注意力机制 (1)
注意力机制 nice
注意力机制在自然语言处理领域十分火热,克服了以往seq2seq翻译定位不准的问题,加强了词的前后联系,能够根据当前的语境,合理分配候选词的权重,提升翻译的准确率。
注意力机制的原理便是寻找当前语境(当前状态)与各个候选词之间的匹配度,计算各个候选词的得分,最终选取合成最佳的词汇。
1. 为什么要引入注意力机制
在Attention诞生之前,已经有CNN和RNN及其变体模型了,那为什么还要引入attention机制?主要有两个方面的原因,如下:
(1)计算能力的限制:当要记住很多“信息“,模型就要变得更复杂,然而目前计算能力依然是限制神经网络发展的瓶颈。
(2)优化算法的限制:LSTM只能在一定程度上缓解RNN中的长距离依赖问题,且信息“记忆”能力并不高。
2. 什么是注意力机制
在介绍什么是注意力机制之前,先让大家看一张图片。当大家看到下面图片,会首先看到什么内容?当过载信息映入眼帘时,我们的大脑会把注意力放在主要的信息上,这就是大脑的注意力机制。

同样,当我们读一句话时,大脑也会首先记住重要的词汇,这样就可以把注意力机制应用到自然语言处理任务中,于是人们就通过借助人脑处理信息过载的方式,提出了Attention机制。
3.注意力机制模型
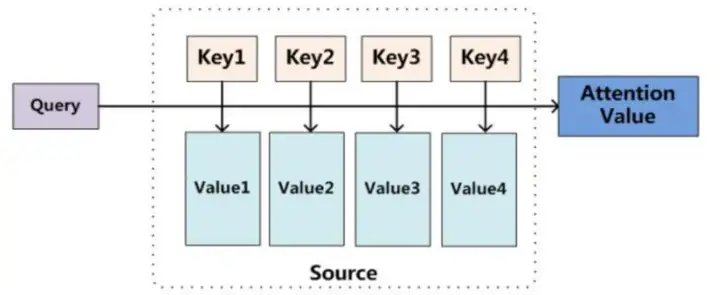
从本质上理解,Attention是从大量信息中筛选出少量重要信息,并聚焦到这些重要信息上,忽略大多不重要的信息。权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
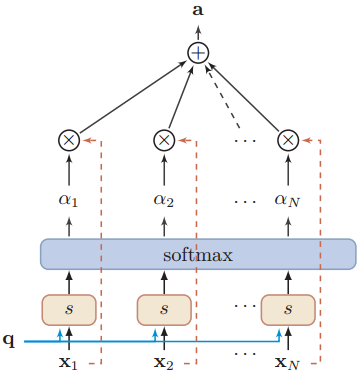
至于Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理;这样,可以将Attention的计算过程抽象为如图展示的三个阶段。

在第一个阶段,可以引入不同的函数和计算机制,根据Query和某个 Keyi ,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:

第一阶段产生的分值根据具体产生的方法不同其数值取值范围也不一样,第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:
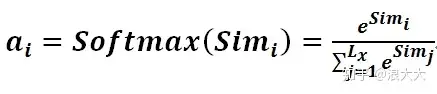
第二阶段的计算结果 ai 即为 Valuei 对应的权重系数,然后进行加权求和即可得到Attention数值:
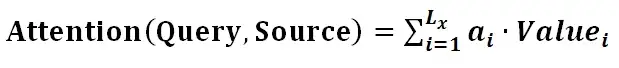
通过如上三个阶段的计算,即可求出针对Query的Attention数值,目前绝大多数具体的注意力机制计算方法都符合上述的三阶段抽象计算过程。

注意力机制是一种通用的思想,本身不依赖于特定框架。
REF
https://blog.csdn.net/qq_37492509/article/details/114991482
https://www.jianshu.com/p/3968af85d3cb
========================================================================================
普通模式
用数学语言来表达这个思想就是:用表示N个输入信息,为了节省计算资源,不需要让神经网络处理这N个输入信息,而只需要从X中选择一些与任务相关的信息输进行计算。软性注意力(Soft Attention)机制是指在选择信息的时候,不是从N个信息中只选择1个,而是计算N个输入信息的加权平均,再输入到神经网络中计算。相对的,硬性注意力(Hard Attention)就是指选择输入序列某一个位置上的信息,比如随机选择一个信息或者选择概率最高的信息。但一般还是用软性注意力机制来处理神经网络的问题。
注意力值的计算是任务处理中非常重要的一步。
注意力值的计算可以分为两步:
(1)在所有输入信息上计算注意力分布
(2)根据注意力分布来计算输入信息的加权平均。
1、注意力分布
给定这样一个场景:把输入信息向量X看做是一个信息存储器,现在给定一个查询向量q,用来查找并选择X中的某些信息,那么就需要知道被选择信息的索引位置。采取“软性”选择机制,不是从存储的多个信息中只挑出一条信息来,而是雨露均沾,从所有的信息中都抽取一些,只不过最相关的信息抽取得就多一些。
于是定义一个注意力变量来表示被选择信息的索引位置,即
来表示选择了第i个输入信息,然后计算在给定了q和X的情况下,选择第i个输入信息的概率
:
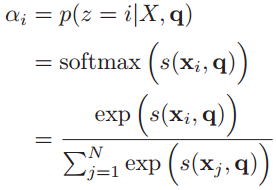
其中构成的概率向量就称为注意力分布(Attention Distribution)。
是注意力打分函数,有以下几种形式:
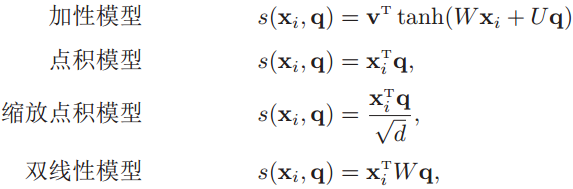
其中W、U和v是可学习的网络参数,d是输入信息的维度。
2、加权平均
注意力分布表示在给定查询q时,输入信息向量X中第i个信息与查询q的相关程度。采用“软性”信息选择机制给出查询所得的结果,就是用加权平均的方式对输入信息进行汇总,得到Attention值:
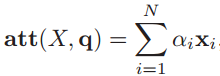
下图是计算Attention值的过程图:
REF
https://aistudio.baidu.com/aistudio/projectdetail/2401371
https://blog.csdn.net/qq_37492509/article/details/114991482
========================================================================================
注意力机制可以解决什么问题?
神经网络中的注意力机制(Attention Mechanism)是在计算能力有限的情况下,将计算资源分配给更重要的任务,同时解决信息超载问题的一种资源分配方案。在神经网络学习中,一般而言模型的参数越多则模型的表达能力越强,模型所存储的信息量也越大,但这会带来信息过载的问题。那么通过引入注意力机制,在众多的输入信息中聚焦于对当前任务更为关键的信息,降低对其他信息的关注度,甚至过滤掉无关信息,就可以解决信息过载问题,并提高任务处理的效率和准确性。
这就类似于人类的视觉注意力机制,通过扫描全局图像,获取需要重点关注的目标区域,而后对这一区域投入更多的注意力资源,获取更多与目标有关的细节信息,而忽视其他无关信息。通过这种机制可以利用有限的注意力资源从大量信息中快速筛选出高价值的信息。
1. Attention机制由来
注意力机制借鉴了人类注意力的说法,比如我们在阅读过程中,会把注意集中在重要的信息上。在训练过程中,输入的权重也都是不同的,注意力机制就是学习到这些权重。最开始attention机制在CV领域被提出来,但后面广泛应用在NLP领域。
2. Encoder-Decoder 框架
需要注意的是,注意力机制是一种通用的思想和技术,不依赖于任何模型,换句话说,注意力机制可以用于任何模型。只是我们介绍注意力机制的时候更多会用encoder-decoder框架做介绍。
Encoder-Decoder 框架可以看作是一种深度学习领域的研究模式,应用场景异常广泛。下图是文本处理领域里 Encoder-Decoder 框架最抽象的一种表示。
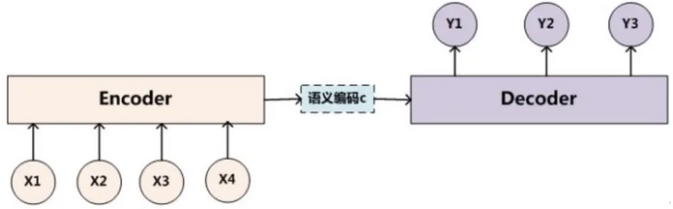
图1:Encoder-Decoder框架
在NLP领域,可以把Encoder-Decoder框架看作是:将一个句子(篇章)转换成另一个句子(篇章)。最直观的例子就是机器翻译,将一种语言的表达翻译成另一种语言。对于句子对<source,target>,将给定输入句子source,通过Encoder-Decoder框架生成目标句子target。其中,source和target都是一组单词序列:
Encoder是对source进行编码,转换成中间语义:
对于解码器Decoder,其任务是根据中间语义C和当前已经生成的历史信息来生成下一时刻要生成的单词:
3. 最常见的attention模型——Soft Attention
我们从最常见的 Soft Attention 模型开始介绍 attention 的基本思路。
在上一节介绍的 Encoder-Decoder 框架是没有体现出“注意力模型”的,为什么这么说呢?我们可以看下target的生成过程:
其中,是Decoder的非线性变换函数。从上面式子中可以看出,在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子source的语义编码
都是一样的,没有任何区别。而语义编码
又是通过对source经过Encoder编码产生的,因此对于target中的任何一个单词,source中任意单词对某个目标单词
来说影响力都是相同的,这就是为什么说图1中的模型没有体现注意力的原因。
没有引入注意力的模型在输入句子比较短的时候问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,因此很多细节信息会被丢失。这也是为何要引入注意力模型的重要原因。
下面从一个例子入手,具体说明下注意力机制是怎么做的。
比如机器翻译任务,输入source是英文句子:Tom chase Jerry;输出target想得到中文:汤姆 追逐 杰瑞。在翻译“Jerry”这个单词的时候,在普通Encoder-Decoder模型中,source里的每个单词对“杰瑞”的贡献是相同的,很明显这样不太合理,因为“Jerry”对于翻译成“杰瑞”更重要。如果引入Attention模型,在生成“杰瑞”的时候,应该体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
每个英文单词的概率代表了翻译当前单词“杰瑞”时注意力分配模型分配给不同英文单词的注意力大小。同理,对于target中任意一个单词都应该有对应的source中的单词的注意力分配概率,可以把所有的注意力概率看作,其中
表示source长度,
表示target长度。而且,由于注意力模型的加入,原来在生成target单词时候的中间语义
就不再是固定的,而是会根据注意力概率变化的
,加入了注意力模型的Encoder-Decoder框架就变成了如图2所示。

根据图2,生成target的过程就变成了下面形式:
因为每个可能对应着不同的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:
其中,表示 Encoder 对输入英文单词的某种变换函数,比如如果Encoder是用RNN模型的话,这个
函数的结果往往是某个时刻输入
后隐层节点的状态值;
g代表 Encoder 根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,即:
其中,代表输入句子Source的长度,
代表在Target输出第
个单词时Source输入句子第
个单词的注意力分配系数,而
则是Source输入句子中第
个单词的语义编码。假设下标
就是上面例子所说的“汤姆”生成如下图:
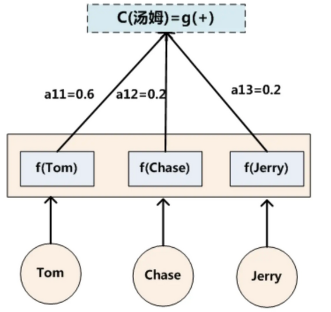
图3: C(汤姆)的计算过程
假设Ci中那个i就是上面的“汤姆”,那么Lx就是3,代表输入句子的长度,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”),对应的注意力模型权值分别是0.6,0.2,0.2,所以g函数就是个加权求和函数。如果形象表示的话,翻译中文单词“汤姆”的时候,数学公式对应的中间语义表示Ci的形成过程类似图3.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号