多模态预训练CLIP
多模态预训练CLIP
https://zhuanlan.zhihu.com/p/477760524
先导知识
前言
CLIP(Contrastive Language–Image Pre-training)[1]是OpenAI的第一篇多模态预训练的算法,它延续了GPT系列“大力出奇迹”的传统。模型是一个基于图像和文本并行的多模态模型,然后通过两个分支的特征向量的相似度计算来构建训练目标。为了训练这个模型,OpenAI采集了超过4亿的图像-文本对。CLIP在诸多多模态任务上取得了非常好的效果,例如图像检索,地理定位,视频动作识别等等,而且在很多任务上仅仅通过无监督学习就可以得到和主流的有监督算法接近的效果。CLIP的思想非常简单,但它仅仅通过如此简单的算法也达到了非常好的效果,这也证明了多模态模型强大的发展潜力。
1. 数据收集
对比开放的计算机视觉应用,目前的所有的视觉公开数据集(例如ImageNet等)的应用场景都是非常有限的,为了学习到通用的图像-文本多模态通用特征,我们首先要做的便是采集足够覆盖开放计算机视觉领域的数据集。这里OpenAI采集了一个总量超过4亿图像-文本对的数据集WIT(WebImage Text)。为了尽可能的提高数据集在不同场景下的覆盖度,WIT的首先使用在英文维基百科中出现了超过100次的单词构建了50万个查询,并且使用WordNet进行了近义词的替换。为了实现数据集的平衡,每个查询最多取2万个查询结果。
2. 算法讲解
2.1 学习目标:对比学习预训练
CLIP的核心思想是将图像和文本映射到同一个特征空间。这个特征空间是一个抽象的概念,例如当我们看到一条狗的图片的时候,我们心中想的是狗,当我们读到狗的时候我们想的也是狗,那么我们心中想象的狗,便是“特征空间”。
所以CLIP也是由两个编码器组成,如图1所示:
- 图像编码器:用于将图像映射到特征空间;
- 文本编码器:用于将文本映射到相同的特征空间。
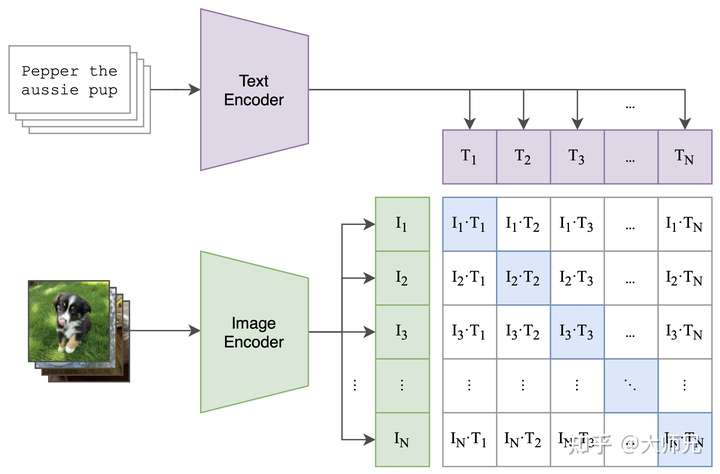
图1:CLIP的对比学习预训练
在模型训练过程中,我们取到的每个batch由
个图像-文本对组成。这 个图像送入到图像编码器中会得到 个图像特征向量 ,同理将这 个文本送入到文本编码器中我们可以得到 个文本特征向量 。因为只有在对角线上的图像和文本是一对,所以CLIP的训练目标是让是一个图像-文本对的特征向量相似度尽可能高,而不是一对的相似度尽可能低,这里相似度的计算使用的是向量内积。通过这个方式,CLIP构建了一个由 个正样本和
个负样本组成的损失函数。另外,因为不同编码器的输出的特征向量长度不一样,CLIP使用了一个线性映射将两个编码器生成的特征向量映射到统一长度,CLIP的计算过程伪代码如下。
# image_encoder - 残差网络 或者 ViT
# text_encoder - CBOW 或者 文本Transformer
# I[n, h, w, c] - 训练图像
# T[n, l] - 训练文本
# W_i[d_i, d_e] - 训练图像生成的特征向量
# W_t[d_t, d_e] - 训练文本生成的特征向量
# t - softmax的温度(temperature)参数
# 提取多模态的特征
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# 多模态特征向特征空间的映射
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# 计算余弦相似度
logits = np.dot(I_e, T_e.T) * np.exp(t)
# 构建损失函数
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/22.2 图像编码器
CLIP的图像编码器选择了5个不同尺寸的残差网络[2]以及3个不同尺寸的ViT[3],并对模型细节做了调整,具体介绍如下。
2.2.1 残差网络
CLIP采用了ResNet-50作为基础模型,并在其基础上做了若干个调整。主要调整如下:
- 引入了模糊池化[4]:模糊池化的核心点是在降采样之前加一个高斯低通滤波;
- 将全局平均池化(Global Average Pooling)替换为注意力池化,这里的注意力是使用的Transformer中介绍的自注意力(Self-Attention)。
CLIP采用的Transformer共有5组,它们依次是ResNet-50,ResNet-100以及按照EfficientNet的思想对ResNet-50分别作
倍, 倍和
倍的缩放得到的模型,表示为ResNet-50x4,ResNet-50x16,ResNet-50x64。
2.2.2 Vision Transformer
CLIP的图像编码器的另一个选择是ViT,这里的改进主要有两点:
- 在patch embedding和position embedding后添加一个LN;
- 换了初始化方法。
ViT共训练了ViT-B/32,ViT-B/16以及ViT-L/14三个模型。
2.3 文本编码器
CLIP的文本编码器使用的是Transformer[5],它共有12层,512的隐层节点数以及8个头。
2.4 CLIP用于图像识别
当训练完模型之后,CLIP模型的效果实现了图像和文本向同一个特征空间映射的能力。当进行图像识别时,我们将待识别的图像映射成一个特征向量。同时我们将所有的类别文本转换成一个句子,然后将这个句子映射成另外一组特征向量。文本特征向量和图像特征向量最相近的那一个便是我们要识别的目标图像的类,如图2所示。
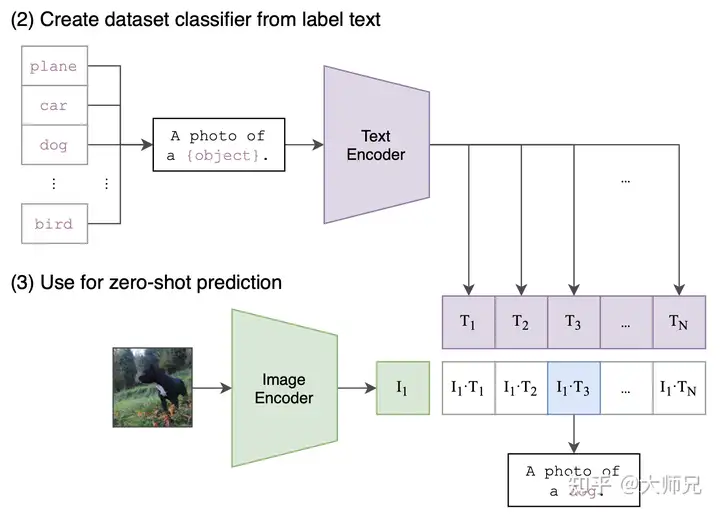
图2:CLIP用于图像分类
3. 模型效果
在论文中,作者对CLIP进行了大篇幅的效果的讨论,我在这里对其重要点进行了汇总。
3.1 优点
CLIP的主要优点有:
- 训练高效:CLIP采取了对比学习的训练方式,可以在一个大小为N的batch中同时构建
- 个优化目标,实现简单快捷,计算高效。此外CLIP的对比学习的训练方式也比基于Image Caption构建的预训练任务简单很多,模型的收敛速度也快了很多;
- 方便迁移:CLIP图像对应的标签不再是一个值了,而是一个句子。这就让模型映射到足够细粒度的类别上提供了可操作空间。由此我们也可以对这个细粒度的映射进行人为控制,进而规避一些涉黄,涉政,涉种族歧视等敏感话题;
- 全局学习:CLIP学习的不再是图像中的一个物体,而是整个图像中的所有信息,不仅包含图像中的目标,还包含这些目标之间的位置,语义等逻辑关系。这便于将CLIP迁移到任何计算机视觉模型上。这也就是为什么CLIP可以在很多看似不相关的下游任务上(OCR等)取得令人意外的效果。
3.2 缺点
CLIP的主要缺点有:
- 数据集:虽然CLIP采取了4亿的图像文本对的数据集,但这4亿的图像文本对并未对外开源。且构建这4亿数据的5万条查询语句介绍的也不详细。而且从它介绍的数据集构建方式来看,它的这种构建数据集的方式还略显单薄,而整个计算机视觉任务是非常庞大且复杂的。如何构建一个分布更合理且全面的数据集是一个非常值得探讨的方向。
- 通用效果:CLIP在论文和它的官方网站上也说了CLIP的一些缺点,例如更细粒度的分类任务,数据集未覆盖到的任务上的表现。这些从本质上来看还是说明了CLIP还是一个有偏的模型。目前看来仅仅通过它的4亿条数据以及对比学习预训练还不足以让模型学习到在NLP上那些通用的能力,这一方向也亟待提升。
- 夸大零样本:CLIP在论文中以及一些宣传上,有些过分夸大它零样本学习(zero-shot learning)的能力。从它的模型效果来看,CLIP还是通过庞大的数据集来尽可能的覆盖下游任务,而它在未见过的数据上表现非常不理想。我认为这种通过庞大的数据集覆盖尽可能多的任务的训练方式,并不能证明模型的零样本学习的能力。因为在更传统的计算机视觉中,零样本更应该是DBM这类生成模型才有的效果。
4. 总结
CLIP是一个OpenAI特色非常重的文章,一是表现在它采集了大量的数据以及使用了大量的训练资源,二是不是非常侧重算法上的创新。这充分体现了目前搞预训练正逐步成为企业垄断的方向,表现在无论是数据,还是计算资源,都是个人和小机构无法承担的。CLIP的技术突破不大,但是效果非常惊艳,作为多模态预训练的算法之一,充分证明了这个方向庞大的科研潜力,起到了抛砖引玉的作用。
Reference
[1] Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International Conference on Machine Learning. PMLR, 2021.
[2] He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[3] Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).
[4] Zhang, Richard. "Making convolutional networks shift-invariant again." International conference on machine learning. PMLR, 2019.
[5] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号