Keras.layers各种层介绍
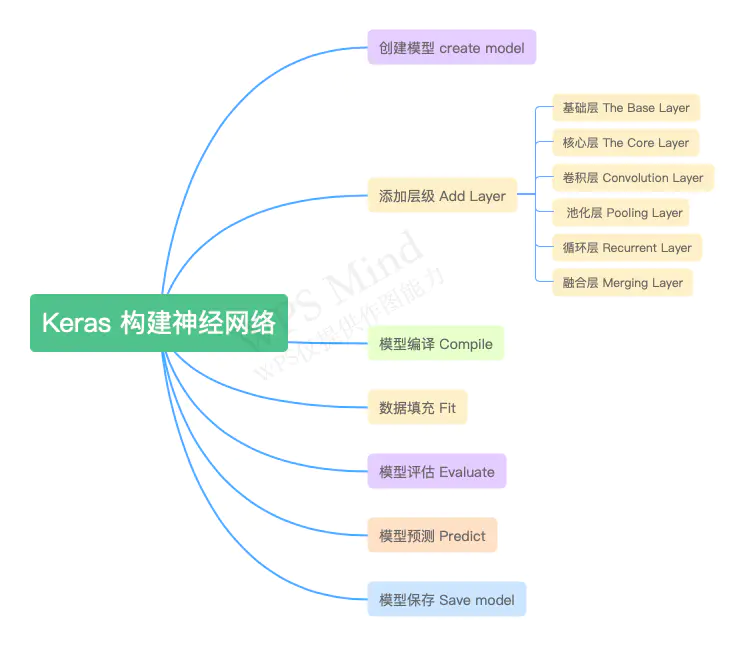
一、网络层
keras的层主要包括:
常用层(Core)、卷积层(Convolutional)、池化层(Pooling)、局部连接层、递归层(Recurrent)、嵌入层( Embedding)、高级激活层、规范层、噪声层、包装层,当然也可以编写自己的层。
对于层的操作
layer.get_weights() #返回该层的权重(numpy array)
layer.set_weights(weights)#将权重加载到该层
config = layer.get_config()#保存该层的配置
layer = layer_from_config(config)#加载一个配置到该层
#如果层仅有一个计算节点(即该层不是共享层),则可以通过下列方法获得输入张量、输出张量、输入数据的形状和输出数据的形状:
layer.input
layer.output
layer.input_shape
layer.output_shape
#如果该层有多个计算节点。可以使用下面的方法
layer.get_input_at(node_index)
layer.get_output_at(node_index)
layer.get_input_shape_at(node_index)
layer.get_output_shape_at(node_index)1、常用网络层
1.1、Dense层(全连接层)
keras.layers.core.Dense(units,activation=None,use_bias=True,kernel_initializer='glorot_uniform',bias_initializer='zeros',kernel_regularizer=None,bias_regularizer=None,activity_regularizer=None,kernel_constraint=None,bias_constraint=None)参数:
- units:大于0的整数,代表该层的输出维度。
- use_bias:布尔值,是否使用偏置项
- kernel_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。
- bias_initializer:偏置向量初始化方法,为预定义初始化方法名的字符串,或用于初始化偏置向量的初始化器。
- regularizer:正则项,kernel为权重的、bias为偏执的,activity为输出的
- constraints:约束项,kernel为权重的,bias为偏执的。
- activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
- input_dim:该层输入的维度
本层实现的运算为
<span id="MathJax-Span-2" class="mrow"><span id="MathJax-Span-3" class="mi">o<span id="MathJax-Span-4" class="mi">u<span id="MathJax-Span-5" class="mi">t<span id="MathJax-Span-6" class="mi">p<span id="MathJax-Span-7" class="mi">u<span id="MathJax-Span-8" class="mi">t<span id="MathJax-Span-9" class="mo">=<span id="MathJax-Span-10" class="mi">a<span id="MathJax-Span-11" class="mi">c<span id="MathJax-Span-12" class="mi">t<span id="MathJax-Span-13" class="mi">i<span id="MathJax-Span-14" class="mi">v<span id="MathJax-Span-15" class="mi">a<span id="MathJax-Span-16" class="mi">t<span id="MathJax-Span-17" class="mi">i<span id="MathJax-Span-18" class="mi">o<span id="MathJax-Span-19" class="mi">n<span id="MathJax-Span-20" class="mo">(<span id="MathJax-Span-21" class="mi">d<span id="MathJax-Span-22" class="mi">o<span id="MathJax-Span-23" class="mi">t<span id="MathJax-Span-24" class="mo">(<span id="MathJax-Span-25" class="mi">i<span id="MathJax-Span-26" class="mi">n<span id="MathJax-Span-27" class="mi">p<span id="MathJax-Span-28" class="mi">u<span id="MathJax-Span-29" class="mi">t<span id="MathJax-Span-30" class="mo">,<span id="MathJax-Span-31" class="mi">k<span id="MathJax-Span-32" class="mi">e<span id="MathJax-Span-33" class="mi">r<span id="MathJax-Span-34" class="mi">n<span id="MathJax-Span-35" class="mi">e<span id="MathJax-Span-36" class="mi">l<span id="MathJax-Span-37" class="mo">)<span id="MathJax-Span-38" class="mo">+<span id="MathJax-Span-39" class="mi">b<span id="MathJax-Span-40" class="mi">i<span id="MathJax-Span-41" class="mi">a<span id="MathJax-Span-42" class="mi">s<span id="MathJax-Span-43" class="mo">)
1.2、Activation层
keras.layers.core.Activation(activation)激活层对一个层的输出施加激活函数
参数:
- activation:将要使用的激活函数,为预定义激活函数名或一个Tensorflow/Theano的函数。参考激活函数
输入shape:任意,当使用激活层作为第一层时,要指定input_shape
输出shape:与输入shape相同
1.3、dropout层
keras.layers.core.Dropout(rate, noise_shape=None, seed=None)为输入数据施加Dropout。Dropout将在训练过程中每次更新参数时按一定概率(rate)随机断开输入神经元,Dropout层用于防止过拟合。
参数
- rate:0~1的浮点数,控制需要断开的神经元的比例
- noise_shape:整数张量,为将要应用在输入上的二值Dropout mask的shape,例如你的输入为(batch_size, timesteps, features),并且你希望在各个时间步上的Dropout mask都相同,则可传入noise_shape=(batch_size, 1, features)。
- seed:整数,使用的随机数种子
1.4、Flatten层
keras.layers.core.Flatten()Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
demo:
model = Sequential()
model.add(Convolution2D(64, 3, 3,
border_mode='same',
input_shape=(3, 32, 32)))
# now: model.output_shape == (None, 64, 32, 32)
model.add(Flatten())
# now: model.output_shape == (None, 65536)1.5、Reshape层
keras.layers.core.Reshape(target_shape)Reshape层用来将输入shape转换为特定的shape
参数
- target_shape:目标shape,为整数的tuple,不包含样本数目的维度(batch大小)
输入shape:任意,但输入的shape必须固定。当使用该层为模型首层时,需要指定input_shape参数
输出shape:(batch_size,)+target_shape
demo:
# as first layer in a Sequential model
model = Sequential()
model.add(Reshape((3, 4), input_shape=(12,)))
# now: model.output_shape == (None, 3, 4)
# note: `None` is the batch dimension
# as intermediate layer in a Sequential model
model.add(Reshape((6, 2)))
# now: model.output_shape == (None, 6, 2)
# also supports shape inference using `-1` as dimension
model.add(Reshape((-1, 2, 2)))
# now: model.output_shape == (None, 3, 2, 2)1.6、Permute层
keras.layers.core.Permute(dims)Permute层将输入的维度按照给定模式进行重排,例如,当需要将RNN和CNN网络连接时,可能会用到该层。所谓的重排也就是交换两行
参数
- dims:整数tuple,指定重排的模式,不包含样本数的维度。重拍模式的下标从1开始。例如(2,1)代表将输入的第二个维度重排到输出的第一个维度,而将输入的第一个维度重排到第二个维度
model = Sequential()
model.add(Permute((2, 1), input_shape=(10, 64)))
# now: model.output_shape == (None, 64, 10)
# note: `None` is the batch dimension输入shape:任意,当使用激活层作为第一层时,要指定input_shape
输出shape:与输入相同,但是其维度按照指定的模式重新排列
1.7、RepeatVector层
keras.layers.core.RepeatVector(n)RepeatVector层将输入重复n次
参数
- n:整数,重复的次数
输入shape:形如(nb_samples, features)的2D张量
输出shape:形如(nb_samples, n, features)的3D张量
例子
model = Sequential()
model.add(Dense(32, input_dim=32))
# now: model.output_shape == (None, 32)
# note: `None` is the batch dimension
model.add(RepeatVector(3))
# now: model.output_shape == (None, 3, 32)1.8、Lambda层
keras.layers.core.Lambda(function, output_shape=None, mask=None, arguments=None)本函数用以对上一层的输出施以任何Theano/TensorFlow表达式
参数
- function:要实现的函数,该函数仅接受一个变量,即上一层的输出
- output_shape:函数应该返回的值的shape,可以是一个tuple,也可以是一个根据输入
- shape计算输出shape的函数
- mask: 掩膜
- arguments:可选,字典,用来记录向函数中传递的其他关键字参数
输入shape:任意,当使用该层作为第一层时,要指定input_shape
输出shape:由output_shape参数指定的输出shape,当使用tensorflow时可自动推断
# add a x -> x^2 layer
model.add(Lambda(lambda x: x ** 2))
# add a layer that returns the concatenation
# of the positive part of the input and
# the opposite of the negative part
def antirectifier(x):
x -= K.mean(x, axis=1, keepdims=True)
x = K.l2_normalize(x, axis=1)
pos = K.relu(x)
neg = K.relu(-x)
return K.concatenate([pos, neg], axis=1)
def antirectifier_output_shape(input_shape):
shape = list(input_shape)
assert len(shape) == 2 # only valid for 2D tensors
shape[-1] *= 2
return tuple(shape)
model.add(Lambda(antirectifier,
output_shape=antirectifier_output_shape))1.9、ActivityRegularizer层
keras.layers.core.ActivityRegularization(l1=0.0, l2=0.0)经过本层的数据不会有任何变化,但会基于其激活值更新损失函数值
参数
- l1:1范数正则因子(正浮点数)
- l2:2范数正则因子(正浮点数)
输入shape:任意,当使用该层作为第一层时,要指定input_shape
输出shape:与输入shape相同
2.0、Masking层
keras.layers.core.Masking(mask_value=0.0)2、卷积层Convolutional
2.1、Conv1D层
keras.layers.convolutional.Conv1D(filters, kernel_size, strides=1, padding='valid', dilation_rate=1, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)一维卷积层(即时域卷积),用以在一维输入信号上进行邻域滤波。当使用该层作为首层时,需要提供关键字参数input_shape。例如(10,128)代表一个长为10的序列,序列中每个信号为128向量。而(None, 128)代表变长的128维向量序列。
该层生成将输入信号与卷积核按照单一的空域(或时域)方向进行卷积。如果use_bias=True,则还会加上一个偏置项,若activation不为None,则输出为经过激活函数的输出。
参数
- filters:卷积核的数目(即输出的维度)
- kernel_size:整数或由单个整数构成的list/tuple,卷积核的空域或时域窗长度
- strides:整数或由单个整数构成的list/tuple,为卷积的步长。任何不为1的strides均与任何不为1的dilation_rate均不兼容
- padding:补0策略,为“valid”, “same” 或“causal”,“causal”将产生因果(膨胀的)卷积,即output[t]不依赖于input[t+1:]。当对不能违反时间顺序的时序信号建模时有用。参考WaveNet: A Generative Model for Raw Audio, section 2.1.。“valid”代表只进行有效的卷积,即对边界数据不处理。“same”代表保留边界处的卷积结果,通常会导致输出shape与输入shape相同。
- activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
- dilation_rate:整数或由单个整数构成的list/tuple,指定dilated convolution中的膨胀比例。任何不为1的dilation_rate均与任何不为1的strides均不兼容。
- use_bias:布尔值,是否使用偏置项
- kernel_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
- bias_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
- kernel_regularizer:施加在权重上的正则项,为Regularizer对象
- bias_regularizer:施加在偏置向量上的正则项,为Regularizer对象
- activity_regularizer:施加在输出上的正则项,为Regularizer对象
- kernel_constraints:施加在权重上的约束项,为Constraints对象
- bias_constraints:施加在偏置上的约束项,为Constraints对象
输入shape:形如(samples,steps,input_dim)的3D张量
输出shape:形如(samples,new_steps,nb_filter)的3D张量,因为有向量填充的原因,steps的值会改变
【Tips】可以将Convolution1D看作Convolution2D的快捷版,对例子中(10,32)的信号进行1D卷积相当于对其进行卷积核为(filter_length, 32)的2D卷积。
2.2、Conv2D层
keras.layers.convolutional.Conv2D(filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)二维卷积层,即对图像的空域卷积。该层对二维输入进行滑动窗卷积,当使用该层作为第一层时,应提供input_shape参数。例如input_shape = (128,128,3)代表128*128的彩色RGB图像(data_format='channels_last')
参数
- filters:卷积核的数目(即输出的维度)
- kernel_size:单个整数或由两个整数构成的list/tuple,卷积核的宽度和长度。如为单个整数,则表示在各个空间维度的相同长度。
- strides:单个整数或由两个整数构成的list/tuple,为卷积的步长。如为单个整数,则表示在各个空间维度的相同步长。任何不为1的strides均与任何不为1的dilation_rate均不兼容
- padding:补0策略,为“valid”, “same” 。“valid”代表只进行有效的卷积,即对边界数据不处理。“same”代表保留边界处的卷积结果,通常会导致输出shape与输入shape相同。
- activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
- dilation_rate:单个整数或由两个整数构成的list/tuple,指定dilated convolution中的膨胀比例。任何不为1的dilation_rate均与任何不为1的strides均不兼容。
- data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
- use_bias:布尔值,是否使用偏置项
- kernel_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
- bias_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
- kernel_regularizer:施加在权重上的正则项,为Regularizer对象
- bias_regularizer:施加在偏置向量上的正则项,为Regularizer对象
- activity_regularizer:施加在输出上的正则项,为Regularizer对象
- kernel_constraints:施加在权重上的约束项,为Constraints对象
- bias_constraints:施加在偏置上的约束项,为Constraints对象
输入shape:
‘channels_first’模式下,输入形如(samples,channels,rows,cols)的4D张量。
‘channels_last’模式下,输入形如(samples,rows,cols,channels)的4D张量。
注意这里的输入shape指的是函数内部实现的输入shape,而非函数接口应指定的input_shape,请参考下面提供的例子。
输出shape:
‘channels_first’模式下,为形如(samples,nb_filter, new_rows, new_cols)的4D张量。
‘channels_last’模式下,为形如(samples,new_rows, new_cols,nb_filter)的4D张。量
输出的行列数可能会因为填充方法而改变。
2.3、SeparableConv2D层
keras.layers.convolutional.SeparableConv2D(filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, depth_multiplier=1, activation=None, use_bias=True, depthwise_initializer='glorot_uniform', pointwise_initializer='glorot_uniform', bias_initializer='zeros', depthwise_regularizer=None, pointwise_regularizer=None, bias_regularizer=None, activity_regularizer=None, depthwise_constraint=None, pointwise_constraint=None, bias_constraint=None)该层是在深度方向上的可分离卷积。
可分离卷积首先按深度方向进行卷积(对每个输入通道分别卷积),然后逐点进行卷积,将上一步的卷积结果混合到输出通道中。参数depth_multiplier控制了在depthwise卷积(第一步)的过程中,每个输入通道信号产生多少个输出通道。
直观来说,可分离卷积可以看做讲一个卷积核分解为两个小的卷积核,或看作Inception模块的一种极端情况。
当使用该层作为第一层时,应提供input_shape参数。例如input_shape = (3,128,128)代表128*128的彩色RGB图像。
参数
- filters:卷积核的数目(即输出的维度)
- kernel_size:单个整数或由两个个整数构成的list/tuple,卷积核的宽度和长度。如为单个整数,则表示在各个空间维度的相同长度。
- strides:单个整数或由两个整数构成的list/tuple,为卷积的步长。如为单个整数,则表示在各个空间维度的相同步长。任何不为1的strides均与任何不为1的dilation_rate均不兼容
- padding:补0策略,为“valid”, “same”
。“valid”代表只进行有效的卷积,即对边界数据不处理。“same”代表保留边界处的卷积结果,通常会导致输出shape与输入shape相同。 - activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
- dilation_rate:单个整数或由两个整数构成的list/tuple,指定dilated
- convolution中的膨胀比例。任何不为1的dilation_rate均与任何不为1的strides均不兼容。
- data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
- use_bias:布尔值,是否使用偏置项 depth_multiplier:在按深度卷积的步骤中,每个输入通道使用多少个输出通道
- kernel_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
- bias_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
- depthwise_regularizer:施加在按深度卷积的权重上的正则项,为Regularizer对象
- pointwise_regularizer:施加在按点卷积的权重上的正则项,为Regularizer对象
- kernel_regularizer:施加在权重上的正则项,为Regularizer对象
- bias_regularizer:施加在偏置向量上的正则项,为Regularizer对象
- activity_regularizer:施加在输出上的正则项,为Regularizer对象
- kernel_constraints:施加在权重上的约束项,为Constraints对象
- bias_constraints:施加在偏置上的约束项,为Constraints对象
- depthwise_constraint:施加在按深度卷积权重上的约束项,为Constraints对象
- pointwise_constraint施加在按点卷积权重的约束项,为Constraints对象
输入shape
‘channels_first’模式下,输入形如(samples,channels,rows,cols)的4D张量。
‘channels_last’模式下,输入形如(samples,rows,cols,channels)的4D张量。
注意这里的输入shape指的是函数内部实现的输入shape,而非函数接口应指定的input_shape,请参考下面提供的例子。
输出shape
‘channels_first’模式下,为形如(samples,nb_filter, new_rows, new_cols)的4D张量。
‘channels_last’模式下,为形如(samples,new_rows, new_cols,nb_filter)的4D张量。
输出的行列数可能会因为填充方法而改变
2.4、Conv2DTranspose层
keras.layers.convolutional.Conv2DTranspose(filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)该层是转置的卷积操作(反卷积)。需要反卷积的情况通常发生在用户想要对一个普通卷积的结果做反方向的变换。例如,将具有该卷积层输出shape的tensor转换为具有该卷积层输入shape的tensor。同时保留与卷积层兼容的连接模式。
当使用该层作为第一层时,应提供input_shape参数。例如input_shape = (3,128,128)代表128*128的彩色RGB图像。
参数
- filters:卷积核的数目(即输出的维度)
- kernel_size:单个整数或由两个个整数构成的list/tuple,卷积核的宽度和长度。如为单个整数,则表示在各个空间维度的相同长度。
- strides:单个整数或由两个整数构成的list/tuple,为卷积的步长。如为单个整数,则表示在各个空间维度的相同步长。任何不为1的strides均与任何不为1的dilation_rate均不兼容
- padding:补0策略,为“valid”, “same” 。“valid”代表只进行有效的卷积,即对边界数据不处理。“same”代表保留边界处的卷积结果,通常会导致输出shape与输入shape相同。
- activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
- dilation_rate:单个整数或由两个个整数构成的list/tuple,指定dilated convolution中的膨胀比例。任何不为1的dilation_rate均与任何不为1的strides均不兼容。
- data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
- use_bias:布尔值,是否使用偏置项
- kernel_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
- bias_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
- kernel_regularizer:施加在权重上的正则项,为Regularizer对象
- bias_regularizer:施加在偏置向量上的正则项,为Regularizer对象
- activity_regularizer:施加在输出上的正则项,为Regularizer对象
- kernel_constraints:施加在权重上的约束项,为Constraints对象
- bias_constraints:施加在偏置上的约束项,为Constraints对象
输入shape
‘channels_first’模式下,输入形如(samples,channels,rows,cols)的4D张量。
‘channels_last’模式下,输入形如(samples,rows,cols,channels)的4D张量。
注意这里的输入shape指的是函数内部实现的输入shape,而非函数接口应指定的input_shape,请参考下面提供的例子。
输出shape
‘channels_first’模式下,为形如(samples,nb_filter, new_rows, new_cols)的4D张量。
‘channels_last’模式下,为形如(samples,new_rows, new_cols,nb_filter)的4D张量。
输出的行列数可能会因为填充方法而改变
2.5、Conv3D层
keras.layers.convolutional.Conv3D(filters, kernel_size, strides=(1, 1, 1), padding='valid', data_format=None, dilation_rate=(1, 1, 1), activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)三维卷积对三维的输入进行滑动窗卷积,当使用该层作为第一层时,应提供input_shape参数。例如input_shape = (3,10,128,128)代表对10帧128*128的彩色RGB图像进行卷积。数据的通道位置仍然有data_format参数指定。
参数
- filters:卷积核的数目(即输出的维度)
- kernel_size:单个整数或由3个整数构成的list/tuple,卷积核的宽度和长度。如为单个整数,则表示在各个空间维度的相同长度。
- strides:单个整数或由3个整数构成的list/tuple,为卷积的步长。如为单个整数,则表示在各个空间维度的相同步长。任何不为1的strides均与任何不为1的dilation_rate均不兼容
- padding:补0策略,为“valid”, “same” 。“valid”代表只进行有效的卷积,即对边界数据不处理。“same”代表保留边界处的卷积结果,通常会导致输出shape与输入shape相同。
- activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
- dilation_rate:单个整数或由3个个整数构成的list/tuple,指定dilated convolution中的膨胀比例。任何不为1的dilation_rate均与任何不为1的strides均不兼容。
- data_format:字符串,“channels_first”或“channels_last”之一,代表数据的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128x128的数据为例,“channels_first”应将数据组织为(3,128,128,128),而“channels_last”应将数据组织为(128,128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
- use_bias:布尔值,是否使用偏置项
- kernel_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
- bias_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
- kernel_regularizer:施加在权重上的正则项,为Regularizer对象
- bias_regularizer:施加在偏置向量上的正则项,为Regularizer对象
- activity_regularizer:施加在输出上的正则项,为Regularizer对象
- kernel_constraints:施加在权重上的约束项,为Constraints对象
- bias_constraints:施加在偏置上的约束项,为Constraints对象
输入shape
‘channels_first’模式下,输入应为形如(samples,channels,input_dim1,input_dim2, input_dim3)的5D张量
‘channels_last’模式下,输入应为形如(samples,input_dim1,input_dim2, input_dim3,channels)的5D张量
这里的输入shape指的是函数内部实现的输入shape,而非函数接口应指定的input_shape。
2.6、Cropping1D层
keras.layers.convolutional.Cropping1D(cropping=(1, 1))在时间轴(axis1)上对1D输入(即时间序列)进行裁剪
参数
- cropping:长为2的tuple,指定在序列的首尾要裁剪掉多少个元素
输入shape:形如(samples,axis_to_crop,features)的3D张量
输出shape:形如(samples,cropped_axis,features)的3D张量。
2.7、Cropping2D层
keras.layers.convolutional.Cropping2D(cropping=((0, 0), (0, 0)), data_format=None)对2D输入(图像)进行裁剪,将在空域维度,即宽和高的方向上裁剪
参数
- cropping:长为2的整数tuple,分别为宽和高方向上头部与尾部需要裁剪掉的元素数
- data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
输入shape:形如(samples,depth, first_axis_to_crop, second_axis_to_crop)
输出shape:形如(samples, depth, first_cropped_axis, second_cropped_axis)的4D张量。
2.8、Cropping3D层
keras.layers.convolutional.Cropping3D(cropping=((1, 1), (1, 1), (1, 1)), data_format=None)对2D输入(图像)进行裁剪
参数
- cropping:长为3的整数tuple,分别为三个方向上头部与尾部需要裁剪掉的元素数
- data_format:字符串,“channels_first”或“channels_last”之一,代表数据的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128x128的数据为例,“channels_first”应将数据组织为(3,128,128,128),而“channels_last”应将数据组织为(128,128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
输入shape:形如 (samples, depth, first_axis_to_crop, second_axis_to_crop, third_axis_to_crop)的5D张量。
输出shape:形如(samples, depth, first_cropped_axis, second_cropped_axis, third_cropped_axis)的5D张量。
2.9、UpSampling1D层
keras.layers.convolutional.UpSampling1D(size=2)在时间轴上,将每个时间步重复length次
参数
- size:上采样因子
输入shape:形如(samples,steps,features)的3D张量
输出shape:形如(samples,upsampled_steps,features)的3D张量
3.0、UpSampling2D层
keras.layers.convolutional.UpSampling2D(size=(2, 2), data_format=None)将数据的行和列分别重复size[0]和size[1]次
参数
-
size:整数tuple,分别为行和列上采样因子
-
data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
输入shape:
‘channels_first’模式下,为形如(samples,channels, rows,cols)的4D张量。
‘channels_last’模式下,为形如(samples,rows, cols,channels)的4D张量。
输出shape:
‘channels_first’模式下,为形如(samples,channels, upsampled_rows, upsampled_cols)的4D张量。
‘channels_last’模式下,为形如(samples,upsampled_rows, upsampled_cols,channels)的4D张量。
3.1、UpSampling3D层
keras.layers.convolutional.UpSampling3D(size=(2, 2, 2), data_format=None)将数据的三个维度上分别重复size[0]、size[1]和ize[2]次
本层目前只能在使用Theano为后端时可用
参数
- size:长为3的整数tuple,代表在三个维度上的上采样因子
- data_format:字符串,“channels_first”或“channels_last”之一,代表数据的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128x128的数据为例,“channels_first”应将数据组织为(3,128,128,128),而“channels_last”应将数据组织为(128,128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
输入shape:
‘channels_first’模式下,为形如(samples, channels, len_pool_dim1, len_pool_dim2, len_pool_dim3)的5D张量
‘channels_last’模式下,为形如(samples, len_pool_dim1, len_pool_dim2, len_pool_dim3,channels, )的5D张量
输出shape:
‘channels_first’模式下,为形如(samples, channels, dim1, dim2, dim3)的5D张量
‘channels_last’模式下,为形如(samples, upsampled_dim1, upsampled_dim2, upsampled_dim3,channels,)的5D张量。
3.2、ZeroPadding1D层
keras.layers.convolutional.ZeroPadding1D(padding=1)对1D输入的首尾端(如时域序列)填充0,以控制卷积以后向量的长度
参数
- padding:整数,表示在要填充的轴的起始和结束处填充0的数目,这里要填充的轴是轴1(第1维,第0维是样本数)
输入shape:形如(samples,axis_to_pad,features)的3D张量
输出shape:形如(samples,paded_axis,features)的3D张量
3.3、ZeroPadding2D层
keras.layers.convolutional.ZeroPadding2D(padding=(1, 1), data_format=None)对2D输入(如图片)的边界填充0,以控制卷积以后特征图的大小
参数
- padding:整数tuple,表示在要填充的轴的起始和结束处填充0的数目,这里要填充的轴是轴3和轴4(即在’th’模式下图像的行和列,在‘channels_last’模式下要填充的则是轴2,3)
- data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
输入shape:
‘channels_first’模式下,形如(samples,channels,first_axis_to_pad,second_axis_to_pad)的4D张量。
‘channels_last’模式下,形如(samples,first_axis_to_pad,second_axis_to_pad, channels)的4D张量。
输出shape:
‘channels_first’模式下,形如(samples,channels,first_paded_axis,second_paded_axis)的4D张量
‘channels_last’模式下,形如(samples,first_paded_axis,second_paded_axis, channels)的4D张量
3.4、ZeroPadding3D层
keras.layers.convolutional.ZeroPadding3D(padding=(1, 1, 1), data_format=None)将数据的三个维度上填充0
本层目前只能在使用Theano为后端时可用
参数
- padding:整数tuple,表示在要填充的轴的起始和结束处填充0的数目,这里要填充的轴是轴3,轴4和轴5,‘channels_last’模式下则是轴2,3和4
- data_format:字符串,“channels_first”或“channels_last”之一,代表数据的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128x128的数据为例,“channels_first”应将数据组织为(3,128,128,128),而“channels_last”应将数据组织为(128,128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
输入shape:
‘channels_first’模式下,为形如(samples, channels, first_axis_to_pad,first_axis_to_pad, first_axis_to_pad,)的5D张量。
‘channels_last’模式下,为形如(samples, first_axis_to_pad,first_axis_to_pad, first_axis_to_pad, channels)的5D张量。
输出shape:
‘channels_first’模式下,为形如(samples, channels, first_paded_axis,second_paded_axis, third_paded_axis,)的5D张量
‘channels_last’模式下,为形如(samples, len_pool_dim1, len_pool_dim2, len_pool_dim3,channels, )的5D张量
3、池化层Pooling
3.1、MaxPooling1D层
keras.layers.pooling.MaxPooling1D(pool_size=2, strides=None, padding='valid')对时域1D信号进行最大值池化
参数
- pool_size:整数,池化窗口大小
- strides:整数或None,下采样因子,例如设2将会使得输出shape为输入的一半,若为None则默认值为pool_size。
- padding:‘valid’或者‘same’
输入shape:形如(samples,steps,features)的3D张量
输出shape:形如(samples,downsampled_steps,features)的3D张量
3.2、MaxPooling2D层
keras.layers.pooling.MaxPooling2D(pool_size=(2, 2), strides=None, padding='valid', data_format=None)为空域信号施加最大值池化
参数
- pool_size:整数或长为2的整数tuple,代表在两个方向(竖直,水平)上的下采样因子,如取(2,2)将使图片在两个维度上均变为原长的一半。为整数意为各个维度值相同且为该数字。
- strides:整数或长为2的整数tuple,或者None,步长值。
- border_mode:‘valid’或者‘same’
- data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
输入shape
‘channels_first’模式下,为形如(samples,channels, rows,cols)的4D张量
‘channels_last’模式下,为形如(samples,rows, cols,channels)的4D张量
输出shape
‘channels_first’模式下,为形如(samples,channels, pooled_rows, pooled_cols)的4D张量
‘channels_last’模式下,为形如(samples,pooled_rows, pooled_cols,channels)的4D张量
3.3、MaxPooling3D层
keras.layers.pooling.MaxPooling3D(pool_size=(2, 2, 2), strides=None, padding='valid', data_format=None)为3D信号(空域或时空域)施加最大值池化。本层目前只能在使用Theano为后端时可用
参数
- pool_size:整数或长为3的整数tuple,代表在三个维度上的下采样因子,如取(2,2,2)将使信号在每个维度都变为原来的一半长。
- strides:整数或长为3的整数tuple,或者None,步长值。
- padding:‘valid’或者‘same’
- data_format:字符串,“channels_first”或“channels_last”之一,代表数据的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128x128的数据为例,“channels_first”应将数据组织为(3,128,128,128),而“channels_last”应将数据组织为(128,128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
输入shape
‘channels_first’模式下,为形如(samples, channels, len_pool_dim1, len_pool_dim2, len_pool_dim3)的5D张量
‘channels_last’模式下,为形如(samples, len_pool_dim1, len_pool_dim2, len_pool_dim3,channels, )的5D张量
输出shape
‘channels_first’模式下,为形如(samples, channels, pooled_dim1, pooled_dim2, pooled_dim3)的5D张量
‘channels_last’模式下,为形如(samples, pooled_dim1, pooled_dim2, pooled_dim3,channels,)的5D张量
3.4、AveragePooling1D层
keras.layers.pooling.AveragePooling1D(pool_size=2, strides=None, padding='valid')对时域1D信号进行平均值池化
参数
- pool_size:整数,池化窗口大小
- strides:整数或None,下采样因子,例如设2将会使得输出shape为输入的一半,若为None则默认值为pool_size。
- padding:‘valid’或者‘same’
输入shape:形如(samples,steps,features)的3D张量
输出shape:形如(samples,downsampled_steps,features)的3D张量
3.5、AveragePooling2D层
keras.layers.pooling.AveragePooling2D(pool_size=(2, 2), strides=None, padding='valid', data_format=None)为空域信号施加平均值池化
参数
- pool_size:整数或长为2的整数tuple,代表在两个方向(竖直,水平)上的下采样因子,如取(2,2)将使图片在两个维度上均变为原长的一半。为整数意为各个维度值相同且为该数字。
- strides:整数或长为2的整数tuple,或者None,步长值。
- border_mode:‘valid’或者‘same’
- data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
输入shape
‘channels_first’模式下,为形如(samples,channels, rows,cols)的4D张量。
‘channels_last’模式下,为形如(samples,rows, cols,channels)的4D张量。
输出shape
‘channels_first’模式下,为形如(samples,channels, pooled_rows, pooled_cols)的4D张量。
‘channels_last’模式下,为形如(samples,pooled_rows, pooled_cols,channels)的4D张量。
3.6、AveragePooling3D层
keras.layers.pooling.AveragePooling3D(pool_size=(2, 2, 2), strides=None, padding='valid', data_format=None)为3D信号(空域或时空域)施加平均值池化。本层目前只能在使用Theano为后端时可用
参数
- pool_size:整数或长为3的整数tuple,代表在三个维度上的下采样因子,如取(2,2,2)将使信号在每个维度都变为原来的一半长。
- strides:整数或长为3的整数tuple,或者None,步长值。
- padding:‘valid’或者‘same’
- data_format:字符串,“channels_first”或“channels_last”之一,代表数据的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128x128的数据为例,“channels_first”应将数据组织为(3,128,128,128),而“channels_last”应将数据组织为(128,128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
输入shape:
‘channels_first’模式下,为形如(samples, channels, len_pool_dim1, len_pool_dim2, len_pool_dim3)的5D张量
‘channels_last’模式下,为形如(samples, len_pool_dim1, len_pool_dim2, len_pool_dim3,channels, )的5D张量
输出shape:
‘channels_first’模式下,为形如(samples, channels, pooled_dim1, pooled_dim2, pooled_dim3)的5D张量
‘channels_last’模式下,为形如(samples, pooled_dim1, pooled_dim2, pooled_dim3,channels,)的5D张量
3.7、GlobalMaxPooling1D层
keras.layers.pooling.GlobalMaxPooling1D()对于时间信号的全局最大池化
输入shape:形如(samples,steps,features)的3D张量。
输出shape:形如(samples, features)的2D张量。
3.8、GlobalAveragePooling1D层
keras.layers.pooling.GlobalAveragePooling1D()为时域信号施加全局平均值池化
输入shape:形如(samples,steps,features)的3D张量
输出shape:形如(samples, features)的2D张量
3.9、GlobalMaxPooling2D层
keras.layers.pooling.GlobalMaxPooling2D(dim_ordering='default')为空域信号施加全局最大值池化
参数
- data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras
1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
输入shape:
‘channels_first’模式下,为形如(samples,channels, rows,cols)的4D张量
‘channels_last’模式下,为形如(samples,rows, cols,channels)的4D张量
输出shape:形如(nb_samples, channels)的2D张量
3.10、GlobalAveragePooling2D层
keras.layers.pooling.GlobalAveragePooling2D(dim_ordering='default')为空域信号施加全局平均值池化
参数
- data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras
1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
输入shape:
‘channels_first’模式下,为形如(samples,channels, rows,cols)的4D张量
‘channels_last’模式下,为形如(samples,rows, cols,channels)的4D张量
输出shape:形如(nb_samples, channels)的2D张量
4、局部连接层LocallyConnceted
4、循环层Recurrent
2.4、递归层(Recurrent)
递归层包含三种模型:LSTM、GRU和SimpleRNN
2.4.1抽象层,不能直接使用
keras.layers.recurrent.Recurrent(weights=None, return_sequences=False, go_backwards=False, stateful=False, unroll=False, consume_less='cpu', input_dim=None, input_length=None)return_sequences:True返回整个序列,false返回输出序列的最后一个输出
go_backwards:True,逆向处理输入序列,默认为False
stateful:布尔值,默认为False,若为True,则一个batch中下标为i的样本的最终状态将会用作下一个batch同样下标的样本的初始状态
2.4.2、全连接RNN网络
keras.layers.recurrent.SimpleRNN(output_dim, init='glorot_uniform', inner_init='orthogonal', activation='tanh', W_regularizer=None, U_regularizer=None, b_regularizer=None, dropout_W=0.0, dropout_U=0.0)inner_init:内部单元的初始化方法
dropout_W:0~1之间的浮点数,控制输入单元到输入门的连接断开比例
dropout_U:0~1之间的浮点数,控制输入单元到递归连接的断开比例
2.4.3、LSTM层
keras.layers.recurrent.LSTM(output_dim, init='glorot_uniform', inner_init='orthogonal', forget_bias_init='one', activation='tanh', inner_activation='hard_sigmoid', W_regularizer=None, U_regularizer=None, b_regularizer=None, dropout_W=0.0, dropout_U=0.0)forget_bias_init:遗忘门偏置的初始化函数,Jozefowicz et al.建议初始化为全1元素
inner_activation:内部单元激活函数
嵌入层 Embedding
2.5 Embedding层
keras.layers.embeddings.Embedding(input_dim, output_dim, init='uniform', input_length=None, W_regularizer=None, activity_regularizer=None, W_constraint=None, mask_zero=False, weights=None, dropout=0.0)只能作为模型第一层
mask_zero:布尔值,确定是否将输入中的‘0’看作是应该被忽略的‘填充’(padding)值,该参数在使用递归层处理变长输入时有用。设置为True的话,模型中后续的层必须都支持masking,否则会抛出异常
Merge层
网络模型
网络模型可以将上面定义了各种基本网络层组合起来。
Keras有两种类型的模型,序贯模型(Sequential)和函数式模型(Model),函数式模型应用更为广泛,序贯模型是函数式模型的一种特殊情况。
两类模型有一些方法是相同的:
model的方法:
model.summary() : 打印出模型概况,它实际调用的是keras.utils.print_summary
model.get_config() :返回包含模型配置信息的Python字典
model = Model.from_config(config) 模型从它的config信息中重构回去
model = Sequential.from_config(config) 模型从它的config信息中重构回去
model.get_weights():返回模型权重张量的列表,类型为numpy array
model.set_weights():从numpy array里将权重载入给模型
model.to_json:返回代表模型的JSON字符串,仅包含网络结构,不包含权值。可以从JSON字符串中重构原模型:
from models import model_from_json
json_string = model.to_json()
model = model_from_json(json_string)model.to_yaml:与model.to_json类似,同样可以从产生的YAML字符串中重构模型
from models import model_from_yaml
yaml_string = model.to_yaml()
model = model_from_yaml(yaml_string)model.save_weights(filepath):将模型权重保存到指定路径,文件类型是HDF5(后缀是.h5)
model.load_weights(filepath, by_name=False):从HDF5文件中加载权重到当前模型中, 默认情况下模型的结构将保持不变。如果想将权重载入不同的模型(有些层相同)中,则设置by_name=True,只有名字匹配的层才会载入权重
keras有两种model,分别是Sequential模型和泛型模型
2.1 Sequential模型
Sequential是多个网络层的线性堆叠
可以通过向Sequential模型传递一个layer的list来构造该模型:
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([
Dense(32, input_dim=784),
Activation('relu'),
Dense(10),
Activation('softmax'),
])也可以通过.add()方法一个个的将layer加入模型中:
model = Sequential()
model.add(Dense(32, input_dim=784))
model.add(Activation('relu'))还可以通过merge将两个Sequential模型通过某种方式合并
Sequential模型的方法:
compile(self, optimizer, loss, metrics=[], sample_weight_mode=None)
fit(self, x, y, batch_size=32, nb_epoch=10, verbose=1, callbacks=[], validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None)
evaluate(self, x, y, batch_size=32, verbose=1, sample_weight=None)
#按batch获得输入数据对应的输出,函数的返回值是预测值的numpy array
predict(self, x, batch_size=32, verbose=0)
#按batch产生输入数据的类别预测结果,函数的返回值是类别预测结果的numpy array或numpy
predict_classes(self, x, batch_size=32, verbose=1)
#本函数按batch产生输入数据属于各个类别的概率,函数的返回值是类别概率的numpy array
predict_proba(self, x, batch_size=32, verbose=1)
train_on_batch(self, x, y, class_weight=None, sample_weight=None)
test_on_batch(self, x, y, sample_weight=None)
predict_on_batch(self, x)
fit_generator(self, generator, samples_per_epoch, nb_epoch, verbose=1, callbacks=[], validation_data=None, nb_val_samples=None, class_weight=None, max_q_size=10)
evaluate_generator(self, generator, val_samples, max_q_size=10)2.2 泛型模型
Keras泛型模型接口是:
用户定义多输出模型、非循环有向模型或具有共享层的模型等复杂模型的途径
适用于实现:全连接网络和多输入多输出模型
多输入多输出,官方例子给出:预测一条新闻的点赞转发数,主要输入是新闻本身,还可以加入额外输入,比如新闻发布日期,新闻作者等,具体的实现还是看官网文档吧:
http://keras-cn.readthedocs.io/en/latest/getting_started/functional_API/
所以感觉这个模型可以针对特定task搞一些创新哦
泛型模型model的属性:
model.layers:组成模型图的各个层
model.inputs:模型的输入张量列表
model.outputs:模型的输出张量列表
方法:类似序列模型的方法
补充get_layer
get_layer(self, name=None, index=None)
本函数依据模型中层的下标或名字获得层对象,泛型模型中层的下标依据自底向上,水平遍历的顺序。
name:字符串,层的名字
index: 整数,层的下标
函数的返回值是层对象
from keras.models import Model
from keras.layers import Input, Dense
a = Input(shape=(32,))
b = Dense(32)(a)
model = Model(inputs=a, outputs=b)REF
https://www.cnblogs.com/lhxsoft/p/13534667.html
http://events.jianshu.io/p/4d21b988f36f

 浙公网安备 33010602011771号
浙公网安备 33010602011771号