连续词袋模型(CBOW)
https://blog.csdn.net/v_JULY_v/article/details/102708459
word2vec是一种将word转为向量的方法,其包含两种算法,分别是skip-gram和CBOW,它们的最大区别是skip-gram是通过中心词去预测中心词周围的词,而CBOW是通过周围的词去预测中心词。
CBOW
CBOW是continuous bag of words的缩写,中文译为“连续词袋模型”。它是一种用于生成词向量的神经网络模型,由Tomas Mikolov等人于2013年提出 。词向量是一种将单词表示为固定长度的实数向量的方法,可以捕捉单词之间的语义和语法关系。
CBOW的基本思想是,给定一个单词的上下文(即窗口内的其他单词),预测该单词本身。

CBOW模型的网络结构示意图
CBOW模型的训练
CBOW模型的训练目标是最大化给定上下文时中心单词出现的概率,即最大化y[t]。这等价于最小化交叉熵损失函数:
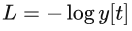
交叉熵损失函数可以通过反向传播算法来求导,并通过随机梯度下降法来更新参数。参数包括输入层到隐藏层之间的权重矩阵W(大小为V×N),以及隐藏层到输出层之间的权重矩阵U(大小为N×V)。
训练完成后,我们可以将W或者U作为生成的词向量矩阵。一般来说,W比U更常用。
CBOW模型的优缺点
CBOW模型相比于传统的基于计数或者基于矩阵分解等方法生成词向量有以下优点:
- 能够利用大规模语料库进行训练
- 能够学习到高质量且低维度(通常在50~300之间) 的稠密向量,节省存储空间和计算资源
- 能够捕捉单词之间的复杂关系,如同义词、反义词、类比关系等
CBOW模型也有以下缺点:
- 忽略了上下文单词的顺序,只考虑了它们的累加效果
- 对于低频或者生僻单词,可能无法生成准确的词向量
- 需要大量的训练时间和内存空间
模型架构
模型由三部分组成:

Input layer
已知我们有一个训练数据(Context(w),w),Context(w)表示词w的上下文
我们将Context(w)中的每个单词的词向量作为输入,输给Projection Layer
Projection Layer
投影层的任务就是将从Input Layer得到的数据进行转换。这里做的是:将Context(w)中的每个词向量相互累加,得到一个全新的向量
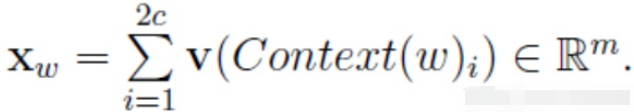
Xw的计算方式有很多种,不一定是相互累加
Output Layer
这里就是重中之重了。Output Layer的作用是:输出我们最终的结果。
CBOW在Output Layer中使用的模型是:Hierarchical softmax,一个树模型的结构。
CBOW 模型训练流程
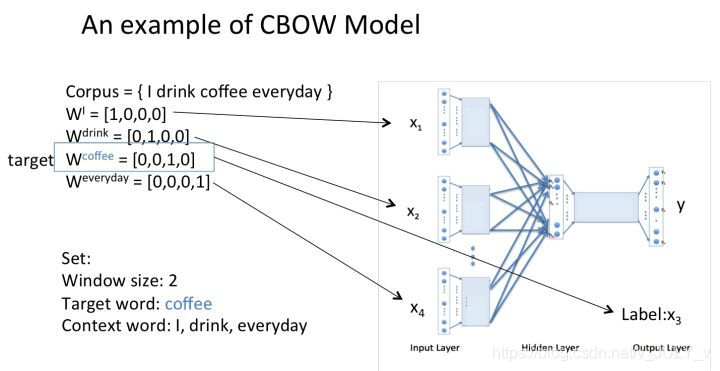
假设我们现在的Corpus是这一个简单的只有四个单词的document:{I drink coffee everyday}
我们选coffee作为中心词,window size设为2,也就是说,我们要根据单词"I","drink"和"everyday"来预测一个单词,并且我们希望这个单词是coffee。
1 将上下文词和目标词都进行 one-hot 表征作为输入:
2 然后将 one-hot 表征结果分别乘以3×4的输入层到隐藏层的权重矩阵W,这个矩阵也叫嵌入矩阵,可以随机初始化生成。
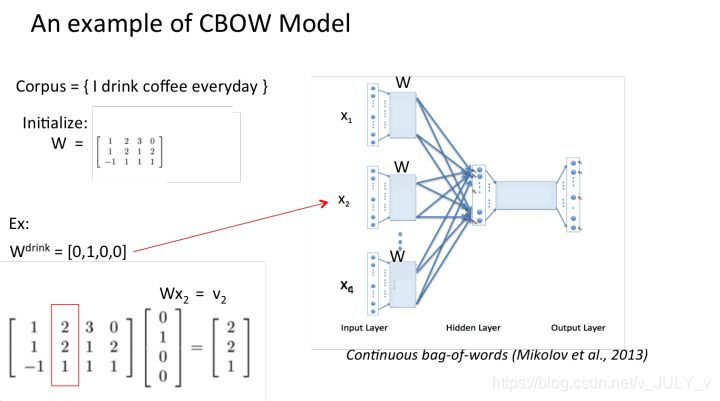
3 将得到的结果向量求平均作为隐藏层向量:
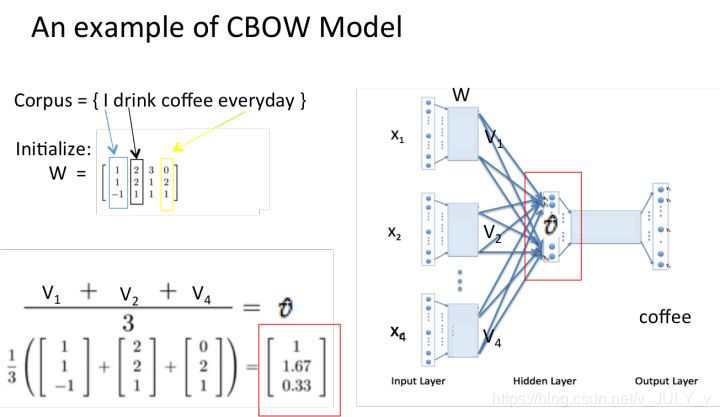
4 然后将隐藏层向量乘以4×3的隐藏层到输出层的权重矩阵W’,这个矩阵也是嵌入矩阵,可以初始化得到。得到输出向量:
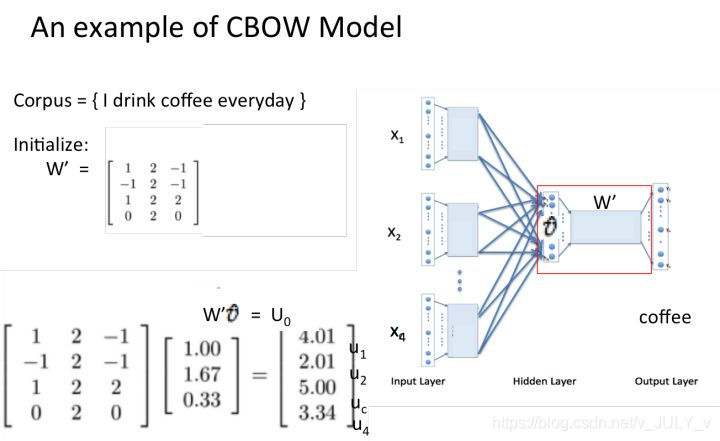
5 最后对输出向量做 softmax 激活处理得到实际输出,并将其与真实标签做比较,然后基于损失函数做梯度优化训练。

以上便是完整的 CBOW 模型计算过程,也是 word2vec 将词汇训练为词向量的基本方法之一。
————————————————
链接:https://blog.csdn.net/v_JULY_v/article/details/102708459
https://zhuanlan.zhihu.com/p/613974960?utm_id=0
https://zhuanlan.zhihu.com/p/570583895

 浙公网安备 33010602011771号
浙公网安备 33010602011771号