TextRCNN、TextCNN、RNN…你都掌握了吗?一文总结文本分类必备经典模型(一)
本专栏将逐一盘点自然语言处理、计算机视觉等领域下的常见任务,并对在这些任务上取得过 SOTA 的经典模型逐一详解。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
本文将分 3 期进行连载,共介绍 20 个在文本分类任务上曾取得 SOTA 的经典模型。
-
第 1 期:RAE、DAN、TextRCNN、Multi-task、DeepMoji、RNN-Capsule
-
第 2 期:TextCNN、dcnn、XML-CNN、textCapsule、Bao et al.、AttentionXML
-
第 3 期:ELMo、GPT、BERT、ALBERT、X-Transformer、LightXML、TextGCN、TensorGCN
您正在阅读的是其中的第 1 期。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
本期收录模型速览
| 模型 | SOTA!模型资源站收录情况 | 模型来源论文 |
|---|---|---|
| RAE | https://sota.jiqizhixin.com/models/models/c4afbfa6-a47f-4f7c-85fa-8b7ba8382f65 收录实现数量:1 |
Semi-Supervised Recursive Autoencoders for Predicting Sentiment Distributions |
| DAN | https://sota.jiqizhixin.com/models/models/b7189fbd-871f-4e13-b4fd-fc9747efde11 收录实现数量:1 |
Deep Unordered Composition Rivals Syntactic Methods for Text Classification |
| TextRCNN | https://sota.jiqizhixin.com/models/models/a5a82cbe-98b7-4f3d-87ae-f9fd59caa55e 收录实现数量:1 支持框架:TensorFlow |
Recurrent Convolutional Neural Networks for Text Classification |
| Multi-task | https://sota.jiqizhixin.com/models/models/351b1aba-c543-437a-8cf8-9b027c5c42b7 收录实现数量:1 支持框架:PyTorch |
Recurrent Neural Network for Text Classification with Multi-Task Learning |
| DeepMoji | https://sota.jiqizhixin.com/models/models/9f50abc9-d67e-483a-bb44-e10c3baeb327 收录实现数量:8 支持框架:TensorFlow、PyTorch、Keras |
Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm |
| RNN-Capsule | https://sota.jiqizhixin.com/models/models/f8cd1ed1-5ebe-42bf-8672-a1d2d9c1c97f 收录实现数量:1 支持框架:TensorFlow |
Investigating Capsule Networks with Dynamic Routing for Text Classification |
文本分类是自然语言处理中最基本、最经典的任务,大部分自然语言处理任务都可以看作是分类任务。近年来,深度学习在众多研究领域中获得了巨大的成功,如今,也成为了 NLP 领域的标配技术,广泛渗透入文本分类任务中。
与数字、图像不同,对文本的处理强调精细化的处理能力。传统的文本分类方法一般需要对输入模型的文本数据进行预处理,此外还需要通过人工标注的方法来获得良好的样本特征,然后使用经典的机器学习算法对其进行分类。类似的方法包括 NaiveBayes(NB)、K 近邻(KNN)、支持向量机 SVM 等。特征提取的水平对文本分类效果的影响甚至高于图像分类,而文本分类中的特征工程往往非常耗时且计算成本高。2010 年后,文本分类的方法逐渐过渡到深度学习模型。应用于文本分类的深度学习通过学习一系列的非线性变换模式将特征工程直接映射到输出,从而将特征工程集成到模型拟合过程中,一经应用就获得了巨大的成功。
与图像分类模型不同,文本分类模型一般不会采用堆叠模块、修改深度模型结构等方式去改进,更多则是通过引入其它技术手段改进模型效果,例如引入注意力机制、预训练、图神经网络、胶囊网络等。所以在介绍经典文本分类模型时,更多的是介绍为了解决文本分类中的哪一类具体问题,针对性的引入了哪些专门的技术 trick,以及这些引入的 trick 是如何与原有的经典架构融合的。
此外,NLP 领域中大量工作都聚焦于前端的词、语句、文本的处理或语义理解,目的是为下游的各类任务服务,当然也包括文本分类任务。为了更聚焦于文本分类模型,我们在这篇文章中只介绍专门的文本分类模型,其它 NLP 模型会放在后续的专题报告中介绍。最后,文本分类模型以 BERT 的出现明显呈现出两个不同的发展阶段,BERT 提出后(2019 年之后),单纯基于 RNN、CNN 改进的且效果比较突出的方法就比较少了。
一、ReNN
递归神经网络(Recursive Neural Network,ReNN)可以自动学习文本的语义,并自动学习语法树结构,而无需进行特征设计。ReNN 是最早期的应用于文本分类的深度学习模型。与传统模型相比,基于 ReNN 的模型提高了性能,并且由于排除了用于不同文本分类任务的特征设计,节省了人力成本。我们具体介绍 ReNN 中的 RAE 模型。
1.1 RAE
递归自动编码器(Recursive AutoEncoder,RAE)被用来预测每个输入句子的情感标签分布,并学习多词短语的表述。在做文本分析时,依据词向量得到某一段文字的向量空间,然后逐层向上分析,继而得到整段文字的向量表示,对这个向量分析得到用户的情感。RAE 相关论文首次发表在 EMNLP 2011 中。图1给出了一个 RAE 模型的说明,该模型从无监督的文本中学习短语和完整句子的向量表示以及它们的层次结构。作者扩展了模型,在层次结构的每个节点上学习情感标签的分布。
图1. RAE 架构说明,RAE 学习短语的语义向量表示。词索引(橙色)首先被映射到语义向量空间(蓝色),然后,被同一个自动编码器网络递归地合并成一个固定长度的句子表示。每个节点的向量被用作预测情感标签分布的特征
半监督递归自动编码器(Semi-Supervised Recursive Autoencoders)
模型旨在为大小可变的短语在无监督&半监督的情况下寻找训练机制,这些词表征能用在后续任务中。本文首先介绍神经网络词表征,再提出一种基于autoencoder的递归模型,进而引入本文模型 RAE,以及 RAE 能学到短语、短语结构和情感分布联合表征原因。
1)神经词汇表征(Neural Word Representations)。首先将词表征为连续的向量。有两种方法,第一种方法是简单初始化每个词向量,通过一个高斯分布进行采样;第二种方法是通过无监督的方法进行词向量的预训练,这类模型能够在向量空间中学到词表征,通过梯度迭代词向量从他们共现的统计特征中捕获语法和语义信息。
2)传统递归自动编码器(Traditional Recursive Autoencoders)。传统的自动编码器作用是学习输入的表征,一般用于预给定的树结构,如图 2:
图2. 递归自动编码器在二进制树上的应用说明。没有填充的节点只用于计算重建误差。一个标准的自动编码器(方框内)在树的每个节点上都被重新使用
3)用于结构预测的无监督递归自动编码器(Unsupervised Recursive Autoencoder for Structure Prediction)。在没有给定输入结构的情况下,RAE 的目标是最小化子树中子节点对的重构误差,再通过贪心算法重构树结构。此外,作者还引入 Weighted Reconstruction 和 Length Normalization 以降低重构误差。
4)半监督的递归自动编码器(Semi-Supervised Recursive Autoencoders)。作者拓展了 RAE 用于半监督训练,去预测句子&短句级的目前分布 t。RAE 的优势之一在于树构建的每个节点都能关联到分布词向量表征,能被作为短语的特征表示。图 3 显示了一个半监督的 RAE 单元。
图3. 非终端树节点的 RAE 单元的图示。红色节点显示用于标签分布预测的有监督的 softmax 层
当前 SOTA!平台收录 RAE 共 1 个模型实现资源。
| 模型 | SOTA!平台模型详情页 |
|---|---|
| RAE | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/c4afbfa6-a47f-4f7c-85fa-8b7ba8382f65 |
二、MLP
多层感知器(MultiLayer Perceptron,MLP),有时被俗称为 "vanilla "神经网络,是一种简单的神经网络结构,用于自动捕捉特征。如图 4 所示,我们展示了一个三层的MLP 模型。它包含一个输入层,一个所有节点都有激活函数的隐藏层以及一个输出层。每个节点都用一定的权重𝑤𝑖连接。它将每个输入文本视为一个词袋,与传统模型相比,MLP 在许多文本分类基准上都取得了较好的性能。
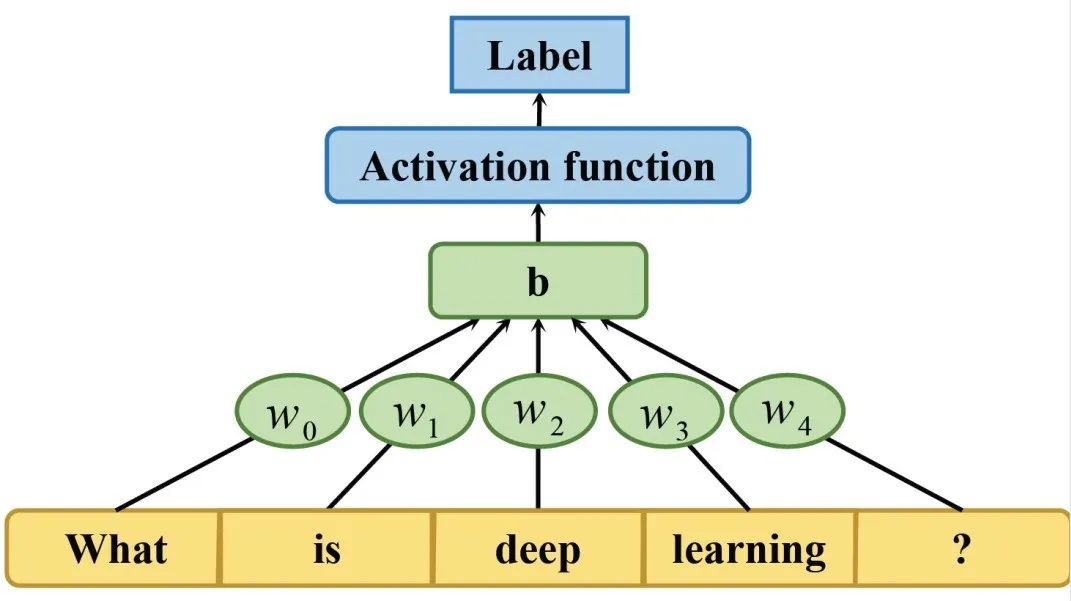
图4. 三层MLP架构
2.1 DAN
论文 Deep Unordered Composition Rivals Syntactic Methods for Text Classification 提出了 NBOW (Neural Bag-of-Words) 模型和 DAN(Deep Averaging Networks) 模型。对比了深层无序组合方法 (Deep Unordered Composition) 和句法方法 (Syntactic Methods) 应用在文本分类任务中的优缺点,强调深层无序组合方法的有效性、效率以及灵活性。论文发表在 ACL 2015 中。
1)神经词袋模型(Neural Bag-of-Words Models)。论文首先提出了一个最简单的无序模型 Neural Bag-of-Words Models (NBOW model)。该模型直接将文本中所有词向量的平均值作为文本的表示,然后输入到 softmax 层。
2)考虑合成的语法问题(Considering Syntax for Composition)。探索更复杂的句法功能,以避免与 NBOW 模型相关的许多缺陷。具体包括:Recursive neural networks (RecNNs);考虑一些复杂的语言学现象,如否定、转折等 (优点);实现效果依赖输入序列(文本)的句法树(可能不适合长文本和不太规范的文本);引入卷积神经网络等。
3)提出了深度平均网络(DAN)。该网络在传统的 NBOW 模型的基础上叠加了非线性层,取得了与句法功能相当或更好的性能。
4)DropOut 提高了稳健性(Word Dropout Improves Robustness)。针对 DAN 模型,论文提出一种 word dropout 策略:在求平均词向量前,随机使得文本中的某些单词 (token) 失效。
图5. 两层DAN架构
当前 SOTA!平台收录 DAN 共 1 个模型实现资源。
| 模型 | SOTA!平台模型详情页 |
|---|---|
| DAN | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/b7189fbd-871f-4e13-b4fd-fc9747efde11 |
三、RNN
递归神经网络(Recurrent Neural Network,RNN)被广泛用于通过递归计算捕捉长距离的依赖性。RNN 语言模型学习历史信息,考虑到适合文本分类任务的所有单词之间的位置信息。首先,每个输入词都用一个特定的向量表示,使用词嵌入技术。然后,嵌入的单词向量被逐一送入RNN 单元。RNN 单元的输出与输入向量的维度相同,并被送入下一个隐藏层。RNN 在模型的不同部分共享参数,每个输入词的权重相同。最后,输入文本的标签可以由隐藏层的最后一个输出来预测。
图6. RNN架构
3.1 TextRCNN
TextRCNN 相关论文首次发表在 AAAI 2015 中。在 TextCNN 网络中,网络结构采用“卷积层+池化层”的形式,卷积层用于提取 n-gram 类型的特征,在 RCNN(循环卷积神经网络)中,卷积层的特征提取的功能被 RNN 替代,即通过 RNN 取代 TextCNN的特征提取。RNN 的优点是能够更好地捕捉上下文信息,有利于捕获长文本的语义。因此整体结构变为了 RNN+池化层,所以叫 RCNN。
TextRCNN 在词嵌入的基础上加上了上下文环境作为新的词嵌入表示。左侧和右侧的context 是通过前向和后向两层 RNN 的中间层输出得到的。这些中间层的输出和原始的词嵌入拼接形成新的词嵌入 y,然后送入池化层。下图是 TextRCNN 模型框架,输入是一个文本 D,可以看成是由一系列单词(W_1, W_2,...)组成的。输出是一个概率分布,最大的位置对应文章属于的类别 K。
图7. 递归卷积神经网络的结构。该图是 "A sunset stroll along the South Bank affords an array of stunning vantage points "这句话的部分例子,下标表示原句中相应的词的位置
RCNN 整体的模型构建流程如下:1)利用前向和后向 RNN 得到每个词的前向和后向上下文的表示,词的表示就变成词向量和前向后向上下文向量 concat 起来的形式了。2)将拼接后的向量非线性映射到低维。3)向量中的每个位置的值都取所有时序上的最大值,得到最终的特征向量。4)softmax 分类得到最终的评分向量。使用随机梯度下降来对参数进行更新。
当前 SOTA!平台收录 TextRCNN 共 1 个模型实现资源,支持框架:TensorFlow。
| 模型 | SOTA!平台模型详情页 |
|---|---|
| TextRCNN | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/a5a82cbe-98b7-4f3d-87ae-f9fd59caa55e |
3.2 Multi-task
Multi-task 的文章发表与 IJCAI 2016。在本文中,作者使用多任务学习框架来共同学习多个相关任务(相对于多个任务的训练数据可以共享),以应对数据不足的问题。本文提出了三种不同的基于递归神经网络的信息共享机制,以针对特定任务和共享层对文本进行建模。整个网络在这些任务上进行联合训练。
图8. Multi-task 三种模型
对于模型 I,每个任务共享一个 LSTM 层和 Eembedding 层,同时每个任务都拥有自己的 Eembedding 层,也就是说,对于任务 m,输入x定义为以下形式:
其中,(x_t)^(m)、(x_t)^(s) 分别表示特定任务和共享词嵌入,⊕表示连接操作。
模型 II 中,每个任务都拥有自己的 LSTM 层,但是下一时刻的输入中包含了下一时刻的char 及所有任务在当前时刻的隐层输出 h。
作者修改了 cell 的计算公式以决定保存多少信息:
模型 III 中,每个任务都拥有一个共享的 BI-LSTM 层,同时各自有一个 LSTM 层,LSTM 的输入包括 char 及 BI-LSTM 在该时刻的隐层输出,与模型 II 一样,作者也修改了 cell 的计算公式
当前 SOTA!平台收录 Multi-task 共 1 个模型实现资源,支持框架:PyTorch。
| 模型 | SOTA!平台模型详情页 |
|---|---|
| Multi-task | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/351b1aba-c543-437a-8cf8-9b027c5c42b7 |
3.3 DeepMoji
DeepMoji 发表在 EMNLP 2017 中,是 Bjarke Felbo 等提出的一种联合 Bi-LSTM 和Attention 的混合神经网络,对表情符号的情绪识效果最优,在文本分类任务中表现也不错。
DeepMoji 的结构如图 9 所示,第一层是一个让每个 Word 能够嵌入向量空间的嵌入层,然后用 tanh 激活函数把嵌入维度压缩到[-1,1];第二层和第三层用一个 BiLSTM,每一个方向用 512 个隐层单元;第四层是一个 attention 层,通过 skip-connections 将前面三层的输出拼接,输入到 attention 中;第五层就是一个 softmax 层。简言之,DeepMoji 就是在 Embedding 后接两层 Bi-LSTM,然后再将这三层的输出拼接,到Attention,再接一个 softmax。
图9. DeepMoji模型,S为文本长度,C为类别数量
当前 SOTA!平台收录 DeepMoji 共 8 个模型实现资源,支持框架:TensorFlow、PyTorch、Keras。
| 模型 | SOTA!平台模型详情页 |
|---|---|
| DeepMoji | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/9f50abc9-d67e-483a-bb44-e10c3baeb327 |
3.4 RNN-Capsule
RNN-Capsule 是胶囊方法在文本分类中的应用,相关论文发表在 EMNLP 2018 中。胶囊网络(Capsule Network)用神经元向量代替传统神经网络的单个神经元节点,以 Dynamic Routing 的方式去训练这种全新的神经网络,从而提升模型效率及文本表达能力。
该模型首先利用标准的卷积网络,通过多个卷积滤波器提取句子的局部语义表征。然后将 CNN 的标量输出替换为向量输出胶囊,从而构建 Primary Capsule 层。接着输入到作者提出的改进的动态路由(共享机制的动态路由和非共享机制的动态路由),得到卷积胶囊层。最后将卷积胶囊层的胶囊压平,送入到全连接胶囊层,每个胶囊表示属于每个类别的概率。
图10. 用于文本分类的胶囊网络的结构。动态路由的过程显示在底部
在路由过程中,许多胶囊属于背景胶囊,即这些胶囊与最终的类别胶囊无关,比如文本里的停用词、类别无关词等等。作者提出了三种策略以减少背景或者噪音胶囊对网络的影响:
-
Orphan 类别:在胶囊网络的最后一层引入 Orphan 类别,它可以捕捉一些背景知识,比如停用词。在文本任务中停用词比较一致,比如谓词和代词等,所以引入Orphan 类别的效果较好。
-
Leaky-Softmax:在中间的连续卷积层引入去噪机制。对比 Orphan 类别,Leaky-Softmax 是一种轻量的去噪方法,它不需要额外的参数和计算量。
-
路由参数修正:传统的路由参数,通常用均与分布进行初始化,忽略了下层胶囊的概率。相反,作者把下层胶囊的概率当成路由参数的先验,改进路由过程。
为了提升文本性能,作者引入了两种网络结构,具体如下:
图11. 两种胶囊网络架构
Capsule-A 从嵌入层开始,将语料库中的每个词转化为 300 维(V = 300)的词向量,然后是一个具有 32 个滤波器(B = 32)、步长为 1 的 ReLU 非线性的 3-gram(K1 = 3)卷积层。所有其他层都是胶囊层,从具有 32 个滤波器(C=32)的 B×d 初级胶囊层开始,然后是具有 16 个滤波器(D=16)的 3×C×d×d(K2=3)卷积胶囊层和一个全连接的胶囊层,依次进行。每个胶囊都有 16 维(d=16)的实例化参数,其长度(规范)可以描述胶囊存在的概率。胶囊层由转换矩阵连接,每个连接也要乘以路由系数,该系数由路由协议机制动态计算得出。
Capsule-B 的基本结构与 Capsule-A 相似,只是在 N-gram 卷积层中采用了三个平行网络,过滤窗口(N)为 3、4、5(见图 11)。全连接的胶囊层的最终输出被送入平均池以产生最终结果。通过这种方式,Capsule-B 可以学习到更有意义和更全面的文本表述。
当前 SOTA!平台收录 RNN-Capsule 共 1 个模型实现资源,支持框架:TensorFlow。
| 模型 | SOTA!平台模型详情页 |
|---|---|
| RNN-Capsule | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/models/models/f8cd1ed1-5ebe-42bf-8672-a1d2d9c1c97f |
前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及API等资源。
网页端访问:在浏览器地址栏输入新版站点地址 sota.jiqizhixin.com ,即可前往「SOTA!模型」平台,查看关注的模型是否有新资源收录。
移动端访问:在微信移动端中搜索服务号名称「机器之心SOTA模型」或 ID 「sotaai」,关注 SOTA!模型服务号,即可通过服务号底部菜单栏使用平台功能,更有最新AI技术、开发资源及社区动态定期推送。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号