Sequence Read Archive (SRA)
The Sequence Read Archive (SRA) is an archive for high throughput sequencing data, publically accessible, for the purpose of enhancing reproducibility in the scientific community.
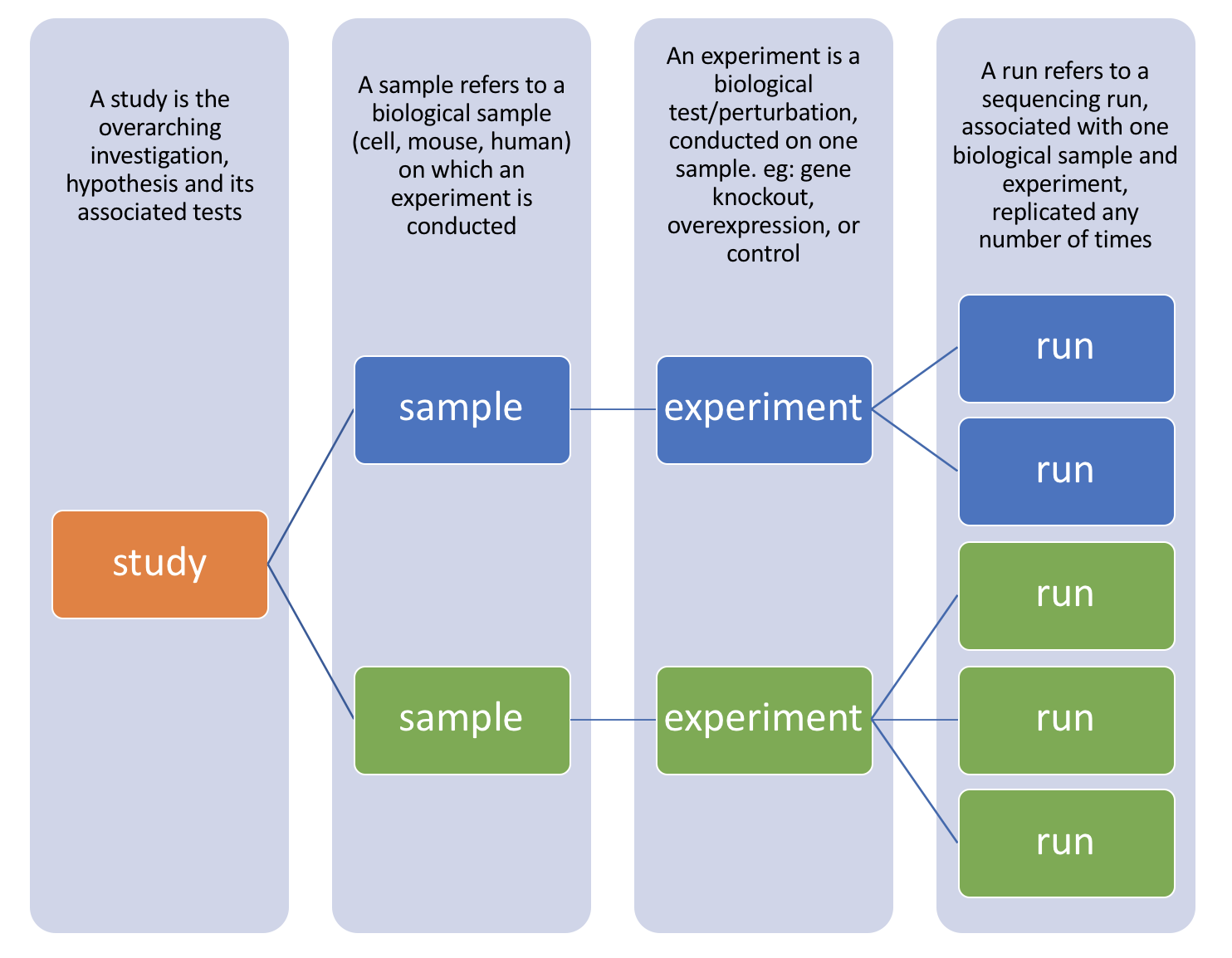
There are four hierarchical levels of SRA entities and their accessions:
- STUDY with accessions in the form of SRP, ERP, or DRP
- SAMPLE with accessions in the form of SRS, ERS, or DRS
- EXPERIMENT with accessions in the form of SRX, ERX, or DRX
- RUN with accessions in the form of SRR, ERR, or DRR
The minimum publishable unit in the SRA, is an EXPERIMENT (SRX)
REF
https://hbctraining.github.io/Accessing_public_genomic_data/lessons/downloading_from_SRA.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号