train the model model.fit 模型训练
#train the model
history = model.fit(x_train, y_train,
batch_size=32,
epochs=100,
validation_split=0.1,
shuffle=True,
class_weight=class_weights,
callbacks=[es])
model.fit( 训练集的输入特征,
训练集的标签,
batch_size, #每一个batch的大小
epochs, #迭代次数
validation_data = (测试集的输入特征,测试集的标签),
validation_split = 从测试集中划分多少比例给验证数据,
validation_freq = 测试的epoch间隔数)
https://blog.csdn.net/yunfeather/article/details/106463327
model.fit( ) :
将训练数据在模型中训练一定次数,返回loss和测量指标
model.fit(x, y, batch_size, epochs, verbose, validation_split, validation_data, validation_freq)
model.fit( ) 参数:
| x | 输入特征 |
| y | 输出标签(或回归) |
| batch_size | 每一个batch的大小(批尺寸),即训练一次网络所用的样本数 |
| epochs | 迭代次数,即全部样本数据将被“轮”多少次,轮完训练停止 |
| verbose |
0:不输出信息;1:显示进度条(一般默认为1);2:每个epoch输出一行记录; |
| validation_split | (0,1)的浮点数,分割数据当验证数据,其它当训练数据 |
| validation_data | 指定验证数据,该数据将覆盖validation_spilt设定的数据 |
| validation_freq | 指定验证数据的epoch |
| callback |
在每个training/epoch/batch结束时,可以通过回调函数Callbacks查看一些内部信息。常用的callback有EarlyStopping,当监视的变量停止改善时,停止训练,防止模型过拟合,其默认参数如下: |
callback=callbacks.EarlyStopping(monitor='loss',min_delta=0.002,patience=0,mode='auto',restore_best_weights=False)
- monitor:监视量,一般是loss。
- min_delta:监视量改变的最小值,如果监视量的改变绝对值比min_delta小,这次就不算监视量改善,具体是增大还是减小看mode
- patience:如发现监视量loss相比上一个epoch训练没有下降,则经过patience个epoch后停止训练
- mode:在min模式训练,如果监视量停止下降则终止训练;在max模式下,如果监视量停止上升则停止训练。监视量使用acc时就要用max,使用loss时就要用min。
- restore_best_weights:是否把模型权重设为训练效果最好的epoch。如果为False,最终模型权重是最后一次训练的权重
model.fit( )返回值
model.fit( )函数返回一个History的对象,即记录了loss和其他指标的数值随epoch变化的情况。
shuffle
鸢尾花数据:
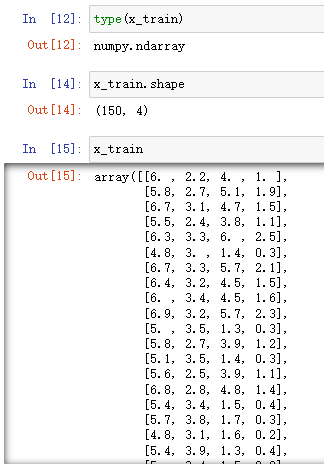
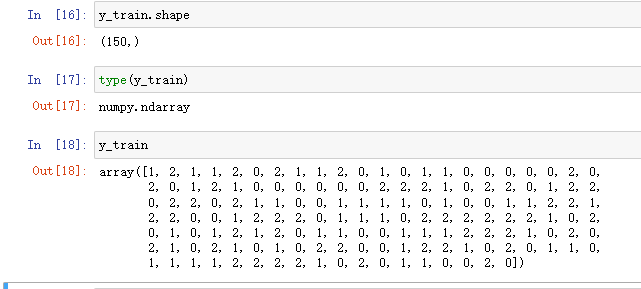
- x:输入数据Input data;
- y:标签;
- batch_size:整数,梯度下降时每个batch的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步;
- epochs:整数,训练步数;
- verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录;
- callbacks:回调函数;
- validation_split:0~1之间,将训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试模型的精度。注意,validation_split的划分在shuffle之前,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不均匀;
- validation_data:指定的验证集。此参数将覆盖validation_spilt;
- shuffle:布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺序。若为字符串“batch”,则是用来处理HDF5数据的特殊情况,它将在batch内部将数据打乱。
- class_weight:将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)
sample_weight:权值的numpy array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递一个的形式为samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了sample_weight_mode=’temporal’。 - initial_epoch: 从该参数指定的epoch开始训练,在继续之前的训练时有用。
- steps_per_epoch:指定每个epoch所使用的迭代次数,默认每次用尽数据集
REF
https://blog.csdn.net/Fwuyi/article/details/123214588
https://blog.csdn.net/xiaofeixia002X/article/details/128482822

 浙公网安备 33010602011771号
浙公网安备 33010602011771号