self-attention 自注意力机制 2, 多头自注意力机制
https://blog.csdn.net/Michale_L/article/details/126549946
GOOD
三、Self-Attention详解
针对输入是一组向量,输出也是一组向量,输入长度为N(N可变化)的向量,输出同样为长度为N 的向量。
3.1 单个输出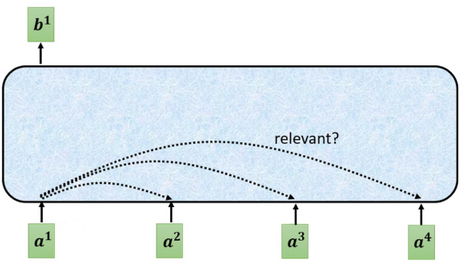
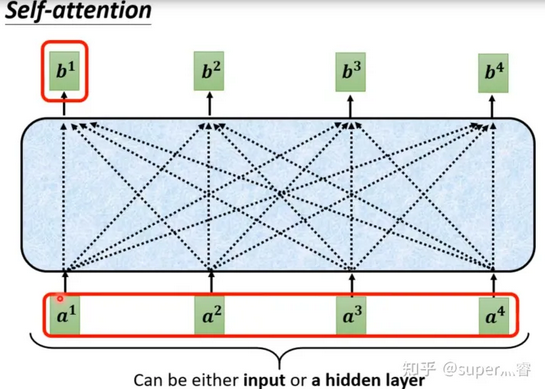
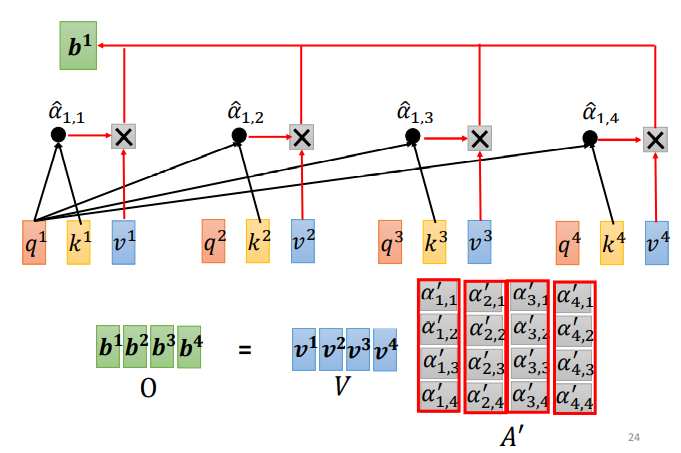
对于每一个输入向量a,经过蓝色部分self-attention之后都输出一个向量b,这个向量b是考虑了所有的输入向量对a1产生的影响才得到的,这里有四个词向量a对应就会输出四个向量b。
下面以b1的输出为例
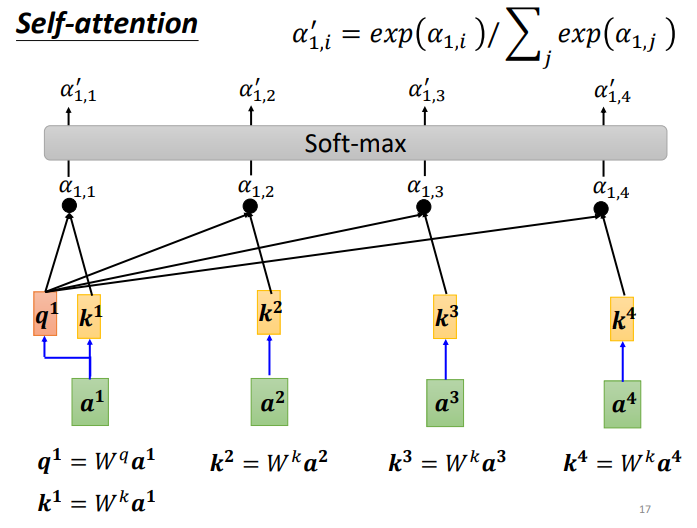
首先,如何计算sequence中各向量与a1的关联程度,有下面两种方法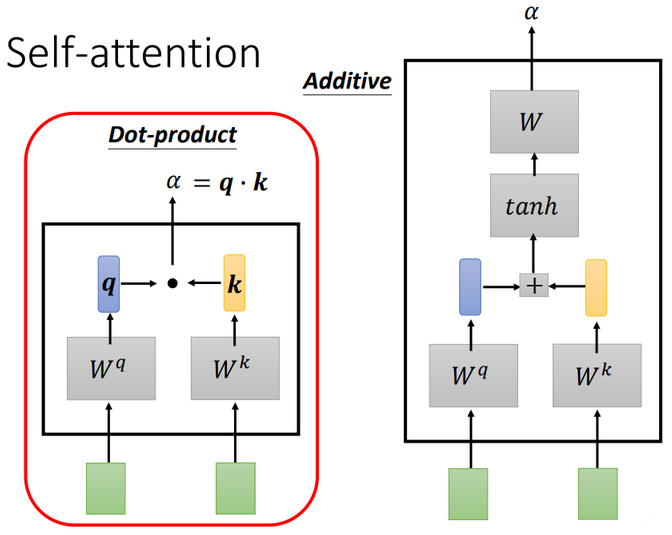
Dot-product方法是将两个向量乘上不同的矩阵w,得到q和k,做点积得到α,transformer中就用到了Dot-product。
上图中绿色的部分就是输入向量 a1 和 a2,灰色的 Wq 和 Wk 为权重矩阵,需要学习来更新,用 a1 去和 Wq 相乘,得到一个向量 q,然后使用 a2 和 Wk 相乘,得到一个数值 k。最后使用 q 和 k 做点积,得到 α。α也就是表示两个向量之间的相关联程度。
上图右边加性模型这种机制也是输入向量与权重矩阵相乘,后相加,然后使用tanh投射到一个新的函数空间内,再与权重矩阵相乘,得到最后的结果。
可以计算每一个α(又称为attention score),q称为query,k称为key
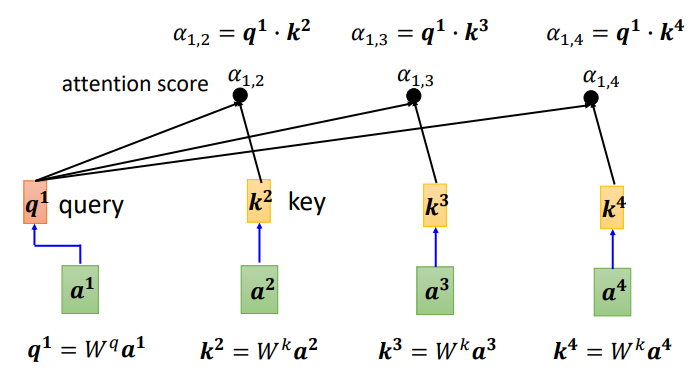
另外,也可以计算 a1 和自己的关联性,再得到各向量与 a1 的相关程度之后,用softmax计算出一个attention distribution,这样就把相关程度归一化,通过数值就可以看出哪些向量是和a1最有关系。
下面需要根据 α′ 抽取sequence里重要的信息:
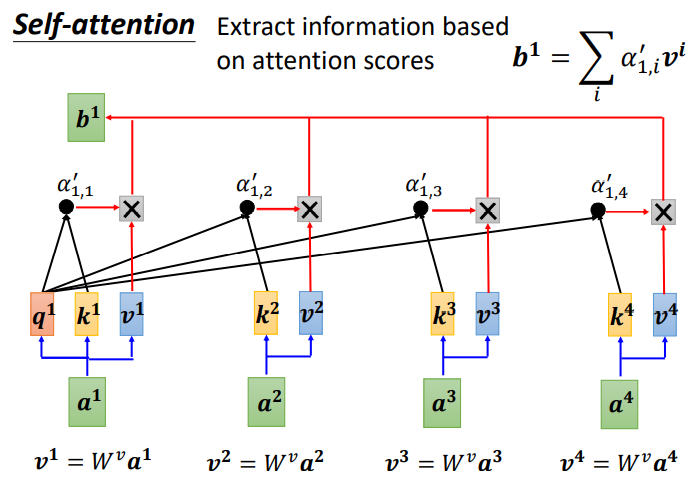
先求 v,v 就是键值 value,v 和 q、k 计算方式相同,也是用输入 a 乘以权重矩阵 W,得到 v 后,与对应的 α′ 相乘,每一个 v 乘与 α' 后求和,得到输出 b1。
如果 a1 和 a2 关联性比较高, α1,2′ 就比较大,那么,得到的输出 b1 就可能比较接近 v2 ,即 attention score 决定了该 vector 在结果中占的分量;
矩阵运算
用矩阵运算表示b1的生成:
Step 1:q、k、v的矩阵形式生成
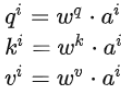
写成矩阵形式:
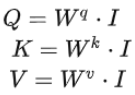
把4个输入a拼成一个矩阵,这个矩阵有4个column,也就是a1到a4,
乘上相应的权重矩阵W,得到相应的矩阵Q、K、V,分别表示query,key和value。
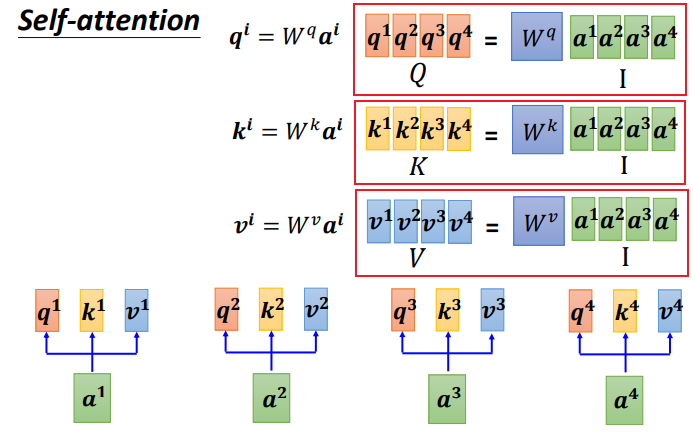
三个W是我们需要学习的参数
Step 2:利用得到的 Q 和 K 计算每两个输入向量之间的相关性,也就是计算 attention 的值 α, α 的计算方法有多种,通常采用点乘的方式。
先针对 q1,通过与 k1 到 k4 拼接成的矩阵 K 相乘,得到 拼接成的矩阵。
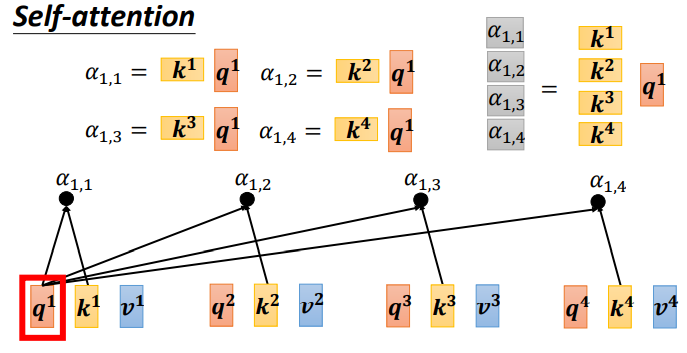
同样,q1到q4也可以拼接成矩阵Q直接与矩阵K相乘:

公式为:
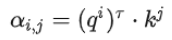
矩阵形式:
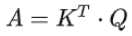
矩阵A中的每一个值记录了对应的两个输入向量的Attention的大小α,A'是经过softmax归一化后的矩阵。
Step 3:利用得到的A'和V,计算每个输入向量a对应的self-attention层的输出向量b:
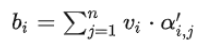
写成矩阵形式:

对self-attention操作过程做个总结,输入是I,输出是O:
矩阵Wq、 Wk 、Wv是需要学习的参数。
四、Multi-head Self-attention 多头自注意力机制
self-attention的进阶版本 Multi-head Self-attention,多头自注意力机制。
因为相关性有很多种不同的形式,有很多种不同的定义,所以有时不能只有一个 q,要有多个 q,不同的 q 负责不同种类的相关性。
对于1个输入a
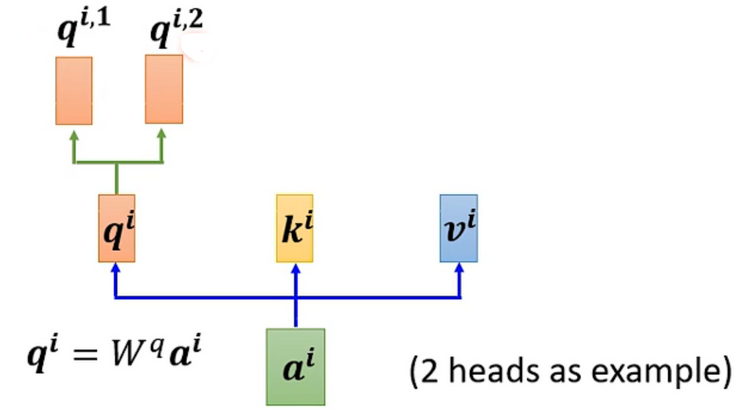
首先,和上面一样,用 a 乘权重矩阵 W 得到 q^i,然后再用 q^i 乘两个不同的 W,得到两个不同的 q^{i,n},i 代表的是位置,1和2代表的是这个位置的第几个 q。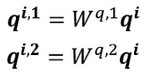
这上面这个图中,有两个head,代表这个问题有两种不同的相关性。
同样,k 和 v 也需要有多个,两个 k、v 的计算方式和 q 相同,都是先算出来 ki 和 vi,然后再乘两个不同的权重矩阵。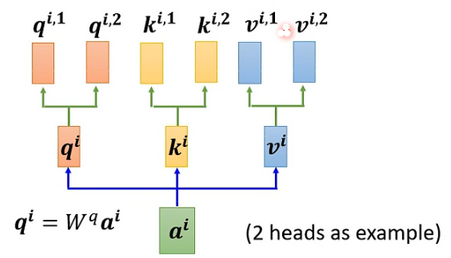
对于多个输入向量也一样,每个向量都有多个head:

算出来 q、k、v 之后怎么做 self-attention 呢?
和上面讲的过程一样,只不过是1那类的一起做,2那类的一起做,两个独立的过程,算出来两个 b。
对于1: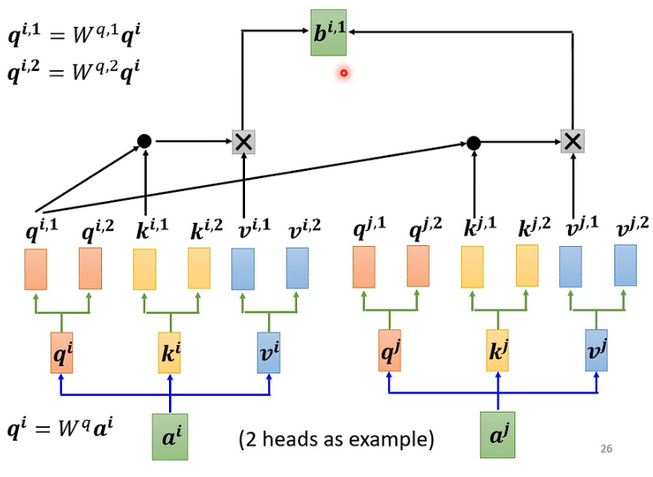
对于2: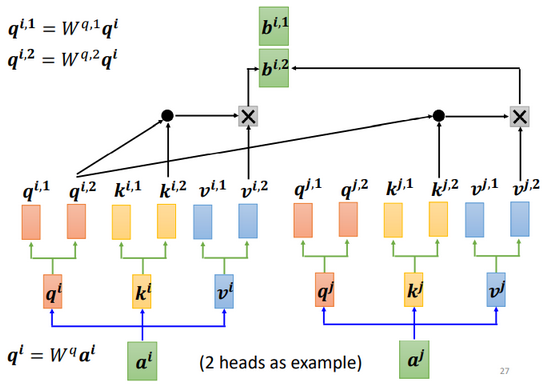
这只是两个head的例子,有多个head过程也一样,都是分开算b。
最后,把bi,1,bi,2拼接成矩阵再乘权重矩阵W,得到bi,也就是这个self- attention向量ai的输出,如下图所示:

五、Positional Encoding
在训练 self attention 的时候,实际上对于位置的信息是缺失的,没有前后的区别,上面讲的 a1,a2,a3 不代表输入的顺序,只是指输入的向量数量,不像 RNN,对于输入有明显的前后顺序,比如在翻译任务里面,对于“机器学习”,机器学习依次输入。而 self-attention 的输入是同时输入,输出也是同时产生然后输出的。
如何在Self-Attention里面体现位置信息呢?就是使用 Positional Encoding。
也就是新引入了一个位置向量ei,非常简单,如下图所示: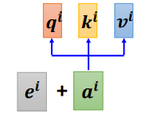
每一个位置设置一个 vector,叫做 positional vector,用 ei 表示,不同的位置有一个专属的 ei。
如果 ai 加上了 ei,就会体现出位置的信息,i 是多少,位置就是多少。
vector长度是人为设定的,也可以从数据中训练出来。
原文链接:https://blog.csdn.net/Michale_L/article/details/126549946

 浙公网安备 33010602011771号
浙公网安备 33010602011771号