformer 的层数,对应于论文中的L
num_attention_heads:multi-head attention 的 head 数,对应于论文中的A
intermediate_size:encoder 的“中间”隐层神经元数(例如 feed-forward layer),对应于论文中的4H。
hidden_act:隐藏层激活函数
hidden_dropout_prob:隐层 dropout 率
attention_probs_dropout_prob:注意力部分的 dropout
max_position_embeddings:最大位置编码
type_vocab_size:token_type_ids 的词典大小
initializer_range:truncated_normal_initializer 初始化方法的 stdev
这里要注意一点,可能刚看的时候对type_vocab_size这个参数会有点不理解,其实就是在next sentence prediction任务里的Segment A和 Segment B。在下载的bert_config.json文件里也有说明,默认值应该为 2。
=======================================================
预训练模型
由于从头开始(from scratch)训练需要巨大的计算资源,因此Google提供了预训练的模型(的checkpoint),目前包括英语、汉语和多语言3类模型:
BERT-Base, Uncased:12层,768隐藏,12头,110M参数
BERT-Large, Uncased:24层,1024个隐藏,16个头,340M参数
BERT-Base, Cased:12层,768隐藏,12头,110M参数
BERT-Large, Cased:24层,1024个隐藏,16个头,340M参数
BERT-Base, Multilingual Cased (New, recommended):104种语言,12层,768隐藏,12头,110M参数
BERT-Base, Multilingual Uncased (Orig, not recommended) (不推荐使用,Multilingual Cased代替使用):102种语言,12层,768隐藏,12头,110M参数
BERT-Base, Chinese:中文简体和繁体,12层,768隐藏,12头,110M参数
Uncased的意思是在预处理的时候都变成了小写,而cased是保留大小写。
这么多版本应该如何选择呢?
如果我们处理的问题只包含英文,那么我们应该选择英语的版本(模型大效果好但是参数多训练慢而且需要更多内存/显存)。如果我们只处理中文,那么应该使用中文的版本。如果是其他语言就使用多语言的版本。
链接:https://blog.csdn.net/jiaowoshouzi/article/details/89388794/
=======================================================
代码:
pretrain_run.py
#parser.add_argument('--model', type=str, required=True, help='choose a model: Bert, ERNIE')
parser.add_argument('--model', type=str, default='bert', help='choose a model: bert, ERNIE')
数据:
保存模型:
运行结果:
E:\Eprogramfiles\Anaconda3\python.exe E:/other/lightvit/Chinese-Text-Classification-PyTorch/pretrain_run.py
Microsoft Visual C++ Redistributable is not installed, this may lead to the DLL load failure.
It can be downloaded at https://aka.ms/vs/16/release/vc_redist.x64.exe
2023-06-05 12:19:06
0it [00:00, ?it/s]Loading data...
26612it [00:03, 8351.77it/s]
10000it [00:01, 9050.94it/s]
10000it [00:01, 8944.73it/s]
Time usage: 0:00:05
Epoch [1/3]
E:\other\lightvit\Chinese-Text-Classification-PyTorch\pytorch_pretrained\optimization.py:275: UserWarning: This overload of add_ is deprecated:
add_(Number alpha, Tensor other)
Consider using one of the following signatures instead:
add_(Tensor other, *, Number alpha) (Triggered internally at C:\Users\builder\tkoch\workspace\pytorch\pytorch_1647970138273\work\torch\csrc\utils\python_arg_parser.cpp:1052.)
next_m.mul_(beta1).add_(1 - beta1, grad)
Iter: 0, Train Loss: 2.4, Train Acc: 10.16%, Val Loss: 2.4, Val Acc: 9.08%, Time: 0:07:23 *
预测?
=======================================================
save
torch.save(model.state_dict(), PATH)
load
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.eval() # 当用于inference时不要忘记添加
链接:https://blog.csdn.net/qq_46497008/article/details/111682674
=======================================================
- bert_config_file:必要参数,bert配置文件,描述了模型的结构
- input_file:必要参数,输入文件
- output_dir:必要参数,输出地址
- init_checkpoint:初始化时的checkpoint,通常是预训练好的bert模型或者没有
- max_seq_length:最大序列长度
- max_predictions_per_seq:每个序列最大预测数量,或者说每个序列最多被遮蔽的数量
- do_train:是否进行训练
- do_eval:是否进行验证
- train_batch_size:训练btach size
- eval_batch_size:验证batch size
- learning_rate:学习率
- num_train_steps:训练步数
- num_warmup_steps:预热步数
- save_checkpoints_steps:多少步保存一次checkpoint
- max_eval_steps:验证的最大步数
- use_tpu:是否使用tpu
- 其他TPU相关的参数
https://zhuanlan.zhihu.com/p/161740210
=======================================================
E:\Eprogramfiles\Anaconda3\python.exe E:/other/lightvit/Chinese-Text-Classification-PyTorch/pretrain_run.py
Microsoft Visual C++ Redistributable is not installed, this may lead to the DLL load failure.
It can be downloaded at https://aka.ms/vs/16/release/vc_redist.x64.exe
2023-06-05 16:11:48
Loading data...
1471it [00:00, 8104.06it/s]
301it [00:00, 9145.20it/s]
291it [00:00, 7678.44it/s]
Time usage: 0:00:00
Epoch [1/3]
E:\other\lightvit\Chinese-Text-Classification-PyTorch\pytorch_pretrained\optimization.py:275: UserWarning: This overload of add_ is deprecated:
add_(Number alpha, Tensor other)
Consider using one of the following signatures instead:
add_(Tensor other, *, Number alpha) (Triggered internally at C:\Users\builder\tkoch\workspace\pytorch\pytorch_1647970138273\work\torch\csrc\utils\python_arg_parser.cpp:1052.)
next_m.mul_(beta1).add_(1 - beta1, grad)
Iter: 0, Train Loss: 2.4, Train Acc: 10.16%, Val Loss: 2.4, Val Acc: 9.38%, Time: 0:00:28 *
Epoch [2/3]
Epoch [3/3]
Traceback (most recent call last):
File "E:/other/lightvit/Chinese-Text-Classification-PyTorch/pretrain_run.py", line 44, in <module>
train(config, model, train_iter, dev_iter, test_iter)
File "E:\other\lightvit\Chinese-Text-Classification-PyTorch\pretrain_eval.py", line 82, in train
test(config, model, test_iter)
File "E:\other\lightvit\Chinese-Text-Classification-PyTorch\pretrain_eval.py", line 90, in test
test_acc, test_loss, test_report, test_confusion = evaluate(config, model, test_iter, test=True)
File "E:\other\lightvit\Chinese-Text-Classification-PyTorch\pretrain_eval.py", line 118, in evaluate
report = metrics.classification_report(labels_all, predict_all, target_names=config.class_list, digits=4)
File "E:\Eprogramfiles\Anaconda3\lib\site-packages\sklearn\utils\validation.py", line 72, in inner_f
return f(**kwargs)
File "E:\Eprogramfiles\Anaconda3\lib\site-packages\sklearn\metrics\_classification.py", line 1950, in classification_report
raise ValueError(
ValueError: Number of classes, 7, does not match size of target_names, 10. Try specifying the labels parameter
Process finished with exit code 1
=======================================================
E:\Eprogramfiles\Anaconda3\python.exe E:/other/lightvit/Chinese-Text-Classification-PyTorch/pretrain_run.py
Microsoft Visual C++ Redistributable is not installed, this may lead to the DLL load failure.
It can be downloaded at https://aka.ms/vs/16/release/vc_redist.x64.exe
2023-06-05 16:36:36
Loading data...
1471it [00:00, 8254.76it/s]
301it [00:00, 5172.79it/s]
592it [00:00, 6570.30it/s]
Time usage: 0:00:00
Epoch [1/3]
E:\other\lightvit\Chinese-Text-Classification-PyTorch\pytorch_pretrained\optimization.py:275: UserWarning: This overload of add_ is deprecated:
add_(Number alpha, Tensor other)
Consider using one of the following signatures instead:
add_(Tensor other, *, Number alpha) (Triggered internally at C:\Users\builder\tkoch\workspace\pytorch\pytorch_1647970138273\work\torch\csrc\utils\python_arg_parser.cpp:1052.)
next_m.mul_(beta1).add_(1 - beta1, grad)
Iter: 0, Train Loss: 2.4, Train Acc: 10.16%, Val Loss: 2.4, Val Acc: 9.38%, Time: 0:00:27 *
Epoch [2/3]
Epoch [3/3]
E:\Eprogramfiles\Anaconda3\lib\site-packages\sklearn\metrics\_classification.py:1221: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
Test Loss: 2.4, Test Acc: 4.92%
Precision, Recall and F1-Score...
precision recall f1-score support
finance 0.0142 0.0541 0.0225 37
realty 0.0000 0.0000 0.0000 36
stocks 0.0000 0.0000 0.0000 29
education 0.1667 0.0031 0.0060 325
science 0.0000 0.0000 0.0000 27
society 0.0625 0.8966 0.1169 29
politics 0.0000 0.0000 0.0000 29
sports 0.0000 0.0000 0.0000 26
game 0.0000 0.0000 0.0000 24
entertainment 0.0000 0.0000 0.0000 27
accuracy 0.0492 589
macro avg 0.0243 0.0954 0.0145 589
weighted avg 0.0959 0.0492 0.0105 589
Confusion Matrix...
[[ 2 1 0 3 0 31 0 0 0 0]
[ 3 0 0 0 0 33 0 0 0 0]
[ 3 1 0 0 0 24 1 0 0 0]
[110 1 0 1 0 197 1 0 13 2]
[ 4 2 0 0 0 19 1 0 0 1]
[ 3 0 0 0 0 26 0 0 0 0]
[ 8 0 0 1 0 20 0 0 0 0]
[ 4 0 0 0 0 22 0 0 0 0]
[ 4 0 0 1 0 19 0 0 0 0]
[ 0 1 0 0 1 25 0 0 0 0]]
Time usage: 0:00:23
run time: 625 seconds
2023-06-05 16:47:01
Process finished with exit code 0
=======================================================
=======================================================
=======================================================
https://huggingface.co/bert-base-chinese/tree/main

=======================================================
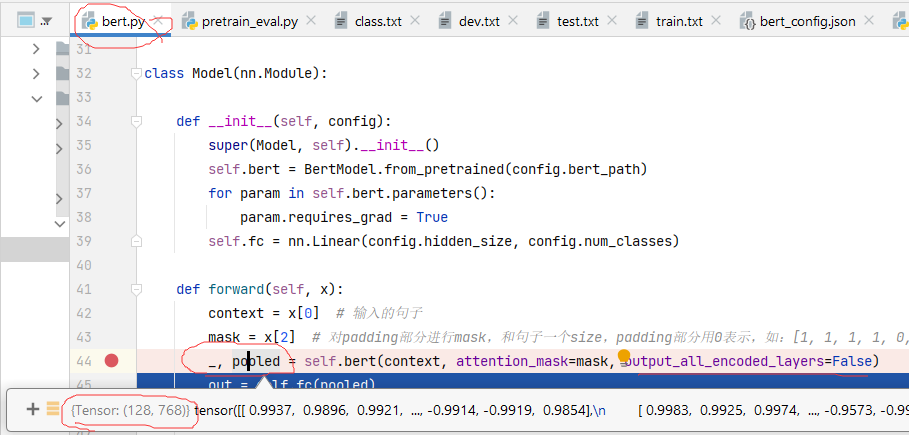
模型的输入
下面介绍一个核心的参数,更多详细内容可以查看官方文档:
input_ids (torch.LongTensor of shape (batch_size, sequence_length)) — 词汇表中输入序列标记的索引
attention_mask (torch.FloatTensor of shape (batch_size, sequence_length), optional) — 对输入数据进行mask,解决pad问题.在 [0, 1] 中选择的掩码值:1 表示未屏蔽的标记,0 表示已屏蔽的标记
token_type_ids (torch.LongTensor of shape (batch_size, sequence_length), optional) — 分段标记索引以指示输入的第一和第二部分。在 [0, 1] 中选择索引:0对应一个句子A的token,1对应一个句子B的token。
{'input_ids': [101, 2769, 1762, 3844, 6407, 8815, 8716, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
{'input_ids': [101, 2769, 1762, 3844, 6407, 8815, 8716, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
['[CLS]', '我', '在', '测', '试', 'be', '##rt', '[SEP]']
模型的输出
( last_hidden_state: FloatTensor = None,
pooler_output: FloatTensor = None,
hidden_states: typing.Optional[typing.Tuple[torch.FloatTensor]] = None,
past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.FloatTensor]]] = None,
attentions: typing.Optional[typing.Tuple[torch.FloatTensor]] = None,
cross_attentions: typing.Optional[typing.Tuple[torch.FloatTensor]] = None )
https://huggingface.co/docs/transformers/main_classes/output#transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions
last_hidden_state (torch.FloatTensor of shape (batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列.
hidden_states (tuple(torch.FloatTensor), optional, returned when output_hidden_states=True is passed or when config.output_hidden_states=True) — 形状为(batch_size、sequence_length、hidden_size)的torch.FloatTensor 的元组(一个用于嵌入的输出,如果模型有嵌入层,+ 一个用于每一层的输出)
————————————————
版权声明:本文为CSDN博主「科皮子菊」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/meiqi0538/article/details/124891560
=======================================================
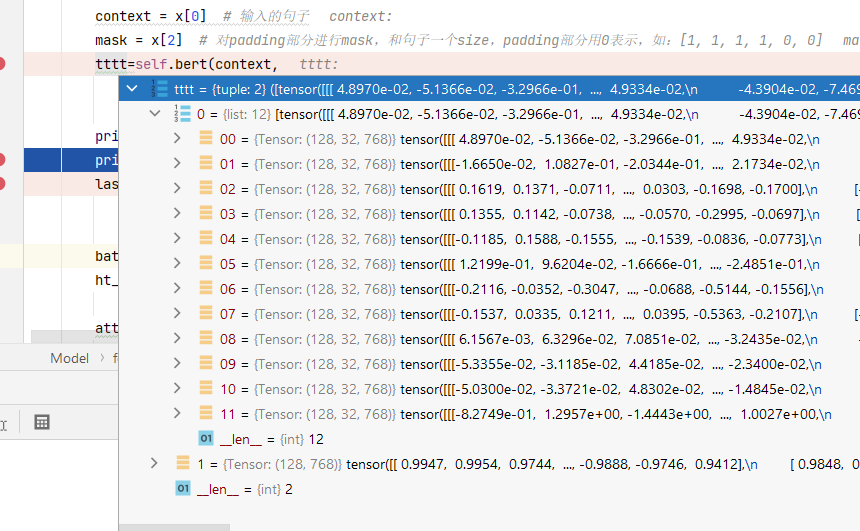
输出是一个元组类型的数据 ,包含四部分,
last hidden state shape是(batch_size, sequence_length, hidden_size),hidden_size=768,它是模型最后一层的隐藏状态
pooler_output:shape是(batch_size, hidden_size),这是序列的第一个token (cls) 的最后一层的隐藏状态,它是由线性层和Tanh激活函数进一步处理的,这个输出不是对输入的语义内容的一个很好的总结,对于整个输入序列的隐藏状态序列的平均化或池化可以更好的表示一句话。
hidden_states:这是输出的一个可选项,如果输出,需要指定config.output_hidden_states=True,它是一个元组,含有13个元素,第一个元素可以当做是embedding,其余12个元素是各层隐藏状态的输出,每个元素的形状是(batch_size, sequence_length, hidden_size),
attentions:这也是输出的一个可选项,如果输出,需要指定config.output_attentions=True,它也是一个元组,含有12个元素,包含每的层注意力权重,用于计算self-attention heads的加权平均值
————————————————
版权声明:本文为CSDN博主「uan_cs」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_41971355/article/details/121124868
import torch from torch import tensor from transformers import BertConfig, BertTokenizer, BertModel model_path = 'model/chinese-roberta-wwm-ext/'#已下载的预训练模型文件路径 config = BertConfig.from_pretrained(model_path, output_hidden_states = True, output_attentions=True) assert config.output_hidden_states == True assert config.output_attentions == True model = BertModel.from_pretrained(model_path, config = config) tokenizer = BertTokenizer.from_pretrained(model_path) text = '我热爱这个世界' # input = tokenizer(text) # {'input_ids': [101, 2769, 4178, 4263, 6821, 702, 686, 4518, 102], #'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0], #'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]} # input = tokenizer.encode(text) # [101, 2769, 4178, 4263, 6821, 702, 686, 4518, 102] # input = tokenizer.encode_plus(text) # {'input_ids': [101, 2769, 4178, 4263, 6821, 702, 686, 4518, 102], #'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0], #'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]} input_ids = torch.tensor([tokenizer.encode(text)], dtype=torch.long)#一个输入也需要组batch print(input_ids.shape) #torch.Size([1, 9]) model.eval() output = model(input_ids) print(len(output)) print(output[0].shape) #最后一层的隐藏状态 (batch_size, sequence_length, hidden_size) print(output[1].shape) #第一个token即(cls)最后一层的隐藏状态 (batch_size, hidden_size) print(len(output[2])) #需要指定 output_hidden_states = True, 包含所有隐藏状态,第一个元素是embedding, 其余元素是各层的输出 (batch_size, sequence_length, hidden_size) print(len(output[3])) #需要指定output_attentions=True,包含每一层的注意力权重,用于计算self-attention heads的加权平均值(batch_size, layer_nums, sequence_length, sequence_legth) # 4 # torch.Size([1, 9, 768]) # torch.Size([1, 768]) # 13 # 12 all_hidden_state = output[2] print(all_hidden_state[0].shape) print(all_hidden_state[1].shape) print(all_hidden_state[2].shape) # torch.Size([1, 9, 768]) # torch.Size([1, 9, 768]) # torch.Size([1, 9, 768]) attentions = output[3] print(attentions[0].shape) print(attentions[1].shape) print(attentions[2].shape) # torch.Size([1, 12, 9, 9]) # torch.Size([1, 12, 9, 9]) # torch.Size([1, 12, 9, 9])
=======================================================
Parameters
- last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. - pooler_output (
torch.FloatTensorof shape(batch_size, hidden_size)) — Last layer hidden-state of the first token of the sequence (classification token) after further processing through the layers used for the auxiliary pretraining task. E.g. for BERT-family of models, this returns the classification token after processing through a linear layer and a tanh activation function. The linear layer weights are trained from the next sentence prediction (classification) objective during pretraining. - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
- attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
- cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueandconfig.add_cross_attention=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
- past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and optionally ifconfig.is_encoder_decoder=True2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
config.is_encoder_decoder=Truein the cross-attention blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding.
Base class for model’s outputs that also contains a pooling of the last hidden states.
=======================================================
import torch from transformers import BertTokenizer, BertModel bertModel = BertModel.from_pretrained('bert-base-chinese', output_hidden_states=True, output_attentions=True) tokenizer = BertTokenizer.from_pretrained('bert-base-chinese') text = '让我们来看一下bert的输出都有哪些' # encode和encode_plus的区别 # encode仅返回input_ids # encode_ids返回所有的编码信息,具体如下: # input_ids:单词在词典的编码; # token_type_ids:区分两个句子的编码(上句全为0,下句全为1); # attention_mask:指定对哪些词进行self-attention操作。 input_ids = torch.tensor([tokenizer.encode(text)]).long() outputs = bertModel(input_ids) print(len(outputs)) print(outputs.keys()) print(outputs['last_hidden_state'].shape) print(outputs['pooler_output'].shape) print(len(outputs['hidden_states'])) print(len(outputs['attentions']))
代码输出结果:
4 odict_keys(['last_hidden_state', 'pooler_output', 'hidden_states', 'attentions']) torch.Size([1, 18, 768]) torch.Size([1, 768]) 13 12
可以看出,bert的输出是由四部分组成:
last_hidden_state:shape是(batch_size, sequence_length, hidden_size),hidden_size=768,它是模型最后一层输出的隐藏状态。(通常用于命名实体识别)
pooler_output:shape是(batch_size,
hidden_size),这是序列的第一个token(classification
token)的最后一层的隐藏状态,它是由线性层和Tanh激活函数进一步处理的。(通常用于句子分类,至于是使用这个表示,还是使用整个输入序列的隐藏状态序列的平均化或池化,视情况而定)
hidden_states:这是输出的一个可选项,如果输出,需要指定config.output_hidden_states=True,它也是一个元组,它的第一个元素是embedding,其余元素是各层的输出,每个元素的形状是(batch_size,
sequence_length, hidden_size)
attentions:这也是输出的一个可选项,如果输出,需要指定config.output_attentions=True,它也是一个元组,它的元素是每一层的注意力权重,用于计算self-attention heads的加权平均值。
参考链接:
https://www.cnblogs.com/xiximayou/p/15016604.html
=======================================================

既然bert输出每层都包含不同信息,本文就尝试将bert输出12层加上embedding层一起做分类。但是不同的层的权重怎么定呢,于是就考虑添加注意力来训练每层的权重:下面为pytroch模型的代码:
class NeuralNet(nn.Module): def __init__(self, model_name_or_path, hidden_size=768, num_class=3): super(NeuralNet, self).__init__() self.config = BertConfig.from_pretrained(model_name_or_path, num_labels=3) self.config.output_hidden_states = True#需要设置为true才输出 self.bert = BertModel.from_pretrained(model_name_or_path, config=self.config) for param in self.bert.parameters(): param.requires_grad = True self.weights = nn.Parameter(torch.rand(13, 1)) self.dropouts = nn.ModuleList([ nn.Dropout(0.5) for _ in range(5) ]) self.fc = nn.Linear(hidden_size, num_class) def forward(self, input_ids, input_mask, segment_ids): last_hidden_states, pool, all_hidden_states = self.bert(input_ids, token_type_ids=segment_ids, attention_mask=input_mask) batch_size = input_ids.shape[0] ht_cls = torch.cat(all_hidden_states)[:, :1, :].view( 13, batch_size, 1, 768) atten = torch.sum(ht_cls * self.weights.view( 13, 1, 1, 1), dim=[1, 3]) atten = F.softmax(atten.view(-1), dim=0) feature = torch.sum(ht_cls * atten.view(13, 1, 1, 1), dim=[0, 2]) for i, dropout in enumerate(self.dropouts): if i == 0: h = self.fc(dropout(feature)) else: h += self.fc(dropout(feature)) h = h / len(self.dropouts) return h
=======================================================
=======================================================
=======================================================
=======================================================

 浙公网安备 33010602011771号
浙公网安备 33010602011771号