TextCNN
TextCNN
一、TextCNN详解
1、TextCNN是什么
我们之前提到CNN时,通常会认为属于CV领域,是用于解决计算机视觉方向问题的模型,但是在2014年,Yoon Kim针对CNN的输入层做了一些变形,提出了文本分类模型TextCNN。与传统图像的CNN网络相比,TextCNN 在网络结构上没有任何变化(甚至更加简单了),从图1可以看出TextCNN 其实只有一层卷积,一层max-pooling,最后将输出外接softmax来n分类。
TextCNN网络结构
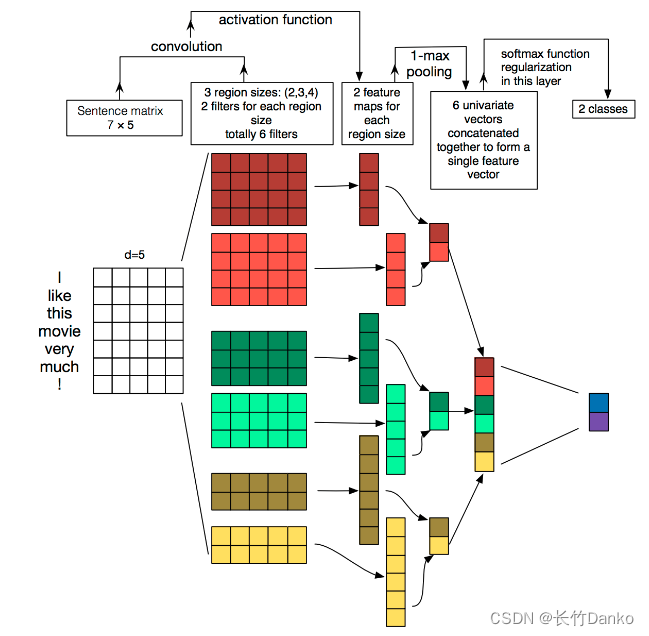
【图1:TextCNN网络结构】
与图像当中CNN的网络相比,textCNN 最大的不同便是在输入数据的不同:图像是二维数据,图像的卷积核是从左到右,从上到下进行滑动来进行特征抽取。自然语言是一维数据,虽然经过word embedding生成了二维向量,但是对词向量做从左到右滑动来进行卷积没有意义。比如 “今天” 对应的向量[0, 0, 0, 0, 1],按窗口大小为 1* 2 从左到右滑动得到[0,0],[0,0],[0,0],[0, 1]这四个向量,对应的都是"今天"这个词汇,这种滑动没有帮助。
TextCNN的成功,不是网络结构的成功,而是通过引入已经训练好的词向量来在多个数据集上达到了超越benchmark的表现,进一步证明了构造更好的embedding,是提升nlp各项任务的关键能力,后面会专门讲解目前流行的embedding算法。
2、TextCNN 的优势
TextCNN最大优势网络结构简单 ,在模型网络结构如此简单的情况下,通过引入已经训练好的词向量依旧有很不错的效果,在多项数据数据集上超越benchmark。
网络结构简单导致参数数目少, 计算量少, 训练速度快,在单机单卡的v100机器上,训练165万数据, 迭代26万步,半个小时左右可以收敛。
3、TextCNN 的网络计算原理
输入层(Embedding层)
输入层的作用就是将输入文本切词后,通过词向量文件及词向量矩阵,将文本向量化,支持后续进行卷积池化等操作。具体来说,分为以下几步:
文本切词
通过jieba分词等工具,将输入文本切分为若干个词。例如“今天晚上吃什么呢”,分词后变为【“今天”, “晚上”, “吃”, “什么”, “呢”】。除了文本输入时,需要进行切词,接下来要介绍的词向量,在构建词向量文件时,也需要进行切词操作。
词向量矩阵初始化
先简要介绍下词向量文件及词向量矩阵。词向量文件的表现形式,是以离线配置文件的形式存在的,通常是json文件,代码中加载后以dict形式存在,如{"的": 1, "是": 2, ……},词向量文件的作用是,在对输入文本进行切词后,需要获取每个词的向量表征,则先通过词向量文件获取词对应的索引,再通过索引在词向量矩阵中获取词的向量表征。这时再理解词向量矩阵,就简单多了,词向量矩阵的作用,是用于获取输入文本的向量表征,说的通俗点,就是用向量将文本表现出来,以用于模型中的数值计算(例如后续的卷积、池化等操作)。词向量矩阵的每一行,是某个词对应的向量,也就是说,我们通过词向量文件中的索引,可以在词向量矩阵中获取词的向量表征。再简单介绍下词向量矩阵及词向量文件生成的两种方式。
随机初始化词向量矩阵:这种方式很容易理解,就是使用self.embedding = torch.nn.Embedding(vocab_size, embed_dim)命令直接随机生成个初始化的词向量矩阵,此时的向量值符合正态分布N(0,1),这里的vocab_size是指词向量矩阵能表征的词的个数,这个数值即是词向量文件中词的数量加1(加1的原因是,如果某个词在词向量文件中不存在,则获取不到索引,也就无法在词向量矩阵中获取对应的向量,这时我们默认这个词的索引为0,即将词向量的第一行作为这个词的向量表征。使用预训练的词向量文件时,这个方法同样适用),embed_dim是指表征每个词时,向量的维度(可自定义,如256)。对于随机初始化词向量矩阵的方式,词向量文件的生成方式一般是将当前所有的文本数据(包括训练数据、验证数据、测试数据)进行切词,再对所有词进行聚合统计,保留词的数量大于某个阈值(比如3)的词,并进行索引编号(编号从1开始,0作为上面提到的不在词向量文件中的其他词的索引),进而生成词向量文件。顺便提一句,词向量矩阵的初始化的方式也有很多种,比如Xavier、Kaiming初始化方法。
使用预训练的词向量文件初始化词向量矩阵:本质上,词向量矩阵的作用是实现文本的向量表征,因此,如何用更合适的向量表示文本,逐渐成为了一个热门研究方向。预训练的词向量文件便是其中的一个研究成果,如通过word2vec、glove等预训练模型生成的词向量文件,通过大量的训练数据,来生成词的向量表征。以word2vec为例,训练后生成的词向量文件是以离线配置文件的形式存在,可通过gensim工具包进行加载,具体命令是wvmodel = gensim.models.KeyedVectors.load_word2vec_format(word2vec_file, binary=False, encoding='utf-8', unicode_errors='ignore'),加载后,可通过wvmodel.key_to_index获取词向量文件(要对词向量文件中的词索引进行重新编号,原索引从0开始,调整为从1开始,0作为不在词向量文件中的词的索引),通过wvmodel.get_vector("xxx")获取词向量文件中每个词对应的向量,将词向量文件中所有词对应的向量聚合在一起后(聚合的方式是,每个词的向量表征,按照词的索引,填充在词向量矩阵对应的位置),生成预训练词向量矩阵weight,再通过self.embedding = torch.nn.Embedding.from_pretrained(weight, freeze=False)完成词向量矩阵的初始化,参数freeze的作用,是指明训练时是否更新词向量矩阵的权重值,True为不更新,默认为True,等同于self.embedding.weight.requires_grad = False)。
还有个细节需要介绍下,在获取到预训练的词向量文件后,由于预训练的词向量文件很大,因此在后续的训练过程中,可能会出现内存不足的错误,此时可对词向量文件及预训练词向量矩阵进行调整,具体来说,先对我们本身任务的所有文本数据进行切词统计,保留数量超过一定阈值的词,作为词向量文件(就是随机初始化词向量矩阵时,词向量文件的生成方法),再利用这个词向量文件,配合wvmodel.get_vector("xxx"),获取预训练词向量矩阵weight,最后进行后续的词向量矩阵初始化过程。这样操作之后,由于词向量文件中词的数量减少,词向量矩阵的行数减少,内存占用会随之减少很多。另外,生成词向量的预训练方法还有很多,参见【通俗易懂的词向量】。
输入文本向量化
经过上述两步,输入文本已经完成分词,且词向量矩阵也完成初始化,这时便可对输入文本进行向量化操作,总结下,会根据文本切词后,每个词在词向量文件中的索引,确定这个词在词向量矩阵中的位置,从而获取这个词的向量表征,最终组合出输入文本的向量表征,即输入文本对应的向量矩阵,这个矩阵的列数和词向量矩阵的列数一致,行数不固定了,依赖于文本切词后词的数量。
卷积层
卷积层与传统CV领域的卷积处理模块没有太大区别,这里我们着重介绍一些需要注意的细节。
通道(channel):在传统CV领域,可以利用 (R, G, B) 作为不同channel,通道个数一般为3个。在使用TextCNN做分类时,通道个数一般是一个。其实也可以采用多channel输入,TextCNN的多channel通常是不同方式的embedding方式(比如 word2vec或glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。但是实验证明,单channel 的TextCNN 表现都要优于多channels的TextCNN,如图2所示。
我们在这里也介绍一下四个model 的不同:
a、CNN-rand(随机词向量)
指定词向量的维度embedding_size后,文本分类模型对不同单词的向量作随机初始化, 后续有监督学习过程中,通过BP的方式更新输入层的各个词汇对应的词向量。
b、CNN-static(静态词向量)
使用预训练的词向量,即利用word2vec、fastText或者Glove等词向量工具,在开放领域数据上进行无监督的学习,获得词汇的具体词向量表示方式,拿来直接作为输入层的输入,并且在TextCNN模型训练过程中不再调整词向量, 这属于迁移学习在NLP领域的一种具体的应用。
c、CNN-non-static(非静态词向量)
预训练的词向量+ 动态调整 , 即拿word2vec训练好的词向量初始化, 训练过程中再对词向量进行微调。
d、multiple channel(多通道)
借鉴图像中的RGB三通道的思想, 这里也可以用 static 与 non-static 两种词向量初始化方式来搭建两个通道。
卷积计算
TextCNN的卷积计算和CV领域的卷积计算略有不同,主要体现在卷积核的形状大小上,TextCNN的卷积核大小,行数可自定义(如2、3、4等),列数要和词向量矩阵的列数相同,因为词向量矩阵的每一行表征一个词,只有两者列数相同,卷积核才能提取每一个词的完整信息。卷积核的列数少于词向量矩阵的列数,提取信息不完整,没意义。而传统CV的卷积核列数也可自定义。另外和传统CV一致,卷积核的个数也可自定义。
在这里插入图片描述

【图2:TextCNN实验】
池化层
池化层也很容易理解,我们同样介绍一些细节。池化层的输入是卷积层的输出,卷积层输出的通道数m等于卷积核的数量,每个通道都是一列。池化的操作就是对这些输出通道进行池化计算,目前存在两种计算方式,平均池化和最大值池化。
平均池化(average pooling):平均池化就是对每个通道的所有数值求均值,torch.nn.functional.avg_pool1d命令即可实现。
最大池化(max pooling):最大池化就是对每个通道的所有数值求最大值,torch.nn.functional.max_pool1d命令即可实现。
不管是平均池化还是最大池化,最终都会生成m个数值,将这m个数值拼接后,进入最后的全连接层。
全连接层
根据池化层的输出和分类类别数量,构建全连接层,再经过softmax,得到最终的分类结果,torch.nn.Linear(input_num, num_class)即可定义全连接层,其中input_num是池化层输出的维数,即m,num_class是分类任务的类别数量。
————————————————
链接:https://blog.csdn.net/qq_39439006/article/details/126760701
https://blog.csdn.net/qq_39439006/article/details/126760701

 浙公网安备 33010602011771号
浙公网安备 33010602011771号