文本分类 2018-2020 文献分析
文本分类 转自 https://mp.weixin.qq.com/s/0hKzedHimfPtWgzEk49YzA
https://mp.weixin.qq.com/s/0hKzedHimfPtWgzEk49YzA
A Survey on Text Classification: From Shallow to Deep Learning,2020[1]
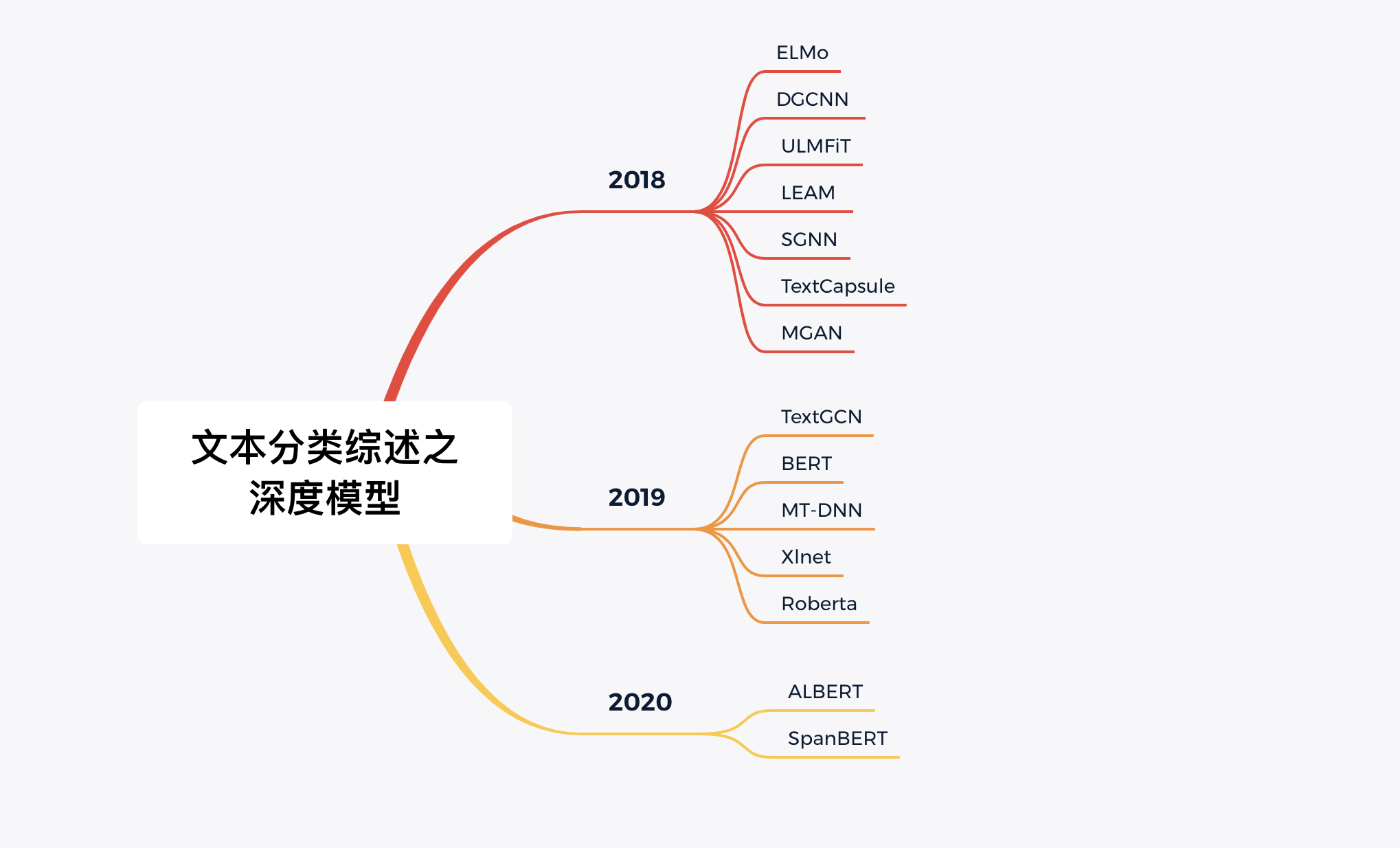
2018
Multi-grained attention network for aspect-level sentiment classification[2]
主要贡献
多粒度注意力网络,结合粗粒度和细粒度注意力来捕捉aspect和上下文在词级别上的交互;aspect对齐损失来描述拥有共同上下文的aspect之间的aspect级别上的相互影响。
Investigating capsule networks with dynamic routing for text classification[3]
在这项研究中,我们探索了用于文本分类,具有动态路由的胶囊网络。我们提出了三种策略来稳定动态路由的过程,以减轻某些可能包含“背景”信息,或尚未成功训练的噪声胶囊的影响。
Constructing narrative event evolutionary graph for script event prediction[4]
脚本事件预测需要模型在已知现有事件的上下文信息的情况下,预测对应的上下文事件。以往的模型主要基于事件对或事件链,这种模式无法充分利用事件之间的密集连接,在某种程度上这会限制模型对事件的预测能力。为了解决这个问题,我们提出构造一个事件图来更好地利用事件网络信息进行脚本事件预测。特别是,我们首先从大量新闻语料库中提取叙事事件链,然后根据提取的事件链来构建一个叙事事件进化图(narrative event evolutionary graph ,NEEG)。NEEG可以看作是描述事件进化原理和模式的知识库。
为了解决NEEG上的推理问题,我们提出了可放缩图神经网络(SGNN)来对事件之间的交互进行建模,并更好地学习事件的潜在表示。SGNN每次都只处理相关的节点,而不是在整个图的基础上计算特征信息,这使我们的模型能在大规模图上进行计算。通过比较输入上下文事件的特征表示与候选事件特征表示之间的相似性,我们可以选择最合理的后续事件。
SGM: sequence generation model for multi-label classification[5]
多标签分类是NLP任务中一项重要而又具有挑战性的任务。相较于单标签分类,由于多个标签之间趋于相关,因而更加复杂。现有方法倾向于忽略标签之间的相关性。此外,文本的不同部分对于预测不同的标签可能有不同的贡献,然而现有模型并未考虑这一点。
在本文中,我们提出将多标签分类任务视为序列生成问题,并用具有新颖解码器结构的序列生成模型来解决该问题。
Joint embedding of words and labelsfor text classification[6]
在对文本序列进行表征学习时,单词嵌入是捕获单词之间语义规律的有效中间表示。在本文中,我们提出将文本分类视为标签与单词的联合嵌入问题:每个标签与单词向量一起嵌入同一向量空间。
我们引入了一个注意力框架,该框架可测量文本序列和标签之间嵌入的兼容性。该注意力框架在带有标签标记的数据集上进行训练,以确保在给定文本序列的情况下,相关单词的权重高于不相关单词的权重。我们的方法保持了单词嵌入的可解释性,并且还具有内置的能力来利用替代信息源,来作为输入文本序列信息的补充。
Universal language model fine-tuning for text classification[7]
归纳迁移学习在CV领域大放异彩,但并未广泛应用于NLP领域,NLP领域的现有方法仍然需要针对特定任务进行模型修改并从头开始训练。因此本文提出了通用语言模型微调(Universal Language Model Fine-tuning ,ULMFiT),一种可以应用于NLP中任何任务的高效率迁移学习方法,并介绍了对语言模型进行微调的关键技术。
Large-scale hierarchical text classification withrecursively regularized deep graph-cnn[8]
将文本分类按主题进行层次分类是一个常见且实际的问题。传统方法仅使用单词袋(bag-of-words)并取得了良好的效果。但是,当有许多具有不同的主题粒度标签时,词袋的表征能力可能不足。鉴于深度学习模型已被证明可以有效地自动学习图像数据的不同表示形式,因此值得研究哪种方法是文本表征学习的最佳方法。
在本文中,我们提出了一种基于graph-CNN的深度学习模型,该模型首先将文本转换为单词图,然后使用图卷积运算对词图进行卷积。将文本表示为图具有捕获非连续和长距离语义信息的优势。CNN模型的优势在于可以学习不同级别的语义信息。为了进一步利用标签的层次结构,我们使用标签之间的依赖性来深度网络结构进行正则化。
Deep contextualized word rep-resentations[9]
我们介绍了一种新型的深层上下文词表示形式,该模型既可以对以下信息进行建模(1)单词使用方法的复杂特征(例如语法和语义) (2)这些用法在语言上下文之间的变化方式(即建模多义性)。我们的词向量是深度双向语言模型(biLM)内部状态的学习函数,双向语言模型已在大型文本语料库上进行了预训练。
2019
Roberta: A robustly optimized BERT pretraining approach[10]
主要贡献
更多训练数据、更大batch size、训练时间更长;去掉NSP;训练序列更长;动态调整Masking机制,数据copy十份,每句话会有十种不同的mask方式。
TL;DR
语言模型的预训练能带来显著的性能提升,但详细比较不同的预训练方法仍然具有挑战性,这是因为训练的计算开销很大,并且通常是在不同大小的非公共数据集上进行的,此外超参数的选择对最终结果有很大的影响。
本文提出了一项针对BERT预训练的复制研究,该研究仔细测试了许多关键超参数和训练集大小对预训练性能的影响。我们发现BERT明显训练不足,并且在经过预训练后可以达到甚至超过其后发布的每个模型的性能。
Xlnet: Generalized autoregressive pretraining for language understanding[11]
主要贡献
采用自回归(AR)模型替代自编码(AE)模型,解决mask带来的负面影响;双流自注意力机制;引入transformer-xl,解决超长序列的依赖问题;采用相对位置编码
TL;DR
凭借对双向上下文进行建模的能力,与基于自回归语言模型的预训练方法(GPT)相比,基于像BERT这种去噪自编码的预训练方法能够达到更好的性能。然而,由于依赖于使用掩码(masks)去改变输入,BERT忽略了屏蔽位置之间的依赖性并且受到预训练与微调之间差异的影响。结合这些优缺点,我们提出了XLNet,这是一种通用的自回归预训练方法,其具有以下优势:
- 通过最大化因式分解次序的概率期望来学习双向上下文,
- 由于其自回归公式,克服了BERT的局限性。
Multi-task deep neural networks for natural language understanding[12]
主要贡献
多任务学习机制训练模型,提高模型的泛化性能。
TL;DR
本文提出了一种多任务深度神经网络 (MT-DNN) ,用于跨多种自然语言理解任务(NLU)的学习表示。MT-DNN 不仅利用大量跨任务数据,而且得益于一种正则化效果,这种效果可以帮助产生更通用的表示,从而有助于扩展到新的任务和领域。MT-DNN 扩展引入了一个预先训练的双向转换语言模型BERT。
BERT: pre-training of deep bidirectional transformers for language understanding[13]
主要贡献
BERT是双向的Transformer block连接,增加词向量模型泛化能力,充分描述字符级、词级、句子级关系特征。真正的双向encoding,Masked LM类似完形填空;transformer做encoder实现上下文相关,而不是bi-LSTM,模型更深,并行性更好;学习句子关系表示,句子级负采样
TL;DR
我们介绍了一种新的语言表示模型BERT,它表示Transformers的双向编码器表示。与最近的语言表示模型不同(Peters et al., 2018; Radford et al., 2018),BERT通过在所有层的上下文联合调节来预训练深层双向表示。因此,只需一个额外的输出层就可以对预先训练好的BERT表示进行微调,以便为各种任务创建最先进的模型,例如问答和语言推断,而无需基本的任务特定架构修改。
Graph convolutional networks for text classification[14]
主要贡献
构建基于文本和词的异构图,在GCN上进行半监督文本分类,包含文本节点和词节点,document-word边的权重是TF-IDF,word-word边的权重是PMI,即词的共现频率。
TL;DR
文本分类是自然语言处理中的一个重要而经典的问题。已经有很多研究将卷积神经网络 (规则网格上的卷积,例如序列) 应用于分类。然而,只有个别研究探索了将更灵活的图卷积神经网络(在非网格上卷积,如任意图)应用到该任务上。
在这项工作中,我们提出使用图卷积网络(GCN)来进行文本分类。基于词的共现关系和文档词的关系,我们为整个语料库构建单个文本图,然后学习用于语料库的文本图卷积网络(text GCN)。我们的text-GCN首先对词语和文本使用one-hot编码进行初始化,然后在已知文档类标签的监督下联合学习单词和文本的嵌入(通过GCN网络传播)。
2020
Spanbert: Improving pre-training by representing and predicting spans[15]
主要贡献
Span Mask机制,不再对随机的单个token添加mask,随机对邻接分词添加mask;Span Boundary Objective(SBO)训练,使用分词边界表示预测被添加mask分词的内容;一个句子的训练效果更好。
TL;DR
提出了一种名为SpanBERT的预训练方法,旨在更好地表示和预测文本范围。我们的方法通过在BERT模型上进行了以下改进:
- 在进行单词遮蔽时,屏蔽随机范围内的token,而不是单个随机的token
- 训练跨度边界表示来预测屏蔽跨度的整个内容,而不依赖于其中的单个标记表示。
ALBERT: A lite BERT for self-supervised learning of language representations[16]
主要贡献
瘦身成功版BERT,全新的参数共享机制。对embedding因式分解,隐层embedding带有上线文信息;跨层参数共享,全连接和attention层都进行参数共享,效果下降,参数减少,训练时间缩短;句间连贯
TL;DR
在对自然语言表示进行预训练时增加模型大小通常会提高下游任务的性能。然而,在某种程度上由于GPU/TPU的内存限制和训练时间的增长,进一步的提升模型规模变得更加困难。为了解决这些问题,我们提出了两种参数缩减技术来降低内存消耗,并提高BERT的训练速度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号